对目标场景进行取景的方法及装置与流程
本发明实施例涉及通信领域,具体而言,涉及一种对目标场景进行取景的方法及装置。
背景技术:
1、在相关领域中,需要对场景进行取景,例如,对视频会议进行取景,现有技术中通常使用手机或者其他类似终端的摄像头拍摄场景的画面。对于较大的场景,视场角小的摄像头无法拍摄到场景的全景画面,对于场景中的特写画面需要移动摄像头的位置拍摄,通常需要专业的拍摄人员进行跟拍,无法对场景自动进行取景。
2、针对上述问题,目前尚未存在有效的解决方案。
技术实现思路
1、本发明实施例提供了一种对目标场景进行取景的方法及装置,以至少解决相关技术中无法对场景自动进行取景的问题。
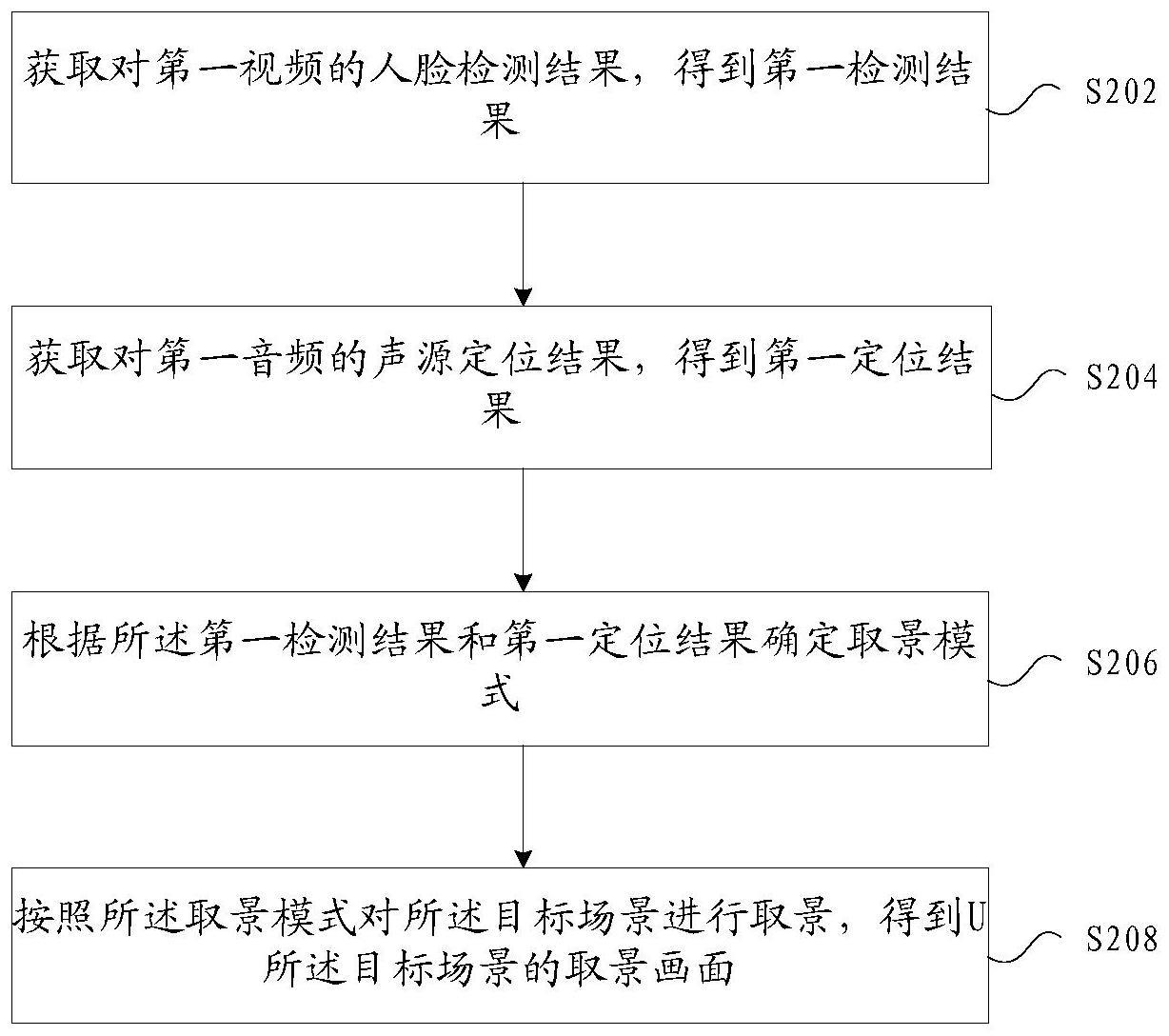
2、根据本发明的一个实施例,提供了一种对目标场景进行取景的方法,包括:获取对第一视频的人脸检测结果,得到第一检测结果,其中,所述第一视频是在第一时刻通过全景相机对目标场景进行拍摄得到的视频;获取对第一音频的声源定位结果,得到第一定位结果,其中,所述第一音频是在所述第一时刻通过麦克风阵列对所述目标场景进行采集得到的音频;根据所述第一检测结果和第一定位结果确定取景模式,其中,所述取景模式包括:自动模式、追踪模式和独立模式,所述自动模式是对所述目标场景中所有参与者进行取景的模式,所述追踪模式是对所述目标场景中的主发言人进行追踪取景的模式,所述独立模式是对所述目标场景中多个发言人进行取景的模式;按照所述取景模式对所述目标场景进行取景,得到所述目标场景的取景画面。
3、在一个示例性实施例中,根据所述第一检测结果和第一定位结果确定取景模式,包括:在所述第一检测结果和所述第一定位结果表示所述目标场景中不存在发言人的情况下,确定所述取景模式为所述自动模式;在所述第一检测结果和所述第一定位结果表示所述目标场景中存在主发言人的情况下,确定所述取景模式为所述追踪模式;在所述第一检测结果和所述第一定位结果表示所述目标场景中存在至少两个发言人的情况下,确定所述取景模式为所述独立模式。
4、在一个示例性实施例中,所述方法还包括:获取发言人数据库,其中,所述发言人数据库中记录了发言人,以及发言人的发言时长;根据所述发言人数据库确定所述发言时长最长的发言人为目标发言人,所述目标发言人的发言时长为目标发言时长;根据所述目标发言人的目标发言时长,确定所述目标场景中是否存在所述主发言人。
5、在一个示例性实施例中,根据所述目标发言人的目标发言时长,确定所述目标场景中是否存在所述主发言人,包括:确定所述发言人数据库中记录的所有发言人的发言时长的总和,得到总发言时长;在所述目标发言时长与所述总发言时长的比值大于或等于预设值的情况下,确定所述目标发言人为所述主发言人;否则,确定所述所述目标场景中存在至少两个发言人。
