基于人工智能技术的视频生成及处理方法与流程
本发明涉及视频生成及处理,具体为基于人工智能技术的视频生成及处理方法。
背景技术:
1、数字视频就是以数字形式记录的视频,和模拟视频相对的。数字视频有不同的产生方式,存储方式和播出方式。比如通过数字摄像机直接产生数字视频信号,存储在数字带,p2卡,蓝光盘或者磁盘上,从而得到不同格式的数字视频。然后通过pc,特定的播放器等播放出来。
2、现有的数字视频在生成时需要将视频文件与音频文件进行组合,而在组合的过程中,因为音频时间线和视频的时间线可能存在误差,导致最后生成的视频出现音画不同步的情况,且在过大的视频在进行生成时对设备的要求也特别高。
技术实现思路
1、本发明的目的在于提供基于人工智能技术的视频生成及处理方法,以解决上述背景技术中提出的现有的数字视频在生成时需要将视频文件与音频文件进行组合,而在组合的过程中,因为音频时间线和视频的时间线可能存在误差,导致最后生成的视频出现音画不同步的情况,且在过大的视频在进行生成时对设备的要求也特别高的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、基于人工智能技术的视频生成方法,具体包括以下步骤:
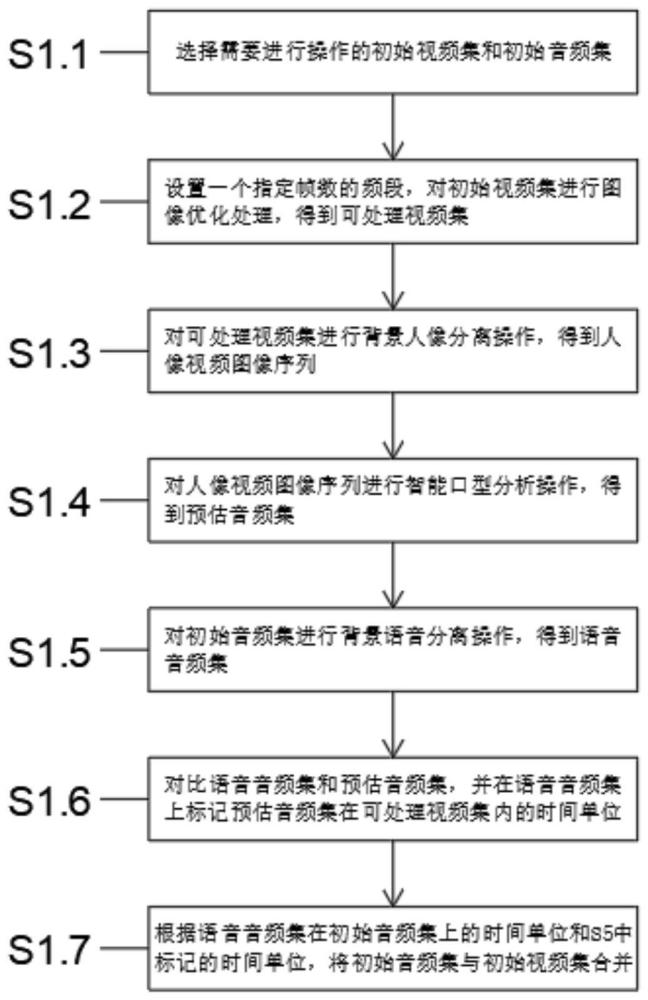
4、s1.1、选择需要进行操作的初始视频集和初始音频集;
5、s1.2、设置一个指定帧数的频段,将初始视频集按照设置的频段进行分隔,然后对初始视频进行图像优化处理,得到可处理视频集;
6、s1.3、对可处理视频集进行背景人像分离操作,得到人像视频图像序列;
7、s1.4、对人像视频图像序列进行智能口型分析操作,得到预估音频集;
8、s1.5、对初始音频集进行背景语音分离操作,得到语音音频集;
9、s1.6、对比语音音频集和预估音频集,并在语音音频集上标记预估音频集在可处理视频集内的时间单位;
10、s1.7、根据语音音频集在初始音频集上的时间单位和s1.5中标记的时间单位,将初始音频集与初始视频集合并,即得到初始完整视频集。
11、作为本发明的一种优选方案:所述人像视频图像序列在分离完成后,同步标记出人像视频图像序列在初始视频集中的时间单位,所述预估音频集在生成完成后,同步将人像视频图像序列的时间单位覆盖在预估音频集上,得到预估音频集对应在初始视频集中的时间单位。
12、作为本发明的一种优选方案:所述语音音频集在分离完成后,同步标记语音音频集在初始音频集上的时间单位,所述语音音频集分离完成后的背景音频集同步保留,用于进行纠错操作。
13、作为本发明的一种优选方案:所述语音音频集和预估音频集的对比过程具体包括以下步骤:
14、s1.6.1、通过语音识别技术对语音音频集和预估音频集进行语音文字识别操作,得到语音音频文字集和预估音频文字集;
15、s1.6.2、通过频率分析技术对语音音频集和预估音频集进行声音频率分析操作,得到语音音频频段集和预估音频频段集;
16、s1.6.3、将语音音频文字集与预估音频文字集和语音音频频段集和预估音频频段集进行全段相似度对比,当相似度高于95%时,则将预估音频文字集和预估音频频段集对应在初始视频集上的时间单位覆盖在语音音频文字集和语音音频频段集对应在初始音频集上的时间单位上。
17、作为本发明的一种优选方案:所述s1.6.3中在文字和频段的相似度均高于95%时,频段对比的结果优先级高于文字的优先级。
18、作为本发明的一种优选方案,基于人工智能技术的视频处理方法,具体包括以下步骤:
19、s2.1、将s1.7生成的完整视频片段进行拼接,得到初始完成视频集,并对每个拼接处进行标记;
20、s2.2、对拼接处进行卡顿和闪烁检查,并进行平滑处理;
21、s2.3、对s1.5中的语音音频集进行语音识别操作,得到视频文字包;
