血糖浓度预测方法与流程
本发明涉及一种血糖浓度预测方法,更具体地讲,涉及一种基于“m+n”理论的血糖浓度预测方法。
背景技术:
血糖是人体一项极为重要的生理指标,对维持机体,尤其是脑、神经的正常生理功能有着非常重要的意义。目前血糖浓度测量方法主要有自动生化仪测量法和快速血糖仪测量法,都是通过采血的方式来检测血糖值,会给患者带来创伤,对患者长时间的血糖监测不利,因此无创血糖检测的实现具有十分重要的现实意义。
然而由于信号微弱、测量条件变化复杂、人体生理指标和血液中非测量组分等因素对测量的影响进而导致血糖预测精度不高,达不到临床使用需求,是目前近红外无创光谱血糖测量突出的难题。因此探究新的测量方法以克服测量条件、人体生理背景等对光谱测量的影响来提高预测精度,对全面实现血糖的无创测量具有重要意义。
技术实现要素:
本发明的实施例提供一种血糖浓度预测方法,其能够全面考虑测量条件、人体生理背景等对血糖浓度测量的影响,从而有效提高血糖浓度的预测精度。
根据本发明的示例性实施例的一方面,提供了一种血糖浓度预测方法,所述方法可以包括:采集多个样本测试者的生理数据;向所述多个样本测试者的测量部位发射预设波长的光;采集穿透测量部位的光的光谱数据;直接测量所述多个样本测试者的血糖浓度真值和非血糖浓度数据;保存所述多个样本测试者的生理数据、光谱数据、血糖浓度真值和非血糖浓度数据;根据所述多个样本测试者的生理数据、光谱数据、血糖浓度真值和非血糖浓度数据,采用多元校正算法建立基于“m+n”理论的血糖浓度预测模型,其中,所述多个样本测试者的生理数据、光谱数据和非血糖浓度数据作为基于“m+n”理论的血糖浓度预测模型的输入,血糖浓度真值作为基于“m+n”理论的血糖浓度预测模型的输出;根据建立的基于“m+n”理论的血糖浓度预测模型,从待测者的穿透测量部位的光的光谱数据、生理数据和非血糖浓度数据预测待测者的血糖浓度。
生理数据可以包括年龄、腰围身高比例、血压和体温中的至少一种。
非血糖浓度数据可以包括:甘油三酯的浓度、高密度脂蛋白胆固醇的浓度和血清总胆固醇的浓度。
所述方法还可以包括:采集所述多个样本测试者的与测量条件相关的数据;根据所述多个样本测试者的与测量条件相关的数据、生理数据、光谱数据、血糖浓度真值和非血糖浓度数据,采用多元校正算法建立基于“m+n”理论的血糖浓度预测模型,其中,所述多个样本测试者的与测量条件相关的数据、生理数据、光谱数据和非血糖浓度数据作为基于“m+n”理论的血糖浓度预测模型的输入,血糖浓度真值作为基于“m+n”理论的血糖浓度预测模型的输出。
与测量条件相关的数据可以包括与测量部位、接触压力、测量时间、检测距离、环境温湿度和电压波动中的至少一种相关的数据。
所述方法还可以包括:根据基于“m+n”理论的血糖浓度预测模型来从待测者的与测量条件相关的数据、生理数据、光谱数据和非血糖浓度数据预测待测者的血糖浓度。
多元校正算法可以是偏最小二乘法、人工神经网络、支持向量机、小波变换算法中的一种。
所述方法还可以包括:利用单沿提取法处理所述多个样本测试者的穿透测量部位的光的光谱数据;根据处理后的光谱数据、所述多个样本测试者的生理数据、血糖浓度真值和非血糖浓度数据,建立基于“m+n”理论的血糖浓度预测模型。
所述方法还可以包括:利用单沿提取法处理待测者的穿透测量部位的光的光谱数据;根据基于“m+n”理论的血糖浓度预测模型,从待测者的处理后的光谱数据、生理数据和非血糖浓度数据预测待测者的血糖浓度。
通过使用根据本发明的示例性实施例的血糖浓度预测方法,能够有效提高血糖浓度的预测精度,有利于开发出精确的无创血糖浓度测量方法。
