一种基于深度强化学习的车联网混合路由方法
本发明涉及无线通信,具体说的是一种基于深度强化学习的车联网混合路由方法。
背景技术:
1、随着车辆数量的不断增长,越来越多的研究人员开始关注车联网(vanet)路由路径的优化。vanet路由协议的目标是在vanet环境中找到最优的转发路径,以实现高效的数据传输,从而保证vanet系统的稳定运行。然而,vanet通信技术在实际应用中仍然面临着各种挑战。例如,由于车辆的高速移动性,网络拓扑结构变化频繁;交通拥堵和天气条件也会导致车辆密度分布不均匀;十字路口的建筑物和无线电障碍物也会导致信号衰减问题。这些挑战可能会严重影响网络的通信质量,导致消息传输不稳定和效率低。因此,设计一个能够确保车辆节点之间高效通信的vanet路由协议至关重要。
2、由于vanet通信技术面临的各种挑战,传统的为manet设计的动态自适应路由协议不再适用于vanet的环境。随着机器学习技术的不断发展和进步,大量的研究人员已经开始探索使用机器学习技术来优化现有的路由协议。有作者提出了pfq-aodv模糊q学习技术来评估无线链路的质量和学习最合适的路径。有作者提出了q-grid路由协议,该协议将区域划分为网络格,并通过q学习计算给定目标相邻格之间不同运动模式的q值,但没有考虑交叉口和建筑物对各网格传输质量的影响。
3、由于车辆在交叉路口处的随机性,可能会导致传输性能的降低。最理想的数据分组转发策略是确定每个交通节点到目的地的最短路径,并使数据分组在每个路口沿最短路径传递,但这样的策略实际上并不完全可行。因此,近些年来,有研究人员考虑基于交叉路口的感知路由协议。感知路由协议可以减少车辆之间的冲突,提高交通效率,减少交通拥堵和碰撞事故的发生率。有文献提出qtar协议结合地理路由和静态道路地图信息,构建高可靠性路由路径。有文献提出rrin路由算法,通过设计两个q学习函数用于道路模型段选择(rmss)和中间车辆选择(ivs)。有文献提出了基于交叉路口的iv2xq协议,在交叉路口层,利用q学习算法对历史交通信息进行分析,以选择交叉路口之间的最佳路线,但是利用历史流量信息来学习网络环境可能造成路由延迟问题,依靠新的信息对于做出正确的路由决策是必不可少的。有文献提出的irq方法结合全局和局部视角,引入交通信息传播机制改善路由效果,旨在提高路由效率和通信质量、减少交通拥堵,但是对于交叉路口等复杂的交通环境,使用q学习算法可能无法选择最合适的转发道路,导致数据包丢失率的增加。根据以上分析,研究人员利用机器学习技术优化基于交叉路口的路由协议,旨在提高数据传输效率和稳定性。然而,随着车辆数量的增多,交通环境变得更加复杂,q学习算法的泛化能力与实时性逐渐降低,进而导致路由时延与数据包丢失率上升。
技术实现思路
1、为解决上述技术问题,本发明提供一种基于深度强化学习的车联网混合路由方法,提高了数据包的投递率及传输的可靠性。
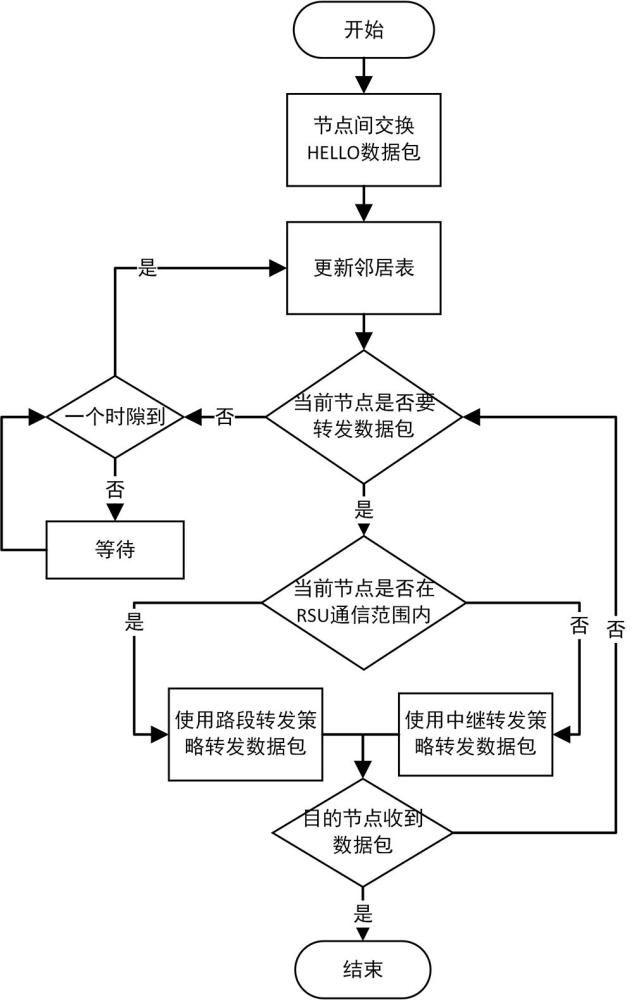
2、为实现上述目的,本发明所采用的技术方案是:一种基于深度强化学习的车联网混合路由方法,在道路的交叉路口设置用于通信的路边单元rsu,道路中需要通信的车辆为车联网中的节点,所述方法包括以下步骤:
3、步骤1,每个节点间定期交换hello数据包,更新邻居表;路边单元rsu收集路段上节点的交通状态信息,rsu中安装的边缘服务器同步该信息并对该信息进行数据预处理,中央服务器利用预处理后的信息进行ddqn训练,所述ddqn训练通过构建q网络进行,q网络包含评估网络和目标网络;
4、步骤2,当前节点vi需要转发数据包时,判断当前节点vi是否在路边单元rsu的通信范围内,若不在通信范围内,执行中继转发策略,通过构建q学习算法的动作值函数,更新迭代计算当前节点vi通过邻居节点到达目的节点的q值,选择q值最高的邻居节点作为新的当前节点;
