一种基于动态的漏洞修复优先级排序方法及装置与流程
本发明涉及网络安全领域,具体是一种基于动态的漏洞修复优先级排序方法及装置。
背景技术:
1、近几年漏洞已经成为当前it领域的热门话题之一。首先,漏洞传播速度高速化。借助各大社区、社交平台,漏洞的传播速度惊人,早上披露的漏洞,到下午可能已经有了利用代码,到了晚上很多攻击可能已经发生;其次,漏洞数量越来越多。信息技术与人们的生活越来越近,五花八门的应用,海量的数据,技术在持续发展,应用在大面积推广,大量的漏洞正在影响着每一个人的生活。
2、当漏洞数量非常多,不能全部逐一修补的时候,传统的管理手段一般制定管理要求,希望在一定时间内漏洞的修复比例达到一定比例,比如90%,而这不能真正达到阻止攻击者成功攻击的目的,因为资源是有限的,如过不对修补工作进行优先级分析,了解需要优先修复哪些漏洞,就无法将有限的资源集中在对业务可能造成重大影响的漏洞处置上,从而无法快速减少业务风险。
技术实现思路
1、本发明的目的在于提供一种基于动态的漏洞修复优先级排序方法及装置,以解决上述问题。
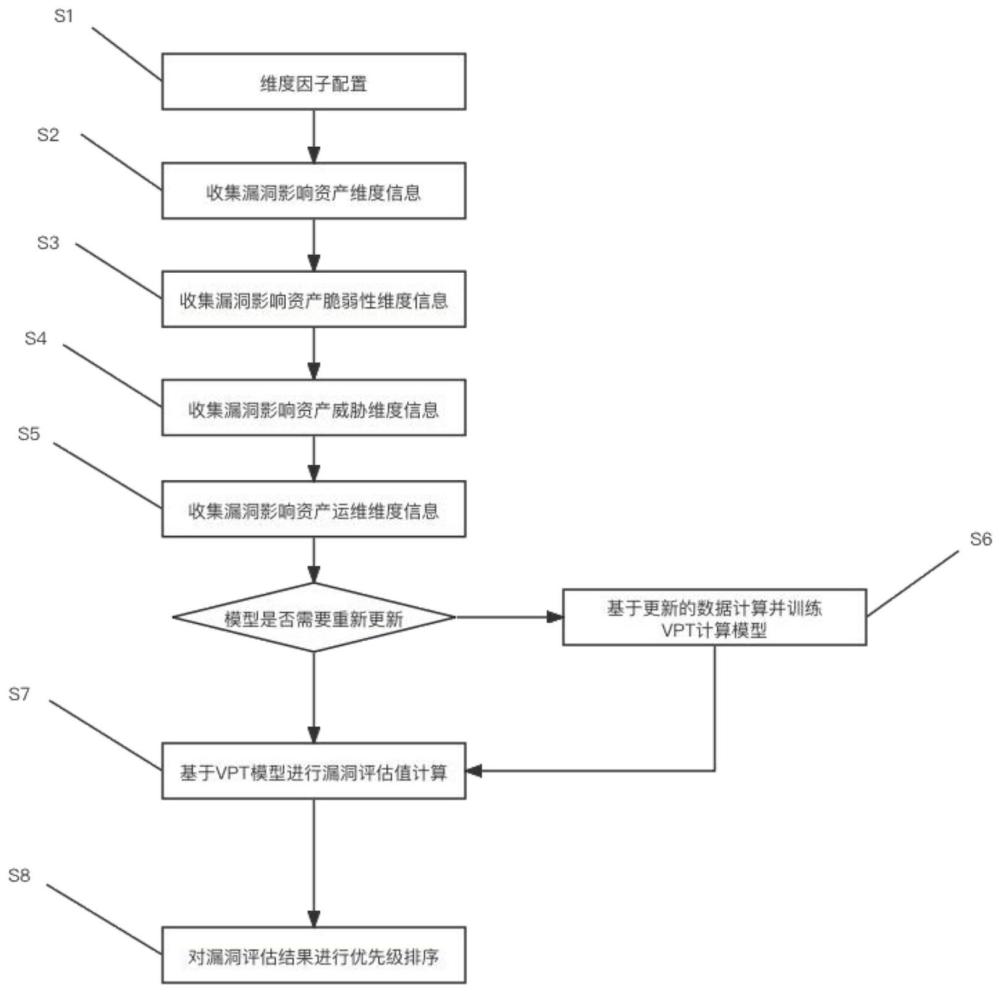
2、一种基于动态的漏洞修复优先级排序方法,包括:
3、配置影响漏洞的维度因子的基本权重以及相应维度因子的开关,所述维度因子包括资产因子、脆弱性因子、漏洞威胁因子、漏洞运维因子;
4、收集影响漏洞的维度因子对应的维度信息,所述维度信息包括资产维度信息、脆弱性维度信息、威胁维度信息、运维维度信息;
5、若需要对vpt漏洞排序计算模型进行更新,则基于更新的维度因子和维度信息训练vpt漏洞排序计算模型;
6、根据训练的vpt漏洞排序计算模型对漏洞信息进行评估计算,从漏洞的资产、脆弱性、威胁、运维4个维度计算漏洞评估值;
7、依据漏洞评估值将漏洞从高到低进行排序,输出最佳的漏洞修复排序优先级。
8、进一步的,所述资产维度信息包括资产重要性、资产位置、资产防护情况,得到基于资产维度数据集合,所述脆弱性维度信息包括漏洞脆弱性值、漏洞热度、交叉验证,得到基于漏洞脆弱性维度数据集合,所述威胁维度信息包括漏洞利用poc、漏洞利用方式、漏洞攻击成本,得到基于漏洞威胁维度数据集合,所述运维维度信息包括漏洞忽略比、恢复难易程度。
9、进一步的,所述vpt漏洞排序计算模型的计算步骤,具体包括:
10、数据准备和预处理:对收集的维度信息进行归一化处理,以确保不同因子的数据具有相似的范围;
11、特征工程:基于归一化处理后的维度信息创建特征向量x,其中每个元素对应一个漏洞样本的特征,特征向量xi=w*a,其中a为资产属性值,w为属性权重,特征向量x的构建如下:
12、x=[x1,x2,…xi,…,xn]
13、其中xi是特征向量中的第i个属性值;
14、使用有监督的随机森林算法来训练模型vpt漏洞排序计算模型;
15、使用加权平均算法将模型输出与随机森林算法的输出相结合,产生最终的漏洞修复优先级分数,使用以下公式进行:
16、vptfinal=(1-α)·vptrf+α·vptweighted_average
17、其中,vptfinal是最终的漏洞修复优先级分数,vptrf是随机森林算法的输出,ptweighted_average是加权平均算法的输出,α是调整权重的超参数。
18、进一步的,使用有监督的随机森林算法来训练模型vpt漏洞排序计算模型,具体包括:
19、从训练数据中有放回地随机选择n个样本作为训练数据集;
20、在构建每棵决策树时,对于每个节点从特征集中随机选择m个特征进行分裂,然后使用度量方法选择最佳特征进行分裂;
21、重复上述步骤,构建多棵决策树;
22、每棵决策树都有一个投票结果,最终的优先级评分基于多棵树的投票结果来确定。
23、一种基于动态的漏洞修复优先级排序装置,包括:
24、维度因子配置模块,用于配置影响漏洞的维度因子的基本权重以及相应维度因子的开关,所述维度因子包括资产因子、脆弱性因子、漏洞威胁因子、漏洞运维因子;
25、维度信息收集模块,用于收集影响漏洞的维度因子对应的维度信息,所述维度信息包括资产维度信息、脆弱性维度信息、威胁维度信息、运维维度信息;
26、模型更新训练模块,用于在需要对vpt漏洞排序计算模型进行更新时,则基于更新的维度因子和维度信息训练vpt漏洞排序计算模型;
27、评估计算模块,用于根据训练的vpt漏洞排序计算模型对漏洞信息进行评估计算,从漏洞的资产、脆弱性、威胁、运维4个维度计算漏洞评估值;
28、排序输出模块,用于依据漏洞评估值将漏洞从高到低进行排序,输出最佳的漏洞修复排序优先级。
29、进一步的,所述资产维度信息包括资产重要性、资产位置、资产防护情况,得到基于资产维度数据集合,所述脆弱性维度信息包括漏洞脆弱性值、漏洞热度、交叉验证,得到基于漏洞脆弱性维度数据集合,所述威胁维度信息包括漏洞利用poc、漏洞利用方式、漏洞攻击成本,得到基于漏洞威胁维度数据集合,所述运维维度信息包括漏洞忽略比、恢复难易程度。
30、进一步的,所述vpt漏洞排序计算模型的计算步骤,具体包括:
31、数据准备和预处理:对收集的维度信息进行归一化处理,以确保不同因子的数据具有相似的范围;
32、特征工程:基于归一化处理后的维度信息创建特征向量x,其中每个元素对应一个漏洞样本的特征,特征向量xi=w*a,其中a为资产属性值,w为属性权重,特征向量x的构建如下:
33、x=[x1,x2,…xi,…,xn]
34、其中xi是特征向量中的第i个属性值;
35、使用有监督的随机森林算法来训练模型vpt漏洞排序计算模型;
36、使用加权平均算法将模型输出与随机森林算法的输出相结合,产生最终的漏洞修复优先级分数,使用以下公式进行:
37、vptfinal=(1-α)·vptrf+α·vptweighted_average
38、其中,vptfinal是最终的漏洞修复优先级分数,vptrf是随机森林算法的输出,ptweighted_average是加权平均算法的输出,α是调整权重的超参数。
39、进一步的,使用有监督的随机森林算法来训练模型vpt漏洞排序计算模型,具体包括:
40、从训练数据中有放回地随机选择n个样本作为训练数据集;
41、在构建每棵决策树时,对于每个节点从特征集中随机选择m个特征进行分裂,然后使用度量方法选择最佳特征进行分裂;
42、重复上述步骤,构建多棵决策树;
43、每棵决策树都有一个投票结果,最终的优先级评分基于多棵树的投票结果来确定。
44、本发明通过从云端获取外部漏洞利用活跃度的情报,结合本地业务系统重要度,资产防护度等多种因素,综合评估,给出漏洞修复的优先级建议,并能根据单因素变更的情况动态更新,使修补工作效果达到最大程度降低安全风险的目的。
- 还没有人留言评论。精彩留言会获得点赞!