基于改进的预训练扩散模型的视频编辑方法
本发明属于视频生成,涉及一种视频编辑方法,具体涉及一种基于改进的预训练扩散模型的视频编辑方法,可应用于视频风格的转换、视频内容及背景的替换。
背景技术:
1、传统的视频编辑主要使用生成对抗网络gan在向量空间进行特征解耦,从而在改变一个特征的时候,不会影响另一个特征,然而gan存在训练不稳定、梯度消失、模式崩溃的问题。现在的视频编辑通常使用扩散模型对源视频进行加噪,在去噪采样的过程中引入编辑提示词,对源视频进行编辑,然而在仅使用编辑提示词对去噪采样过程进行引导时,训练的文本编码器能够编码的文本内容是有限的,无法用文本来描述具体的个体,或者无法使用文本编码器所能处理的描述范围外的文本。为了降低单一文本描述对编辑视频的帧一致性和美观性的影响,研发人员对引导扩散模型去噪采样的条件进行了改进,例如yuyangzhao在2023年5月15日年发表的论文make-a-protagonist:generic video editing withan ensemble of experts中,公开了一种基于文本图像引导的视频编辑方法,该方法使用多个专家模型对源视频、参考图像和编辑提示词进行解析,结合基于文本图像的视频生成模型和基于掩码的去噪采样算法,实现编辑提示词和参考图像共同对源视频的编辑。该方法使用空间自注意力机制,在视频编辑时引入了空间信息,一定程度上提升了编辑视频的帧一致性,且引入了参考图像信息,对视频的主角进行更直观的描述,一定程度上提升了编辑视频的美观性;但其存在的缺陷在于计算空间自注意力时,每一个图像帧只与第一个图像帧和前一个图像帧进行耦合,在视频主角动作幅度较大时,无法提供足够的空间指导,导致编辑视频的帧一致性仍然较差,且在去噪的过程中,损害了一些高频特征信息,导致编辑视频的美观性仍然较差。
技术实现思路
1、本发明的目的在于克服上述现有技术存在的缺陷,提出了一种基于改进的预训练扩散模型的视频编辑方法,旨在提高编辑视频的帧一致性和美观性。
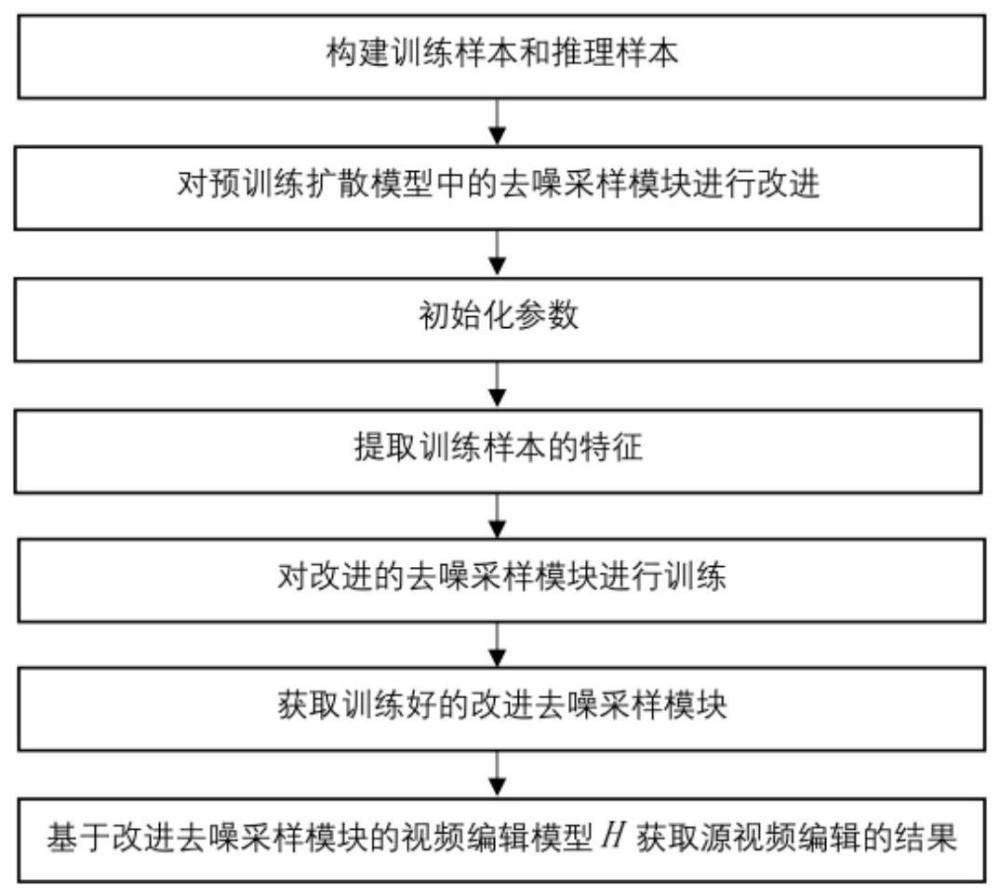
2、为实现上述目的,本发明采取的技术方案包括如下步骤:
3、(1)构建训练样本和推理样本:
4、构建包括n个图像帧的源视频及其描述和参考图像的训练样本r1,以及包括n个图像帧的源视频及其编辑提示词和参考图像的推理样本r2,n≥8;
5、(2)对预训练扩散模型中的去噪采样模块进行改进:
6、在预训练扩散模型所包含的去噪采样模块中每个卷积模块与交叉注意力模块之间加载空间自注意力模块,同时在去噪采样模块解码器端上采样模块和每个注意力上采样模块输入端加载频率优化模块,得到改进的去噪采样模块∈θ;其中,空间自注意力模块为残差结构,包括级联的归一化层、帧特征拼接模块和注意力计算模块;频率优化模块包括级联的快速傅里叶变换模块fft、低频特征缩小模块、逆快速傅里叶变换模块ifft和特征拼接模块,且特征拼接模块的输入端还加载有特征放大模块;
7、(3)初始化参数:
8、初始化迭代次数为s,最大迭代次数为s,s≥200,第s次迭代空间自注意力模块的权值参数为θs,并令s=1;
9、(4)提取训练样本的特征:
10、通过预训练扩散模型中级联的编码器ε和前向加噪模块根据时间步t提取源视频中的每个图像帧的噪声特征通过clip文本图像编码器提取描述的特征iprompt和参考图像的特征iimg,并将iprompt和iimg组成训练样本特征集;
11、(5)对改进的去噪采样模块进行训练:
12、将训练样本特征集和时间步t作为改进的去噪采样模块的输入,对噪声特征xvnt中加入的噪声进行估计,得到估计噪声
13、(6)获取训练好的改进去噪采样模块:
14、通过噪声对权值参数θs进行更新,得到本次迭代的改进去噪采样模块并判断s=s是否成立,若是,得到训练好的改进去噪采样模块∈θ*,否则,令s=s+1,并执行步骤(4);
