一种基于集成学习的车辆入侵检测方法及装置
本发明涉及车联网安全,特别是涉及一种基于集成学习的车辆入侵检测方法及装置。
背景技术:
1、智能汽车网络由车辆内部网和车辆外部网两个网络系统构成。车辆内部网连接了车辆内部的各个电子控制单元,包括发动机控制单元、刹车系统、空调系统等,通过车辆内部网络协议进行通信。车辆外部网则使车辆能够与外部环境进行通信,包括与其他车辆、基础设施和云服务的连接。车联网技术有助于实现智能交通系统、自动驾驶和车辆互联等功能。车辆网络的安全直接关系到驾驶员和乘客的安全,黑客可以利用车辆外部网络的漏洞来入侵车辆的内部网,这种攻击通常被称为"远程攻击"。黑客通过攻击车辆与外部环境进行通信的系统,然后尝试进一步渗透到车辆内部网络,轻则导致车辆用户的隐私信息泄露,重则导致车辆控制失灵造成意外事故,危及人身安全。
2、为了确保车联网安全,通常采用建立规则库进行对比的方案以及基于云边训练部署的异常入侵检测系统的方案。基于规则库的方案根据车辆检测状态与防御规则库对比,从而产生对应的防御策略。基于规则库的方案严重依赖规则库的知识,可能更容易受到规则的刚性限制,容易产生误报或者遗漏,且需要定期对规则库进行更新。基于云边部署的车辆入侵检测方案在训练和更新模型时需要大量的数据传输,可能导致延迟和对网络连接的强烈依赖。此外,也存在云边端被入侵,云边端秘钥泄露的风险。因此,拥有能够短时间内在车辆本地快速训练部署的本地入侵检测方法至关重要。
3、公开号为cn109829543a,名称为一种基于集成学习的数据流在线异常检测方法,首先使用htm网络和n个lstm网络作为弱学习器进行训练,得到训练完成的htm网络和n个独立的lstm基模型。再通过stacking学习器采用logistic回归法对多个基模型的预测结果进行融合得到最终的预测结果。该方法解决了传统的基于阈值原理的异常检测方法无法准确挖掘复杂空间里潜在异常的问题,但选用htm网络和lstm神经网络的训练成本较高,在车辆本地环境中,有限的计算资源将导致训练过程较慢,无法充分发挥这些模型的潜力。
4、公开号为cn110581840a,名称为基于双层异质集成学习器的入侵检测方法,首先采用pkpca算法对原始数据进行降维,得到预处理数据集。再使用预处理数据集对n个分类器进行训练,选择其中表现最好的m个分类器作为优质学习器。通过对优质学习器的输出结果进行加权投票得到最后的入侵检测结果。该方法采用pkpca算法对原始数据进行降维,降低了入侵检测模型的训练成本,提高了模型部署效率。但选用加权投票得出最终结果的方式只适用于捕捉线性关系,适应性不足。
技术实现思路
1、为解决上述技术问题,本发明采用的一个技术方案是:提供一种基于集成学习的车辆入侵检测方法,其特征在于,所述包括:
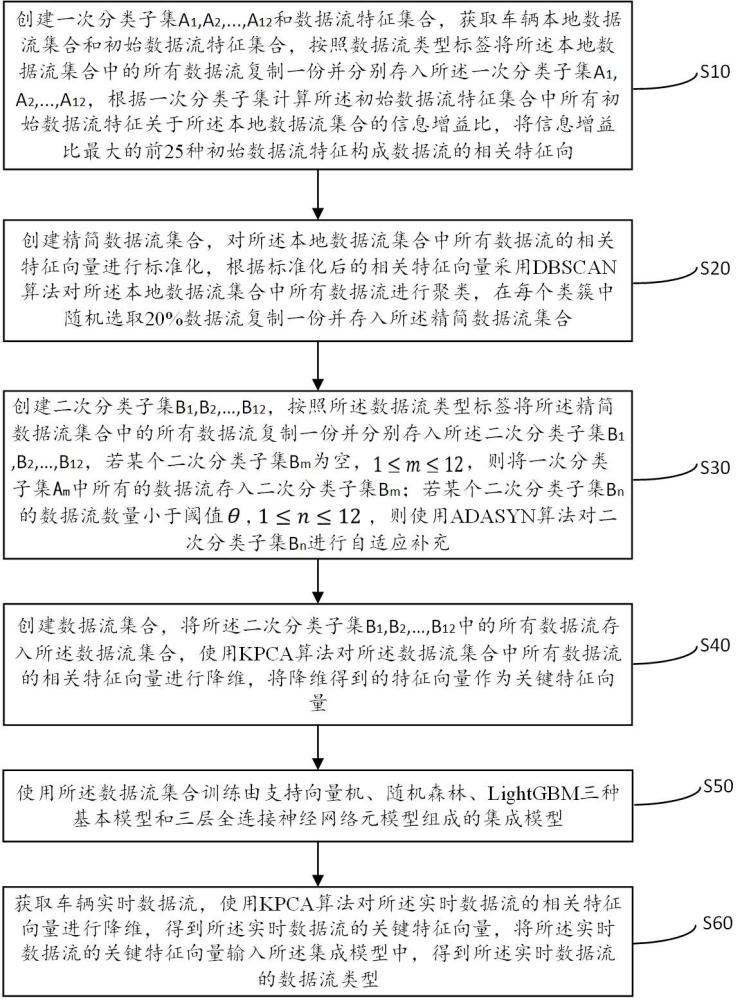
2、s10.创建一次分类子集和数据流特征集合,获取车辆本地数据流集合和初始数据流特征集合,按照数据流类型标签将所述本地数据流集合中的所有数据流复制一份并分别存入所述一次分类子集,根据一次分类子集计算所述初始数据流特征集合中所有初始数据流特征关于所述本地数据流集合的信息增益比,将信息增益比最大的前25种初始数据流特征构成数据流的相关特征向量;
3、s20.创建精简数据流集合,对所述本地数据流集合中所有数据流的相关特征向量进行标准化,根据标准化后的相关特征向量采用dbscan算法对所述本地数据流集合中所有数据流进行聚类,在每个类簇中随机选取20%数据流复制一份并存入所述精简数据流集合;
4、s30.创建二次分类子集,按照所述数据流类型标签将所述精简数据流集合中的所有数据流复制一份并分别存入所述二次分类子集,若某个二次分类子集为空,,则将一次分类子集中所有的数据流存入二次分类子集;若某个二次分类子集的数据流数量小于阈值,,则使用adasyn算法对二次分类子集进行自适应补充;