将在接下来的描述中部分阐述本发明总体构思另外的方面和/或优点,还有一部分通过描述将是清楚的,或者可以经过本发明总体构思的实施而得知。
附图说明
图1是根据本发明的实施例的基于“m+n”理论的血糖浓度预测方法的理论框图。
图2是根据本发明的实施例的基于“m+n”理论的血糖浓度预测系统的框图。
图3是根据本发明的实施例的利用单沿提取法处理的动态光谱数据的曲线图。
图4是根据本发明的实施例的基于“m+n”理论的血糖浓度预测模型的结构图。
图5是根据本发明的实施例的示出基于“m+n”理论的血糖浓度预测值、未考虑非测量组分影响的预测值与真实值之间的比较的图表。
图6是根据本发明的实施例的示出基于“m+n”理论的血糖浓度预测值与真值的相对误差的曲线图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
“m+n”理论从误差理论的角度分析测量系统和测量过程,将被测对象自身的差异和其他干扰因素一同归于整个测量系统中,系统地考虑两者对预测精度的影响。本发明研究血糖浓度预测中的影响因素,根据“m+n”理论将影响因素分成“m”因素和“n”因素,并根据影响因素的特性分别采用不同的方法减小对应的影响因素对血糖浓度预测精度的影响。
“m+n”理论中“m”表示被测对象中影响测量成分的预测精度的m种非测量因素,“n”表示影响测量成分的预测精度的n种外界干扰因素。基于“m+n”理论提高预测精度的关键在于将“m”因素与“n”因素同等对待,判断每个因素是系统误差还是随机误差,同时还提出必要的减小误差的解决方法。
图1是根据本发明的实施例的基于“m+n”理论的血糖浓度预测方法的理论框图。该方法的测量对象是人体血液中的血糖,测量系统是用于获取人体血液信息的光谱仪。
如图1所示,首先,对测量对象及其相关联的测量系统进行整体分析,分析对象包括关于人体的因素101和关于测量系统的因素102,关于人体的因素101包含了影响血糖浓度预测的m种非测量组分或因素,关于测量系统的因素102包含了影响血糖浓度预测的n种外界影响因素。
然后,根据所述分析对象全面地归纳出“m”因素103和“n”因素104,“m”因素103表示影响血糖浓度预测的m种非测量组分或因素,“n”因素104表示影响血糖浓度预测的n种外界影响因素。
下一步,依据“m”因素103和“n”因素104各自的特性,将“m”因素103和“n”因素104分类为系统误差影响因素105和随机误差影响因素106。系统误差具有规律性定值,或者与被测量的血糖浓度有确定的相关关系,或者具有可预测性;而随机误差具有变化微小的特性或者无统计规律可言。
如图1所示,“m”因素103包括系统误差影响因素e1和随机误差影响因素e2,“n”因素104包括系统误差影响因素e3和随机误差影响因素e4。系统误差影响因素e1表示关于人体的影响血糖浓度预测的系统误差影响因素,包括被测人体的血液中影响血糖浓度预测的除血糖以外的血液成分(例如,甘油三酯、高密度脂蛋白胆固醇、血清总胆固醇等)的非血糖浓度数据以及人体相关的生理数据(例如,腰围身高比例、年龄、血压、体温等)。系统误差影响因素e3表示关于测量系统的影响血糖浓度预测的系统误差影响因素,包括与测量条件相关的系统误差影响因素,例如:测量部位、接触压力、测量时间、检测距离、环境温湿度、电压波动等。随机误差影响因素e2关于人体的影响血糖浓度预测的随机误差影响因素,包括人体的肢体运动等。随机误差影响因素e4关于测量系统的影响血糖浓度预测的随机误差影响因素,包括测量仪器中的暗电流等。
