一种基于单向请求报文识别加密视频的方法
本发明涉及一种基于单向请求报文识别加密视频的方法,属于网络安全。
背景技术:
1、视频流量逐渐发展成为全球互联网内容的主流,其中不可避免地包含了一些对社会有负面影响的有害视频,隐私保护和安全防护是互联网应用必须考虑的问题。利用tls(transport layer security,tls)协议实现端到端加密传输是最通用的加密传输方法。如今,网络安全已经引起了广大网民的重点关注,所以对所有数据都加密是网络发展的大趋势,这在很大程度上为互联网应用提供安全防护。但与此同时,这也为网络管理员从加密的视频流量中识别出对社会和国家有害的视频带来了很大的困难。
2、从加密的视频数据中提取出用于网络安全防护的信息是网络管理部门在进行网络管理工作中的重要问题。在这项工作中,要在互联网用户的隐私安全得到保障的前提下,及时准确的发现网络中散布的危害国家和社会的信息。
3、目前对于加密视频的识别已经有了一些研究,这些研究通过从视频传输流量中提取关键特征来识别加密的视频流量。但是在实际网络中,由于网络拓扑结构的复杂性,存在着大量的非对称路由,上游和下游的流量通常采用不同的路径传输,因此这导致网络管理员在数据采集点只能采集到单向流量,使得现有的这些基于双向流的视频识别方法不能获得足够的特征来应用到实际网络场景下,因此,需要开发一种方法从单向流中解析数据以识别加密视频。另一个问题是现实网络中视频数量是海量的,但是现有研究都是基于小型甚至微型视频指纹库进行实验验证,实验结果并不能反映这些算法应用于大型视频指纹库的可行性。因此基于单向流研究出一种应用在现实网络中的视频识别方法显得尤为重要。
技术实现思路
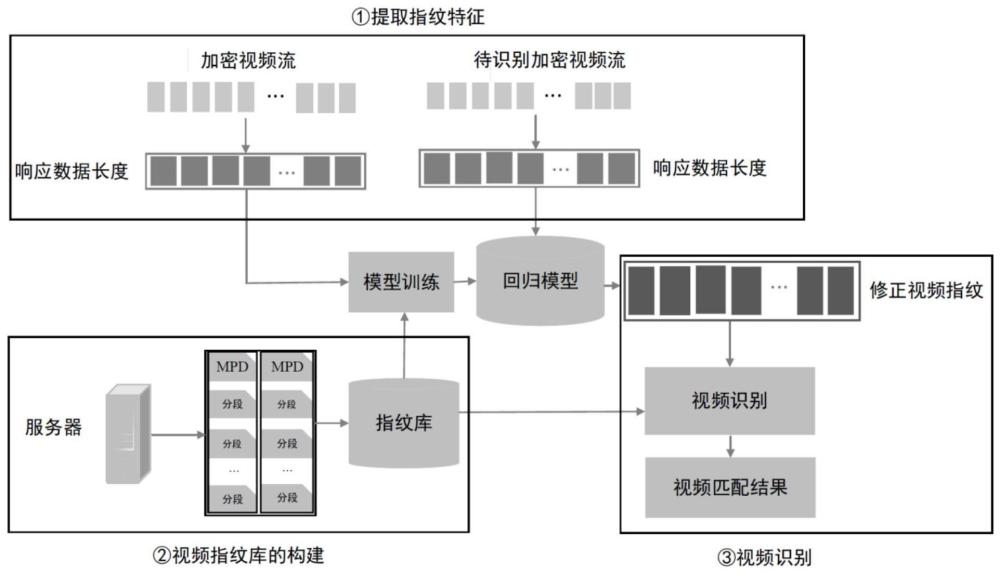
1、本发明公开了一种基于单向请求报文识别加密视频的方法,该方法首先从服务器端获取mpd文件以获得视频分段的负载长度及其顺序信息,并通过获得的视频分段信息构建视频指纹库。然后,基于http/1.1使用的流水线模式,从客户端到服务器端的视频请求报文中分析获得传输的加密视频分段负载长度估计值。接着,在传输的视频分段负载长度与该分段的实际负载长度之间建立拟合模型,从而得到了修正视频分段长度的线性回归模型。最后,将修正后的视频指纹与视频指纹库中的指纹进行匹配从而得到视频的识别结果。本发明只基于单向请求报文识别被加密传输的视频,可应用在非对称路由场景下对加密视频的识别。
2、为了实现本发明的目的,本方案具体技术步骤如下:
3、步骤(1)通过从网页源码或者服务器端的视频描述文件(media presentationdescription,mpd)获取视频分段的相关信息;
4、步骤(2)通过解析步骤(1)中的视频分段相关信息来构建视频指纹库;
5、步骤(3)使用播放器播放指纹库中的部分视频,并采集其加密传输的下行加密视频数据,将从指纹库获得的分段负载实际长度和对应的下行视频数据分段长度构成的数据集按照一定比例分为训练集和测试集;
6、步骤(4)使用步骤(3)获得的训练集,在分段负载实际长度和对应的下行视频数据分段长度之间进行数据拟合,从而得到了修正视频分段负载长度的线性回归模型,使用测试集进行模型验证;
7、步骤(5)通过采集设备采集用户接入点的流量;
8、步骤(6)解析步骤(5)中的流量,过滤出视频流量的上行请求报文,基于http/1.1的流水线传输模式,利用请求报文的tcp头部信息计算视频分段加密后的负载长度,使用得到的线性回归模型修正视频分段的负载长度;