22、s2.4、将视频文字包做出字幕,并与语音音频集的时间单位保持一致,加入至初始完成视频集,得到预处理视频集;
23、s2.5、对预处理视频集进行图像缓冲、图像检测、图像缩放和清晰度优化操作,得到最终视频集。
24、作为本发明的一种优选方案:所述s2.3中的视频文字包包括中文文字包和英文文字包,所述字幕具备自动换行功能。
25、作为本发明的一种优选方案:所述s2.5中的图像缓冲将视频的分辨率调整至1920*1080,所述图像检测是对视频进行卡顿和敏感检测并进行修复。
26、作为本发明的一种优选方案:所述s2.5中的图像缩放是根据指定的缩放比例生成目标视频,所述s2.5中的清晰度优化是根据指定的清晰度要求,对视频进行优化操作。
27、与现有技术相比,本发明的有益效果是:
28、1、本发明通过对视频集进行人像提取的操作,降低了在智能口型分析过程中出现误差的几率,同时可以降低分析过程中的像素容量,降低分析模型的符合,进一步提高分析的准确率;
29、2、将分析得到的音频集和去除背景的音频集进行对比,在相似度高于95%时进行时间单位的替换,可以保证视频集的时间单位准确的贴入音频集,提高后续视频生成的准确率;
30、3、对视频集进行的平滑和辅助字幕添加操作,可以进一步提高视频的质量,提高观看者的体验。
技术特征:
1.基于人工智能技术的视频生成方法,其特征在于,具体包括以下步骤:
2.根据权利要求1所述的基于人工智能技术的视频生成方法,其特征在于:所述人像视频图像序列在分离完成后,同步标记出人像视频图像序列在初始视频集中的时间单位,所述预估音频集在生成完成后,同步将人像视频图像序列的时间单位覆盖在预估音频集上,得到预估音频集对应在初始视频集中的时间单位。
3.根据权利要求1所述的基于人工智能技术的视频生成方法,其特征在于:所述语音音频集在分离完成后,同步标记语音音频集在初始音频集上的时间单位,所述语音音频集分离完成后的背景音频集同步保留,用于进行纠错操作。
4.根据权利要求1所述的基于人工智能技术的视频生成及处理方法,其特征在于:所述语音音频集和预估音频集的对比过程具体包括以下步骤:
5.根据权利要求4所述的基于人工智能技术的视频生成及处理方法,其特征在于:所述s1.6.3中在文字和频段的相似度均高于95%时,频段对比的结果优先级高于文字的优先级。
6.根据权利要求1所述的基于人工智能技术的视频处理方法,其特征在于,具体包括以下步骤:
7.根据权利要求6所述的基于人工智能技术的视频处理方法,其特征在于:所述s2.3中的视频文字包包括中文文字包和英文文字包,所述字幕具备自动换行功能。
8.根据权利要求6所述的基于人工智能技术的视频处理方法,其特征在于:所述s2.5中的图像缓冲将视频的分辨率调整至1920*1080,所述图像检测是对视频进行卡顿和敏感检测并进行修复。
9.根据权利要求6所述的基于人工智能技术的视频处理方法,其特征在于:所述s2.5中的图像缩放是根据指定的缩放比例生成目标视频,所述s2.5中的清晰度优化是根据指定的清晰度要求,对视频进行优化操作。
技术总结
本发明公开了基于人工智能技术的视频生成及处理方法,通过背景人像的分离进行视频分隔,然后基于智能口型识别技术对人像视频集的口型进行分析,再对比口型分析结果和实际音频,将时间单位进行替换,合并后得到完整集,本发明的有益效果是:通过对视频集进行人像提取的操作,降低了在智能口型分析过程中出现误差的几率,同时可以降低分析过程中的像素容量,降低分析模型的符合,进一步提高分析的准确率,将分析得到的音频集和去除背景的音频集进行对比,在相似度高于95%时进行时间单位的替换,可以保证视频集的时间单位准确的贴入音频集,提高后续视频生成的准确率。
技术研发人员:陈嘉豪
受保护的技术使用者:晋城市锋潮网络科技有限公司
技术研发日:
技术公布日:2024/4/7
- 还没有人留言评论。精彩留言会获得点赞!