5、s40.创建数据流集合,将所述二次分类子集中的所有数据流存入所述数据流集合,使用kpca算法对所述数据流集合中所有数据流的相关特征向量进行降维,将降维得到的特征向量作为关键特征向量;
6、s50.使用所述数据流集合训练由支持向量机、随机森林、lightgbm三种基本模型和三层全连接神经网络元模型组成的集成模型;
7、s60.获取车辆实时数据流,使用kpca算法对所述实时数据流的相关特征向量进行降维,得到所述实时数据流的关键特征向量,将所述实时数据流的关键特征向量输入所述集成模型中,得到所述实时数据流的数据流类型。
8、进一步地,所述根据一次分类子集计算所述初始数据流特征集合中所有初始数据流特征关于所述本地数据流集合的信息增益比,包括:
9、s11.计算所述本地数据流集合的信息熵,其计算公式为:
10、;
11、其中,表示所述本地数据流集合,表示所述本地数据流集合大小,表示第i个一次分类子集,表示所述第i个一次分类子集大小;
12、s12.获取所述初始数据流特征集合中第j个初始数据流特征,j初始值为1,根据所述本地数据流集合中所有数据流在所述初始数据流特征上的取值定义所述初始数据流特征的取值范围为,表示所述初始数据流特征的第k种取值;
13、s13.创建k个特征值子集,根据所述初始数据流特征的k种取值将所述本地数据流集合中的所有数据流复制一份并分别存入k个特征值子集;计算所述初始数据流特征关于所述本地数据流集合的信息增益比,其计算公式为:
14、;
15、其中,表示所述初始数据流特征关于所述本地数据流集合的信息增益,其计算公式为:
16、;
17、其中,表示特征值子集与一次分类子集的交集,表示第q个一次分类子集,表示关于所述初始数据流特征的第p个特征值子集,表示特征值子集与一次分类子集的交集大小,表示特征值子集的大小;
18、表示所述初始数据流特征关于所述本地数据流集合的特征熵,其计算公式为:
19、;
20、其中,表示关于所述初始数据流特征的第个特征值子集,表示特征值子集的大小;
21、s14.判断所述初始数据流特征是否为所述初始数据流特征集合中的最后一个初始数据流特征,若是,所述初始数据流特征集合中所有初始数据流特征关于所述本地数据流集合的信息增益比计算完成,若否,j=j+1,转s12。
22、进一步地,所述s10,包括:
23、所述车辆本地数据流集合中的所有数据流包含数据流类型标签和初始数据流特征;
24、所述数据流类型标签由12维的独热编码向量表示,所述独热编码向量表示数据流所属的数据流类型,所述数据流类型包含:正常流量、dos攻击、ddos攻击、fuzzy攻击、spoofing攻击、ssh-patator攻击、ftp-patator攻击、web攻击、port-scan攻击、infiltration攻击、botnet攻击、未知流量;
25、所述初始数据流特征包括:
26、基本流量统计特征:目标端口、流持续时间、正向数据包总数、反向数据包总数、正向数据包总长度、反向数据包总长度、正向数据包长度最大值、正向数据包长度最小值、反向数据包长度最大值、反向数据包长度最小值、每秒流量字节、每秒流量包数;
27、流间隔时间特征:流交互到达时间平均值、流交互到达时间标准差、流交互到达时间最大值、流交互到达时间最小值、正向交互到达时间总和、正向交互到达时间平均值、正向交互到达时间标准差、正向交互到达时间最大值、正向交互到达时间最小值、反向交互到达时间总和、反向交互到达时间平均值、反向交互到达时间标准差、反向交互到达时间最大值、反向交互到达时间最小值;
28、tcp标志特征:正向psh标志数、反向psh标志数、正向urg标志数、反向urg标志数、fin标志数、syn标志数、rst标志数、psh标志数、ack标志数、urg标志数、cwe标志数、ece标志数;
