一种实时数据采集存储方法及系统与流程
本发明涉及数据处理,具体涉及一种实时数据采集存储方法及系统。
背景技术:
1、网络吞吐量指的是在一个网络连接中,在一定时间内传输的数据量或数据速率,是用来评估网络容量与性能的一个重要指标,通过网络吞吐量来确保数据能够以足够的速度和效率传输;其对于网络管理、性能监控和容量规划都非常关键,通过实时监控网络吞吐量网络能够满足实际需求。
2、而对于网络吞吐量数据,实时监控会导致数据产生大量冗余,因此需要对大量网络吞吐量数据进行压缩处理,通常情况下对网络吞吐量数据采用无损压缩或有损压缩的单一压缩方式,然而网络吞吐量数据存在不确定性,存在大量数据相近的情况时,无损压缩会导致压缩效果较差,不能有效降低存储空间的占用;而有损压缩又会造成部分网络吞吐量数据丢失,不利于网络吞吐量的实时采集与监控,因此需要对大量网络吞吐量数据进行聚类分析,通过不同类簇中网络吞吐量数据的相似性来对不同类簇自适应选择压缩方式,从而提高压缩效率的同时保证压缩后的数据质量。
技术实现思路
1、本发明提供一种实时数据采集存储方法及系统,以解决现有的网络数据由于不确定性而采用单一压缩方式导致数据丢失的问题,所采用的技术方案具体如下:
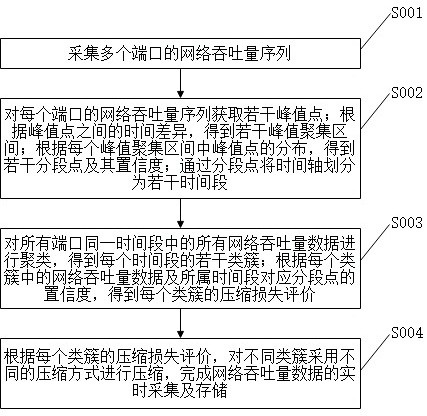
2、第一方面,本发明一个实施例提供了一种实时数据采集存储方法,该方法包括以下步骤:
3、采集多个端口的网络吞吐量序列,所述多个端口的网络吞吐量序列对应同一个时间轴,所述网络吞吐量序列中包含若干网络吞吐量数据;
4、对每个端口的网络吞吐量序列获取若干峰值点;根据峰值点之间的时间差异,得到若干峰值聚集区间;根据每个峰值聚集区间中峰值点的分布,得到若干分段点及其置信度;通过分段点将时间轴划分为若干时间段;
5、对所有端口同一时间段中的所有网络吞吐量数据进行聚类,得到每个时间段的若干类簇;根据每个类簇中的网络吞吐量数据及所属时间段对应分段点的置信度,得到每个类簇的压缩损失评价;
6、根据每个类簇的压缩损失评价,对不同类簇采用不同的压缩方式进行压缩。
7、进一步的,所述对每个端口的网络吞吐量序列获取若干峰值点,包括的具体方法为:
8、对于任意一个端口的网络吞吐量序列,以横坐标为时间,纵坐标为网络吞吐量序列中的网络吞吐量数据构建坐标系,将网络吞吐量序列中每个网络吞吐量数据转换为坐标系中的吞吐量数据点,连接得到该端口的网络吞吐量曲线,对网络吞吐量曲线通过ampd算法得到若干峰值点,记录每个峰值点对应的时间。
9、进一步的,所述得到若干峰值聚集区间,包括的具体方法为:
10、将所有端口的所有峰值点根据对应的时间顺序排列,得到峰值点序列;根据峰值点序列中相邻峰值点对应的时间,对每个峰值点的横坐标进行标记;
11、在横轴即时间轴上,从第一个有标记的横坐标开始,逐个横坐标进行遍历,预设一个聚集阈值,当遍历到第一个标记为1的横坐标时,统计该横坐标对应的峰值点的数量,若峰值点的数量大于或等于聚集阈值,将该横坐标作为一个峰值聚集区间的左端点,继续向后遍历,直到遍历到一个标记为0或没有标记的横坐标时停止,将停止时的横坐标的前一个横坐标,作为峰值聚集区间的右端点,得到一个峰值聚集区间,并继续向后遍历直到下一个标记为1的横坐标再开始判断;
12、若峰值点的数量小于聚集阈值,将该横坐标记为待选端点,记录该横坐标对应的峰值点的数量,继续向后遍历,若遍历到的下一个横坐标的标记为0或没有标记,删除记录的待选端点及记录的峰值点的数量,并继续向后遍历直到下一个标记为1的横坐标再开始判断;若遍历到的下一个横坐标的标记为1,统计当前遍历到的横坐标对应的峰值点的数量,并与已经记录的峰值点的数量获取和值,若和值大于或等于聚集阈值,将待选端点作为一个峰值聚集区间的左端点,继续向后遍历,直到遍历到一个标记为0或没有标记的横坐标时停止,将停止时的横坐标的前一个横坐标,作为峰值聚集区间的右端点,得到一个峰值聚集区间;若和值仍小于聚集阈值,继续遍历,若下一个横坐标没有标记或标记为0,删除记录的待选端点及记录的峰值点的数量,并继续向后遍历直到下一个标记为1的横坐标再开始判断;若下一个横坐标的标记为1,继续统计对应的峰值点的数量,并与和值再相加得到和值,对和值进行判断,以此类推得到峰值聚集区间;
13、对横坐标逐个遍历,最终得到若干峰值聚集区间。
14、进一步的,所述对每个峰值点的横坐标进行标记,包括的具体方法为:
15、对峰值点序列中相邻峰值点计算对应时间之间的差值绝对值,得到的差值绝对值记为相邻峰值点的时间差异;将所有时间差异从小到大升序排列,得到时间差异序列,对时间差异序列通过最大类间方差法进行分割,得到两个类别,将类别中时间差异的均值最小的类别作为峰值聚集类别,将类别中时间差异的均值最大的类别作为峰值离散类别;
16、对于峰值聚集类别,将峰值聚集类别中所有时间差异对应的峰值点的横坐标标记为1;对于峰值离散类别,将峰值离散类别中所有时间差异对应的峰值点的横坐标标记为0,若横坐标已经标记为1,不再对其进行0的标记;对所有峰值点的横坐标均进行0或1的标记。
17、进一步的,所述得到若干分段点及其置信度,包括的具体方法为:
18、对于任意一个峰值聚集区间,该峰值聚集区间中多个横坐标分别对应一个或多个峰值点,记为该峰值聚集区间中的峰值点,该峰值聚集区间中第个峰值点的优选程度的计算方法为:
19、
20、其中,表示该峰值聚集区间中第个峰值点与区间内其他峰值点的横坐标的差值绝对值的均值,表示该峰值聚集区间中峰值点的数量,表示该峰值聚集区间中第个峰值点的纵坐标,表示该峰值聚集区间中除第个峰值点之外第个峰值点的纵坐标,表示求绝对值,表示避免指数函数数值过小的超参数,表示以自然常数为底的指数函数;
21、根据峰值聚集区间内每个峰值点的优选程度,获取若干分段点及置信度。
22、进一步的,所述若干分段点及置信度,具体的获取方法为:
23、对于任意一个峰值聚集区间,获取该峰值聚集区间中每个峰值点的优选程度,将优选程度最大的峰值点的横坐标作为一个分段点,并将优选程度的最大值,作为分段点的置信度;将时间轴上第一个时间点及最后一个时间点作为分段点,置信度设置为1。
24、进一步的,所述得到每个时间段的若干类簇,包括的具体方法为:
25、对于任意一个时间段,获取横坐标在该时间段中的所有吞吐量数据点,对所有吞吐量数据点进行dbscan聚类,距离度量采用吞吐量数据点之间的欧式距离,得到若干类簇。
26、进一步的,所述得到每个类簇的压缩损失评价,包括的具体方法为:
27、对于任意一个类簇,通过凸包获取该类簇的包围区域,对包围区域获取外接圆,记为该类簇的最小外接圆,计算最小外接圆的面积,半径为圆心到圆上任意一个点的欧式距离;对该类簇中所有吞吐量数据点进行pca分析,得到若干主成分向量;该类簇的压缩损失评价的计算方法为:
28、
29、其中,表示该类簇所属时间段中左侧分段点的置信度,表示该类簇所属时间段中右侧分段点的置信度,表示该类簇中吞吐量数据点的数量,表示该类簇的最小外接圆的面积,表示该类簇的所有主成分向量的模长最大值,表示该类簇的所有主成分向量的模长最小值,表示求绝对值,表示避免指数函数数值过小的超参数,表示以自然常数为底的指数函数。
30、进一步的,所述对不同类簇采用不同的压缩方式进行压缩,包括的具体方法为:
31、预设一个损失阈值,若任意一个类簇的压缩损失评价大于或等于损失阈值,采用无损压缩方式;若任意一个类簇的压缩损失评价小于损失阈值,采用有损压缩方式,对该类簇中所有网络吞吐量数据获取均值,通过均值对该类簇中各网络吞吐量数据进行替换;
32、对每个类簇的压缩损失评价都进行判断,确定每个类簇的压缩方式,并对有损压缩的类簇进行替换,完成替换后再对所有类簇的所有网络吞吐量数据通过霍夫曼编码进行压缩。
33、第二方面,本发明另一个实施例提供了一种实时数据采集存储系统,该系统包括存储器、处理器以及存储在所述存储器中并在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述方法的步骤。
34、本发明的有益效果是:本发明通过对多个端口的网络吞吐量数据进行聚类分析,并对类簇根据其中吞吐量数据点的分布量化压缩损失评价,从而对类簇进行自适应的压缩,进而提高网络吞吐量数据的压缩效率的同时,保证压缩后的网络吞吐量数据的质量;其中首先对多个端口的网络吞吐量序列分别获取峰值点,并根据峰值点在时间轴上的聚集分布,得到分段点并对时间轴进行划分,从而得到多个时间段,保证各时间段内不同端口的网络吞吐量数据的变化趋势相近,进而提高类簇的准确性;再对每个时间段所包含的网络吞吐量数据进行聚类,得到类簇,并对类簇根据形状及分布进行分析,获取压缩损失评价并自适应选择压缩方式进行压缩,实现对网络吞吐量数据的实时采集及存储。
- 还没有人留言评论。精彩留言会获得点赞!