一种基于大数据的云服务管理方法及系统与流程
本发明涉及大数据,具体涉及一种基于大数据的云服务管理方法及系统。
背景技术:
1、随着云计算技术的迅速发展和大数据时代的到来,云服务已成为提供数据存储、处理和分析的关键平台,企业和组织越来越依赖于云平台来处理、存储和分析海量数据,以支撑其业务运营和决策制定,尤其是在处理大数据时,如何高效、准确地管理和调配云资源成为了一个亟待解决的问题。在这一背景下,有效管理云平台资源,以满足动态变化的服务需求,成为了一项挑战性任务。
2、大数据云服务管理面临的主要挑战包括数据的高维度、动态变化的负载、以及对实时或近实时处理的需求。传统的资源管理策略,往往基于静态规则,缺乏对实时数据变化的快速响应能力,如基于静态规则的扩缩容策略,难以适应这种快速变化的环境。此外,用户请求的不可预测性以及服务质量(qos)的保证要求,都使得云服务资源管理的自动化和智能化成为了迫切需要,大数据应用的复杂性要求云服务管理能够准确预测未来的资源需求,以优化资源配置和减少成本,然而,现有技术往往无法准确捕捉到数据之间复杂的依赖关系,导致资源预测的不准确。且传统的云服务管理方法依赖于预定义的规则和人工设置的阈值来调整资源,这种方式在面对大规模、高复杂度的数据时往往显得力不从心。
3、虽然已经有一些方法试图通过自动化工具和策略来改善云服务管理,如基于阈值的自动扩展策略和基于历史数据的资源需求预测,但这些方法仍然存在局限性。基于阈值的方法缺乏对未来负载变化的预见性,而基于历史数据的预测方法往往忽略了数据内在的时间序列特性和复杂的非线性关系,导致预测结果的准确性有限,且不能够通过将实时获取的数据结合历史数据进行预测,且现有的变压器网络模型没有考虑到时间编码和上下文信息编码信息,导致预测准确度较低。此外,现有技术往往在处理海量数据时效率低下,无法满足实时或近实时处理的需求。
4、且现有的变压器网络模型不能够根据实时数据并结合历史数据情况进行动态调整,导致计算灵活性较差,且现有的变压器网络不能够根据时间序列函数的变化而变化,针对云服务器数据处理时有较高的局限性,云服务器数据处理行业迫切需要一种新的解决方案,以提高云服务器处理的效率和客户满意度。
技术实现思路
1、针对现有技术中提到的上述问题,为解决上述技术问题,本发明提供了一种基于大数据的云服务管理方法及系统,该方法实时收集云平台服务器的使用数据;应用时间序列分析模型arima对负载数据cpu使用率进行预测,得到时间点t的预测值;将arima模型的预测结果作为附加特征与收集云平台服务器的使用数据一起构成变压器网络模型的输入矩阵x;变压器网络模型采用注意力机制;利用变压器网络模型的最终输出未来一段时间内云平台服务器的资源需求预测;系统根据对cpu使用率、内存需求、网络带宽资源的需求量估计,调整计算资源或网络带宽;本技术通过应用时间序列分析模型arima结合变压器网络模型提升了预测准确度,尤其arima模型的预测结果作为附加特征与收集云平台服务器的使用数据一起构成变压器网络模型的输入矩阵x,同时变压器网络模型将时间编码、上下文信息编码纳入注意力机制,大大提升了云数据处理速度和准确度,极大增加用户体验。
