一种基于对比学习的联邦少样本垃圾邮件检测方法及系统
本发明涉及计算机,具体地,涉及一种基于对比学习的联邦少样本垃圾邮件检测方法及系统。
背景技术:
1、电子邮件是当今流行的通讯手段,以垃圾邮件为主要形式的各类威胁不断出现。垃圾邮件往往以传播非法信息、广告营销、诈骗信息和高危附件等方式干扰邮箱的正常使用,甚至达到诈骗犯罪的目的。垃圾邮件的检测往往涉及用户隐私,针对特定人群发送的诈骗和钓鱼邮件,由于缺少典型样本而难以被模型学习。
2、联邦学习作为一种分布式训练方法,在模型的训练过程中无需交换用户数据而是交换模型参数,在联邦学习框架中,利用客户端数据在本地训练,中心服务器将各个客户端的训练参数聚合,能够保护用户隐私。用户谨慎于对数据的标注,通常难以获得数据的大量有效标签。因此少样本方法适用于类标签数较少的情况,因此本方法在联邦学习中引入了基于对比学习的少样本方法用于垃圾邮件的检测。
3、而申请号为201810799196.3的中国发明申请:《一种垃圾邮件识别方法及装置》,其技术方案具体为:获取目标邮件的头信息,调用邮件分类规则库,将头信息与该邮件分类规则库中的多个垃圾邮件规则分别进行比较;如果根据比较结果确定目标邮件不是垃圾邮件,则对目标邮件的正文进行特征提取,得到目标邮件的文本特征;调用第一邮件识别模型对目标邮件的文本特征进行识别,输出第一识别结果;根据第一识别结果,确定目标邮件是否为垃圾邮件。
4、相较于该发明申请,本发明申请通过仅上传部署在各个客户端的模型的参数到服务器,而敏感数据仅留存于本地的各个客户端,避免了用户隐私泄露的风险,避免了一般方案对用户隐私的侵犯;通过基于对比学习的少样本学习方案,模型无需大量带标签的数据即可实现垃圾邮件的准确分类,避免了由于客户端标记数据少而无法有效训练的问题,同时由于模型来自预训练模型的微调,各客户端间数据分布不平衡问题进而引发的模型不稳定等问题;通过联邦学习综合了各客户端的训练成果,在不侵犯用户隐私的情况下训练了具有良好泛化能力的垃圾邮件检测模型,提高了本地模型的检测性能。
技术实现思路
1、为解决现有技术垃圾邮件检测方法存在用户隐私易泄露,需用大量带标签样本训练模型才能获得较好的检测性能的问题,本发明提供了一种基于对比学习的联邦少样本垃圾邮件检测方法及系统,本发明采用的技术方案是:
2、本发明第一方面提供了一种基于对比学习的联邦少样本垃圾邮件检测方法,包括如下步骤:
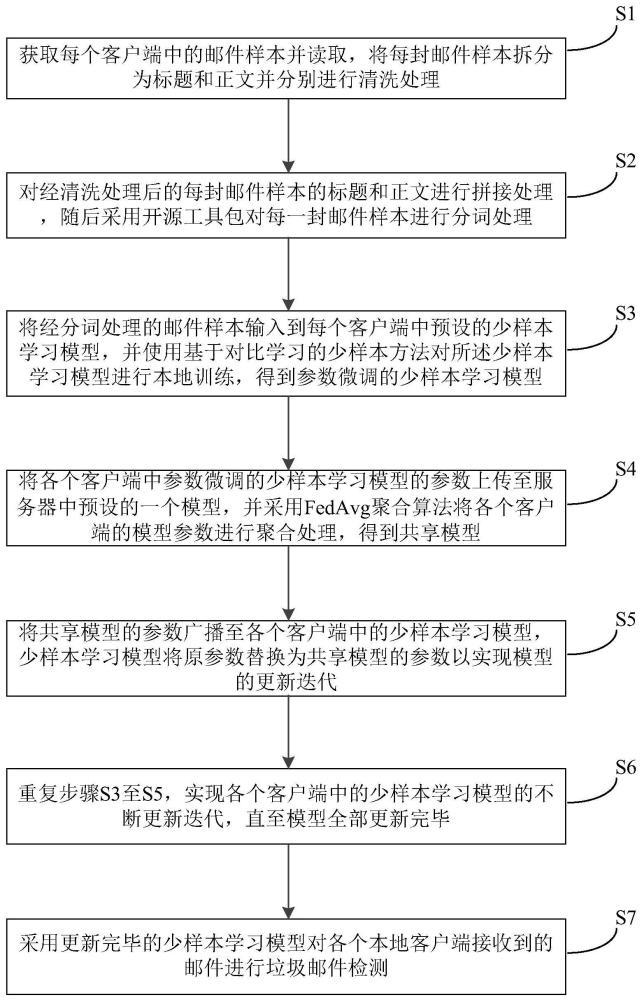
3、s1,获取每个客户端中的邮件样本并读取,将每封邮件样本拆分为标题和正文并分别进行清洗处理;
4、s2,对经清洗处理后的每封邮件样本的标题和正文进行拼接处理,随后对每一封邮件样本进行分词处理;
5、s3,将经分词处理的邮件样本输入到每个客户端中预设的少样本学习模型,并使用基于对比学习的少样本方法对所述少样本学习模型进行本地训练,得到参数微调的少样本学习模型;
6、s4,将各个客户端中参数微调的少样本学习模型的参数上传至服务器中预设的一个模型,并采用fedavg聚合算法将各个客户端的模型参数进行聚合处理,得到共享模型;
7、s5,将共享模型的参数广播至各个客户端中的少样本学习模型,少样本学习模型将原参数替换为共享模型的参数以实现模型的更新迭代;
