一种视频文件存储及搜索控制方法与流程
本发明涉及软件开发领域,尤其是涉及一种视频文件存储及搜索控制方法。
背景技术:
1、现有的视频存储方法,通常是在用户上传视频之前,根据用户客户端与多个服务器端的网络传输情况,或者根据服务器的负载情况,选取一个目标服务器,通过一个目标服务器与客户端建立通讯链路,通过通讯链路上传和下载视频文件。
2、例如,公开号为cn104469392a,公开了一种视频文件存储方法及装置。应用于内容分发网络cdn全局存储系统中的存储调度服务器,所述系统包括:至少一台存储调度服务器和多台存储服务器,所述方法包括:接收目标视频文件存储请求;根据预先记录的各存储服务器的启用时间,从所述系统中确定出启用时间最晚的存储服务器;根据预设的调用规则,从所确定的存储服务器中确定出一台存储服务器,并调用该存储服务器对目标视频文件进行存储。应用上述技术方案,当需要对某一段时间内的视频文件进行同步时,仅需去对应的几台存储服务器获取视频文件,然后进行同步,操作比较简单,效率较高。
3、上述方法依赖于一台存储调度服务器来决定存储目标文件的位置。如果这台存储调度服务器发生故障或停机,整个存储系统的可用性可能会受到影响。当需要对某一段时间内的视频文件进行同步时,只从一台存储服务器获取文件可能导致网络传输延迟,特别是在需要大量数据传输的情况下。这可能会影响视频文件的实时性。上述方法依赖于启用时间最晚的存储服务器,这可能导致存储服务器之间的负载不均衡。某些存储服务器可能会被频繁调用,而其他存储服务器可能很少被使用,从而浪费了资源。如果存储调度服务器选择的存储服务器在某些情况下并不是最佳选择,可能会导致数据的不必要复制和冗余存储。尤其对于高质量的视频文件其对应的视频容量较大,传输时长和传输效率会受限;
4、本背景技术所公开的上述信息仅仅用于增加对本发明背景技术的理解,因此,其可能包括不构成本领域普通技术人员已知的现有技术。
技术实现思路
1、为了解决现有技术中存在的问题,本发明提供一种视频文件存储及搜索控制方法。
2、本发明提供的一种视频文件存储及搜索控制方法采用如下的技术方案:
3、一种视频文件存储及搜索控制方法,包括以下步骤;
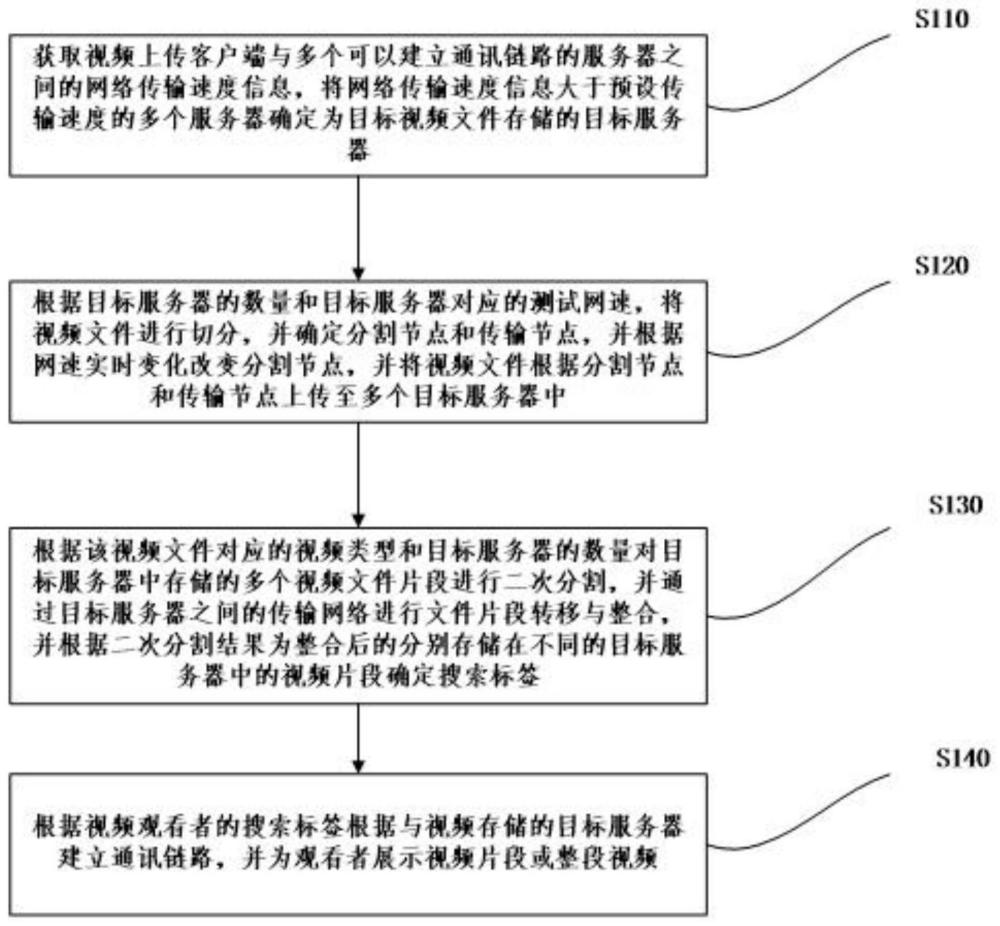
4、s110、获取视频上传客户端与多个可以建立通讯链路的服务器之间的网络传输速度信息,将网络传输速度信息大于预设传输速度的多个服务器确定为目标视频文件存储的目标服务器;
5、s120、根据目标服务器的数量和目标服务器对应的测试网速,将视频文件进行切分,并确定分割节点和传输节点,并根据网速实时变化改变分割节点,并将视频文件根据分割节点和传输节点上传至多个目标服务器中;
6、s130、根据该视频文件对应的视频类型和目标服务器的数量对目标服务器中存储的多个视频文件片段进行二次分割,并通过目标服务器之间的传输网络进行文件片段转移与整合,并根据二次分割结果为整合后的分别存储在不同的目标服务器中的视频片段确定搜索标签;
7、s140、根据视频观看者的搜索标签根据与视频存储的目标服务器建立通讯链路,并为观看者展示视频片段或整段视频。
8、优选的,所述步骤s110具体可以包括:
9、s1101、初始化设置:
10、定义预设的传输速度阈值;列出所有可用的服务器;
11、s1102、网络测速:
12、对每个服务器,客户端发送一个小文件并记录传输所需的时间;计算每个服务器的传输速度;
13、s1103、筛选目标服务器:
14、对于每个服务器,检查其传输速度是否高于预设的传输速度阈值;将传输速度高于阈值的服务器标记为目标服务器。
15、优选的,选择目标服务器可以通过下述代码实现:
16、
17、
18、优选的,所述步骤s120中的目标服务器包括4个,即将视频文件通过4个传输链路分别发送至4个目标服务器进行存储;
19、根据客户端的与不同目标服务器之间的数据传输速度确定分割节点,即传输速度越大对应的数据量也就越多;