在分析了系统误差影响因素105和随机误差影响因素106之后,可以根据各个因素的不同属性采用不同的处理方法,以减小误差和提高预测精度。根据系统误差影响因素105的属性,可以采用相应的系统误差处理方法109减小系统误差。系统误差处理方法109包括:(1)使影响因素固定不变,以在测量过程中剔除该影响因素产生的系统误差;(2)通过补偿方法(如温度补偿)来提高预测精度;(3)通过样本分布的选择来提高建模预测精度。根据随机误差影响因素106的属性,可以采用相应的随机误差处理方法110减小随机误差。随机误差处理方法110包括:(1)最小化处理;(2)多次测量求平均值;(3)提高测量系统的灵敏度;(4)扩展影响因素的变化范围以继续探索其影响模式。
在示例性实施例中,根据上述各个因素的误差特性的差异采用不同的处理方法来降低各个因素对血糖浓度预测的不良影响。
基于光电容积脉搏波原理的动态光谱法,能够利用静脉血管收缩舒张下对光吸收度的改变来直接提取多个波长下反映静脉血液成分的光密度,从理论上降低了个体差异和测量条件带来的误差。在示例性实施例中,通过光谱仪采集人体静脉血的光谱数据,以基于动态光谱原理获取人体血液信息。同时,考虑到临床实际应用情况,测量条件中的测量部位选定为食指(其它身体部位也是可行的),测量时间和检测距离均设定为固定值,例如,每个测试者的测量时间为20s,检测距离为0(食指完全遮盖住光谱仪的光纤入口)。这样可以减小测量部位、测量时间和检测距离对血糖浓度预测造成的误差。
在动态光谱原理的基础上,进一步采用单沿提取法处理光谱数据以减小接触压力等测量条件造成的误差。单沿提取法的基本思想是用统计平均的方法提取各波长下峰峰值的对应比例关系,并非直接提取峰峰值。单沿提取法利用了对数脉搏波的叠加平均效应来剔除和校正各波长下脉搏波的波形误差,同时也利用了单沿动态光谱的叠加平均效应剔除含有粗大误差的单沿动态光谱,从这两方面能有效降低误差对动态光谱波形的不良影响。因此,在数据预处理阶段选取单沿提取法提取动态光谱数据,以利于减小“n”因素中的接触压力造成的系统误差,从而为后续的血糖浓度预测模型的建模和预测奠定基础。
根据本发明的示例性实施例,在血糖浓度预测模型的建模过程中,将利用基于动态光谱原理的单沿提取法处理的光谱数据以及样本测试者静脉血液中的甘油三酯的浓度、高密度脂蛋白胆固醇的浓度、血清总胆固醇的浓度、样本测试者的年龄、腰围身高比例、血压、体温、测量环境的环境温湿度和光谱仪的电压波动等系统误差影响因素都纳入血糖浓度预测模型中,从而全面地考虑上述所有因素对血糖浓度预测值的影响。
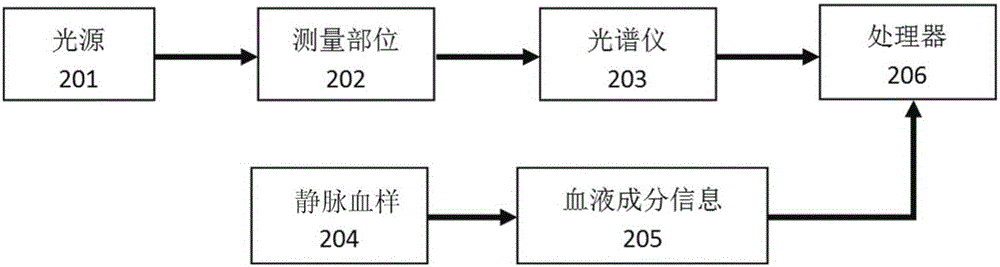
图2是根据本发明的实施例的基于“m+n”理论的血糖浓度预测系统的框图。在示例性实施例中,光源201为50w的溴钨灯,测量部位202是食指,使用的光谱仪203为avaspec-hs1024x58tec高灵敏度型光纤光谱仪,波长范围为200-1160nm。光源201发出的光聚焦透过测量部位202后,由光谱仪203直接进行光谱数据的采集。根据在脉搏波的采集过程中的光强及其它测量条件的影响,实施例中选取的波长范围是580.43nm-1150.3nm,波长间隔为0.94nm,约606个波长。测量系统中还包括与光谱仪203连接的处理器206,处理器206能够与光谱仪203通信,接收并存储光谱数据以及从外部输入的血液成分信息205。
