脉搏波血压测量装置的分类预测数据处理方法与流程
本发明涉及数据处理,特别涉及一种脉搏波血压测量装置的分类预测数据处理方法。
背景技术:
本项研究工作得到了中国国家自然科学基金项目(no.61571268)、广东省科技厅重大科技专项项目-基于智能手机监护仪的远程人体生理多参数实时监测与分析物联网平台与示范工程、以及深圳市发改委重大科技项目-基于智能手机的远程人体生理多参数实时监测与分析网络平台产业化的资助。
近年来,随着可穿戴产品越发流行,尤其是针对医疗健康领域。其中,血压作为人体最重要的生理参数之一,对预防高血压,中风,心肌梗塞或心力衰竭等疾病具有重要意义。
就传统测量血压方法来讲,医生更倾向于选择柯氏听音法或示波法。虽然该种方法测量精度高,但是柯氏听音法的准确性往往因人而异,受到临床经验的影响,示波法测量血压需要佩戴袖带,往往携带不方便。因此,无创高精度可穿戴血压测量设备受到很多人的期待。
其中,针对无创血压测量算法,相关学者做了大量的研究。算法的普遍思路是通过采集人体ppg(photoplethysmography,脉搏波)信号,然后数据进过预处理后提取时域或频域特征,利用相关模型(线性、svm(支持向量机)、ann(人工神经网络))进行训练与回归预测。实际测量的数据具有一定的随机性,包括采集数据的随机性及回归预测模型建立的随机性,这种随机性会对方法的实用性产生不利的影响。
技术实现要素:
本发明的目的是为了解决现有技术中随机性会对方法的实用性产生不利影响的问题,提出一种脉搏波血压测量装置的分类预测数据处理方法。
为解决上述技术问题,本发明采用以下技术方案:
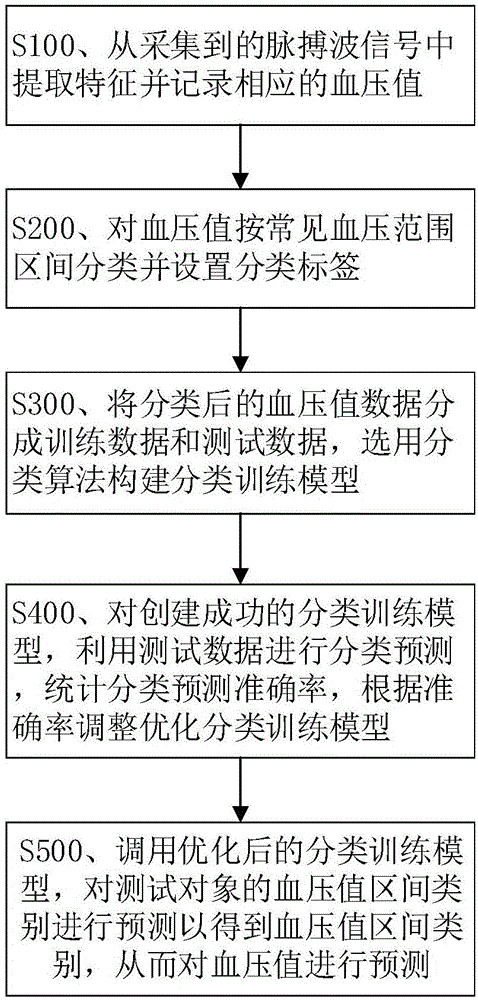
脉搏波血压测量装置的分类预测数据处理方法,包括如下步骤:
s100、从采集到的脉搏波信号中提取特征并记录相应的血压值;
s200、对血压值按常见血压范围区间分类并设置分类标签;
s300、将分类后的血压值数据分成训练数据和测试数据,选用分类算法构建分类训练模型;
s400、对创建成功的分类训练模型,利用测试数据进行分类预测,统计分类预测准确率,根据准确率调整优化分类训练模型;
s500、调用优化后的分类训练模型,对测试对象的血压值区间类别进行预测以得到血压值区间类别,从而对血压值进行预测。
在一些优选的实施方式中,步骤s100包括:
s110、采集脉搏波数据样本;
s120、对数据进行预处理;
s130、提取脉搏波时域参数。
在一些优选的实施方式中,步骤s300包括:
s310、对采集的脉搏波特征参数和对应的血压值区间类别作为样本数据,分为重搏波明显的样本数据和重搏波不明显样本数据;
s320、针对重搏波明显的样本数据,随机选择一部分数据用作重搏明显分类训练数据,其余数据用作重搏明显分类测试数据;针对重搏波不明显样本数据,随机选择一部分数据用作重搏不明显分类训练数据,其余数据用作重搏不明显分类测试数据;
s330、选用分类算法对分类训练数据构建训练模型。
在一些优选的实施方式中,在增加数据样本的情况下重复步骤s100至s400。
在一些优选的实施方式中,步骤s500包括:
s510、采集测试对象样本ppg数据,对数据进行处理以及进行特征参数计算;
s520、根据计算所得的特征参数调用优化后的分类训练模型,对测试对象的血压值区间类别进行预测;
s530、根据得到的血压值区间类别,对血压值进行预测。
在进一步优选的实施方式中,步骤s530中对血压值进行预测的方式包括:回归分析方法和通过求取预测类别对应血压区间范围中值作为最终预测血压值。
在进一步优选的实施方式中,步骤s130包括:
s131、识别统计重搏波明显与不明显的两种典型脉搏波;
s132、检测特征点;