2、本技术提供一种基于大数据的云服务管理方法,其特征在于,包括步骤:
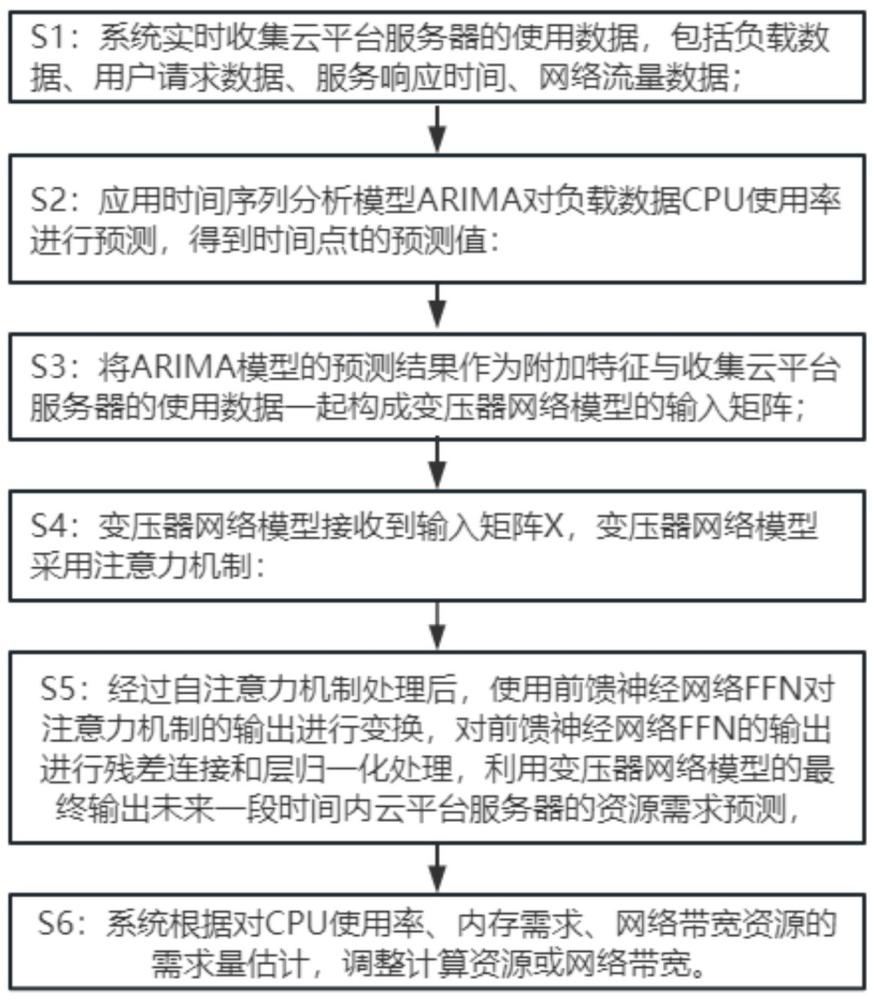
3、s1:系统实时收集云平台服务器的使用数据,包括负载数据、用户请求数据、服务响应时间、网络流量数据;
4、s2:应用时间序列分析模型arima对负载数据cpu使用率进行预测,得到时间点t的预测值:
5、;
6、其中,是常数项,、分别是第1、第p自回归参数,、分别是第1、第q移动平均参数;、、分别是在时间点t-1、t-q、t的误差项;、分别是在时间点t-1、t-p时的预测值;
7、s3:将arima模型的预测结果作为附加特征与收集云平台服务器的使用数据一起构成变压器网络模型的输入矩阵x;
8、s4:变压器网络模型接收到输入矩阵x,变压器网络模型采用注意力机制:
9、;
10、其中,t为时间编码,c代表上下文信息编码;查询q、键k、值v是通过对输入矩阵x进行线性变换得到,、、分别为查询、键、值的转换矩阵,则、、,为缩放因子,为归一化函数;
11、s5:经过自注意力机制处理后,使用前馈神经网络ffn对注意力机制的输出进行变换,其中ffn包括两个线性变换和一个非线性激活函数;对前馈神经网络ffn的输出进行残差连接和层归一化处理,确保经过前馈神经网络ffn处理的特征通过网络层;利用变压器网络模型的最终输出未来一段时间内云平台服务器的资源需求预测,预测包括对cpu使用率、内存需求、网络带宽资源的需求量进行估计;
12、s6:系统根据对cpu使用率、内存需求、网络带宽资源的需求量估计,调整计算资源或网络带宽。
13、优选地,所述负载数据包括cpu使用率、内存使用量、磁盘i/o操作;所述用户请求数据包括请求类型、请求时间、请求频率,请求类型包括数据读取或写入请求;所述服务响应时间包括服务启动时间、处理时间以及响应发送时间;所述网络流量数据包括数据传输速率、流量峰值。
14、优选地,所述应用arima模型对收集的数据进行处理;对每个时间序列数据cpu使用率应用arima模型进行预测,得到时间点t的预测值,包括:首先确定arima模型的自回归项阶数p、差分项阶数d、移动平均项的阶数q,其中,使用自相关图acf和偏自相关图pacf来计算p和q,通过差分次数来确定d;其次,使用历史数据拟合arima模型,估计模型参数、,利用拟合的模型对未来cpu使用率进行预测。
15、优选地,所述s2:应用arima模型对收集的数据进行处理;对每个时间序列数据cpu使用率应用arima模型进行预测,得到时间点t的预测值,还包括一个滚动窗口w,用于确定用于模型训练的数据范围,每次窗口滚动后,评估模型的预测误差ϵ并调整参数:
16、;
17、其中,是第i个时间点的预测值,是第i个时间点的实际值,n是窗口大小,i表示窗口内时间点索引值,如果大于设定阈值增加p或d。