8、s6,重复步骤s3至s5,实现各个客户端中的少样本学习模型的不断更新迭代,直至模型全部更新完毕;
9、s7,采用更新完毕的少样本学习模型对各个本地客户端接收到的邮件进行垃圾邮件检测。
10、相较于现有技术,本发明方法通过仅上传部署在各个客户端的模型的参数到服务器,而敏感数据仅留存于本地的各个客户端,避免了用户隐私泄露的风险,避免了对用户隐私的侵犯;通过基于对比学习的少样本学习方案,模型无需大量带标签的数据即可实现垃圾邮件的准确分类,避免了由于客户端标记数据少而无法有效训练的问题,同时由于模型来自预训练模型的微调,各客户端间数据分布不平衡问题进而引发的模型不稳定等问题。通过联邦学习综合了各客户端的训练成果,在不侵犯用户隐私的情况下训练了具有良好泛化能力的垃圾邮件检测模型,提高了本地模型的检测性能。
11、作为一种优选方案,在步骤s1中,获取每个客户端中的邮件样本并读取,将每封邮件样本拆分为标题和正文并分别进行清洗处理的方法具体包括以下步骤:
12、s11,从每个客户端中的html、eml文件获取邮件样本并读取;
13、s12,将邮件样本拆分为标题和正文,并对邮件样本中的邮件发送人信息、时间戳、标记符、特殊字符采用正则化的方法予以去除;
14、s13,对邮件样本中标题以及正文进行停顿字去除、英文单词的小写化、时态还原、前后缀去除处理。
15、作为一种优选方案,在步骤s2中,对经清洗处理后的每封邮件样本的标题和正文进行拼接处理,随后对每一封邮件样本进行分词处理的方法具体包括以下步骤:
16、s21,对经清洗处理后的每封邮件样本的标题和正文进行拼接处理;
17、s22,将拼接好的邮件样本分为单词和标记;
18、s23,对于每个单词或标记,统计其在所属的邮件样本中出现的频率;
19、s24,利用统计的频率信息生成一个概率分布,用该概率分布表示下一个最可能的子词;
20、s25,将当前单词或标记替换为其对应的子词序列;
21、s26,重复步骤s23至s25,直到处理完整个邮件样本。
22、作为一种优选方案,在步骤s3中,所述少样本学习模型包括孪生编码器网络和分类器,所述孪生编码器网络是由两个编码器形成的两端网络,两个编码器共享参数和权重。
23、作为一种优选方案,在步骤s3中,所述本地训练包括孪生编码器网络以及分类器的本地训练;
24、所述孪生编码器网络的本地训练具体包括以下步骤:
25、sa1,在训练过程中,在训练集中随机抽取两封邮件样本,形成三元组:{si,sj,label},其中si、sj是随机选择的两条样本,label用于表示si、sj是否为同一类的标签;当si、sj为同一类时,si、sj组成正样本对,label取值为1;当si、sj不为同一类时,si、sj组成负样本对,label取值为-1;
26、sa2,将样本对中的两封邮件样本si、sj分别输入到所述孪生编码器网络中的两个编码器中进行编码,得到两封邮件样本的嵌入向量;
27、sa3,计算两个嵌入向量之间的距离,根据label的取值调整编码器参数;
28、sa4,重复步骤sa1至sa3直至所述孪生编码器网络训练完毕,得到参数微调的孪生编码器网络;
29、所述分类器的本地训练具体包括以下步骤:
30、sb1,将训练集中的任意一封邮件样本输入到所述参数微调的孪生编码器网络中,由孪生编码器网络中的任意一个编码器编码生成一个嵌入向量,将该嵌入向量作为分类器的输入;
