一种联合高效分组策略和自适应时域融合的视频去噪方法及相关系统
本发明属于视频去噪,具体涉及一种联合高效分组策略和自适应时域融合的视频去噪方法及相关系统。
背景技术:
1、在移动互联网时代,成像传感器性能不断提升,但是数字成像过程中仍不可避免产生噪声,这不仅降低了图像和视频质量,还会对后续图像处理任务造成不利影响。由于硬件条件限制,移动设备相较于专业光学相机,其传感器尺寸要小很多,因此图像视频的信噪比也更低。与单幅图像相比,视频图像序列具有较强的时间相关性,因此,视频去噪的关键问题是如何融合多个视频帧之间的时域信息来有效去除噪声。
2、现有的视频去噪方法主要分为以下两类:基于模型的传统视频去噪技术和基于深度学习的视频去噪技术。基于模型的视频去噪技术源自对单帧图像去噪技术的扩展,通过对相邻帧的运动估计和补偿,实现视频帧之间的对齐,然后将单帧去噪算法扩展为多帧联合去噪算法,但是传统去噪方法依赖于先验知识,去噪实时性普遍不高。因此,基于模型的传统方法难以充分抑制视频序列中的噪声。另一种基于深度学习的视频去噪技术利用深度神经网络强大的学习能力,自适应学习视频序列的时间相关性和空间相关性,并联合多帧图像去噪,可实现较好的去噪实时性和噪声抑制结果。基于神经网络的视频去噪方法的核心在于构建一个能够充分学习视频帧间、帧内相关性的网络结构,然而许多基于神经网络的视频去噪方法为了提升去噪性能设计了精细复杂的网络结构,但忽视了计算量的快速增长,从而限制了这类去噪算法在真实场景或可移动设备中的应用。
3、为了解决现有视频去噪方法计算复杂度较高、难以实际应用等问题,国内外研究人员提出了一类基于神经网络的快速视频去噪技术。基于神经网络的快速视频去噪技术大致有两种思路:基于多阶段的快速去噪方法和基于多输入多输出的视频去噪方法。
4、基于多阶段的方法不再使用显式的运动估计和运动补偿操作,而是通过逐渐融合时域信息恢复出清晰视频帧。例如,matias tassano等人在“fastdvdnet:towards real-time deep video denoising without flow estimation,ieee/cvf conference oncomputer vision and pattern recognition,2020:1351-1360”中,提出了基于多阶段融合的快速视频去噪方法fastdvdnet,通过两个阶段的渐进式时域融合恢复出高质量视频帧。
5、多输入多输出的视频去噪方法通过同时输出多个视频帧来提高运算效率,但是由于输入视频序列的不完整性,位于输出序列边缘的视频帧质量会显著下降,例如xiang,liuyu等人提出的快速视频去噪方法“remonet:recurrent multi-output network forefficient video denoising,proceedings of the aaai conference on artificialintelligence,2022,36(3):2786-2794”。
