一种声场渲染方法和装置与流程
本发明涉及音频数字信号处理,特别是指一种声场渲染方法和装置。
背景技术:
1、空间音频的背景根植于人类对真实听觉体验的渴望,特别是随着数字媒体技术的进步,用户期待在家庭娱乐、虚拟现实和增强现实中得到更加身临其境的体验。立体声技术曾是家庭娱乐系统的标准配置,但它只提供了有限的方向感。进入数字时代,用户追求的是一个全方位的听觉环境,它可以精确地模拟声音在三维空间中的传播,包括高度和深度。
2、头戴式设备和外放扬声器阵列在提供空间音频体验方面有着本质的不同。头戴式设备,如耳机,通常利用头部相关传递函数(hrtf)和其他算法直接在听众的耳旁模拟声音来源的位置,可以非常精确地控制声音到达每只耳朵的时刻和方式,从而制造出一种虚拟的三维音频效果。这种个人化的体验非常适合单用户场景,如游戏和个人媒体播放。
3、相对于头戴式设备,外放扬声器阵列则是在一个开放的空间中创造三维声场,通过多个扬声器的精确放置和声音的合适处理,可以在不同的空间位置为多个用户同时提供三维音频体验。这需要考虑到房间的声学特性,扬声器的布局和听众的位置,是一种更加社交和共享的听觉体验。然而,这样的设置通常对环境有更高的要求,并且在渲染复杂声场时可能不如头戴式设备那样精确。
4、当前空间音频渲染方案主要使用头部相关传递函数(hrtf)来模拟人耳对于声音方向和距离的自然感知,它通过复杂的声学模型来重现声源在三维空间中的位置,这种技术在耳机和多声道扬声器系统中尤为常见。不过,hrtf的劣势在于它通常是基于平均化的人类耳朵和头部形状的测量数据,这意味着它不能完全适应每个独特的听众,因为个人间的生理差异可能会影响到最终的听觉体验,尤其是在精确定位声源位置时的准确性。
5、矢量基底振幅声相(vector base amplitude panning vbap)技术广泛应用于扬声器阵列中以渲染空间音频,它使用矢量数学来控制不同扬声器间的声音强度,从而在二维或三维空间中模拟声源的方位。尽管vbap能够在水平面或立体空间中有效地定位声源,但它在渲染声源远近,即声音深度的表现上并不突出。由于这一技术主要依赖于声音强度的变化来定位声源,而不是复杂的声学模型,它可能在传达声音源距离听众远近的感觉方面不如hrtf等更高级的三维音频处理技术。这个局限性在尝试创造一个全方位立体的声音场景时,可能会使得体验略显平面化,缺乏真实感。
6、波场合成(wave field synthesis wfs)和高阶环绕声(higher orderambisonics hoa)属于高级空间音频渲染技术。wfs通过大量排列的扬声器阵列产生连续的声波前沿,模拟真实的声场,而hoa则采用麦克风阵列和扬声器阵列通过复杂的数学算法精确地重建和渲染声场。这两种技术在模拟精细的空间声音位置和运动方面都非常先进,能够提供高度真实的听觉体验。然而,它们的劣势在于布局和成本;wfs需要大量的扬声器来精确控制声波,而hoa则需要高阶的麦克风和扬声器配置,且在非理想的听众位置可能无法获得最佳效果,限制了它们在商业和家庭环境中的普及。
7、简而言之,现有空间音频渲染技术在非专业环境中的应用存在局限性,特别是在使用任意扬声器阵列时根据用户的具体位置和头部朝向实时调整音频输出的时候,存在一系列的问题。
技术实现思路