6、在一个示例性实施例中,按照所述取景模式对所述目标场景进行取景,包括:将所述第一检测结果输入触发器,通过所述触发器判断是否满足取景的触发条件;在满足所述触发条件的情况下,按照所述取景模式对所述目标场景进行取景。
7、在一个示例性实施例中,将所述第一检测结果输入触发器,通过所述触发器判断是否满足取景的触发条件,包括:获取对第二视频的人脸检测结果,得到第二检测结果,其中,所述第二视频是在第二时刻通过所述全景相机对所述目标场景进行拍摄得到的视频,所述第二时刻是所述第一时刻之前的视频拍摄时刻;在所述第一检测结果中的检测框与所述第二检测结果中的检测框满足预设条件的情况下,确定满足所述取景的触发条件。
8、在一个示例性实施例中,在所述第一检测结果中的检测框与所述第二检测结果中的检测框满足预设条件的情况下,确定满足所述取景的触发条件,包括:确定所述第一检测结果中的第一目标检测框,以及所述第二检测结果中的第二目标检测框;在所述第一目标检测框的中心点与所述第二目标检测框的中心点之间的距离大于或等于预设距离阈值的情况下,确定满足所述取景的触发条件;或者,在所述第一检测框的面积与所述第二检测框的面积的差值大于或等于预设差值阈值的情况下,确定满足所述取景的触发条件。
9、在一个示例性实施例中,确定所述第一检测结果中的第一目标检测框,以及所述第二检测结果中的第二目标检测框,包括:在所述取景模式为所述自动模式的情况下,将所述第一检测结果中位于所述第一视频的边界的检测框确定为所述第一目标检测框,将所述第二检测结果中位于所述第二视频的边界的检测框确定为所述第二目标检测框;在所述取景模式为所述追踪模式的情况下,将所述第一检测结果中对所述主发言人检测得到的检测框确定为所述第一目标检测框,将所述第二检测结果中对所述主发言人检测得到的检测框确定为所述第二目标检测框;在所述取景模式为所述独立模式的情况下,将所述第一检测结果中对所述多个发言人检测得到的检测框确定为所述第一目标检测框,将所述第二检测结果中对所述多个发言人检测得到的检测框确定为所述第二目标检测框。
10、在一个示例性实施例中,在满足所述触发条件的情况下,按照所述取景模式对所述目标场景进行取景,包括:在所述取景模式为所述自动模式的情况下,在所述第一检测结果中确定位于所述第一视频的边界的检测框;根据所述第一视频的边界的检测框确定取景框;对所述取景框进行填充,得到所述目标场景的取景画面。
11、在一个示例性实施例中,在满足所述触发条件的情况下,按照所述取景模式对所述目标场景进行取景,还包括:在所述取景模式为所述追踪模式的情况下,在所述第一检测结果中确定所述主发言人对应的检测框;将所述主发言人象对应的检测框映射到左副相机在所述第一时刻拍摄的视频画面,得到第一映射画面;或者,将所述主发言人对应的检测框映射到右副相机在所述第一时刻拍摄的视频画面,得到第二映射画面;通过所述第一映射画面或所述第二映射画面对所述目标场景进行取景。
