一种基于混合生成对抗网络的无线网络中断检测方法
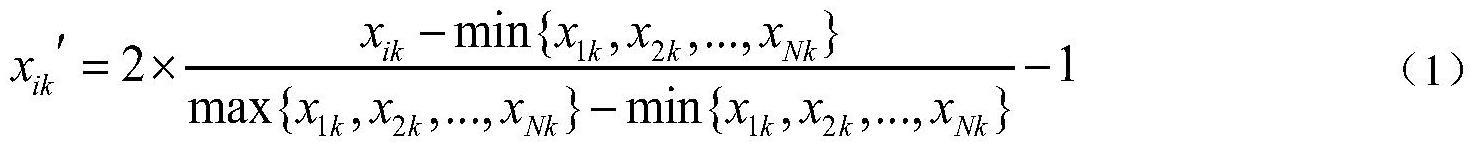
本发明属于无线通信中的网络自动驾驶,具体涉及适用于网络故障智能检测与恢复系统的中断检测方法。
背景技术:
1、无线网络越来越复杂,人工排除和恢复因小区中断而造成的故障成为不可行的任务。包含网络智能部署、网络智能优化、网络故障智能检测与恢复的网络自动驾驶是解决这些问题的关键技术。作为网络自动驾驶的重要组成部分,小区中断检测在网络故障智能检测与恢复技术中发挥着重要作用。目前基于机器学习的方法在小区中断检测中占主导地位。但在无线网络中,中断的发生是小概率事件,与中断相关的数据数量远少于正常数据。在这种情况下,基于机器学习方法的模型分类结果会偏向于多数类,中断检测性能会因为数据不平衡问题显著下降。此外,当网络中存在不止一种类型的中断时,不同类型的中断数据间往往会存在较严重的类间重合。类间重合是指数据集中多类数据混合分布在特征空间的同一区域的现象。这些样本虽然具有不同的类标签,但在特征上具有一定的相似性,会造成分类边界的失真,导致误分类现象的发生。
2、为了解决这些问题,现有研究引入了人工少数类过采样法(synthetic minorityoversampling technique,smote),自适应合成抽样技术(adaptive synthetic sampling,adasyn),生成对抗网络(generative adversarial network,gan)等方法对中断数据进行过采样,生成大量类中断数据,利用新的合成数据集提高基于机器学习方法的分类模型的准确性。然而,当数据不平衡的比例较大时,中断检测性能仍然有待提高。
3、本发明针对上述问题,提出了一种基于混合生成对抗网络的中断检测方法,该方法结合了混合gan和人工神经网络(artificial neural network,ann)的性能优势,解决了中断检测中的数据不平衡和数据类间重叠的问题,适用于实际的通信应用。
技术实现思路
1、技术问题:本发明的目的是提出一种基于混合生成对抗网络的无线网络中断检测方法,一方面通过混合gan对中断数据进行过采样生成平衡的合成数据集,另一方面利用合成数据集训练人工神经网络ann,得到适用于当前环境的中断检测分类模型。相较于传统分类方法以及数据过采样方法,本方法中断检测性能显著改善。
2、技术方案:本发明的基于混合生成对抗网络的无线网络中断检测方法包括如下步骤:
3、第一步:搜集无线通信系统关键性能指标kpi,并形成数据集x;
4、第二步:使用数据集x训练改进后的混合生成对抗网络cwgan-gp-ac,使网络能够对数据集x里的中断数据过采样,生成类中断数据,记录下能够生成中断数据的权重向量和偏置向量,cwgan-gp-ac由生成器g、判别器d和辅助分类器ac组成;
5、第三步:利用第二步中训练完成的混合生成对抗网络cwgan-gp-ac模型生成中断数据,组成数据平衡的数据集v;
6、第四步:计算数据平衡的数据集v中的样本权重;根据样本在特征空间中的位置确定其类间重叠程度并据此分配权重,权重大小不仅表征样本类间重叠程度,也代表样本在训练过程中的误分类成本;权重越大,样本类间重叠程度越低,误分类的概率也越低;
7、第五步:训练人工神经网络ann,获得中断检测模型;
8、第六步:直接将实时搜集到的基站kpi输入ann,进行中断检测;
9、将收集到的数据集x″输入ann网络,得到输出集合y′是对应的数据集预测的标签,如果y′∈{1,2,3},则判断为中断。
10、其中,
11、所述第一步:搜集无线通信系统关键性能指标kpi,并形成数据集x,具体为:
12、通过最小化路测方法mdt获取无线通信系统中时间t内用户上报的kpi信息,并形成数据集其中n为数据集x中元素个数,(xi,yi)是x中第i个元素,i=1,2,...,n;xi∈rk表示某个用户在某时刻上报的k维基站关键性能指标kpi信息,kpi具体包括块错误率bler、参考信号接收功率rsrp、参考信号接收质量rsrq、接收信号的强度指示rssi、吞吐量、信干噪比sinr;yi是xi的标签,表示服务该用户的基站的状态,基站状态分为正常和中断两类,中断基站又根据中断程度的不同被进一步分为轻度中断、中度中断和重度中断;因此,yi是一个一维变量,取值范围是yi∈{0,1,2,3};yi=0表示基站处于正常状态,此时接受到的kpi数值在正常范围内;yi=1表示基站处于轻度中断状态,此时接受到的kpi数值轻微超出正常范围,yi=2表示基站处于中度中断状态,基站性能下降严重,此时接受到的kpi数值远远超出正常范围;yi=3表示基站处于重度中断状态,此时接受到的kpi数值异常。
13、所述第二步包括以下流程:
14、步骤2.1,数据预处理:对数据集x进行最值归一化,使归一化后的数据集x′中收集到的kpi数据取值范围是[-1,1];
15、
16、xik′是归一化后的数据集x′中第i个元素的第k维kpi的取值;
17、步骤2.2,定义cwgan-gp-ac的目标函数,设置训练参数,
18、cwgan-gp-ac的目标函数如下所示:
19、
20、其中x′是步骤2.1中经过数据预处理后的用户上报的kpi数据集x′中的样本,z是满足随机噪声分布pz(z)中的噪声样本,g(z)是当输入噪声样本z时生成器输出,d(x)是当输入数据样本x时判别器的输出;是在噪声样本和生成器生成的假样本之间的区域随机分布的变量,定义为
21、
22、其中ac(g(z))是输入生成器生成的假样本g(z)时辅助分类器的输出,辅助分类器仅用于判别是否中断,因此输出预测标签和生成器生成的假样本的标签,bce定义了假样本的标签与辅助分类器ac预测标签之间的二元交叉熵,定义为
23、
24、其中(qi,yi)是生成器的输出的假样本数据及标签,y′i是假样本的标签,如果yi∈{0},则y′i=0,如果yi∈{1,2,3},则y′i=1;p(y′i)是辅助分类器预测假样本数据qi的标签,如果预测qi为正常数据,则p(y′i)=0,如果预测qi为中断数据,则p(y′i)=1;λ是梯度惩罚系数,当惩罚系数过大,会导致模型过于简单而无法充分拟合输入,反之会导致模型过于自由而产生高复杂度,因此其取值交叉验证方法决定;辅助分类器ac的的缩放因子δ会不断更新,保持为d(g(z))绝对值的10%,以确保生成器的主要目标是减少wasserstein损失;
25、设置后续模型训练所需参数:每次生成器进行迭代时判别器的最大迭代次数ncritic,其取值由实验经验决定;批量大小c,其取值由实验经验决定;进化符号动量优化器的学习率α、衰减速率β1和β2其取值由实验动态调整决定;每轮训练中采样的样本个数m,其取值由实验决定;模型最大迭代次数e,其取值由实验经验决定;模型的迭代次数e=0;模型的批量次数cnow=0;判别器的迭代次数ncriticnow=0;
26、采取高斯分布来初始化cwgan-gp-ac模型中生成器g、判别器d权重矩阵wg,wd,并将偏置向量bg、bd的初始值设置为0;
27、步骤2.3,抽样真实中断数据并生成对应的随机噪声;
28、根据数据集x′中样本标签将x′划分为四个子集:x′0,x′1,x′2,x′3;其中,子集x′0中元素是yi=0的数据样本,代表正常数据;子集x′1,x′2,x′3中的元素是标签分别为1,2,3的样本,分别代表一种中断类型数据;任意抽取子集x′1,x′2,x′3中的m个元素构成中断数据集合从服从标准正态分布的k维随机噪声z中采样m个噪声元素,m的取值由实验决定,构成集合将编号i相同的集合x′outage中的(xi′,yi)和集合z中的zi对应并结合,即对每一个噪声样本zi,添加编号相同的(xi′,yi)样本中的标签yi,得到元素(zi,yi),得到新的带标签的噪声样本集合
29、步骤2.4,训练判别器d以及辅助分类器ac,
