视频处理方法、装置、电子设备及存储介质
本公开涉及多媒体,尤其涉及视频处理方法、装置、电子设备及存储介质。
背景技术:
1、得益于移动通信技术的发展,视频作为包含丰富信息的多媒体被广泛的传输分享。在现有的视频编辑技术领域中,主要依赖于复杂的图像处理技术和手动编辑流程。既要求编辑者具备专业的技术知识和丰富的操作经验,也难以解决现有视频编辑技术在视频帧连贯与自然性方面的不足,效率极低。
技术实现思路
1、本公开提供视频处理方法、装置、电子设备及存储介质,以至少解决相关技术中的问题。本公开的技术方案如下:
2、根据本公开实施例的第一方面,提供一种视频处理方法,包括:
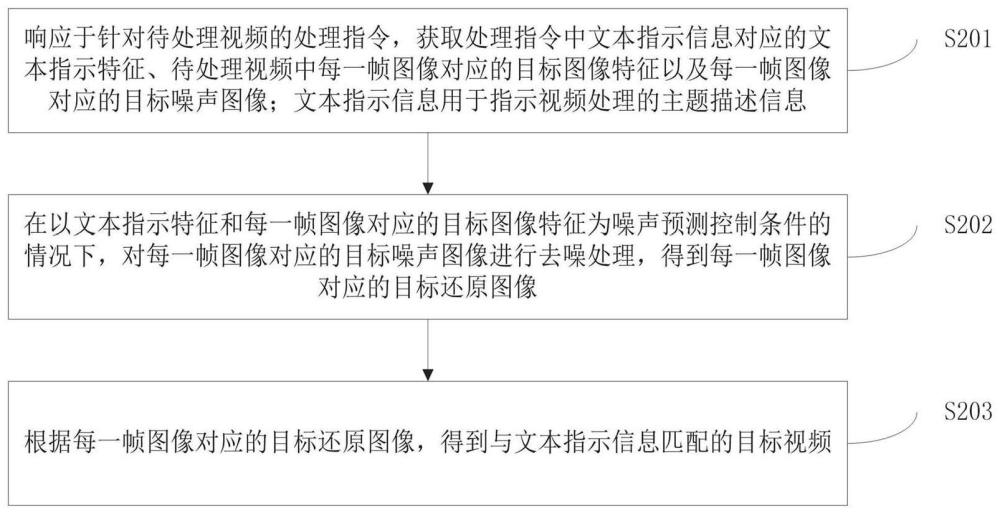
3、响应于针对待处理视频的处理指令,获取所述处理指令中文本指示信息对应的文本指示特征、所述待处理视频中每一帧图像对应的目标图像特征以及所述每一帧图像对应的目标噪声图像;所述文本指示信息用于指示视频处理的主题描述信息;
4、在以所述文本指示特征和所述每一帧图像对应的目标图像特征为噪声预测控制条件的情况下,对所述每一帧图像对应的目标噪声图像进行去噪处理,得到所述每一帧图像对应的目标还原图像;
5、根据所述每一帧图像对应的目标还原图像,得到与所述文本指示信息匹配的目标视频。
6、可选的,所述在以所述文本指示特征和所述每一帧图像对应的目标图像特征为噪声预测控制条件的情况下,对所述每一帧图像对应的目标噪声图像进行去噪处理,得到所述每一帧图像对应的目标还原图像,包括:
7、在第一去噪阶段,将所述文本指示特征、所述目标图像特征和所述目标噪声图像输入第一图像还原模型,以使所述第一图像还原模型以所述文本指示特征为第一控制条件、以所述目标图像特征为第二控制条件,对所述目标噪声图像进行去噪处理,得到初始还原图像;
8、在第二去噪阶段,将所述目标图像特征和所述初始还原图像输入第二图像还原模型,以使所述第二图像还原模型以所述目标图像特征为第三控制条件,对所述初始还原图像进行去噪处理,得到所述目标还原图像。
9、可选的,所述第一去噪阶段包括第一预设数量轮次的去噪处理,所述在第一去噪阶段,将所述文本指示特征、所述目标图像特征和所述目标噪声图像输入图像还原模型中的第一图像还原模型,以使所述第一图像还原模型以所述文本指示特征为第一控制条件、以所述目标图像特征为第二控制条件,对所述目标噪声图像进行去噪处理,得到初始还原图像,包括:
10、确定所述第一去噪阶段中当前去噪轮次对应的当前噪声图像;所述第一去噪阶段的首个去噪轮次对应的当前噪声图像为所述目标噪声图像;
11、将所述文本指示特征和所述当前噪声图像输入所述第一图像还原模型中的第一噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第一预测噪声;
12、将所述目标图像特征和所述当前噪声图像输入所述第一图像还原模型中的第二噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第二预测噪声;
13、将所述第一预测噪声和所述第二预测噪声输入所述第一图像还原模型中的第一噪声混合模块,进行噪声混合处理,得到所述当前去噪轮次对应的第一混合噪声;
14、将所述当前噪声图像和所述第一混合噪声输入所述第一图像还原模型中的第一去噪模块,对所述当前噪声图像进行去噪处理,得到所述当前去噪轮次对应的当前还原图像;
15、将所述当前还原图像作为下一去噪轮次对应的下一噪声图像,迭代执行上述去噪处理,直至所述当前去噪轮次的数值达到所述第一预设数量,并得到所述初始还原图像。
16、可选的,所述第二去噪阶段包括第二预设数量轮次的去噪处理,所述在第二去噪阶段,将所述目标图像特征和所述初始还原图像输入所述图像还原模型中的第二图像还原模型,以使所述第二图像还原模型以所述目标图像特征为第三控制条件,对所述初始还原图像进行去噪处理,得到所述目标还原图像,包括:
17、确定所述第二去噪阶段中当前去噪轮次对应的当前噪声图像;所述第二去噪阶段的首个去噪轮次对应的当前噪声图像为所述初始还原图像;