18、优选地,所述t为时间编码,时间编码t采用正弦和余弦函数的位置编码方法,对于序列中的每个位置pos和每个维度j,时间编码的第j个维度的值由下列公式给出:
19、当i为偶数时,;
20、当i为奇数时,;
21、其中,是位置索引,是维度索引,是模型的维度。
22、本技术还提供一种基于大数据的云服务管理系统,包括:
23、使用数据收集模块,系统实时收集云平台服务器的使用数据,包括负载数据、用户请求数据、服务响应时间、网络流量数据;
24、预测值计算模块,应用时间序列分析模型arima对负载数据cpu使用率进行预测,得到时间点t的预测值:
25、;
26、其中,是常数项,、分别是第1、第p自回归参数,、分别是第1、第q移动平均参数;、、分别是在时间点t-1、t-q、t的误差项;、分别是在时间点t-1、t-p时的预测值;
27、输入矩阵生成模块,将arima模型的预测结果作为附加特征与收集云平台服务器的使用数据一起构成变压器网络模型的输入矩阵x;
28、注意力机制计算模块,变压器网络模型接收到输入矩阵x,变压器网络模型采用注意力机制:
29、;
30、其中,t为时间编码,c代表上下文信息编码;查询q、键k、值v是通过对输入矩阵x进行线性变换得到,、、分别为查询、键、值的转换矩阵,则、、,为缩放因子,为归一化函数;
31、后处理模块,经过自注意力机制处理后,使用前馈神经网络ffn对注意力机制的输出进行变换,其中ffn包括两个线性变换和一个非线性激活函数;对前馈神经网络ffn的输出进行残差连接和层归一化处理,确保经过前馈神经网络ffn处理的特征通过网络层;利用变压器网络模型的最终输出未来一段时间内云平台服务器的资源需求预测,预测包括对cpu使用率、内存需求、网络带宽资源的需求量进行估计;
32、调整模块,系统根据对cpu使用率、内存需求、网络带宽资源的需求量估计,调整计算资源或网络带宽。
33、优选地,所述使用数据收集模块:负载数据包括cpu使用率、内存使用量、磁盘i/o操作;用户请求数据包括请求类型、请求时间、请求频率,请求类型包括数据读取或写入请求;服务响应时间包括服务启动时间、处理时间以及响应发送时间;网络流量数据包括数据传输速率、流量峰值。
34、优选地,所述预测值计算模块,应用arima模型对收集的数据进行处理;对每个时间序列数据cpu使用率应用arima模型进行预测,得到时间点t的预测值,包括:首先确定arima模型的自回归项阶数p、差分项阶数d、移动平均项的阶数q,其中,使用自相关图acf和偏自相关图pacf来计算p和q,通过差分次数来确定d;其次,使用历史数据拟合arima模型,估计模型参数、,利用拟合的模型对未来cpu使用率进行预测。
35、优选地,所述预测值计算模块,应用arima模型对收集的数据进行处理;对每个时间序列数据cpu使用率应用arima模型进行预测,得到时间点t的预测值,还包括一个滚动窗口w,用于确定用于模型训练的数据范围,每次窗口滚动后,评估模型的预测误差ϵ并调整参数:
36、;