s133、计算特征参数。
在一些优选的实施方式中,步骤s300中的分类算法包括:二元逻辑分类、支持向量机分类、人工神经网络分类、决策树和随机森林。
在进一步优选的实施方式中,步骤s110的预处理包括去除基线漂移、滤波去除工频干扰和肌电干扰。
在另一方面,本发明还提供一种计算机可读存储介质:
一种计算机可读存储介质,其存储有与计算设备结合使用的计算机程序,所述计算机程序被处理器执行以实现上述方法。
与现有技术相比,本发明的有益效果有:
将具体血压值回归预测转化为一定血压范围内的分类决策,通过设定相应血压区间并进行分类,选用分类算法构建分类训练模型,可以在保持预测精度的前提下降低预测难度,减少了实际测量的数据的随机性对测量的影响,提高实用性。
附图说明
图1是本发明的流程图;
图2是步骤s100的流程图;
图3是步骤s130的流程图;
图4是本发明涉及的一个周期脉搏波的重搏波明显的波形;
图5是本发明涉及的一个周期脉搏波的重搏波不明显的波形;
图6是步骤s300的流程图;
图7是步骤s500的流程图。
具体实施方式
以下对本发明的实施方式作详细说明。应该强调的是,下述说明仅仅是示例性的,而不是为了限制本发明的范围及其应用。
参考图1,脉搏波血压测量装置的分类预测数据处理方法包括如下步骤:
s100、从采集到的脉搏波信号中提取特征并记录相应的血压值。参考图2,步骤s100具体包括子步骤s110、s120和s130:
s110、采集脉搏波数据样本。具体为:针对不同人(总人数:n)分别采集脉搏波数据(ppg信号),脉搏波数据的获取主要是通过脉搏波采集设备测量得到,每个对象采集数据的时长为t秒,t秒数据对应有效完整脉搏波波形数d,则特征矩阵维数为n*d。脉搏波数据对应的血压值为采集脉搏波的时间段内通过血压测量设备测量得到的可保证准确性的血压值,包括舒张压和收缩压。这里,需要测量n组脉搏波数据及其对应的血压值。优选地,t>20s,n>>100。
s120、对数据进行预处理。具体为:对每个采集对象下的每段数据(t秒)进行预处理,主要设计一个带通滤波器,实现去除基线漂移,滤波去除工频干扰和肌电干扰,可采用fir带通滤波器,通带频率1-5hz。
s130、提取脉搏波时域参数。针对滤波平滑后的数据,进行脉搏波时域参数的提取,参考图3,具体包括子步骤s131、s132和s133:
s131、识别统计重搏波明显与不明显的两种典型脉搏波。具体为:识别统计两种典型脉搏波,分别为重搏波明显与不明显的脉搏波,对应人数n1、n2,则n=n1+n2。
s132、检测特征点。针对两种典型脉搏波波形提取对应波形的特征点:
参考图4,针对重搏波明显的波形,需要检测的特征点有主动脉瓣开放点a(troughpoint),收缩期最高压力点b(systolicpeak),重搏波起点c(dicroticnotch),重搏波最高压力点d(dicroticpeak)。
参考图5,针对重搏波不明显的波形,需要检测的特征点主要有主动脉瓣开放点a(troughpoint),收缩期最高压力点b(systolicpeak)。
利用findpeaks函数可以检测出数据中的极大值点b和d。通过对数据取反再利用findpeaks函数可以检测出数据中的极小值点a和c,findpeaks是利用差分法实现对数据的极值点检测,即设有脉搏波数据d1,d2,d3,……,di,……,如果有di>di-1且di>di+1则判定di为极大值点。
s133、计算特征参数。根据特征点计算对应波形类型下的特征参数:
参考图4,针对重搏波明显波形(dicroticpeakobvious),提取的特征参数如下:
△t:收缩期和舒张期峰值之间的时间延迟;
t1-t4:血压收缩期和舒张期有关时域特征;