18、将所述目标图像特征和所述当前噪声图像输入所述第二图像还原模型中的第三噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第三预测噪声;
19、将所述当前噪声图像和所述第三预测噪声输入所述第二图像还原模型中的第二去噪模块,对所述当前噪声图像进行去噪处理,得到所述当前去噪轮次对应的当前还原图像;
20、将所述当前还原图像作为下一去噪轮次对应的下一噪声图像,迭代执行上述去噪处理,直至所述当前去噪轮次的数值达到所述第二预设数量,并得到所述目标还原图像。
21、可选的,所述去噪处理包括第三预设数量轮次的去噪处理,所述以所述文本指示特征和所述目标图像特征为控制条件,对所述目标噪声图像进行去噪处理,得到所述目标图像对应的目标还原图像,包括:
22、确定所述去噪处理中当前去噪轮次对应的当前噪声图像;所述去噪处理的首个去噪轮次对应的当前噪声图像为所述目标噪声图像;
23、将所述文本指示特征和所述当前噪声图像输入第三图像还原模型中的第四噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第四预测噪声;
24、将所述目标图像特征和所述当前噪声图像输入所述第三图像还原模型中的第五噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第五预测噪声;
25、将所述第四预测噪声和所述第五预测噪声输入所述第三图像还原模型中的第二噪声混合模块,进行噪声混合处理,得到所述当前去噪轮次对应的第二混合噪声;
26、将所述当前噪声图像和所述第二混合噪声,对所述当前噪声图像进行去噪处理,得到所述当前去噪轮次对应的当前还原图像;
27、将所述当前还原图像作为下一去噪轮次对应的下一噪声图像,迭代执行上述去噪处理,直至所述当前去噪轮次的数值达到所述第三预设数量,并得到所述目标还原图像。
28、可选的,所述将所述目标图像特征和所述当前噪声图像输入所述第一图像还原模型中的第二噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第二预测噪声,包括:
29、将所述目标图像特征和所述当前噪声图像输入所述第二噪声预测模块中的第一预测通道,对所述当前噪声图像进行第一噪声预测处理,得到第一子预测噪声;
30、将所述当前噪声图像输入所述第二噪声预测模块中的第二预测通道,对所述当前噪声图像进行第二噪声预测处理,得到第二子预测噪声;
31、基于预设的指导尺度、所述第一子预测噪声和所述第二子预测噪声,得到所述当前去噪轮次对应的第二预测噪声;所述指导尺度用于指示所述第一子预测噪声和所述第二子预测噪声在所述第二预测噪声中的占比。
32、可选的,所述方法还包括:
33、获取训练数据集,所述训练数据集包括至少一个训练样本组,每个训练样本组对应于一种预设主题,所述训练样本组中的每一个训练样本包括样本图像、样本还原图像和样本文本指示信息,所述样本还原图像为按照所述训练样本组对应的预设主题对所述样本图像处理后得到的与所述样本文本指示信息匹配的图像,所述样本文本指示信息包括所述样本还原图像的描述信息和所述预设主题;
34、将所述样本文本指示信息输入初始文本编码器,进行文本编码处理,得到样本文本指示特征;
35、将所述样本图像输入图像编码器,进行图像编码,得到所述样本图像对应的样本图像特征;
36、将所述样本图像特征输入图像加噪模型,进行加噪处理,得到所述样本图像对应的样本噪声图像,并确定增加的样本噪声;
37、将所述样本文本指示特征和所述样本噪声图像输入第一初始噪声预测模块,对所述样本噪声图像进行噪声预测处理,得到第一样本预测噪声;
38、根据所述样本噪声和所述第一样本预测噪声之间的第一损失数据,对所述初始文本编码器和所述第一初始噪声预测模块进行训练,得到文本编码器和所述第一噪声预测模块;所述文本编码器中建立了所述描述信息与所述预设主题之间的映射关系;所述文本编码器用于获取所述处理指令中文本指示信息对应的文本指示特征。
39、可选的,所述方法还包括:
40、将所述样本文本指示特征、所述样本图像特征和所述样本噪声图像输入第二初始噪声预测模块,对所述样本噪声图像进行噪声预测处理,得到第二样本预测噪声;
41、根据所述样本噪声和所述第二样本预测噪声之间的第二损失数据,对所述第二初始噪声预测模块进行训练,得到所述第二噪声预测模块。
42、可选的,所述响应于针对待处理视频的处理指令,获取所述处理指令中文本指示信息对应的文本指示特征、所述待处理视频中每一帧图像对应的目标图像特征以及所述每一帧图像对应的目标噪声图像,包括:
43、响应于针对待处理视频的处理指令,获取所述处理指令中的文本指示信息;所述文本指示信息指示视频处理的主题描述信息;
44、将所述文本指示信息输入文本编码器,进行文本编码处理,得到所述文本指示特征;
45、将所述每一帧图像输入图像编码器,进行图像编码处理,得到所述每一帧图像对应的目标图像特征;
46、将所述每一帧图像对应的目标图像特征输入图像加噪模型,进行加噪处理,得到所述每一帧图像对应的对应的目标噪声图像。
47、根据本公开实施例的第二方面,提供一种视频处理装置,包括:
48、特征编码和加噪模块,被配置为执行响应于针对待处理视频的处理指令,获取所述处理指令中文本指示信息对应的文本指示特征、所述待处理视频中每一帧图像对应的目标图像特征以及所述每一帧图像对应的目标噪声图像;所述文本指示信息用于指示视频处理的主题描述信息;
49、去噪模块,被配置为执行在以所述文本指示特征和所述每一帧图像对应的目标图像特征为噪声预测控制条件的情况下,对所述每一帧图像对应的目标噪声图像进行去噪处理,得到所述每一帧图像对应的目标还原图像;
50、目标视频生成模块,被配置为执行根据所述每一帧图像对应的目标还原图像,得到与所述文本指示信息匹配的目标视频。
51、可选的,所述去噪模块包括:
52、第一去噪子模块,被配置为执行在第一去噪阶段,将所述文本指示特征、所述目标图像特征和所述目标噪声图像输入第一图像还原模型,以使所述第一图像还原模型以所述文本指示特征为第一控制条件、以所述目标图像特征为第二控制条件,对所述目标噪声图像进行去噪处理,得到初始还原图像;
53、第二去噪子模块,被配置为执行在第二去噪阶段,将所述目标图像特征和所述初始还原图像输入第二图像还原模型,以使所述第二图像还原模型以所述目标图像特征为第三控制条件,对所述初始还原图像进行去噪处理,得到所述目标还原图像。
54、可选的,所述第一去噪阶段包括第一预设数量轮次的去噪处理,所述第一去噪子模块包括:
55、当前噪声图像的第一确定单元,被配置为执行确定所述第一去噪阶段中当前去噪轮次对应的当前噪声图像;所述第一去噪阶段的首个去噪轮次对应的当前噪声图像为所述目标噪声图像;
56、第一噪声预测单元,被配置为执行将所述文本指示特征和所述当前噪声图像输入所述第一图像还原模型中的第一噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第一预测噪声;
57、第二噪声预测单元,被配置为执行将所述目标图像特征和所述当前噪声图像输入所述第一图像还原模型中的第二噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第二预测噪声;
58、第一噪声混合单元,被配置为执行将所述第一预测噪声和所述第二预测噪声输入所述第一图像还原模型中的第一噪声混合模块,进行噪声混合处理,得到所述当前去噪轮次对应的第一混合噪声;
59、第一去噪单元,被配置为执行将所述当前噪声图像和所述第一混合噪声输入所述第一图像还原模型中的第一去噪模块,对所述当前噪声图像进行去噪处理,得到所述当前去噪轮次对应的当前还原图像;
60、第一迭代单元,被配置为执行将所述当前还原图像作为下一去噪轮次对应的下一噪声图像,迭代执行上述去噪处理,直至所述当前去噪轮次的数值达到所述第一预设数量,并得到所述初始还原图像。
61、可选的,所述第二去噪阶段包括第二预设数量轮次的去噪处理,所述第二去噪子模块包括:
62、当前噪声图像的第二确定单元,被配置为执行确定所述第二去噪阶段中当前去噪轮次对应的当前噪声图像;所述第二去噪阶段的首个去噪轮次对应的当前噪声图像为所述初始还原图像;