31、sb2,将步骤sb1中的嵌入向量输入到分类器后输出邮件样本对应的预测值,通过比较预设阈值与预测值对邮件样本进行分类,并根据邮件样本的类标签与预测值计算二元交叉熵损失函数,通过反向传播算法调整分类器的网络参数;
32、sb3,重复步骤sb1至sb2直至所述分类器训练完毕,得到参数微调的分类器。
33、作为一种优选方案,在步骤sa3中,计算两个嵌入向量之间的距离,根据label的取值调整编码器参数的方法具体为:
34、若label的取值为1,使两个嵌入向量之间的距离变近;
35、若label的取值为-1,使两个嵌入向量之间的距离变远;
36、嵌入向量之间的距离采用余弦相似度来衡量,其公式具体为:
37、
38、其中,v1,v2分别表示两个嵌入向量,yi表示两个嵌入向量对应的邮件样本是否为同一类,取1时为同一类邮件样本,-1时为非同一类邮件样本。
39、作为一种优选方案,在所述步骤sb2中,根据邮件样本的类标签与预测值计算二元交叉熵损失函数的计算式具体为:
40、
41、其中,n表示批大小,y表示邮件样本i的类标签,a为预测值。
42、作为一种优选方案,在步骤s7中,采用更新完毕的少样本学习模型对各个本地客户端接收到的邮件进行垃圾邮件检测的步骤具体包括:
43、在客户端中,获取邮件并读取,将每封邮件拆分为标题和正文并分别进行清洗处理;
44、对经清洗处理后的每封邮件的标题和正文进行拼接处理,随后对每一封邮件进行分词处理;
45、将经分词处理的邮件输入到更新完毕的少样本学习模型中;在更新完毕的少样本学习模型中,由孪生编码器网络中的任意一个编码器编码生成一个嵌入向量,将该嵌入向量输入到分类器进行分类,最后根据分类器的输出结果作为判断邮件是否为垃圾邮件的依据。
46、本发明第二方面提供了一种根据前述的一种基于对比学习的联邦少样本垃圾邮件检测方法的垃圾邮件检测系统,包括邮件清洗处理模块、邮件分词处理模块以及垃圾邮件检测模块;
47、所述邮件清洗处理模块用于在客户端中,获取邮件并读取,将每封邮件拆分为标题和正文并分别进行清洗处理;
48、所述邮件分词处理模块用于对经清洗处理后的每封邮件的标题和正文进行拼接处理,随后对每一封邮件进行分词处理;
49、所述垃圾邮件检测模块用于将经分词处理的邮件输入到更新完毕的少样本学习模型中;在更新完毕的少样本学习模型中,由孪生编码器网络中的任意一个编码器编码生成一个嵌入向量,将该嵌入向量输入到分类器进行分类,最后根据分类器的输出结果作为判断邮件是否为垃圾邮件的依据。
50、相较于现有技术,本发明具有的有益效果是:
51、1)本发明通过仅上传部署在各个客户端的少样本学习模型的参数到服务器,而敏感数据仅留存于本地的各个客户端,避免了用户隐私泄露的风险,避免了一般方案对用户隐私的侵犯。
52、2)本发明通过基于对比学习的少样本学习方案,少样本学习模型无需大量带标签的数据即可实现垃圾邮件的准确分类,避免了由于客户端标记数据少而无法有效训练的问题,同时由于模型来自预训练模型的微调,各客户端间数据分布不平衡问题进而引发的模型不稳定等问题。
53、3)本发明通过联邦学习综合了各客户端的训练成果,在不侵犯用户隐私的情况下训练了具有良好泛化能力的垃圾邮件检测模型,提高了本地模型的检测性能。
- 还没有人留言评论。精彩留言会获得点赞!