12、在一个示例性实施例中,将所述主发言人对应的检测框映射到左副相机在所述第一时刻拍摄的视频画面,得到第一映射画面;或者,将所述主发言人对应的检测框映射到右副相机在所述第一时刻拍摄的视频画面,得到第二映射画面,包括:在所述主发言人对应的检测框位于所述第一视频的左侧的情况下,将所述主发言人对应的检测框映射到左副相机在所述第一时刻拍摄的视频画面,得到所述第一映射画面;在所述主发言人对应的检测框位于所述第一视频的右侧的情况下,将所述主发言人对应的检测框映射到右副相机在所述第一时刻拍摄的视频画面,得到所述第二映射画面。
13、在一个示例性实施例中,通过所述第一映射画面或所述第二映射画面对所述目标场景进行取景,包括:根据所述第一映射画面或者所述第二映射画面确定取景框;对所述取景框进行填充,得到所述目标场景的取景画面。
14、在一个示例性实施例中,所述方法还包括:在所述取景模式为所述追踪模式的情况下,通过所述第一定位结果确定所述第一音频的角度值;通过第一检测结果中的检测框确定人脸的角度值;在所述第一音频的角度值与所述人脸的角度值的差值在预设范围内的情况下,定位到所述主发言人。
15、在一个示例性实施例中,在所述第一音频的角度值与所述人脸的角度值的差值在预设范围内的情况下,定位到所述主发言人,还包括:在所述第一检测结果中定位到的发言人与第二检测结果中定位到的发言人相同的情况下,增加所述发言人的发言时长,其中,所述第二检测结果是对第二视频的人脸检测结果,所述第二视频是在第二时刻通过所述全景相机对所述目标场景进行拍摄得到的视频,所述第二时刻是所述第一时刻之前的视频拍摄时刻;在所述发言人的计时时长大于或等于预设时长阈值的情况下,将所述发言人确定为所述主发言人。
16、在一个示例性实施例中,在满足所述触发条件的情况下,按照所述取景模式对所述目标场景进行取景,还包括:在所述取景模式为所述独立模式的情况下,在所述第一检测结果中确定所述多个发言人对应的检测框;将所述多个发言人中每个发言人对应的检测框映射到左副相机在所述第一时刻拍摄的视频画面;或者,映射到右副相机在所述第一时刻拍摄的视频画面,得到多个映射画面;通过所述多个映射画面对所述目标场景进行取景。