63、第三噪声预测单元,被配置为执行将所述目标图像特征和所述当前噪声图像输入所述第二图像还原模型中的第三噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第三预测噪声;
64、第二去噪单元,被配置为执行将所述当前噪声图像和所述第三预测噪声输入所述第二图像还原模型中的第二去噪模块,对所述当前噪声图像进行去噪处理,得到所述当前去噪轮次对应的当前还原图像;
65、第二迭代单元,被配置为执行将所述当前还原图像作为下一去噪轮次对应的下一噪声图像,迭代执行上述去噪处理,直至所述当前去噪轮次的数值达到所述第二预设数量,并得到所述目标还原图像。
66、可选的,所述装置被配置为执行第三预设数量轮次的去噪处理,所述去噪模块包括:
67、当前噪声图像的第三确定单元,被配置为执行确定所述去噪处理中当前去噪轮次对应的当前噪声图像;所述去噪处理的首个去噪轮次对应的当前噪声图像为所述目标噪声图像;
68、第三噪声预测单元,被配置为执行将所述文本指示特征和所述当前噪声图像输入第三图像还原模型中的第四噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第四预测噪声;
69、第四噪声预测单元,被配置为执行将所述目标图像特征和所述当前噪声图像输入所述第三图像还原模型中的第五噪声预测模块,对所述当前噪声图像进行噪声预测处理,得到所述当前去噪轮次对应的第五预测噪声;
70、第二噪声混合单元,被配置为执行将所述第四预测噪声和所述第五预测噪声输入所述第三图像还原模型中的第二噪声混合模块,进行噪声混合处理,得到所述当前去噪轮次对应的第二混合噪声;
71、第三去噪单元,被配置为执行将所述当前噪声图像和所述第二混合噪声,对所述当前噪声图像进行去噪处理,得到所述当前去噪轮次对应的当前还原图像;
72、第三迭代单元,被配置为执行将所述当前还原图像作为下一去噪轮次对应的下一噪声图像,迭代执行上述去噪处理,直至所述当前去噪轮次的数值达到所述第三预设数量,并得到所述目标还原图像。
73、可选的,所述第二噪声预测单元包括:
74、第一预测通道子单元,被配置为执行将所述目标图像特征和所述当前噪声图像输入所述第二噪声预测模块中的第一预测通道,对所述当前噪声图像进行第一噪声预测处理,得到第一子预测噪声;
75、第二预测通道子单元,被配置为执行将所述当前噪声图像输入所述第二噪声预测模块中的第二预测通道,对所述当前噪声图像进行第二噪声预测处理,得到第二子预测噪声;
76、加权子单元,被配置为执行基于预设的指导尺度、所述第一子预测噪声和所述第二子预测噪声,得到所述当前去噪轮次对应的第二预测噪声;所述指导尺度用于指示所述第一子预测噪声和所述第二子预测噪声在所述第二预测噪声中的占比。
77、可选的,所述装置还包括:
78、训练数据获取单元,被配置为执行获取训练数据集,所述训练数据集包括至少一个训练样本组,每个训练样本组对应于一种预设主题,所述训练样本组中的每一个训练样本包括样本图像、样本还原图像和样本文本指示信息,所述样本还原图像为按照所述训练样本组对应的预设主题对所述样本图像处理后得到的与所述样本文本指示信息匹配的图像,所述样本文本指示信息包括所述样本还原图像的描述信息和所述预设主题;
79、样本文本编码单元,被配置为执行将所述样本文本指示信息输入初始文本编码器,进行文本编码处理,得到样本文本指示特征;
80、样本图像编码单元,被配置为执行将所述样本图像输入图像编码器,进行图像编码,得到所述样本图像对应的样本图像特征;
81、样本图像加噪单元,被配置为执行将所述样本图像特征输入图像加噪模型,进行加噪处理,得到所述样本图像对应的样本噪声图像,并确定增加的样本噪声;
82、第一样本噪声预测单元,被配置为执行将所述样本文本指示特征和所述样本噪声图像输入第一初始噪声预测模块,对所述样本噪声图像进行噪声预测处理,得到第一样本预测噪声;