29、数据包长度特征:最小数据包长度、最大数据包长度、数据包长度平均值、数据包长度标准差、数据包长度方差;
30、连接状态特征:下行/上行比率、正向初始窗口字节数、反向初始窗口字节数、正向有效数据包数、正向最小段大小;
31、活跃连接和闲置连接特征:活跃连接的平均值、活跃连接的标准差、活跃连接的最大值、活跃连接的最小值、闲置连接的平均值、闲置连接的标准差;
32、数据包特征:正向数据包平均字节数、正向数据包平均包数、正向数据包平均速率、反向数据包平均字节数、反向数据包平均包数、反向数据包平均速率;
33、子流特征:子流正向数据包数、子流正向字节数、子流反向数据包数、子流反向字节数。
34、进一步地,所述s20,包括:
35、所述dbscan算法使用欧式距离计算本地数据流集合中数据流之间的距离,其计算公式为:
36、;
37、其中,表示所述本地数据流集合中任意数据流的相关特征向量,表示所述本地数据流集合中与不同的任意数据流的相关特征向量,表示数据流与数据流之间的欧式距离,表示相关特征向量的第个相关特征,表示相关特征向量的第个相关特征。
38、进一步地,所述s30,包括:
39、所述阈值的值为,其中,表示对向下取整,,表示精简数据流集合,表示精简数据流集合大小。
40、进一步地,所述使用adasyn算法对二次分类子集进行自适应补充,包括:
41、s31.获取数据流数量小于阈值的二次分类子集,获取所述二次分类子集中的第个数据流,初始值为1,计算所述第个数据流与所述二次分类子集中其余所有数据流之间关于相关特征向量的欧式距离,选择欧式距离最小的个数据流作为所述第个数据流的邻居数据流;
42、s32.计算所述第个数据流的加权分布,所述加权分布的计算公式为:
43、;
44、其中,,表示所述第个数据流的数据流类型,表示所述第个数据流的第个邻居数据流的数据流类型;
45、s33.判断所述第个数据流是否为所述二次分类子集中的最后一个数据流,若是,转s34,若否,,转s31;
46、s34.计算所述二次分类子集中所有数据流的补充比例,其计算公式为:
47、;
48、其中,表示所述二次分类子集中的任意数据流,表示数据流r的补充比例,表示数据流r的加权分布,表示所述二次分类子集的大小,表示所述二次分类子集中第个数据流的加权分布;
49、s35.对所述二次分类子集中的每个数据流生成个合成数据流,将生成的合成数据流作为数据流存入所述二次分类子集,所述合成数据流由25维的相关特征向量表示,所述合成数据流的相关特征的生成公式如下:
50、;
51、其中,表示所述二次分类子集中的任意数据流,表示根据数据流生成的合成数据流的第个相关特征,,表示数据流的第个相关特征,表示从所述数据流的邻居数据流中随机选取的一个数据流,表示数据流的第个相关特征,表示区间[0,1]上的随机数。
52、进一步地,所述使用kpca算法对所述数据流集合中所有数据流的相关特征向量进行降维,包括:
53、s41.获取所述数据流集合中的数据流总数量为m,构建一个m行m列的核矩阵km,所述核矩阵km的元素为:
54、;
55、其中,表示所述核矩阵km中第i行第j列的元素值,,,sdb表示所述数据流集合,表示数据流集合sdb中第i个数据流与第j个数据流之间关于相关特征向量的欧式距离,表示所述数据流集合sdb中所有数据流之间关于相关特征向量的欧式距离的平均值;
56、s42.对所述核矩阵km进行中心化得到新的核矩阵,所述新的核矩阵的元素为:
57、;
58、其中,表示所述核矩阵中第i行第j列的元素值,,,表示所述核矩阵km中第i行第j列的元素值,表示所述核矩阵km第i行所有元素的平均值,表示所述核矩阵km第j列所有元素的平均值,表示所述核矩阵km中所有元素的平均值;
59、s43.对所述新的核矩阵进行特征分解,得到其特征值和与特征值对应的特征向量,对所述特征向量进行归一化,得到归一化后特征向量,取最大的15个特征值对应的归一化后的特征向量构成一个m行15列的特征矩阵x;