1、为了解决现有空间音频渲染技术在非专业环境中的应用局限性,特别是在使用任意扬声器阵列时根据用户的具体位置和头部朝向实时调整音频输出的问题,本发明实施例提供了一种声场渲染方法及装置。所述技术方案如下:
2、一方面,提供了一种声场渲染方法,该方法由声场渲染设备实现,该方法包括:
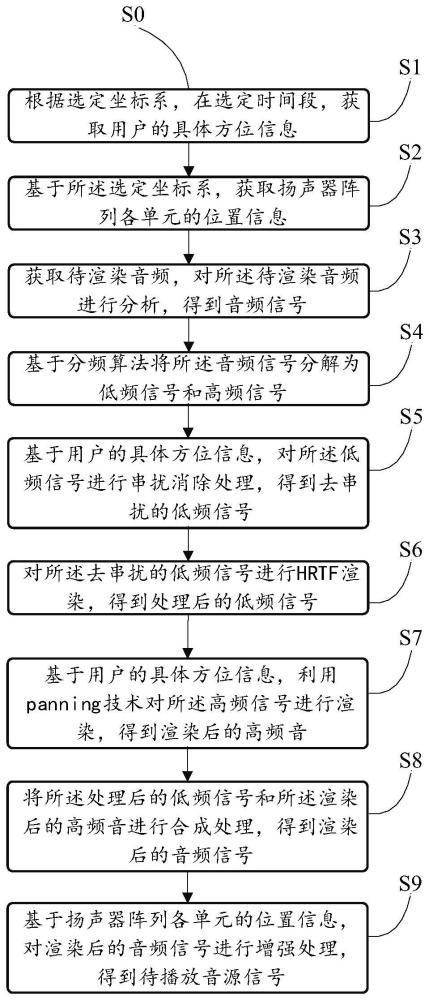
3、s1:根据选定坐标系,在选定时间段,获取用户的具体方位信息,所述用户的具体方位信息包含用户的在选定坐标系的具体位置信息和用户的头部朝向信息;
4、s2:基于所述选定坐标系,获取扬声器阵列各单元的位置信息;
5、s3:获取待渲染音频,对所述待渲染音频进行分析,得到音频信号;
6、s4:基于分频算法将所述音频信号分解为低频信号和高频信号;
7、s5:基于用户的具体方位信息,对所述低频信号进行串扰消除处理,得到去串扰的低频信号;
8、s6:对所述去串扰的低频信号进行hrtf渲染,得到处理后的低频信号;
9、s7:基于用户的具体方位信息,利用panning技术对所述高频信号进行渲染,得到渲染后的高频音;
10、s8:将所述处理后的低频信号和所述渲染后的高频音进行合成处理,得到渲染后的音频信号;
11、s9:基于扬声器阵列各单元的位置信息,对渲染后的音频信号进行增强处理,得到待播放音源信号。
12、优选地,所述s1的基于所述选定坐标系,获取扬声器阵列各单元的位置信息,包括:
13、s11:选定坐标系;
14、s12:通过传感器持续监测用户的在选定坐标系的位置信息和用户的头部朝向信息,得到用户的具体方位的实时数据;
15、s13:基于选定时间段,从用户的具体方位的实时数据获取用户的在选定坐标系的位置信息和用户的头部朝向信息;
16、s14:将用户的在选定坐标系的位置信息和用户的头部朝向信息合并得到用户的具体方位信息。
17、优选地,所述s4的基于分频算法将所述音频信号分解为低频信号和高频信号,包括:
18、s41:基于低通滤波器,对所述音频信号进行滤波操作,得到低频信号;
19、s42:基于高通滤波器,对所述音频信号进行滤波操作,得到高频信号。
20、优选地,所述s5的基于用户的具体方位信息,对所述低频信号进行串扰消除处理,得到去串扰的低频信号,包括:
21、s51:基于方向性滤波器,利用用户的在选定坐标系的位置信息建立空间滤波器模型;
22、s52:通过用户的在选定坐标系的位置信息和空间滤波器模型,估计用户引入的串扰信号,得到估计的串扰信号;
23、s53:采用串扰消除算法对估计的串扰信号进行消除,得到去串扰的低频信号。
24、优选地,所述s6的对所述去串扰的低频信号进行hrtf渲染,得到处理后的低频信号,包括:
25、s61:获取去串扰的低频信号和用户的头部朝向信息;
26、s62:根据用户的头部朝向信息选择适当的hrtf滤波器,所述选择适当的hrtf滤波器是通过hrtf数据库获取对应用户的头部朝向信息的hrtf数据;
27、s63:基于hrtf数据对去串扰的低频信号进行滤波,得到滤波后的低频信号;
28、s64:对滤波后的低频信号进行交叉耳延迟处理,得到处理后的低频信号。
29、优选地,所述s7的基于用户的具体方位信息,利用panning技术对所述高频信号进行渲染,得到渲染后的高频音,包括:
30、s71:创建立体声轨道,得到立体声轨道,并将所述高频信号导入到所述立体声轨道中,得到所述高频信号的左右声道的波形显示;