83、第一训练单元,被配置为执行根据所述样本噪声和所述第一样本预测噪声之间的第一损失数据,对所述初始文本编码器和所述第一初始噪声预测模块进行训练,得到文本编码器和所述第一噪声预测模块;所述文本编码器中建立了所述描述信息与所述预设主题之间的映射关系;所述文本编码器用于获取所述处理指令中文本指示信息对应的文本指示特征。
84、可选的,所述装置还包括:
85、第二样本噪声预测单元,被配置为执行将所述样本文本指示特征、所述样本图像特征和所述样本噪声图像输入第二初始噪声预测模块,对所述样本噪声图像进行噪声预测处理,得到第二样本预测噪声;
86、第二训练单元,被配置为执行根据所述样本噪声和所述第二样本预测噪声之间的第二损失数据,对所述第二初始噪声预测模块进行训练,得到所述第二噪声预测模块。
87、可选的,所述特征编码和加噪模块包括:
88、文本指示信息获取单元,被配置为执行响应于针对待处理视频的处理指令,获取所述处理指令中的文本指示信息;所述文本指示信息指示视频处理的主题描述信息;
89、文本编码单元,被配置为执行将所述文本指示信息输入文本编码器,进行文本编码处理,得到所述文本指示特征;
90、图像编码单元,被配置为执行将所述每一帧图像输入图像编码器,进行图像编码处理,得到所述每一帧图像对应的目标图像特征;
91、图像加噪单元,被配置为执行将所述每一帧图像对应的目标图像特征输入图像加噪模型,进行加噪处理,得到所述每一帧图像对应的对应的目标噪声图像。
92、根据本公开实施例的第三方面,提供一种电子设备,包括:处理器;用于存储所述处理器可执行指令的存储器;其中,所述处理器被配置为执行所述指令,以实现本公开实施例第一方面中任一项所述的视频处理方法。
93、根据本公开实施例的第四方面,提供一种计算机可读存储介质,当所述计算机可读存储介质中的指令由电子设备的处理器执行时,使得所述电子设备能够执行如本公开实施例第一方面中任一项所述的视频处理方法。
94、根据本公开实施例的第五方面,提供一种计算机程序产品,包括计算机指令,所述计算机指令被处理器执行时实现如本公开实施例第一方面中任一项所述的视频处理方法。
95、本公开的实施例提供的技术方案至少带来以下有益效果:
96、本公开的实施例响应于针对待处理视频的处理指令,获取所述处理指令中文本指示信息对应的文本指示特征、所述待处理视频中每一帧图像对应的目标图像特征以及所述每一帧图像对应的目标噪声图像;所述文本指示信息用于指示视频处理的主题描述信息;在以所述文本指示特征和所述每一帧图像对应的目标图像特征为噪声预测控制条件的情况下,对所述每一帧图像对应的目标噪声图像进行去噪处理,得到所述每一帧图像对应的目标还原图像;从而可以根据所述每一帧图像对应的目标还原图像,得到与所述文本指示信息匹配的目标视频。
97、本公开的实施例以文本指示信息触发针对待处理视频的自动化处理,也即用户仅需输入文本指示信息则可获得符合文本指示信息要求的目标视频,降低了对用户的视频处理能力的要求,也极大地减少了手动处理的时间和精力,提升了用户好友性,提高了视频处理的效率,扩大了视频处理的应用范围和受众,适用于那些需要快速响应市场变化和编辑需求的领域,如社交媒体内容创作、商业广告制作等。
98、在本公开的实施例中,在去噪过程中,引入文本指示特征并将文本指示特征作为噪声预测控制条件之一以控制去噪阶段的噪声,从而在去噪后的目标还原图像上实现文本指示信息所指示的主题描述信息对应的视觉效果,进而在各帧图像对应的目标还原图像之间实现处理主题的一致性。同时在去噪过程中,对于每一帧图像,引入每一帧图像对应的目标图像特征并将每一帧图像对应的目标图像特征作为噪声预测控制条件之一以控制去噪阶段的噪声,目标图像特征指示了对应图像中的关键特征或核心属性信息,从而可以在去噪后的目标还原图像上保持关键特征,进而在各帧图像对应的目标还原图像之间实现关键特征的帧间连贯性,提升目标视频的整体真实感和连贯性,提升用户的观感。
99、在本公开的实施例中,基于单帧图像进行图像处理,能够快速处理大规模的视频数据,能满足实时处理的需求,如直播或即是社交媒体内容的制作。
100、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
- 还没有人留言评论。精彩留言会获得点赞!