60、s44.利用所述特征矩阵x将所述数据流集合中所有数据流的相关特征向量投影至特征空间中,得到所有数据流的关键特征向量,所述关键特征向量为15维,表示为,表示所述数据流集合中的任意数据流,表示任意数据流的关键特征向量,表示所述任意数据流的第个关键特征,,所述关键特征的计算方式为:
61、;
62、其中,表示所述任意数据流的相关特征向量,表示所述任意数据流与所述数据流集合sdb中第个数据流之间关于相关特征向量的欧式距离,表示所述数据流集合sdb中所有数据流之间关于相关特征向量的欧式距离的平均值,表示所述特征矩阵的第行第列的元素值,表示所述数据流集合sdb中的数据流总数量。
63、进一步地,所述s50,包括:
64、s51.将所述数据流集合随机划分为70%的训练集和30%的验证集,将所述训练集中所有数据流的关键特征向量和数据流类型标签分别输入支持向量机、随机森林、lightgbm三种模型中进行训练,将验证集输入训练好的三种模型,得到验证集在三种模型上的输出,所述验证集在三种模型上的输出为三个12维的概率向量,所述概率向量表示模型通过计算得到验证集分别为12种数据流类型的概率,将验证集在三种模型上输出的概率向量拼接成一个36维的集成特征向量;
65、s52.将所述集成特征向量和所述验证集的数据流类型标签输入三层的全连接神经网络进行训练,当迭代次数大于5000次或者准确度达到99.9%时停止训练,所述全连接神经网络使用交叉熵作为损失函数,所述全连接神经网络的输出为一个12维的概率向量。
66、进一步地,所述s60,包括:
67、获取车辆实时数据流,选取所述实时数据流的相关特征构成相关特征向量,使用kpca算法对所述实时数据流的相关特征向量进行降维,得到所述实时数据流的关键特征向量,将所述实时数据流的关键特征向量分别输入训练好的支持向量机、随机森林、lightgbm三种模型中,得到所述实时数据流在三种模型上输出的三个概率向量,将所述三个概率向量组合成一个集成特征向量,将所述集成特征向量输入训练好的全连接神经网络,得到一个12维的概率向量,将所述12维的概率向量中最大概率所属的数据流类型作为所述实时数据流的数据流类型。
68、一种基于集成学习的车辆入侵检测装置,其特征在于,包括:
69、数据预处理模块:用于计算本地车辆数据集中所有初始数据流特征的信息增益比,根据信息增益比选取相关特征向量,标准化所述相关特征向量后进行dbscan聚类,在每个dbscan类簇中随机选取20%数据流,得到精简数据流集合;
70、数据生成模块:用于将所述精简数据流集合中的数据流存入二次分类子集,对类别不平衡的二次分类子集进行自适应补充,得到数据流集合;
71、特征工程模块:用于对所述数据流集合中所有数据流的相关特征向量使用kpac算法进行降维,得到关键特征向量;
72、集成学习模块:用于使用所述数据流集合的关键特征向量训练由支持向量机、随机森林、lightgbm三种基本模型和三层全连接神经网络元模型组成的集成模型,以及使用训练好的集成模型来确定车辆实时数据流的数据流类型。
73、本发明的有益效果是:
74、利用信息增益比对数据流初步降维和归一化处理,然后使用dbscan算法进行聚类,这一流程解决了将高维特征直接进行聚类可能引发的维度灾难。使用kpca算法对数据流的相关特征向量进行降维,能够减少模型的训练成本以及降低过拟合风险。通过adasyn算法对于不平衡的数据流类型进行自适应的补充,解决了数据流样本不平衡的问题,提高了模型的泛化能力。基于支持向量机、随机森林以及lightgbm模型的集成学习模型,融合三种基础模型的优势对数据流进行初步分类,然后通过全连接神经网络综合初步分类结果得到最终的数据流类型,能够保证数据流异常检测的准确率和稳定性。
- 还没有人留言评论。精彩留言会获得点赞!