37、其中,是第i个时间点的预测值,是第i个时间点的实际值,n是窗口大小,i表示窗口内时间点索引值,如果大于设定阈值增加p或d。
38、优选地,所述t为时间编码,时间编码t采用正弦和余弦函数的位置编码方法,对于序列中的每个位置pos和每个维度j,时间编码的第j个维度的值由下列公式给出:
39、当i为偶数时,;
40、当i为奇数时,;
41、其中,是位置索引,是维度索引,是模型的维度。
42、本发明提供了一种基于大数据的云服务管理方法及系统,所能实现的有益技术效果如下:
43、1、本发明通过应用时间序列分析模型arima结合变压器网络模型提升了预测准确度,尤其arima模型的预测结果作为附加特征与收集云平台服务器的使用数据一起构成变压器网络模型的输入矩阵x,同时变压器网络模型将时间编码、上下文信息编码纳入注意力机制,大大提升了云数据处理速度和准确度,极大增加用户体验,系统能够根据模型预测结果及时调整资源分配,以应对突发事件和负载峰值,保证服务的高可用性和性能。
44、2、本发明变压器网络模型接收到输入矩阵x,变压器网络模型采用注意力机制:
45、;
46、其中,t为时间编码,c代表上下文信息编码;查询q、键k、值v是通过对输入矩阵x进行线性变换得到,、、分别为查询、键、值的转换矩阵,则、、,为缩放因子,为归一化函数;其中通过将时间编码t、上下文信息编码c纳入到注意力机制中,大大提升了信息的丰富程度,提升了变压器网络模型预测准确度。系统根据预测结果动态调整计算资源或网络带宽,优化资源配置。通过引入时间编码和上下文信息编码,模型能够有效地理解和利用时间序列数据的顺序信息,增强预测的准确性。
47、3、本发明创造性的采用应用时间序列分析模型arima对负载数据cpu使用率进行预测,得到时间点t的预测值:输入矩阵生成模块,将arima模型的预测结果作为附加特征与收集云平台服务器的使用数据一起构成变压器网络模型的输入矩阵x;通过将预测结果与原数据结合,丰富了数据输入类型,将arima的预测数据作为变压器网络模型的输入,大大提高了变压器网络的准确性,大大提升了实时云服务数据处理效率和准确率,能够更准确地预测云平台服务器的资源需求。
48、4、本发明应用arima模型对收集的数据进行处理,对每个时间序列数据cpu使用率应用arima模型进行预测,得到时间点t的预测值,还包括一个滚动窗口w,用于确定用于模型训练的数据范围,每次窗口滚动后,评估模型的预测误差ϵ并调整参数:
49、;
50、其中,是第i个时间点的预测值,是第i个时间点的实际值,n是窗口大小,i表示窗口内时间点索引值,如果大于设定阈值增加p或d,通过均方差的引入可以动态调整,提升了更加精确的资源需求预测和动态资源配置,企业可以避免过度配置资源而造成的不必要开支,同时减少因资源不足而影响用户体验的情况。这种数据驱动的资源管理策略有助于实现资源配置的最优化,从而在满足业务需求的前提下,最大程度地降低运营成本。本发明涉及一种滚动窗口机制,用于不断更新模型训练数据,保证预测结果的时效性和准确性。
- 还没有人留言评论。精彩留言会获得点赞!