直播间的歌曲领唱播放方法、装置及网络直播系统与流程
本技术涉及视频直播,特别是一种直播间的歌曲领唱播放方法、装置、网络直播系统、电子设备及计算机可读存储介质。
背景技术:
1、随着网络技术发展,网络直播已经得到大部分网络用户的使用,其中视频直播以其内容和形式的直观性、即时性和互动性,在促进灵活就业、促进经济社会发展、丰富人民群众精神文化生活等方面发挥了重要作用,主播可以在直播中更好地展现自己才艺才华,从而为更多主播实现了自我价值。
2、在直播平台的直播间中,主播可以通过演唱歌曲方式与观众进行互动,例如当前在直播间中较为流行的虚拟ktv互动模式,在k歌场景下,主播可以通过领唱方式带领观众进行唱歌,从而极大增强了主播与观众之间的互动性。常用技术中,在主播进行领唱时,一般是采用主播在歌曲文件伴奏下进行真实演唱的方式,但是当直播时间较长时对于主播负担较重影响直播效果,或者在一些特定时间段主播无法值守时,也会影响直播效果。
3、为了提升直播效果,在直播平台上也引入了ai人工智能技术来进行智能领唱,但是领唱效果与真实领唱之间存在较大差距,且可提供的演绎方式有限,导致观众无法获得真实性更高的演唱效果,降低了直播间的互动性。
技术实现思路
1、基于此,有必要提供一种直播间的歌曲领唱播放方法、装置、网络直播系统、电子设备及计算机可读存储介质,以提升领唱歌曲的真实性效果,提升直播间的互动性。
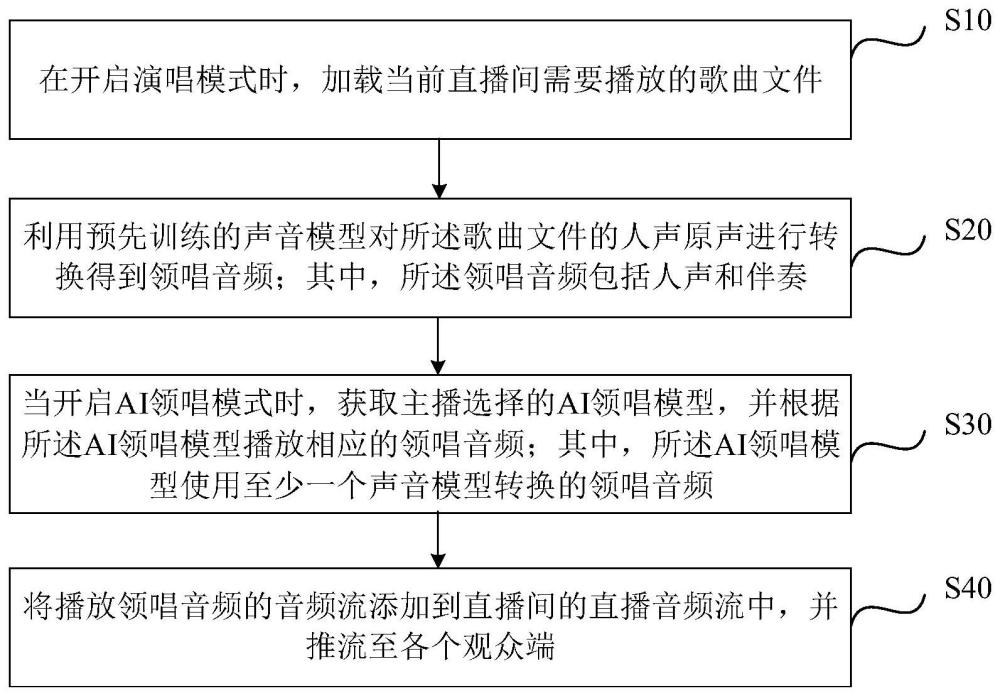
2、一种直播间的歌曲领唱播放方法,包括:
3、在开启演唱模式时,加载当前直播间需要播放的歌曲文件;
4、利用预先训练的声音模型对所述歌曲文件的人声原声进行转换得到领唱音频;其中,所述领唱音频包括人声和伴奏;
5、当开启ai领唱模式时,获取主播选择的ai领唱模型,并根据所述ai领唱模型播放相应的领唱音频;其中,所述ai领唱模型使用至少一个声音模型转换的领唱音频;
6、将播放领唱音频的音频流添加到直播间的直播音频流中,并推流至各个观众端。
7、在一个实施例中,所述利用预先训练的声音模型对所述歌曲文件的人声原声进行转换得到领唱音频,包括:
8、将所述歌曲文件的人声原声与伴奏进行分离;
9、将所述人声原声输入所述目标对象的声音模型得到内容与所述人声原声一致的所述目标对象的人声;
10、将所述目标对象的人声和歌曲文件的伴奏进行对齐得到领唱音频。
11、在一个实施例中,所述声音模型包括基于主播声音训练的模型;
12、所述根据所述ai领唱模型播放相应的领唱音频,包括:
13、根据所述ai领唱模型确定播放的领唱音频及其播放顺序,根据所述播放顺序依次播放各个领唱音频。
14、在一个实施例中,所述的直播间的歌曲领唱播放方法,在领唱过程中,还包括:
15、响应于主播触发的暂停指令,暂停播放领唱音频;
16、在暂停过程中接收主播输入的直播语音,并将直播语音添加到直播间的直播音频流中;以及
17、响应于主播触发的暂停指令,恢复播放领唱音频。
18、在一个实施例中,所述的直播间的歌曲领唱播放方法,在领唱过程中,还包括:
19、当主播端检测到麦克风输入的主播语音时,暂停播放领唱音频,并主播端上传的主播语音添加到直播间的直播音频流中;以及
20、当主播端检测到麦克风停止输入主播语音时,恢复播放领唱音频。
21、在一个实施例中,所述的直播间的歌曲领唱播放方法,在领唱过程中,还包括:
22、根据ai领唱模型的配置信息,播放相应的领唱音频的人声和伴奏;
23、在领唱过程中,根据主播预选的文案内容以及声音模型转换成语音内容,并根据时长将所述语音内容随机插入到领唱音频中;
24、在插入过程中,暂停播放所述领唱音频的人声,同步播放所述语音内容和伴奏。
25、在一个实施例中,所述声音模型还包括基于虚拟主播人声训练的模型;
26、所述根据所述ai领唱模型播放相应的领唱音频,还包括:
27、获取主播或者观众选择的虚拟主播以及歌曲文件,利用所述虚拟主播的声音模型对所述歌曲文件的人声原声进行转换得到领唱音频,播放该领唱音频。
28、在一个实施例中,所述的直播间的歌曲领唱播放方法,在领唱过程中,还包括:
29、监听用户进入直播间的消息;
