一种不同比特率下的HEVC视频双压缩检测方法
本发明涉及数字视频取证方法,具体涉及一种不同比特率下的hevc视频双压缩检测方法。
背景技术:
1、随着数字多媒体的日益普及和计算机与通信技术的迅猛发展,各类社交媒体和电子设备会产生海量的视频数据,通常情况下未经压缩视频的数据量庞大,因此为了节省网络传输时间和存储空间,通常会将其压缩成视频码流格式进行传输和存储。然而,一些不法分子常常利用各种视频编辑处理软件对这些视频进行篡改。具体来说,这些不法分子首先将视频码流解压成视频序列,随后进行一些解压缩域的篡改如帧删除、插入、目标对象的复制粘贴以及移除等篡改操作。最后将篡改后的视频再次压缩成视频码流文件。因此,被篡改的视频必然经历了二次压缩。研究人员可以通过二次压缩检测技术初步判断视频是否经过篡改。
2、比特率是视频压缩时最能体现视频质量的参数之一。通常情况下,人们认为高比特视频往往具有更高的视觉质量并占用更大的存储空间。因此,不法分子在篡改视频后往往选择使用高比特率对其再次压缩存储。然而,这种痕迹在解压缩域是很难发现的,尤其当插入和篡改的帧的痕迹十分轻微或经历精细的后处理后,常规的检测方法变得不再适用,在这种场景下,视频比特率的异常痕迹可以更好的检测篡改视频,因此有必要深入研究视频比特率上升所带来的异常痕迹。
3、近年来,随着深度学习发展,也涌现出了许多利用卷积神经网络实现hevc视频双压缩检测的方法。为了更进一步满足实际的使用需求,研究者们开始运用卷积神经网络来提供更准确和细粒度的检测结果,但现有的方法如果要实现帧级的检测,计算量将变得很庞大。与此同时,这些算法对于不同的编码参数设置也十分敏感。因此针对不同比特率下的hevc视频双压缩帧级检测计算量大和对不同编码参数鲁棒性差的问题,发明一种不同比特率下的hevc视频帧级双压缩检测具有十分重要的意义。
技术实现思路
1、本发明所要解决的问题是:提出一种不同比特率下的hevc视频双压缩检测方法,用于解决不同比特率下的hevc视频双压缩帧级检测计算量大和对不同编码参数鲁棒性差的问题。
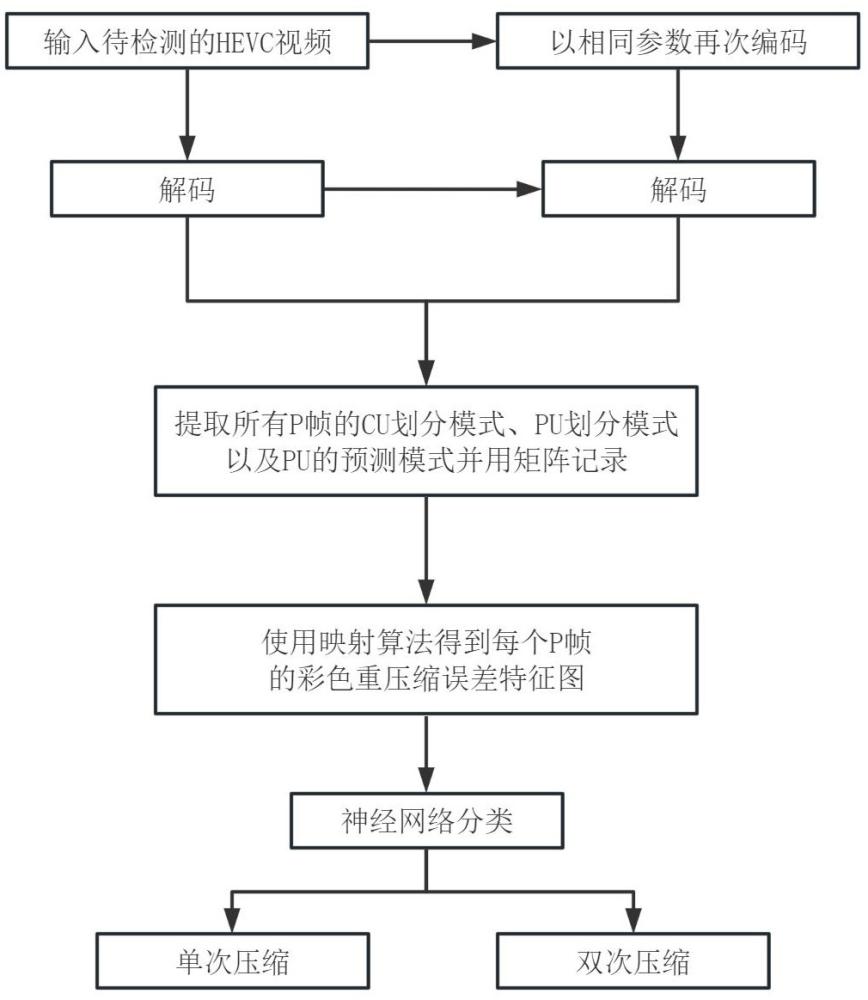
2、本发明采用如下技术方案:一种不同比特率下的hevc视频双压缩检测方法,针对待检测的hevc视频,执行如下步骤s1-步骤s4:
3、步骤s1、对输入的hevc视频进行解码,再用同样的参数对其进行二次压缩编码并解码,通过两次解码过程,提取hevc视频所有p帧的编码信息;
4、步骤s2、将步骤s1中的编码信息按照mpm映射算法得到编码信息矩阵,并通过vpm映射算法得到hevc视频每个p帧的彩色重压缩误差特征图;
5、步骤s3、将待检测的hevc视频每个p帧的彩色重压缩误差特征图,送入已经训练完成的卷积神经网络中,得到hevc视频帧级的分类结果;
6、步骤s4、通过投票策略得到gop级或视频级的hevc视频双压缩分类结果。
7、具体而言,步骤s1的具体步骤如下:
8、步骤s1.1、对输入的hevc视频使用hm解码器进行解码,提取hevc视频所有p帧的编码单元cu的划分模式、预测单元pu的划分模式以及预测单元pu的预测模式;
9、步骤s1.2、通过码流得到第一次编码的参数,用hevc编码器以相同的参数对hevc视频进行再次编码和解码,解码过程中再次提取hevc视频所有p帧的编码单元cu的划分模式、预测单元pu的划分模式以及预测单元pu的预测模式。
10、具体而言,步骤s2的具体步骤如下:
11、步骤s2.1、以pu最小单元为单位定义提取hevc视频所有p帧的编码信息,表示为cominfo;
12、步骤s2.2、用映射算法mpm以4*4的最小编码单元为单位,分别记录s1.1中所述的三种编码信息,得到相应的三个编码信息矩阵;
13、步骤s2.3、以同样参数再次编码和解码,得到第二次压缩后的三个编码信息矩阵,将两次解码得到的编码信息矩阵通过映射算法vpm得到三通道的彩色重压缩误差特征图。
14、具体而言,步骤s2.1中p帧的编码信息cominfo,表示如下:
15、cominfo=(pampu,pamcu,prmpu)