在一个示例性实施例中,选定了239名测试者进行实验。测试者平卧放松并将食指指端完全遮挡住光谱仪203的光纤入口,光谱仪203采集特定测量时间内的光谱数据,然后将光谱数据发送给与光谱仪203连接的处理器206,以由处理器206进行数据存储和处理。在光谱数据采集完成后,由工作人员对测试者进行静脉抽血获得测试者的静脉血样204,工作人员可以从静脉血样204中提取测试者的血液成分信息,即,血糖浓度真值以及甘油三酯的浓度、高密度脂蛋白胆固醇的浓度和血清总胆固醇的浓度等其它血液组分信息。工作人员将收集的血液成分信息输入到处理器206中,还在处理器206中记录测试者的年龄、腰围身高比例、血压和体温,同时记录测量过程中的环境温湿度、光谱仪的电压波动情况。在示例性实施例中,通过重复以上步骤采集到239组光谱数据样本。
为了提高基于动态光谱的多波长血糖浓度预测建模方法的稳定性和可靠性,需要评判动态光谱数据的质量,本申请采用的方法是利用动态光谱数据稳定波长数的多少来进行光谱数据的质量的评判。稳定波长数是各波长下对数脉搏波频域基波分量频率持续一致的波长个数。稳定波长数越大则表明各波长下对数脉搏波越相似,即动态光谱数据质量越高。根据稳定波长数这一标准在原始的239组光谱数据样本中选取了192组光谱数据样本,以用于血糖浓度预测模型的建模和预测分析。
处理器206对选取的192组光谱数据样本进行单沿提取。单沿提取法的提取步骤如下:
(1)对采集到的ppg信号取对数,将其中强度较大信号进行叠加平均,作为脉搏波的模板;
(2)找到每个周期内的波峰与波谷值,通过峰谷值来确定上升沿和下降沿,将所有波长的有效上升沿与模板的有效上升沿进行最小二乘拟合,以此来校正对数脉搏波的上升沿;
记任意波长λ下对数脉搏波在时域上的表达式为等式(1):
yλ(t)=δaλ·x(t)+dcλ(1)
其中,δaλ为静脉血液的吸光度值;x(t)为对数脉搏波的波形函数;dcλ为对数脉搏波的直流分量,对数脉搏波随时间t变化的出射光强为yλ(t)。
由于各波长对数脉搏波的波形具有相似性,即x(t)是不变的,则对数脉搏波模板的出射光强值y0(t)可表示为等式(2)
y0(t)=δa0·x(t)+dc0(2)
其中,δa0,dc0分别为对数脉搏波模板的平均吸光度和平均直流分量;
将等式(1)和(2)合并,可以得到等式(3):
从式(3)可以看出,对数脉搏波模板的出射光强y0(t)为自变量,各波长对数脉搏波的出射光强yλ(t)为因变量,两者之间是线性关系;斜率a=δaλ/δa0为经过最小二乘拟合得到的各波长的拟合斜率,将所有波长下的拟合斜率作为动态光谱的等效值,构成一系列单沿动态光谱。
(3)计算每一个波长下的单沿动态光谱与叠加平均值的欧式距离di(x,y)(i为单沿动态光谱的个数),这里采用欧式距离来判定单沿动态光谱与叠加平均值的相似性,欧式距离是时间序列相似性研究中最广泛使用的相似性度量方法,其几何表达式如下:
欧式距离d(x,y)越小,说明单沿动态光谱与叠加平均值之间的相似度越高。计算欧式距离di(x,y)的叠加平均值
(4)按照判别粗大误差的莱以特准则(3σ准则),如下所示:
|δi|>3σ(8)
如果某单沿动态光谱满足莱以特准则,则可以认为该单沿动态光谱含有粗大误差,应予以剔除;否则认为该单沿动态光谱中不含有粗大误差。对剔除粗大误差后的单沿动态光谱再进行上述操作步骤,直到不再存在含有粗大误差的单沿动态光谱为止,从而筛选得到最终的有效单沿动态光谱数据,之后对有效单沿动态光谱数据进行叠加平均作为最终的归一化的单沿动态光谱输出。如此,通过单沿提取法处理动态光谱数据可以减小“n”因素中的接触压力等造成的误差。