9、步骤(7)将修正后的视频分段负载长度与视频指纹库中的视频指纹进行匹配得到加密视频的识别结果。
10、进一步的,所述步骤(1)中,获取网络视频的视频分段相关详细信息的方法如下:
11、视频平台有时将记录视频分段详细信息的内容转换为json格式显示在网页源码中,所以通过分析视频网页源码的方法来获得该视频分段的详细描述信息,或者直接获取视频的描述文件(mpd文件)获取记录视频分段详细信息的内容。
12、进一步的,所述步骤(2)中,构建视频指纹库的具体过程如下:
13、从网页内容中提取出视频的分段信息后,从中解析视频分段的实际负载长度和传输顺序,以此来构建视频指纹库,最终视频指纹库包括每个加密视频的id编号及其按序排列的视频分段负载长度。
14、进一步的,所述步骤(3)中,使用播放器播放指纹库中的部分视频,对加密传输的下行加密视频数据的具体采集步骤如下:
15、(3.1)首先通过播放器播放步骤(2)中构造的视频指纹库中的部分视频,采集加密传输的下行加密数据,从中提取视频分段加密后的负载长度;
16、(3.2)根据指纹库获得的视频分段负载实际长度和对应的下行视频数据分段长度构成的数据集按照一定比例分为训练集和测试集,其中训练集占三分之二;
17、(3.3)实验数据采集过程中保证视频分段信息的稳定,并在每次播放完一个视频后及时释放应用缓存空间,以保证每次播放都是全数据传输,以确保所提取用于训练模型的数据的完整性。
18、进一步的,所述步骤(4)中,通过数据拟合得到视频分段负载实际长度的回归模型,具体过程如下:
19、使用步骤(3)获得的训练集,在分段负载实际长度和对应的下行视频数据分段长度之间进行数据拟合,得到修正视频分段负载长度的线性回归模型。
20、进一步的,所述步骤(5)中,通过采集设备采集用户接入点的流量,具体过程如下:
21、通过采集设备采集用户接入点的流量,并从中筛选出视频流量进行识别。
22、进一步的,所述步骤(6)中,通过线性回归模型待匹配加密视频分段负载长度,具体包含以下子步骤:
23、(6.1)解析步骤(5)中筛选出来的视频流量,过滤出视频流量的上行请求报文,并分析从客户端到服务端的请求报文,基于http/1.1的流水线传输模式,利用请求报文tcp头部信息计算加密后视频分段的负载长度,tcp报文中的ack信息表示客户端期望从服务器接收的下一个tcp信息的字节数,所以基于客户端相邻的两个请求包tcp头部的确认号之差计算数据段的负载长度估计值;
24、(6.2)得到加密的视频分段负载长度估计值后,利用步骤(4)中的回归模型得到视频分段实际负载长度的修正值。
25、进一步的,所述步骤(7)中,对加密视频的识别具体包含以下子步骤:
26、视频通常是顺序播放,因此序列中视频片段的匹配不仅与可匹配片段有关,还与可匹配片段前后的片段有关,因此选择顺序匹配的方法来匹配视频分段。
27、与现有技术相比,本发明的技术方案具有以下优点:
28、(1)本发明提出了一种基于单向请求报文识别加密视频的方法,以单向流量作为分析对象,适用于非对称路由场景。
29、(2)本发明仅从加密视频相邻请求的确认号提取每个视频分段的负载估计值,所需的资源消耗较小。
30、(3)本发明结合提出了一种修正视频分段实际负载长度的回归模型,以精确修正视频分段长度,使得本发明得以应用于较大规模的视频指纹库场景。
- 还没有人留言评论。精彩留言会获得点赞!