17、在一个示例性实施例中,将所述多个发言人中每个发言人对应的检测框映射到左副相机在所述第一时刻拍摄的视频画面;或者,映射到右副相机在所述第一时刻拍摄的视频画面,得到多个映射画面,包括:对所述多个发言人中每个发言人对应的检测框执行以下操作,在执行以下操作时的发言人对应的检测框为当前发言人对应的检测框:在所述当前发言人对应的检测框位于所述第一视频的左侧的情况下,将所述当前发言人对应的检测框映射到左副相机在所述第一时刻拍摄的视频画面,得到当前映射画面;在所述当前发言人对应的检测框位于所述第一视频的右侧的情况下,将所述当前发言人对应的检测框映射到右副相机在所述第一时刻拍摄的视频画面,得到当前映射画面,其中,所述多个映射画面包括所述当前映射画面。
18、在一个示例性实施例中,通过所述多个映射画面对所述目标场景进行取景,包括:确定所述多个映射画面中每个映射画面的取景框,得到多个取景框;对所述多个取景框进行填充,得到多个取景画面;对所述多个取景画面进行拼接,得到所述目标场景的取景画面。
19、根据本发明的另一个实施例,提供了一种对目标场景进行取景的装置,包括:第一获取模块,用于获取对第一视频的人脸检测结果,得到第一检测结果,其中,所述第一视频是在第一时刻通过全景相机对目标场景进行拍摄得到的视频;第二获取模块,用于获取对第一音频的声源定位结果,得到第一定位结果,其中,所述第一音频是在所述第一时刻通过麦克风阵列对所述目标场景进行采集得到的音频;确定模块,用于根据所述第一检测结果和第一定位结果确定取景模式,其中,所述取景模式包括:自动模式、追踪模式和独立模式,所述自动模式是对所述目标场景中所有参与值象进行取景的模式,所述追踪模式是对所述目标场景中的主发言人进行追踪取景的模式,所述独立模式是对所述目标场景中多个发言人进行取景的模式;取景模块,用于按照所述取景模式对所述目标场景进行取景,得到所述目标场景的取景画面。
20、根据本发明的又一个实施例,还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,其中,所述计算机程序被处理器执行时实现上述任一项中所述的方法的步骤。
21、根据本发明的又一个实施例,还提供了一种电子装置,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以执行上述任一项方法实施例中的步骤。
22、通过本发明,由于将取景模式划分为自动模式、追踪模式和独立模式,其中,自动模式是对目标场景中所有参与者进行取景,追踪模式对目标场景中的主发言人进行追踪取景的模式,独立模式是对目标场景中多个发言人进行取景的模式。
23、在第一时刻通过全景相机对目标场景进行拍摄得到第一视频,同时在第一时刻通过麦克风阵列对目标场景进行音频采集,得到第一音频。根据对第一视频的第一检测结果和对第一音频的第一定位结果可以确定取景模式。按照确定出的取景模式对目标场景进行取景,这样可以达到自动对目标场景进行取景的目的,因此,可以解决相关技术中无法对场景自动进行取景的问题。
- 还没有人留言评论。精彩留言会获得点赞!