一种基于声音刺激的视觉图像感知系统和方法与流程
本发明属于信号处理领域,特别涉及一种基于声音刺激的视觉图像感知系统和方法。
背景技术:
市场上能够辅助全盲病人生活的医疗产品少之又少。目前已通过美国fda认证的视障辅助设备主要分为两类:第一类是需要手术植入的人工视觉系统,它先通过摄像头采集植入者前方的图像信息,然后编码生成电脉冲信号,最后再用植入到病人视网膜上的电极阵列刺激视神经,从而帮助病人恢复一定的光感。这类设备的主要问题在于,具有一定的手术风险,而且部分病人不适合进行手术植入(视神经损伤等),再加上昂贵的价格(一套要10万美元以上),使得大部分病人没有条件使用人工视觉类的设备。另一类设备是将二维的图像信息,通过其他感知通道传递给盲人,盲人再在脑中将的到的信息进行“翻译”,从而获知一定的图像信息。比如用电极阵列刺激皮肤或舌头,通过触觉接收二维图像信息,再将其转换成“视觉感知”。此类设备特点是没有风险,价格相对便宜,但是使用不够方便且不够美观,需要将电极贴在头皮上或者含在嘴里。
技术实现要素:
有鉴于此,本发明的目的在于提供一种既不需要手术植入,成本低,使用方便,又能够给盲人传递图像信息的系统,将会解决很多盲人基本生活上的困难,造福社会。
为达到上述目的,本发明提供了一种基于声音刺激的视觉图像感知系统,包括眼镜架、体外机和耳机,其中眼镜架上设置摄像头;体外机包括图像处理模块、声音合成模块和声音播放模块,
所述摄像头与体外机的图像处理模块连接,摄像头获取二维或三维图像,图像处理模块将二维或三维图像进行深度检测、二值化、轮廓提取和字符识别后,输出给声音合成模块进行声音处理后,将声音信号传输给声音播放模块通过气导或骨导耳机播放。
优选地,所述图像处理模块至少包括依次连接的深度检测单元、二值化单元、轮廓提取单元和字符识别单元。
优选地,所述摄像头包括一个或两个af镜头。
优选地,所述声音合成模块包括头相关传递函数滤波单元。
优选地,所述声音合成模块对于图像对应的声音合成处理根据下式:
a(i)=s*h(i)*g(i)
a=a(1)→a(2)→a(3)→a(4)→...→a(n)
其中,s为基准声音的频域信号;h(i)为平面上第i个点所对应的头相关传递函数;g(i)为第i个声音的增益大小,通过物体的远近来判断;a(i)为声音空间中第i个声音;a为将平面上所有对应的声音连续播放后,形成的可传递当前二维或三维图像的声音信号。
基于上述目的,本发明还提供了一种采用上述系统的基于声音刺激的视觉图像感知方法,包括以下步骤:
摄像头采集获取二维或三维图像,进行图像处理,获得简化二维或三维图像;
根据简化二维或三维图像,进行声音合成处理;
将处理后的声音传输给耳机进行播放。
优选地,所述图像处理包括以下步骤:
预处理,将二维或三维图像进行深度检测,然后灰度化后进行二值化和去噪;
轮廓提取,依次进行图像剪切、图像细化和图像压缩;
字符识别,输出采集的二维或三维图像中的字符或边缘轮廓。
优选地,所述声音合成根据头相关传递函数进行。
优选地,所述声音合成处理包括以下步骤:
第一步:假设平面的维度是n行n列,那么就从最左上角的节点开始遍历,记为第1圈,坐标位置表示为(1,n),如果有信号则进行第二步,没有信号则进入步骤第四步;
第二步:当遍历到有信号的节点时,将此节点设为当前节点,首先播放该节点的声音信号,然后选择所处方位与当前遍历方向一致的节点遍历,若有信号则重复步骤第二步,直至遍历完成;若无信号则进入步骤第三步;