20、第一部分数据为整个数据的头部数据传输节点位于头部;第四部分为整个数据的尾部数据,该部分的传输节点位于的尾部;而中间的部分数据的传输节点位于该部分数据对应的中部,间隔性地传输该传输节点靠近头部和靠近尾部的数据,基于此种设置可以根据实时的网络传输速度,动态调整分割节点,避免出现数据重复传递的现象。
21、优选的,针对不同类型的视频,可以制定不同的分割策略,以更好地满足各种视频类型的需求,以下是根据不同视频类型确定分割策略:
22、s1301、风景类视频分割策略:
23、风景视频通常以连续的自然景色为主题,较少有剧情和人物;分割策略可以基于场景切换或镜头变化来划分片段;可以根据视频中的景点特征来确定分割点,以便用户更容易找到感兴趣的场景;分割后的文件片段可以以地理位置、景点名称或景观特征为搜索标签;在风景类视频使用视频帧的差异来检测场景切换时通过计算相邻帧之间的差异度,如均方误差或结构相似性指数;如果差异超过预设阈值,可以将其视为场景切换点;
24、均方误差(mse)可通过如下公式计算:
25、
26、其中,i,j表示图像中的像素坐标,i(i,j)是原始图像中的像素值,i′(i,j)是对应位置的预测像素值,m和n分别是图像的宽度和高度;
27、结构相似性指数(ssim)可通过如下公式计算:
28、ssim=l(i,i').c(i,i').s(i,i')
29、其中l(i,i′)衡量亮度相似性,c(i,i′)衡量对比度相似性,s(i,i′)衡量结构相似性;
30、s1302、故事类视频分割策略:
31、故事类视频通常有清晰的情节和剧情发展;分割策略可以基于剧情事件、场景切换或对话交互来划分片段;可以在重要情节发生时切割视频,以便用户可以方便地找到故事情节的高潮部分;分割后的文件片段可以以关键情节或主要角色名称为搜索标签;对于故事类视频,可以使用自然语言处理技术来分析音频和字幕,以识别关键词、情感分析等,从而确定剧情事件发生的时刻;
32、s1303、人物记实类视频分割策略:
33、人物记实类视频通常侧重于展示特定人物或主题;分割策略可以基于人物出现、话题切换或时间段来划分片段;可以在不同人物出现或不同话题讨论时切割视频,以便用户可以按照特定人物或话题查找内容;分割后的文件片段可以以人物姓名、话题标签或时间标记为搜索标签;对于人物记实类视频,可以使用人脸检测算法来检测人物的出现和离开;例如,使用haar级联分类器或深度学习模型进行人脸检测;
34、对于分割节点前后对应的片段进行相似度检测,因为在视频文件传输到各个目标服务器的过程中是基于网速进行分割的,在第一次分割的过程中可能从在同一情节、同一人物的视频片段被分割到两个目标服务器存储,通过s130步骤的根据视频文件内容进行二次分割,如果发现在不同目标服务器中位于分割节点两侧的二次分割视频片段属于相同内容,需要对位于分割节点两侧的二次分割视频片段进行转移与整合,将相同内容的片段合并然后存储在同一个目标服务器中;
35、所述步骤s1302还包括;
36、s13021、音频和字幕提取;
37、s13022、文本预处理;
38、s13023、关键词提取;
39、s13024、情感分析;
40、s13025、剧情事件检测以及s13026、时间戳标记。
41、优选的,所述步骤s13021、音频和字幕提取首先从视频中提取音频和字幕数据;音频可以通过音频提取工具,如音频解码器,来获取,而字幕可以通过视频字幕提取工具来获得;功能代码如下:
42、
43、
44、优选的,所述s13022、文本预处理对字幕文本进行预处理,包括分词、去除停用词、标点符号和转换为小写;这有助于提高文本分析的准确性;功能代码如下:
45、import nltk
46、from nltk.corpus import stopwords
47、from nltk.tokenize import word_tokenize
48、import string
49、nltk.download('stopwords')
50、nltk.download('punkt')
51、#示例字幕文本
52、subtitle_text="this is an example subtitle text.it contains somewords and punctuation!"