图3示出了示例性实施例的利用单沿提取法处理的动态光谱数据的曲线图。除了单沿提取法,还可以采用峰峰值提取法、频域提取法、快速数字锁定放大器提取法、差值提取法等动态光谱提取法来处理动态光谱数据。
下面参照图4描述基于“m+n”理论的血糖浓度预测模型的建模过程。图4是根据本发明的实施例的基于“m+n”理论的血糖浓度预测模型的结构图。根据本发明的实施例,基于多元校正算法建立血糖浓度预测模型。
偏最小二乘法(partialleastsquareregression,pls)是一种数学优化技术,它提供一种线性回归建模的方法。偏最小二乘法是基于因子分析的多变量校正方法,其数学基础为多元线性回归算法(multiplelinearregression,mlr)和主成分回归算法(principalcomponentregression,pcr)。pls具有将多元回归问题转化为若干一元回归问题的特点,适合用于本次实验中样本数较少而变量数较多的过程建模。因此,在示例性实施例中,基于偏最小二乘法建立血糖浓度预测模型。
在一般的多元线性回归分析模型中,设有p个自变量x1,x2,…xp,q个因变量y1,y2,…yq,为了研究自变量与因变量之间的统计关系,观测n个采样点,由此构成了自变量与因变量的数据矩阵x=[x1,x2,…xp]n*p,y=[y1,y2,…yq]n*q。偏最小二乘法分别在x和y中提取第一成分t1和u1,使得t1为x1,x2,…xp的线性组合,u1为y1,y2,…yq的线性组合,且要满足以下两个条件:
(1)t1和u1要尽可能多的携带x与y数据矩阵中的变异信息;
(2)成分t1和u1的相关程度要达到最大使x的成分t1对y的成分u1的解释能力最强。
在pls建模过程中,选择合适的主成分数直接关系到模型的实际预测能力。提取符合以上两个条件的成分t1和u1,然后用pls分别实施x对t1和y对u1的回归。若回归方程能够达到所需精度,可终止算法;否则,将利用x被t1解释后的残差和y被u1解释后的残差来进行第二成分t2和u2的提取。不断重复,直到达到一个满意的精度为止。若最终对自变量x共提取了m个成分t1,t2,…,tm,pls将通过实施yk(k=1,2,…,q)对t1,t2,…,tm的回归,最终得到yk关于x1,x2,…xp的回归方程。
为了数学推导方便,将x、y矩阵分别做标准化处理得到e0=(e01,e02,…,e0p)n*p,f0=(f01,f02,…,f0q)n*q。设t1=e0ε1和u1=f0θ1,其中ε1和θ1为单位矩阵且满足
由拉格朗日算法可得出ε1和θ1:
ε1和θ1分别是
式中,e1和f1分别为以上两个回归方程的残差矩阵,回归系数向量p1和q1表示为:
用残差矩阵e1和f1取代e0和f0求得ε2和θ2,并得到第二个成分t2和u2,建立回归方程,有
同样的,e2和f2为残差矩阵,回归系数向量是:
以此类推,设秩为a,可得到
由于t1,…,ta均可以表示为e0中各向量的线性组合,(3-15)与(3-16)结合可表示为(3-17),其中
根据上述理论,基于偏最小二乘法研究血糖浓度预测模型的输出输入关系。
根据本发明的实施例,将“m”因素103中的系统误差影响因素e1和“n”因素104中的系统误差影响因素e3都作为血糖浓度预测模型的输入变量(即,自变量),将血糖浓度预测值作为血糖浓度预测模型的输出变量(即,因变量)。如此,基于偏最小二乘法建立多输入单输出的模型。