第三步:由于处在当前遍历方向的节点无信号,那么就从此节点接着顺时针围绕当前节点旋转遍历;如果遇到有信号的节点,则进入第二步,若没有,则进入第四步;
第四步:如果之前遍历到第i圈,那么继续遍历第i+1圈,节点坐标依次为(i,n),(i,n-1),(i,n-2)...(i,n-i+1),(i-1,n-i+1),(i-2,n-i+1)...(1,n-i+1),如果这些节点中有信号则继续第二步,无信号则继续遍历更外侧的第i+2圈,直至遇到有信号的节点,或遍历完平面所有节点。
优选地,所述声音合成处理根据下式:
a(i)=s*h(i)*g(i)
a=a(1)→a(2)→a(3)→a(4)→...→a(n)
其中,s为基准声音的频域信号;h(i)为平面上第i个点所对应的头相关传递函数;g(i)为第i个声音的增益大小,通过物体的远近来判断;a(i)为声音空间中第i个声音;a为将平面上所有对应的声音连续播放后,形成的可传递当前二维或三维图像的声音信号。
本发明的有益效果在于:本发明采用头相关转移函数,对于任何一个声音,都可以处理成从特定方向传来的感觉,并通过耳机播放给病人。这就意味着,对于任何一个简单的二维图像,都可以通过这种连续处理声音的方式,在听觉空间中生成一个同样的图像,并被感知到。也就是将声音变成一支笔,勾勒出你所希望的图形。而盲人由于长期依靠听觉生活,所以在听声辨位方面普遍要强于常人,所以本发明可以起到更好的效果来帮助盲人通过声音感知物体的轮廓,形状,甚至距离远近,方便他们进行简单的物体识别,会对盲人的生活带来极大的帮助。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明实施例1的一种基于声音刺激的视觉图像感知系统结构示意图;
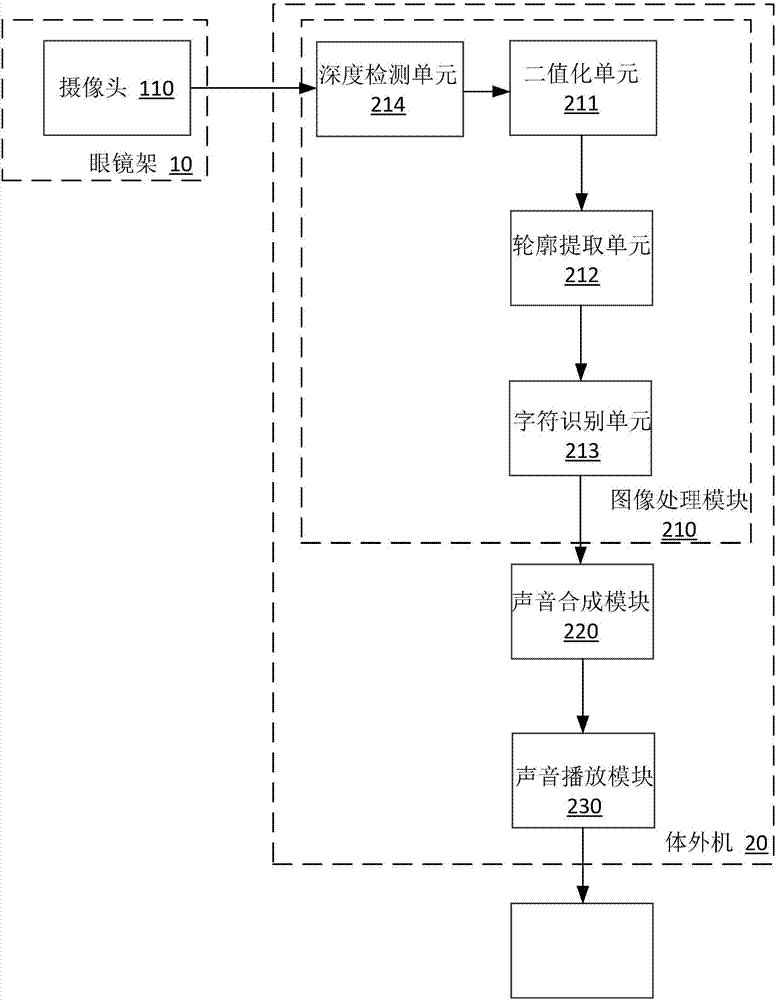
图2为本发明实施例2的一种基于声音刺激的视觉图像感知系统结构示意图;
图3为本发明实施例1的一种基于声音刺激的视觉图像感知方法的步骤流程图;
图4为本发明实施例2的一种基于声音刺激的视觉图像感知方法的步骤流程图;
图5为本发明实施例的一种基于声音刺激的视觉图像感知系统经图像处理模块后的视觉图像。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
实施例1
参见图1,所示为本发明实施例1的一种基于声音刺激的视觉图像感知系统,包括眼镜架10、体外机20和耳机30,其中眼镜架10上设置摄像头;体外机20包括图像处理模块210、声音合成模块220和声音播放模块230,
所述摄像头与体外机20的图像处理模块210连接,摄像头获取二维或三维图像,图像处理模块210将二维或三维图像进行深度检测、二值化、轮廓提取和字符识别后,输出给声音合成模块220进行声音处理后,将声音信号传输给声音播放模块230通过耳机30播放。
实施例2
在实施例1的基础上,参见图2,所示为本发明实施例2的一种基于声音刺激的视觉图像感知系统,图像处理模块210至少包括依次连接的深度检测单元214、二值化单元211、轮廓提取单元212和字符识别单元213。
具体实施例中,采集二维图像时需要一个摄像头,采集三维图像时需要两个摄像头,摄像头包括af镜头。
声音合成模块220包括头相关传递函数滤波单元,因为头和耳廓等器官(作用类似于滤波器)的存在,导致不同方向传来的声音会受到频率上不同的影响,因此,依据先前的经验,人的大脑会自动根据声音的频率变化识别出声音传来的方向。在具体的声音处理过程中,首先选定一个标准声源,比如纯音,复合音,白噪声或人的语音等,然后针对二维平面上不同位置的点,对这个声音进行相应的头相关传递函数滤波,这样便可在听觉空间中,产生相应位置的声音感受。然后再将所有这样处理后的声音,快速连续播放,使人产生听觉上的轮廓感。