31、s72:根据panning参数,调整左右声道的波形显示的振幅比例,得到调整后的左右声道音频数据;
32、s73:合并调整后的左右声道音频数据,得到渲染后的高频信号。
33、优选地,所述s8的基于扬声器阵列各单元的位置信息,对渲染后的音频信号进行增强处理,得到待播放音源信号,包括:
34、s81:获取扬声器阵列各单元的位置信息;
35、s82:对渲染后的音频信号进行分析,确定目标音源的位置信息,并计算声源定位参数;
36、s83:根据声源定位参数,对渲染后的音频信号,进行声场增强处理得到待播放音源信号。
37、另一方面,提供了一种声场渲染装置,该装置应用于声场渲染方法,该装置包括:
38、具体方位模块:用于根据选定坐标系,在选定时间段,获取用户的具体方位信息,所述用户的具体方位信息包含用户的在选定坐标系的具体位置信息和用户的头部朝向信息;
39、位置信息模块:用于基于所述选定坐标系,获取扬声器阵列各单元的位置信息;
40、音频信号模块:用于获取待渲染音频,对所述待渲染音频进行分析,得到音频信号;
41、信号分解模块:用于基于分频算法将所述音频信号分解为低频信号和高频信号;
42、串扰消除模块:用于基于用户的具体方位信息,对所述低频信号进行串扰消除处理,得到去串扰的低频信号;
43、第一渲染模块:用于对所述去串扰的低频信号进行hrtf渲染,得到处理后的低频信号;
44、第二渲染模块:用于基于用户的具体方位信息,利用panning技术对所述高频信号进行渲染,得到渲染后的高频音;
45、合成模块:用于将所述处理后的低频信号和所述渲染后的高频音进行合成处理,得到渲染后的音频信号;
46、增强模块:用于基于扬声器阵列各单元的位置信息,对渲染后的音频信号进行增强处理,得到待播放音源信号。
47、另一方面,提供一种声场渲染设备,所述声场渲染设备包括:处理器;存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,实现如上述声场渲染方法中的任一项所述的方法。
48、另一方面,提供一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述声场渲染方法中的任一项所述的方法。
49、本发明实施例提供的技术方案带来的有益效果至少包括:
50、本发明实施例提供的技术方案能够实现高度逼真的声音渲染的系统,它能够动态地通过传感器识别和响应用户的位置变化,以及头部的朝向,从而在任何给定的环境中,无论扬声器的类型和布局如何,都能为用户提供一个准确的、定制化的听觉体验,确保用户在任何时刻都能听到最真实、最具沉浸感的声音。
51、具体来说,在音频渲染过程中,系统会实时跟踪用户的位置和头部朝向,并且考虑到扬声器的精确位置。系统首先对输入的音频进行分析。接着,音频信号通过分频器分解为低频和高频信号。低频信号利用其较长波长的优势,通过串扰消除技术和hrtf渲染进行处理,这样做因为低频信号较不受干扰,更易于控制。相对地,高频信号由于其方向性强,使用panning技术进行渲染,能够更精确地模拟声源位置的细微变化。在渲染过程中,系统通过传感器持续监测用户位置以及头部朝向以及扬声器布局的空间特性实时调整渲染算法。最后,综合低频和高频信号后,输出至扬声器,确保用户无论身处空间何处、头部如何朝向,都能享受到稳定一致的、高度真实和沉浸式的听觉体验。
- 还没有人留言评论。精彩留言会获得点赞!