5、若在通信范围内,执行路段转发策略,边缘服务器基于步骤1中ddqn训练的评估网络获得每个路段的q值,从中选择最大q值的路段作为最佳转发路段,通过rsu将数据包转发给最佳转发路段上的一个中继节点,将该中继节点作为新的当前节点,当目的节点接收到数据,结束整个路由过程,否则重新执行步骤2。
6、优选的,数据预处理包括以下步骤:
7、步骤1.1:计算一定长度的路段上的车辆密度公式如下:
8、
9、其中,是交叉路口ii到ij之间路段上的车辆数量,是路段长度;
10、步骤1.2:计算车辆连通性概率,n辆车在长度为l的路段上行驶的概率遵循泊松分布,两个相邻车辆之间的距离λ<rcom时,车辆的连通性概率计算公式如下:
11、
12、其中,是路段上车辆密度,rcom是车辆通信半径;
13、步骤1.3:计算路段上的平均负载,计算公式如下:
14、
15、其中,和分别是路段r在交叉路口ii收到和发送的数据包总数,和分别是路段r在交叉路口ij收到和发送的数据包总数。
16、优选的,ddqn训练包括以下步骤:
17、步骤1.4,通过当前状态下的评估网络预测评估网络下一个状态的q值,并选择q值最大的行动a’;
18、步骤1.5,根据评估网络选择的行动a’来更新目标网络的q值;
19、步骤1.6,根据更新后的目标网络q值计算目标q值,每隔一定的步数,将评估网络的权重复制到目标网络中,当目标q值和当前状态下评估网络的q值之间的误差函数值小于阈值0.01或达到预定的回合数,ddqn训练结束。
20、优选的,目标q值计算公式如下:
21、
22、其中,yddqn是目标q值,是即时奖励,γ是折扣因子,q(s',a',w')为评估网络,为目标网络,为评估网络在下一状态选择的最佳行为a’,s’是下一个状态,a’代表下一步可能的行动,w和w’分别是目标网络和评估网络的权重。
23、优选的,即时奖励计算公式如下:
24、
25、其中,是当前交叉路口ii到ij之间路段上的车辆平均速度,是邻居交叉路口到目的交叉路口的距离,是当前交叉路口ii到ij之间路段上车辆的连通性概率,ω1、ω2、ω3是对于不同的因素赋予的权重系数。
26、优选的,q学习算法的动作值函数更新迭代式为:
27、
28、其中,vi为当前节点,vj是vi的邻居节点,vd为目的节点,ve是vj邻居节点中的其中一个节点,n(vj)为vj邻居节点的集合,为奖励函数,α为学习率,γ为折扣因子。
29、优选的,奖励函数的计算方法为:
30、
31、其中,表示链路生存时间;表示路由延迟;表示信道衰落函数,β1、β2、β3是对于不同的因素赋予的权重系数。
32、优选的,q学习算法的动作值函数中折扣因子的计算方法为:
33、
34、其中,是t时刻节点vi的邻居节点集合,为t-1时刻节点vi的邻居节点集合。
35、优选的,q学习算法的动作值函数中学习率的计算方法为:
36、
37、
38、
39、其中,k是一个常数,ewmaaverage是一跳邻居节点的平均队列长度,n是一跳范围内邻居节点的数量,是当前时刻t下任何一辆邻居节点的平均队列长度值,使用指数加权平均来计算;δ称为权重因子,随着时间推移,权重呈指数衰减;是邻居节点vj的队列长度。
40、本发明有益效果是:(1)本发明将路段上的中继转发策略和交叉路口处的路段转发策略相结合,先将数据包转发到通信条件最好的路段上,然后在路段上选择最合适的中继车辆,提高了传输的可靠性。
41、(2)本发明中的中继转发策略,利用q学习算法,以实现在vanet高动态性环境下的最佳中继车辆选择,从而提高数据包的投递率。
42、(3)本发明中的路段转发策略,采用ddqn算法进行ddqn训练,边缘服务器基于所训练的评估网络,选出一条最佳转发路段,然后利用交叉路口区域的rsu节点进行辅助分发,该策略不仅能够学习到全局最优的路由策略,还能根据本地信息进行路由决策,从而选择出最适合转发的路段。
- 还没有人留言评论。精彩留言会获得点赞!