在本发明中,建模方法不仅限于在此示出的偏最小二乘法,还可以考虑诸如人工神经网络、支持向量机、小波变换算法等的多元校正算法来进行血糖浓度预测模型的建模。
如图4所示,在这个示例性实施例中,将参照图3获得的样本测试者的甘油三酯的浓度x1、高密度脂蛋白胆固醇的浓度x2、血清总胆固醇的浓度x3、腰围身高比例x4、年龄x5、血压x6、体温x7、环境温湿度x8、光谱仪的电压波动x9以及单沿提取法处理后的动态光谱数据x10作为血糖浓度预测模型的输入变量(即,p个自变量,p=10,根据实际需求,自变量个数不仅限于此),将样本测试者的血糖浓度真值(即,血糖浓度预测模型的血糖浓度预测值)y作为血糖浓度预测模型的输出变量(即单个因变量,q=1)。其中,样本测试者的甘油三酯的浓度x1、高密度脂蛋白胆固醇的浓度x2、血清总胆固醇的浓度x3、腰围身高比例x4、年龄x5、血压x6、体温x7属于系统误差影响因素e1,环境温湿度x8、光谱仪的电压波动x9属于系统误差影响因素e3,单沿提取法处理后的动态光谱数据x10是相对于系统误差影响因素e3中的测量部位、接触压力等的因变量。
在前面描述的192组样本中随机选取144例样本进行建模,剩下的48例样本进行预测和对比分析。基于所述144例样本,采用偏最小二乘法研究输入变量与输出变量之间的关系,建立考虑多个因素综合作用的血糖浓度预测模型,以符合复杂的应用条件,提高血糖浓度的预测精度和预测范围。
传统的血糖浓度预测模型仅基于采集的原始动态光谱数据来进行预测,至少没有考虑到系统误差影响因素e1对血糖浓度预测的影响。然而,与已有的血糖浓度预测模型相比,根据本发明的实施例的基于“m+n”理论的血糖浓度预测模型不仅考虑到了系统误差影响因素e1还考虑到系统误差影响因素e3。在实验研究过程中,工作人员将基于“m+n”理论的血糖浓度预测模型与传统的血糖浓度预测模型的预测精度进行了对比分析。
根据本发明的实施例,基于“m+n”理论的血糖浓度预测模型的血糖浓度预测值和血糖浓度真值的相关系数为0.9295,相对误差为±0.0888;而传统的血糖浓度预测模型的血糖浓度预测值和血糖浓度真值的相关系数为0.8285,相对误差为±0.1493。上述数据表明:就预测精度而言,基于“m+n”理论的血糖浓度预测方法优于传统预测方法。图5示出了根据本发明的实施例的基于“m+n”理论的血糖浓度预测值、传统的血糖浓度预测值与血糖浓度真值之间的比较的图表。图6示出了根据本发明的实施例的基于“m+n”理论的血糖浓度预测值与真值的相对误差的曲线图。
“m+n”理论从误差理论的角度阐明了在光谱分析中m种非测量组分(即“m”因素)和n种外界干扰因素(即“n”因素)对预测精度的影响。基于“m+n”理论的血糖浓度预测方法将被测对象和其它影响因素一同归于整个预测模型中,全面综合地考虑了m因素和n因素对血糖浓度预测精度的影响。本发明的实施例通过将“m”因素中的系统误差影响因素e1纳入血糖浓度模型,并利用单沿提取法减小“n”因素中的接触压力对血糖浓度预测值带来的不良影响,使得血糖浓度预测精度得以提高。通过对比分析,可以发现基于“m+n”理论的血糖浓度预测方法可以达到较好的预测精度。
上述实施例中的实施方案可以进一步组合或者替换,且实施例仅仅是对本发明的优选实施例进行描述,并非对本发明的构思和范围进行限定,在不脱离本发明设计思想的前提下,本领域中专业技术人员对本发明的技术方案做出的各种变化和改进,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!