6、与大多数基于神经网络的视频去噪方法相比,现有基于神经网络的快速视频去噪技术通过高效的时域融合方法提高了运算效率,可以有效去除噪声,但是这类技术依然依赖于计算机设备的计算能力,而由于移动设备的算力有限,导致这类技术未能广泛应用于真实去噪场景中。此外,算法的计算量和去噪性能的平衡也是一个值得深入研究的问题。
技术实现思路
1、本发明的目的在于克服上述不足,提供一种联合高效分组策略和自适应时域融合的视频去噪方法,能够在降低计算复杂度的同时提高视频中每一个视频帧的峰值信噪比。
2、为了达到上述目的,本发明采用如下技术方案:
3、本发明提供一种联合高效分组策略和自适应时域融合的视频去噪方法,包括以下步骤:
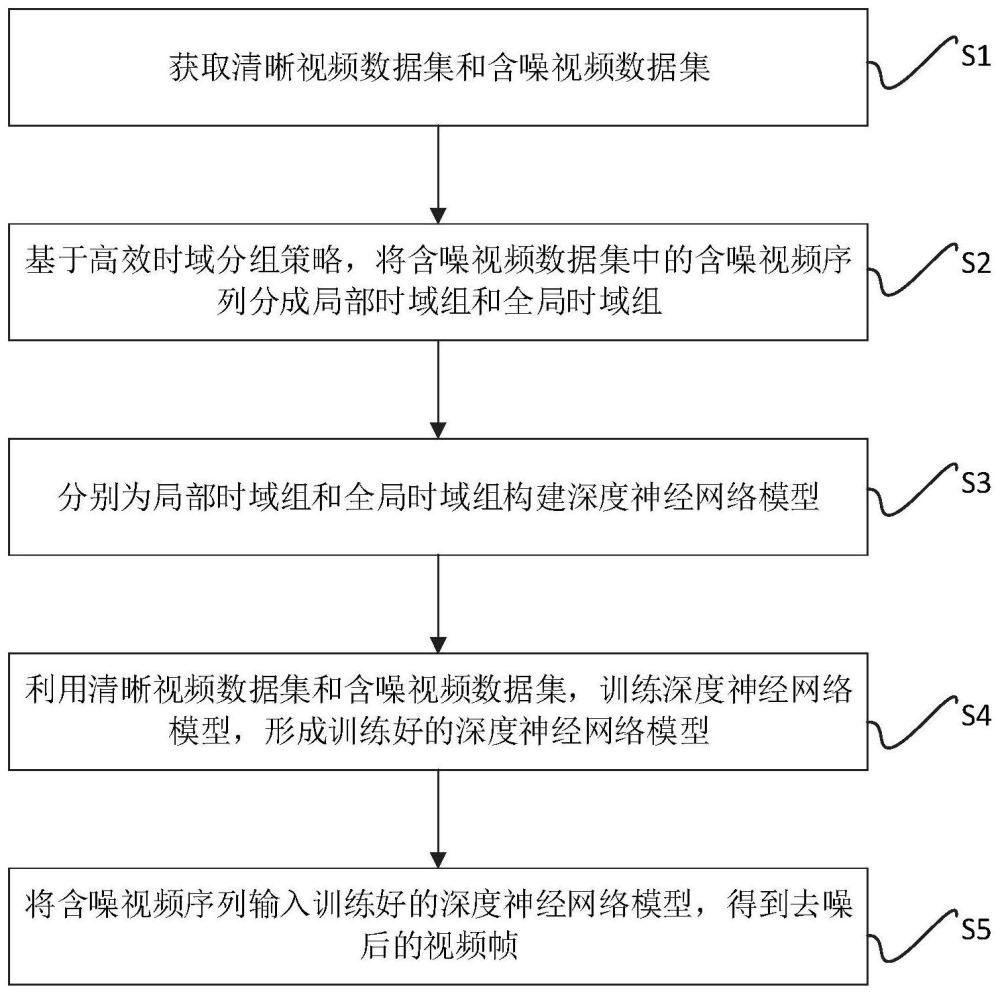
4、获取清晰视频数据集x和含噪视频数据集y;
5、基于高效时域分组策略,将含噪视频数据集y中的含噪视频序列yt-t,...,yt,....,yt+t分成局部时域组和全局时域组;
6、分别为局部时域组和全局时域组构建深度神经网络模型;
7、利用清晰视频数据集x和含噪视频数据集y,训练深度神经网络模型,形成训练好的深度神经网络模型;
8、将含噪视频序列输入训练好的深度神经网络模型,得到去噪后的视频帧。
9、本发明进一步的改进在于,所述获取清晰视频数据集x和含噪视频数据集y的方法如下:
10、对于给定的n个时刻的清晰视频序列,将其存储备份作为清晰标签集x={x1,x2,...,xt,...,xn},1≤t≤n;每个清晰视频序列包含(2t+1)个视频帧,将t时刻的清晰视频序列表示为xt={xt-t,...,xt,...,xt+t};
11、对清晰视频数据集x添加高斯噪声,得到含噪视频数据集y={y1,y2,...,yt,...,yn},每个含噪视频序列包含(2t+1)个视频帧,将t时刻的含噪视频序列表示为yt={yt-t,...,yt,...,yt+t}。
12、本发明进一步的改进在于,所述每个局部时域组和全局时域组中均包含3个视频帧,其中局部时域组中包含当前帧yt和与其相邻的两个视频帧yt-1,yt+1,全局时域组中包含当前帧yt和相邻帧中时域对称的两个视频帧yt-i,yt+i,1≤i≤t。
13、本发明进一步的改进在于,所述构建深度神经网络模型的方法如下:
14、第一步,搭建自适应融合模块,将视频帧和噪声方差图共同输入u-net网络来预测逐像素点的滤波器,同时利用卷积网络来提取相邻帧的特征,最后通过逐像素点滤波器与相邻帧特征图的点乘操作实现时域信息的自适应融合;