t:完整的波形周期;
增强指数(ai):增强压力(ag)是波反射对收缩期动脉压力贡献的度量:
拐点面积比(ipa):a1和a2是在拐点处分离的整个ppg波下的区域面积:
w1、w2:脉冲宽度;
h/t:脉搏高度与周期比;
大动脉硬化指数(si):与动脉僵硬度相关
r_slope:h/t1,波形上升沿斜率;
f_slope:h/(t2+t3+t4),波形下降斜率;
h、h1、h2、h3:脉搏波归一化下相对高度;
k:脉搏波波形特征值(pulsewavewaveformeigenvalue),由如下公式计算:
其中,pm(meanarterialpressure)为平均动脉压,ps(systolicbloodpressure)为收缩压,pd(diastolicbloodpressure)为舒张压。
参考图5,针对重搏波不明显波形(dicroticpeaknotobvious),提取的特征参数如下:
脉搏周期t,收缩期上升时间sut,舒张期时间dt,ipa(拐点面积比,a1/a2),r_slope(上升斜率:h/sut),f_slope(下降斜率:h/dt)和k(脉搏波波形特征值),脉搏高度百分比(10%,25%,33%,50%,66%,75%)对应时间宽度如图5和下表一:
表一脉搏高度百分比对应的时间宽度
脉搏波波形特征值k由如下公式计算:
其中,pm(meanarterialpressure)为平均动脉压,ps(systolicbloodpressure)为收缩压,pd(diastolicbloodpressure)为舒张压。
s200、对血压值按常见血压范围区间分类并设置分类标签。对采集脉搏波信号对应的血压值按常见血压范围区间分类,设舒张压血压值区间种类数为c1,收缩压血压值区间种类数为c2。
分类标签的设置:对于n*d组脉搏波特征对应的两类血压值(收缩压,舒张压)分类制作对应标签。收缩压常见血压范围为90-140mmhg,舒张压常见血压范围为60-90mmhg。若划分血压区间间隔选为dis=10mmhg,那么对于收缩压分类标签及对应血压范围为:1(<=90mmhg),2(90~100mmhg),3(100~110mmhg),4(110~120mmhg),5(120~130mmhg),6(130~140mmhg),7(>140mmhg)。对于舒张压分类标签及对应血压范围为:1(<=60mmhg),2(60~70mmhg),3(70~80mmhg),4(80~90mmhg),5(>90mmhg)。
s300、将分类后的血压值数据分成训练数据和测试数据,选用分类算法构建分类训练模型。参考图6,具体包括子步骤s310、s320和s330:
s310、对采集的脉搏波特征参数和对应的血压值区间类别作为样本数据,分为重搏波明显的样本数据和重搏波不明显样本数据。具体的:对采集的n*d组脉搏波特征参数和对应的血压值区间类别作为样本数据的1~n*d组,其中重搏波明显的样本数为n1*d,不明显样本数n2*d。
s320、针对重搏波明显的样本数据,随机选择一部分数据用作重搏明显分类训练数据,其余数据用作重搏明显分类测试数据;针对重搏波不明显样本数据,随机选择一部分数据用作重搏不明显分类训练数据,其余数据用作重搏不明显分类测试数据。具体的:针对两类数据,随机选择k1*d组数据用作重搏明显分类训练数据,其余(n1-k1)*d数据用作重搏明显分类测试数据。同理重搏不明显分类训练数据组数为k2*d,测试数据组数为(n2-k2)*d,优选地,k1/n1=75%=k2/n2。
