基于贝叶斯算法的垃圾邮件识别方法与流程
本发明涉及网络信息处理,特别是一种基于贝叶斯算法的垃圾邮件识别方法。
背景技术:
1、贝叶斯算法是统计学的一种分类方法,它是一类利用概率统计知识进行分类的算法。朴素贝叶斯法(naive bayes model)是基于贝叶斯定理与特征条件独立假设的分类方法。朴素贝叶斯分类算法可以与决策树和神经网络分类算法相媲美,该算法能运用到大型数据库中,而且方法简单、分类准确率高、速度快。spam表示垃圾邮件,ham表示普通邮件。
2、目前大多数垃圾邮件识别引擎主要以预制在引擎中的垃圾邮件特征进行邮件的分类(spam/ham)。此方式需要根据大量垃圾邮件编写垃圾邮件特征,同时由于不同行业的邮件内容特征不同,因此还需要根据不同行业进行单独的垃圾邮件特征编写。为了保证垃圾邮件特征的准确率,必须定期更新垃圾邮件特征。导致垃圾邮件特征的开发和维护成本非常高。
3、文献1:中国专利cn201310683058.6公开了一种基于邮件特征和内容的垃圾邮件过滤方法,其中的分词虽然也是通过贝叶斯计算得到的,但是在现有技术方案中仅仅只对单个分词进行计算,在过滤过程中缺乏垃圾邮件判断依据,导致过滤精确度不稳定,同时单个分词数量较多,造成系统处理量大、整体运行慢,维护不便。
技术实现思路
1、本发明的目的在于提供一种基于贝叶斯算法的垃圾邮件识别方法,通过对样本邮件进行学习,利用计算出邮件对应的分类概率实现对引擎运行环境下的邮件分类,无需进行垃圾邮件特征的编写和定期维护,达到有效适用于不同场景的目的。
2、实现本发明目的的技术解决方案为:
3、一种基于贝叶斯算法的垃圾邮件识别方法,该识别方法包括:
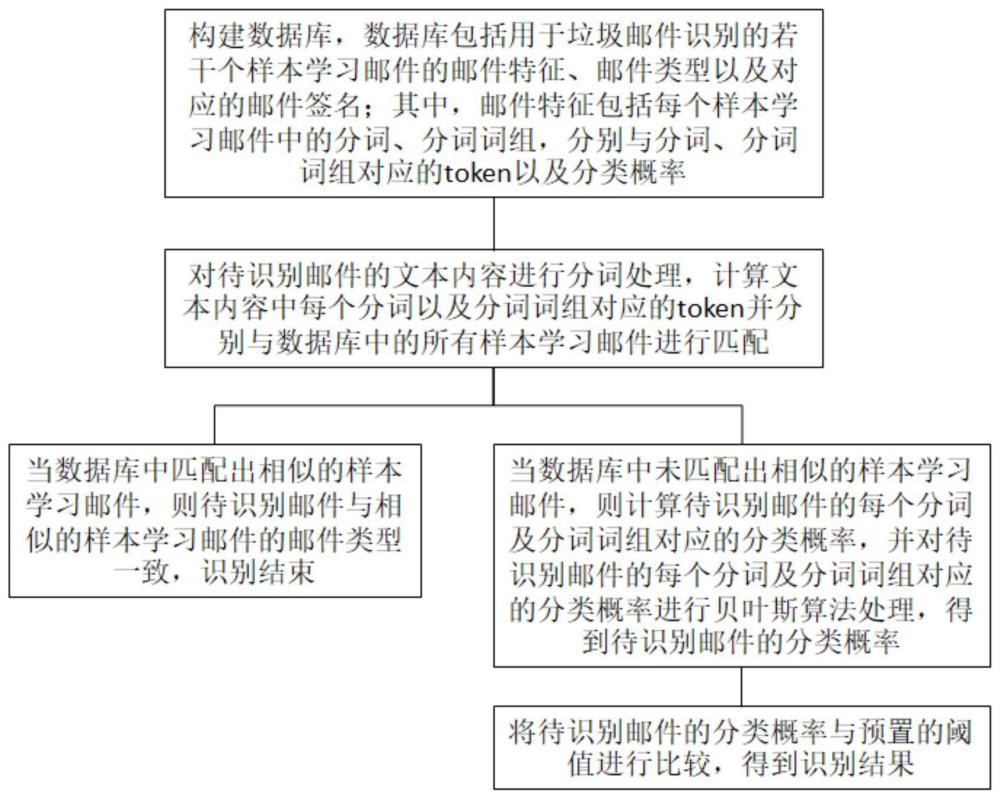
4、构建数据库,数据库包括用于垃圾邮件识别的若干个样本学习邮件的邮件特征、邮件类型以及对应的邮件签名;其中,邮件特征包括每个样本学习邮件中的分词、分词词组,分别与分词、分词词组对应的token以及分类概率;
5、对待识别邮件的文本内容进行分词处理,计算文本内容中每个分词以及分词词组对应的token并分别与数据库中的所有样本学习邮件进行匹配;
6、当数据库中匹配出相似的样本学习邮件,则待识别邮件与相似的样本学习邮件的邮件类型一致,识别结束;
7、当数据库中未匹配出相似的样本学习邮件,则计算待识别邮件的每个分词及分词词组对应的分类概率,并对待识别邮件的每个分词及分词词组对应的分类概率进行贝叶斯算法处理,得到待识别邮件的分类概率;
8、将待识别邮件的分类概率与预置的spam概率阈值进行比较,得到识别结果。
9、进一步的,分类概率包括spam概率和ham概率,贝叶斯算法处理的具体流程为:
10、分别计算出待识别邮件中每个分词对应的token,以及每个分词词组对应的token;