15、第二步,构建多阶段融合框架,分别将局部时域组和全局时域组输入不同的计算支路进行第一阶段的组内信息融合;
16、第三步,第二融合阶段使用自适应融合模块将第一阶段输出的结果进行进一步的组间信息融合,从而恢复出高质量的视频帧。
17、本发明进一步的改进在于,所述训练深度神经网络模型的方法如下:
18、第一步,对于给定的n个清晰视频序列,将其存储备份作为清晰视频数据集x;
19、第二步,对清晰视频数据集添加噪声,得到含噪视频数据集y,利用对应集合训练搭建好的深度神经网络模型,形成训练好的深度神经网络模型。
20、本发明进一步的改进在于,所述的含噪视频数据集y是采用清晰视频数据集x与高斯噪声矩阵n相加获得的,即y=x+n。
21、本发明进一步的改进在于,高斯噪声矩阵n符合高斯分布,其构建方式为:
22、n:n(0,σ2)
23、其中,σ为噪声标准差。
24、本发明提供一种联合高效分组策略和自适应时域融合系统,包括以下模块:
25、数据读取模块,用于获取清晰视频数据集x和含噪视频数据集y;
26、分组模块,用于将含噪视频数据集y中的含噪视频序列yt-t,...,yt,....,yt+t分成局部时域组和全局时域组;
27、模型构建模块,用于分别为局部时域组和全局时域组构建深度神经网络模型;
28、训练模块,用于利用清晰视频数据集x和含噪视频数据集y,训练深度神经网络模型,形成训练好的深度神经网络模型;
29、数据输出模块,用于将含噪视频序列输入训练好的深度神经网络模型,得到去噪后的视频帧。
30、本发明提供一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现联合高效分组策略和自适应时域融合的视频去噪方法的步骤。
31、本发明提供一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现联合高效分组策略和自适应时域融合的视频去噪方法的步骤。
32、与现有技术相比,本发明具有如下有益效果:
33、本发明通过基于高效的时域分组策略构造多阶段的融合去噪框架,通过自适应融合模块实现时域信息的融合,恢复出清晰视频帧,包括:获取清晰视频数据集x和含噪视频数据集y;对输入视频序列进行分组;构建深度神经网络模型;利用清晰视频数据集x和含噪视频数据集y,训练深度神经网络模型;获取去噪后的视频帧。通过将输入含噪视频序列划分成局部时域组和全局时域组并对其分配不同的计算量,高效建模视频帧的时间、空间信息,提升了去噪算法的运算效率,为后续的视频处理奠定了良好的基础,同时提出了高效相邻视频帧分组策略,便于后续的图像分类、目标识别、边缘检测等。
- 还没有人留言评论。精彩留言会获得点赞!