s330、选用分类算法对分类训练数据构建训练模型。针对上述脉搏波数据的特征参数及其血压分类标签,选用合适的分类算法对两种典型脉搏波类型的收缩压和舒张压分别构建分类训练模型。常见分类算法有二元逻辑分类、支持向量机分类、人工神经网络分类、决策树、随机森林等,优选用随机森林。
支持向量机分类:寻找最佳分类超平面分类预测样本类别,根据训练样本的分布,搜索所有可能的线性分类器中最佳的那个。决定分类超平面的样本并不是所有训练数据,而是其中的两个间隔最小的两个不同类别的数据点。这种可以用来真正帮助决策最优线性分类模型的数据点叫做“支持向量”。
集成模型分类:综合考量多个分类器的预测结果,作出决策,分为两种:
一种是利用相同的分类训练数据同时搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数做出最终的分类决策。典型模型为随机森林分类器,即在相同训练数据上同时搭建多棵决策树,一株标准的决策树会根据每位特征对预测结果的影响进行排序,从而决定不同特征从上至下构建分裂节点的顺序,如此一来,所有随机森林中的决策树都会受这一策略影响而构建得一致,从而丧失多样性。因此随机森林分类器在构建过程中,每一个决策树都会放弃这一固定的排序算法,转而随机选取特征。
另一种是按照一定次序搭建多个分类模型,这些模型之间存在依赖关系,一般而言,每一个后续模型的加入都需要对现有集成模型的综合性能有所贡献,进而不断提升更新过后的集成模型的性能,并最终期望借助整合多个分类能力较弱的分类器,搭建出具有更强分类能力的模型。比较有代表性的当属梯度提升决策树,与随机森林分类器模型不同的是这里每一棵决策树在生成过程中都会尽可能降低整体集成模型在训练集上的拟合误差。
s400、对创建成功的分类训练模型,利用测试数据进行分类预测,统计分类预测准确率,根据准确率调整优化分类训练模型。
在增加数据样本的情况下重复步骤s100至s400。
s500、调用优化后的分类训练模型,对测试对象的血压值区间类别进行预测以得到血压值区间类别,从而对血压值进行预测。参考图7,具体包括子步骤s510、s520和s530:
s510、采集测试对象样本ppg数据,对数据进行处理以及进行特征参数计算。具体为:采集测试对象样本ppg数据t秒,对数据进行预处理,识别波形种类,然后进行特征参数计算。
s520、根据计算所得的特征参数调用优化后的分类训练模型,对测试对象的血压值区间类别进行预测。
s530、根据得到的血压值区间类别,对血压值进行预测。
在得到分类区间类别情况下,可结合常见回归分析方法(如线性回归,svr等)对确切血压值进行预测。也可通过求取预测类别对应血压区间范围中值作为最终预测血压值,例如在dis=10mmhg的前提下,如对收缩压所在区间预测标签为3,即预测血压所在区间范围为100~110mmhg,则预测收缩压值为(100+110)/2=105mmhg。
在另一方面,本发明还提供一种计算机可读存储介质,其存储有与计算设备结合使用的计算机程序,所述计算机程序被处理器执行以实现上述方法。
根据上述可知,本发明将具体血压值回归预测转化为一定血压范围内的分类决策,通过设定相应血压区间并进行分类,结合ppg信号有效特征的选取,试验多种分类算法,获得最适合的高精确性分类算法,从而构建分类训练模型,可以在保持预测精度的前提下降低预测难度,避免了单纯利用回归模型要求对模型特征关系刻画要求高的问题,减少了实际测量的数据的随机性对测量的影响,提高实用性。
以上内容是结合具体/优选的实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,其还可以对这些已描述的实施方式做出若干替代或变型,而这些替代或变型方式都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!