11、第一次查找和计算待识别邮件中每个分词对应的token在数据库中的分类概率;
12、第二次查找和计算待识别邮件中每个分词词组对应的token在数据库中的分类概率;
13、将第一次查找结果与第二次查找结果进行汇总,得到待识别邮件的分类概率。
14、进一步的,邮件类型包括垃圾邮件和普通邮件,当待识别邮件的分类概率超过预置的阈值时,待识别邮件为垃圾邮件,反之待识别邮件为普通邮件。
15、进一步的,文本内容包括待识别邮件的标题、正文和附件的文本类格式内容;
16、当待识别邮件的标题、正文和附件中至少有一项是非文本类格式内容时,先将非文本类格式内容转换成文本类格式内容,再对转换后的文本类格式内容进行归一化处理,生成待识别邮件的文本内容。
17、进一步的,归一化处理包括去除转换后的文本类格式内容中的无效符号、统一文本类格式内容中出现的英文字母的大小写格式以及统一文本类格式内容的文本编码。
18、进一步的,样本学习处理的具体流程为:
19、对样本学习邮件的文本内容进行分词处理,得到若干个分词;
20、按照每个分词的排序,以两个分词为一组进行分词组词,得到若干个分词词组;
21、根据每个分词以及分词词组的词间距离和样本邮件的类型,采用贝叶斯算法分别计算出每个分词对应的token和token在数据库中的spam概率和ham概率,以及每个分词词组对应的token和token在数据库中的spam概率和ham概率,得到样本学习邮件的分类概率,并生成样本学习邮件的邮件特征;其中,词间距离为两个不同分词之间存在的词数量;
22、将样本学习邮件的分类概率与预置的spam概率阈值进行比较,确定样本学习邮件的邮件类型;
23、采用md5运算方法求解出一个包含所有分词的哈希值,并将哈希值作为样本学习邮件的邮件签名,用于判断待识别邮件与样本学习邮件是否相似;
24、将样本学习邮件的邮件特征、邮件类型以及对应的邮件签名更新到数据库中,样本学习处理完毕。
25、进一步的,分词处理的具体流程为:
26、提取待识别邮件的文本内容中的纯英文部分和纯中文部分;
27、使用标点符号将纯中文部分的内容拆分成若干个语句,根据预置的dag词典对每个语句进行第一次分词,若出现dag词典中无记录的分词,则采用hmm模型和viterbi算法对剩余未成功分词的语句进行第二次分词;
28、使用空格符号将纯英文部分的内容按照英文单词进行分词。
29、一种垃圾邮件识别装置,该识别装置包括:
30、存储器,用于存储计算机程序;
31、处理器,用于执行计算机程序时实现如该识别方法的步骤。
32、一种计算机可读存储介质,该计算可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现如该识别方法的步骤。
33、本发明与现有技术相比,其显著优点是:
34、(1)本发明基于贝叶斯算法实现,可对其所处运行环境的大量样本邮件进行学习,生成邮件的分类概率,实现对邮件的分类(spam/ham);无需进行垃圾邮件特征的编写和定期维护,可应用性强,能够适用于不同场景。
35、(2)本发明通过http方式对外提供服务,完成邮件的样本学习和分类,兼顾与其他系统进行集成,从而提高了系统运行的性能,采用多进程方式,即可横向进行性能扩展,又不会增加系统的复杂度。
技术特征:
1.一种基于贝叶斯算法的垃圾邮件识别方法,其特征在于:所述识别方法包括:
2.根据权利要求1所述的基于贝叶斯算法的垃圾邮件识别方法,其特征在于:所述分类概率包括spam概率和ham概率,所述贝叶斯算法处理的具体流程为:
3.根据权利要求2所述的基于贝叶斯算法的垃圾邮件识别方法,其特征在于:所述邮件类型包括垃圾邮件和普通邮件,当待识别邮件的分类概率超过预置的阈值时,待识别邮件为垃圾邮件,反之待识别邮件为普通邮件。
4.根据权利要求1所述的基于贝叶斯算法的垃圾邮件识别方法,其特征在于:所述文本内容包括待识别邮件的标题、正文和附件的文本类格式内容;
5.根据权利要求1所述的基于贝叶斯算法的垃圾邮件识别方法,其特征在于:所述归一化处理包括去除转换后的文本类格式内容中的无效符号、统一文本类格式内容中出现的英文字母的大小写格式以及统一文本类格式内容的文本编码。
6.根据权利要求1所述的基于贝叶斯算法的垃圾邮件识别方法,其特征在于:所述样本学习处理的具体流程为:
7.根据权利要求1所述的基于贝叶斯算法的垃圾邮件识别方法,其特征在于:所述分词处理的具体流程为:
8.一种垃圾邮件识别装置,其特征在于:包括:
9.一种计算机可读存储介质,其特征在于:所述计算可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述基于贝叶斯算法的垃圾邮件识别方法的步骤。
技术总结
本发明涉及一种基于贝叶斯算法的垃圾邮件识别方法,该识别方法包括:构建数据库;对待识别邮件的文本内容进行分词处理,并分别与数据库中的所有样本学习邮件进行匹配;当匹配出相似的样本学习邮件,获取与相似的样本学习邮件的邮件类型,识别结束;当未匹配出相似的样本学习邮件,则计算待识别邮件的每个分词及分词词组对应的分类概率并进行贝叶斯算法处理,得到待识别邮件的分类概率;将待识别邮件的分类概率与预置的SPAM概率阈值进行比较,得到识别结果。本发明与现有技术相比,其显著优点是:本发明无需进行垃圾邮件特征的编写和定期维护,能够对其所处运行环境的大量样本邮件进行学习,实现对邮件的识别分类,可应用性强,适用于不同场景。
技术研发人员:关洪涛,刘军凯,谭航,张玉军,胡德强,侍从祥
受保护的技术使用者:江苏省未来网络创新研究院
技术研发日:
技术公布日:2024/3/31
- 还没有人留言评论。精彩留言会获得点赞!