16、其中,pu的划分模式pampu∈{0,1,...,x},pampu为0时代表不进行pu划分,pampu为1,...,x时分别代表pu的七种划分模式,包括:2n×n、n×2n、n×n、2n×nu、2n×nd、nl×2n和nr×2n;
17、cu的划分模式pamcu∈{0,1,...,y},pamcu为0时代表不进行cu划分,pamcu为1,...,y时分别代表cu的四种划分模式,包括:64×64、32×32、16×16和8×8;
18、pu的预测模式prmpu∈{0,1,2,3},prmpu为0时代表帧内预测模式,prmpu为1,2,3时分别代表帧间预测的跳过skip、高级运动向量预测技术amvp、合并merge这三类运动矢量mv预测模式。
19、具体而言,步骤s2.3中所述映射算法,表示如下:
20、vpm=(infotype,var,val,lab)
21、其中、infotype∈cominfo,var∈{0,1}代表编码信息是否在第二次压缩中发生改变,val∈{0,1,...7}代表编码信息的值;lab∈{0,1,...15}是根据infotype、var和val得到的矩阵值。
22、具体而言,步骤s3的具体步骤如下:
23、步骤s3.1、选取原始yuv序列,使用比特率b1进行第一次压缩,得到单压缩的hevc视频,作为数据集中的正样本;
24、将单压缩的hevc视频解码后,使用比特率b2对其进行重新压缩,b2≠b1,得到对应的双压缩hevc视频,作为数据集中的负样本;
25、步骤s3.2、构造卷积神经网络,包括:残差卷积模块、下采样卷积模块与多头自注意力卷积模块;
26、步骤s3.3、使用步骤s2的方式,提取数据集中正负样本的彩色重压缩误差图,将其送入步骤s3.2构造的卷积神经网络进行训练,得到训练好的卷积神经网络分类器,在训练过程中,采用交叉熵损失来优化网络参数,具体如下所示:
27、
28、其中,m表示视频帧的数量,hi∈{0,1}表示模型对第i帧分类的结果,yi∈{0,1}表示了第i帧的真实标签值;
29、步骤s3.4:使用步骤s2的方式,提取待检测hevc视频的彩色重压缩误差图,输入步骤s3.3所述的训练好的卷积神经网络分类器,得到hevc视频帧级的分类结果。
30、具体而言,步骤s3.2中所述卷积神经网络,包括残差卷积模块、下采样卷积模块与resnet18设计相同,和多头自注意力卷积模块,构造卷积神经网络,方法包括:
31、s3.2.1、根据步骤s2.3构造的彩色重压缩误差特征图的特性,利用卷积核为2×2的卷积捕捉彩色重压缩误差特征图的浅层局部特征;
32、s3.2.2、使用连续多个残差卷积模块和下采样卷积模块的组合,在增加特征通道数量的同时压缩彩色重压缩误差特征图的大小,并不断建模和学习更复杂的特征特性;
33、s3.2.3、使用两个多头自注意力卷积模块,在深层次运用多头自注意力卷积mhsa,有效的减少运算量的同时更好的捕捉特征的全局结构;
34、s3.2.4、通过全局平均池化和全连接层得到帧级的分类结果。
35、具体而言,步骤s4的具体步骤如下:
36、通过多数投票策略获得n帧hevc视频的视频级结果,其中多数投票策略如下所示:
37、
38、其中,res表示投票后得到的结果,arg max(·)表示取最大值函数,lab∈{0,1}代表样本真实标签值,pren代表第n帧的分类结果,γ(·)是条件成立时取1,不成立取0的函数,==用于判断符号两侧的条件是否相等。
39、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
40、(1)本发明提出的不同比特率下的hevc视频双压缩检测方法实现了计算量较小的帧级别检测,并可以通过投票策略得到更灵活的结果。
41、(2)本发明提出的不同比特率下的hevc视频双压缩检测方法利用设计好的映射算法得到彩色重压缩误差图,可以更好的融合不同的编码信息,对不同编码参数具有鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!