30、当新用户进入直播间时,获取该新用户的用户信息,根据所述用户信息及欢迎信息生成欢迎语音;
31、暂停播放领唱音频的人声,并将所述欢迎语音插入到播放领唱音频的音频流中。
32、在一个实施例中,所述的直播间的歌曲领唱播放方法,还包括:
33、收集目标对象的干声数据;
34、提取所述干声数据的声音特征;
35、建立学习模型,并利用所述声音特征对所述学习模型进行训练,得到克隆所述目标对象的声音模型。
36、一种直播间的歌曲领唱播放装置,包括:
37、歌曲加载模块,用于在开启演唱模式时,加载当前直播间需要播放的歌曲文件;
38、声音转换模块,用于利用预先训练的声音模型对所述歌曲文件的人声原声进行转换得到领唱音频;其中,所述领唱音频包括人声和伴奏;
39、领唱播放模块,用于当开启ai领唱模式时,获取主播选择的ai领唱模型,并根据所述ai领唱模型播放相应的领唱音频;其中,所述ai领唱模型使用至少一个声音模型转换的领唱音频;
40、直播推流模块,用于将播放领唱音频的音频流添加到直播间的直播音频流中,并推流至各个观众端。
41、一种直播系统,包括:主播端、观众端以及直播服务器;其中,所述主播端和观众端分别通过通信网络连接至所述直播服务器;
42、所述主播端,用于接入直播间的主播以及采集主播直播视频流上传至直播服务器;
43、所述直播服务器,用于将主播的直播视频流转发至观众端,以及在领唱模式下,利用所述的直播间的歌曲领唱播放方法来播放直播间需要领唱的歌曲文件;
44、所述观众端,用于接入直播间的观众用户以及接收所述主播直播视频流进行播放。
45、一种电子设备,该电子设备,其包括:
46、一个或多个处理器;
47、存储器;
48、一个或多个应用程序,其中所述一个或多个应用程序被存储在所述存储器中并被配置为由所述一个或多个处理器执行,所述一个或多个程序配置用于执行所述的直播间的歌曲领唱播放方法的步骤。
49、一种计算机可读存储介质,所述存储介质存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或指令集由所述处理器加载并所述的直播间的歌曲领唱播放方法的步骤。
50、本技术的技术方案,主播在开启演唱模式时,加载当前直播间需要播放的歌曲文件;利用预先训练的声音模型对歌曲文件的人声原声进行转换得到领唱音频;当开启ai领唱模式时,获取主播选择的ai领唱模型来播放相应的领唱音频;将播放的音频流添加到直播间的直播音频流中进行推流。该技术方案,在直播间领唱中,利用声音模型进行声音克隆转换歌曲文件的人声原声,在直播间的演唱模式场景下引入ai领唱方式,可以实现接近于真实领唱的领唱效果,并且可提供多种演绎方式,观众可以获得真实性更高的演唱效果,增强了直播间的互动性,也提升了观众的听觉享受,提升直播间活跃度。
51、进一步的,通过预先训练的多个声音模型,主播可以建立个人的多种不同演唱风格,在领唱过程中也可以按需使用这些演唱风格,提升了领唱曲的真实性和互动性。
52、进一步的,在领唱过程中,主播通过指令方式可以暂停领唱,主播可以随时加入直播声音,实现半ai领唱效果,既可以释放主播的时间和压力,也可以使得主播始终掌握直播的主动权,增强了直播间互动效果。同时,还可以通过检测主播端的麦克风输入的主播语音方式来自动暂停ai领唱,减少主播触发指令操作,提升了直播效果,提升主播应用体验。
53、进一步的,根据ai领唱模型的配置信息,在领唱过程中,利用预选的文案内容转换成语音内容,在ai领唱过程中随机插入主播的其他语音元素,使得让整个ai领唱过程更加自然、真实,极大提升了直播间的互动性。
54、进一步的,基于虚拟主播人声训练的声音模型,利用虚拟主播的角色可以创作和表演全新的音乐作品,不受时间、空间和物理限制,在短时间内产生大量的音乐作品,并以独特的方式呈现和演绎,领唱的虚拟主播可以演唱多样性的歌曲,极大提升观众的听觉体验。
55、进一步的,在ai领唱过程中,当有新的观众进入直播间时,能够自主地,达到真实互动的直播效果,提升了主播与观众之间的互动性,增强了用户粘性,提升直播间活跃度。
- 还没有人留言评论。精彩留言会获得点赞!