声音合成模块220对于图像对应的声音合成处理根据下式:
a(i)=s*h(i)*g(i)
a=a(1)→a(2)→a(3)→a(4)→...→a(n)
其中,s为基准声音的频域信号;h(i)为平面上第i个点所对应的头相关传递函数;g(i)为第i个声音的增益大小,通过物体的远近来判断;a(i)为声音空间中第i个声音;a为将平面上所有对应的声音连续播放后,形成的可传递当前二维或三维图像的声音信号。
与上述系统对应的,本发明还提供了一种基于声音刺激的视觉图像感知方法,其实施例1流程图参见图3,包括以下步骤:
s10,摄像头采集获取二维或三维图像,进行图像处理,获得简化二维或三维图像;
s20,根据简化二维或三维图像,进行声音合成处理;
s30,将处理后的声音传输给耳机进行播放。
方法实施例2,参见图4,s10中的图像处理和s20中的声音合成处理,包括以下步骤:
s101,预处理,将二维或三维图像进行深度检测,再灰度化后进行二值化和去噪;
s102,轮廓提取,依次进行图像剪切、图像细化和图像压缩;
s103,字符识别,输出采集的二维或三维图像中的字符或边缘轮廓。
s201,假设声音空间的平面维度是n行n列,那么就从最左上角的节点开始遍历,记为第1圈,坐标位置表示为(1,n),如果有信号则进行s202,没有信号则进入步骤s204;
s202,当遍历到有信号的节点时,将此节点设为当前节点,首先播放该节点的声音信号并将该节点设为无信号以避免重复播放,然后选择所处方位与当前遍历方向一致的节点遍历,若有信号则重复步骤s202,直至遍历完成;若无信号则进入步骤s203;
其中,当前遍历方向是指前两个被连续遍历到的有信号的相邻节点的连接方向,比如从(1,n)遍历到(2,n),且这两个节点都有信号,那么当前遍历方向就被设为正右,也就是说此时应优先遍历当前节点正右方的相邻节点,以此类推,遍历方向默认为正右方;
s203,由于处在当前遍历方向的节点无信号,那么就从此节点接着顺时针围绕当前节点旋转遍历;如果遇到有信号的节点,则进入s202,若没有,则进入s204;
s204,如果之前遍历到第i圈,那么继续遍历第i+1圈,节点坐标依次为(i,n),(i,n-1),(i,n-2)...(i,n-i+1),(i-1,n-i+1),(i-2,n-i+1)...(1,n-i+1),如果遍历过程中遇到有信号的节点则继续s202,无信号则继续遍历更外侧的第i+2圈,直至遇到有信号的节点,或遍历完平面所有节点。
具体实施例中,s20中声音合成处理根据下式:
a(i)=s*h(i)*g(i)
a=a(1)→a(2)→a(3)→a(4)→...→a(n)
其中,s为基准声音的频域信号;h(i)为平面上第i个点所对应的头相关传递函数;g(i)为第i个声音的增益大小,通过物体的远近来判断;a(i)为声音空间中第i个声音;a为将平面上所有对应的声音连续播放后,形成的可传递当前二维或三维图像的声音信号。
参见图5为本发明实施例的一种基于声音刺激的视觉图像感知系统经图像处理模块后的视觉图像。
摄像头采集到了“8”的图像,经过图像处理后为图5的轮廓图像,具体实施例中可以从左下角依次播放声音,快速扫过整个“8”字轮廓,这样整个门的轮廓生成在人的脑海中。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!