53、#分词
54、words=word_tokenize(subtitle_text)
55、#去除停用词和标点符号
56、stop_words=set(stopwords.words('english'))
57、filtered_words=[word.lower()for word in words if word.lower()not instop_words and word not in string.punctuation]
58、#合并处理后的文本
59、processed_text="".join(filtered_words)
60、print(processed_text)。
61、优选的,所述s13023、关键词提取使用nlp技术,如tf-idf(词频-逆文档频率)或文本关键词抽取算法,来提取在文本中频繁出现的关键词;这些关键词可能与剧情事件相关;功能代码如下:
62、from sklearn.feature_extraction.text import tfidfvectorizer
63、#示例文本集
64、documents=["this is document 1.","this is document 2.","this isdocument 3."]
65、#创建tf-idf向量化器
66、tfidf_vectorizer=tfidfvectorizer()
67、#计算tf-idf权重
68、tfidf_matrix=tfidf_vectorizer.fit_transform(documents)
69、#获取关键词
70、feature_names=tfidf_vectorizer.get_feature_names_out()
71、max_tfidf=tfidf_matrix.max(0).toarray()[0]
72、sorted_keywords=[feature_names[i]for i in max_tfidf.argsort()[-5:]]
73、print(sorted_keywords)。
74、优选的,所述s13024、情感分析运用情感分析技术,nlp模型可以识别文本中的情感极性,如积极、消极或中性;这可以帮助确定剧情事件中的情感走向;
75、功能代码如下:
76、from textblob import textblob
77、#示例文本
78、text="this is a very good product.i love it!"
79、#创建textblob对象
80、blob=textblob(text)
81、#进行情感分析
82、sentiment=blob.sentiment
83、#打印情感分析结果
84、print("polarity(positive/negative):",sentiment.polarity)
85、print("subjectivity(objective/subjective):",sentiment.subjectivity)。
86、优选的,所述s13025、剧情事件检测基于提取的关键词和情感分析的结果,可以利用规则或机器学习模型来检测剧情事件;例如,如果某一段字幕中包含关键词"婚礼",并且情感分析显示积极情感,那么可以判断这是一个婚礼场景;功能代码如下:
87、from textblob import textblob
88、#示例文本
89、text="this is a very good product.i love it!"
90、#创建textblob对象
91、blob=textblob(text)
92、#进行情感分析
93、sentiment=blob.sentiment
94、#打印情感分析结果
95、print("polarity(positive/negative):",sentiment.polarity)
96、print("subjectivity(objective/subjective):",sentiment.subjectivity);
97、所述s13026、时间戳标记一旦剧情事件被检测出来,可以在视频时间轴上标记事件发生的时间戳,以便用户能够在视频中方便地找到这些事件;
98、功能代码如下:
99、#示例时间戳标记
100、event_timestamp="00:05:30"#事件发生在视频的5分30秒处
101、#在视频中跳到事件发生的时间点
102、video=videofileclip("video.mp4")
103、event_frame=video.get_frame(event_timestamp)
104、#显示事件发生的帧
105、event_frame.show()。
106、综上所述,本发明包括以下有益技术效果:
107、1.通过网络速度筛选和实时调整分割节点,提高了视频存储和传输的效率,减少了数据传输延迟。
108、2.采用不同分割策略,使观众能够根据视频类型更轻松地找到感兴趣的内容,提供了个性化的观看体验。通过nlp和情感分析,系统能够自动识别剧情事件,帮助观众找到视频的高潮部分,提高了观看体验。
109、3.根据视频内容的二次分割结果,自动生成搜索标签,减轻了用户手动标记的负担。
- 还没有人留言评论。精彩留言会获得点赞!