15、(7)基于改进去噪采样模块的视频编辑模型h获取源视频编辑的结果:
16、构建基于改进去噪采样模块的视频编辑模型h,并将推理样本r2和时间步t′作为视频编辑模型h的输入进行推理,得到源视频的编辑视频
17、本发明与现有技术相比,具有以下优点:
18、(1)本发明通过在预训练扩散模型所包含的去噪采样模块中每个卷积模块与交叉注意力模块之间加载空间自注意力模块,同时在去噪采样模块解码器端上采样模块和每个注意力上采样模块输入端加载频率优化模块,得到改进的去噪采样模块,在对其进行训练以及获取源视频编辑结果的过程中,空间自注意力模块能够获取所有图像帧的空间特征,在视频主角动作幅度较大时,能为视频的编辑过程提供丰富的空间信息指导,与现有技术相比,有效提高了编辑视频的帧一致性。
19、(2)本发明采用的改进的去噪采样模块中包含有频率优化模块,得到改进的去噪采样模块,在对改进的去噪采样模块进行训练以及获取源视频编辑结果的过程中,频率优化模块将跳跃连接引入特征的低频特征缩小,相应的放大了高频特征,使得生成视频的纹理及边缘细节更好,与现有技术相比,有效提高了编辑视频的美观性。
技术特征:
1.一种基于改进的预训练扩散模型的视频编辑方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的方法,其特征在于,步骤(1)中所述的构建训练样本和推理样本,实现步骤为:
3.根据权利要求1所述的方法,其特征在于,步骤(2)中所述的预训练扩散模型,包括加载级联的编码器ε、前向加噪模块、结构为unet网络的去噪采样模块和解码器且编码器ε和去噪采样模块之间还加载有ddim反演模块,去噪采样模块输入端还加载有clip文本图像编码器,其中:
4.根据权利要求3所述的方法,其特征在于,步骤(4)中所述的时间步t,是指预训练扩散模型包含的前向加噪模块的加噪次数,其中,t∈[1,t1],t1表示最大加噪次数,t1≥1000。
5.根据权利要求4所述的方法,其特征在于,步骤(4)中所述的提取源视频中的每个图像帧的噪声特征实现步骤为:
6.根据权利要求5所述的方法,其特征在于,步骤(5)中所述的对改进的去噪采样模块∈θ进行训练,实现步骤为:
7.根据权利要求6所述的方法,其特征在于,步骤(6)中所述的通过噪声对权值参数为θs进行更新,更新公式为:
8.根据权利要求7所述的方法,其特征在于,步骤(7)中所述的基于改进去噪采样模块的视频编辑模型h,包括级联的预训练编码器ε、预训练ddim反演模块、特征融合模块、改进去噪采样模块∈θ*和预训练解码器其中特征融合模块的输入端还加载有并行连接的掩码分割单元和clip文本图像编码器,改进去噪采样模块∈θ*的输入端还加载有级联的控制信号提取单元和controlnet单元。
9.根据权利要求8所述的方法,其特征在于,步骤(7)中所述的将推理样本r2和时间步t′作为视频编辑模型h的输入进行推理,实现步骤为:
技术总结
本发明提出了一种基于改进的预训练扩散模型的视频编辑方法,实现步骤为:构建训练样本和推理样本;对预训练扩散模型中的去噪采样模块进行改进;初始化参数;提取训练样本的特征;对改进的去噪采样模块进行训练;获取训练好的改进去噪采样模块;基于改进去噪采样模块的视频编辑模型H获取源视频编辑的结果。本发明所构建的改进去噪采样模块,使用空间自注意力模块对噪声特征与所有N个图像帧特征的拼接特征进行耦合,充分利用图像帧的空间特征信息,提高了编辑视频的帧一致性,而且在解码器端对跳跃连接输入的特征进行低频特征缩小,相应的放大了高频特征,增加了纹理细节和边缘信息,有效的提升了编辑视频的美观性。
技术研发人员:宋彬,边梦洁,陈宸
受保护的技术使用者:西安电子科技大学
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!