30、将标签噪声集合输入生成器g,生成伪中断数据集合o中的标签yi和集合z′中的一一对应,取在0到1上均匀分布的随机数γ~u[0,1],定义
31、oi′=γoi+(1-γ)zi (5)
32、得到新的伪中断数据集合将新的伪中断数据集合o′和真实中断数据集合z′输入判别器d和辅助分类器ac,判别器d对集合o′和集合z′进行判别,输出预测标签,辅助分类器ac只对集合o′进行中断预测,输出第二步中定义的标签;使用带梯度惩罚项的梯度下降方法最大化式(2),更新判别器参数wd,bd,当前批量次数cnow=cnow+1;
33、步骤2.5,循环步骤2.3和2.4直到cnow=c
34、步骤2.6,使用进化符号动量(lion)优化器对流程(4)中使用的梯度下降方法的梯度进行更新,并令cnow=0,ncriticnow=ncriticnow+1;
35、步骤2.7,循环步骤2.3、2.4、2.5、2.6,直到判别器的迭代次数ncriticnow=ncritic;
36、步骤2.8,训练生成器g,
37、再次从服从标准正态分布的k维随机噪声z中采样和步骤2.3数量一样的m个噪声元素,构成集合将集合x′outage中的(xi′,yi)和集合中的编号相同的对应,构建新的标签噪声集合将标签噪声集合输入生成器g,使用带梯度惩罚项的梯度下降方法最小化式(2),更新生成器参数wg,bg,令模型迭代次数e=e+1,前批量次数cnow=0,判别器现在的迭代次数ncriticnow=0;循环步骤2.3、2.4、2.5、2.6、2.7、2.8,直至e=e;训练完成,记录生成器g,判别器d权重向量wg,wd和偏置向量bg,bd。
38、所述第三步具体为:从服从标准正态分布的k维随机噪声z中采样mv个噪声元素,其中mv=0.9n,构成集合因为只生成少数类的中断数据,所以随机生成取值为1,2,3的标签;随机生成标签信息将集合中的和集合中的编号相同的对应,构建新的标签噪声集合将标签噪声集合输入生成器g;生成中断数据集合中的标签和集合z′中的一一对应;将生成数据集和原始数据集合并,得到数据平衡的数据集v。
39、所述第四步计算平衡的数据集v中的样本权重,具体为:
40、对第三步得到的平衡数据集v中的每个样本v,首先根据公式(6),(7)选择k个距其最近的样本构成近邻集合neigh,其中||·||2表示向量的二范数
41、
42、neigh=neigh∪{vk} (7)
43、随后根据公式(8)计算vk的权重we
44、
45、其中表示集合neigh中标签与样本ve相同的样本总数,表示近邻个数,根据we值的不同,将样本划分为三类:we=1,代表位于安全区域的样本,其所有相邻样本均属于同一类别;0<we<1代表位于重叠区域的样本,其近邻中存在不同类别样本;we=0代表离群点,该样本的所有近邻样本都属于其它类别,对于离群点我们引入调整系数作为其权重,即we=β,按此操作遍历数据集中所有样本,计算权重,获得权重集合w。
46、所述第五步:训练人工神经网络ann,获得中断检测模型,具体为:
47、根据第三步得到的平衡数据集v和第四部得到的权重w确定ann的损失函数如公式(9)
48、
49、其中nv代表输入网络的数据集v的样本总数,we是权重集合w中的类间重叠指数,sign(ve,j)代表若样本ve的标签等于j,则取1,否则取0;μj代表输出层第j个神经元所对应的权重矩阵和偏倚向量,上标t代表转置,使用梯度下降方法求式(9)的极小值,获得ann网络的权重向量wann和偏置向量bann。
50、有益效果:本发明中提出的基于混合生成对抗网络的中断检测方法具有以下优势:相较于以前的过采样方法,本发明利用cwgan-gp的损失函数和辅助分类器提高了生成中断数据的质量,由此提升了中断检测准确性能。此外,本发明通过计算数据集中的样本类重叠指数并引入人工神经网络的训练中,解决了中断检测中的数据不平衡和数据类间重叠的问题。
- 还没有人留言评论。精彩留言会获得点赞!