一种基于双随机游走模型的miRNA-疾病关联预测方法与流程
本发明涉及生物信息学和人工智能交叉领域,具体是一种基于双随机游走模型的mirna-疾病关联预测方法。
背景技术:
micrornas(mirnas)是一类很小的内源性非编码rna,长度约为20-24个核苷酸,通过碱基配对与其靶向mrna的3′端非编码区相结合,导致靶mrna的降解或翻译机制,从而在转录水平上调控基因表达。越来越多的研究表明,mirna在转录、免疫反应、细胞增值、细胞分化等生物过程中起着非常重要的作用。mirna功能失调和mirna突变可能会导致各种疾病的发生,因此,识别mirna与疾病之间的相互作用关系至关重要,这将为人类理解疾病机制,疾病的预防和治疗提供帮助。
目前,现有的mirna-疾病关联关系预测方法主要分为三类:
第一类:生物学实验方法测定mirna与特定疾病的关系,这种方法耗时长,实验成本高;
第二类:基于机器学习的预测方法,rlsmda作为一个半监督的mirna-疾病预测方法,其不需要负样本,rfmda预测方法,是第一个用随机森林算法预测mirna-疾病关联的方法;
第三类:基于网络的预测方法,这类方法利用已知mirna-疾病关联关系数据,基于相似的mirna调控的疾病也相似这一假设,通过整合mirna功能相似性和疾病语义相似性等数据,来预测mirna-疾病关联关系,这类方法已成为mirna-疾病关联关系预测的重要工具,例如katzmda和pbmda方法,整合多种数据来预测mirna-疾病关联。
虽然上述方法预测mirna-疾病的关联取得了良好的效果,为疾病的治疗、诊断以及预后提供了帮助,但仍存在很多不足的地方。例如,传统的生物学实验方法测定mirna-疾病的关联,需要耗费大量的时间,浪费人力和财力。基于机器学习和网络的预测方法,预测准确率有待提高。因此迫切需要设计一种新的mirna-疾病关联关系预测方法。
技术实现要素:
本发明的目的是针对现有技术的不足,而提供一种基于双随机游走模型的mirna-疾病关联预测方法。这种方法耗时短、成本低,预测mirna-疾病关联关系精度高。
实现本发明目的的技术方案是:
一种基于双随机游走模型的mirna-疾病关联预测方法,与现有技术不同处在于,包括如下步骤:
1)获取mirna-疾病关联数据集,构建关于mirna-疾病关联的邻接矩阵:从hmdd数据库中获取经生物实验证实的mirna-疾病关联数据,得到5430对不同的mirna和疾病关联数据,其中涉及疾病种类383种,mirna种类495种,定义d={d(1),d(2),d(3),...,d(nd)}来记nd种疾病的集合,m={m(1),m(2),m(3),...,m(nm)}来记nm种mirna的集合,构建邻接矩阵mdnd×nm表示mirna和疾病关联数据的关系,当疾病d(i)和mirnam(j)被验证为关联时,邻接矩阵mdnd×nm中md(i,j)的值设为1;反之,md(i,j)的值设为0,表示未知的关联;
2)分别构建mirna和疾病的高斯相互作用属性核相似性矩阵:依据步骤1)建立的邻接矩阵mdnd×nm,首先,构建mirna高斯相互作用属性核相似性矩阵km:mirnam(i)和m(j)的高斯相互作用属性核相似性计算如公式(1)和公式(2)所示:
km(m(i),m(j))=exp(-γm||md(m(i))-md(m(j))||2)(1),
其中,md(m(i))和md(m(j))分别表示邻接矩阵md的第i列向量和第j列向量,||·||是求向量的范数,参数γm定义为高斯相互作用属性核的带宽,由所有mirna两两之间的高斯相互作用属性核相似性构建mirna高斯相互作用属性核相似性矩阵km;
其次,构建疾病高斯相互作用属性核相似性矩阵kd:疾病d(i)和d(j)之间的高斯相互作用属性核相似性计算如公式(3)和公式(4)所示:
kd(d(i),d(j))=exp(-γd||md(d(i))-md(d(j))||2)(3),
其中,md(d(i))和md(d(j))分别表示邻接矩阵md的第i行向量和第j行向量,||·||是求向量的范数,参数γd定义为高斯相互作用属性核的带宽,由所有疾病两两之间的高斯相互作用属性核相似性构建疾病高斯相互作用属性核相似性矩阵kd:
3)构建mirna功能相似性矩阵以及疾病语义相似性矩阵:首先,构建mirna功能相似性矩阵mfs,先从网站:http://www.cuilab.cn/获取mirna功能相似性分数,然后,构建具有495行和495列的mirna功能相似性矩阵mfs,其中元素mfs(i,j)表示mirnam(i)和mirnam(j)之间的功能相似性分数,其次,采用疾病语义相似性模型1,构建疾病语义相似性矩阵dss1,mesh数据库提供了疾病的严格分类系统,每一种疾病都可以定义为有向无环图(dag),dag是由数据节点和连接边组成,给定一种疾病d,dag=(d,t(d),(e(d)),其中t(d)表示祖先节点及其自身,e(d)表示d的连接边的集合,疾病t是t(d)中的一个节点,对疾病d的贡献值计算如公式(5):
定义疾病d对自身的贡献值为1,而对其他疾病的贡献值则取决于语义贡献因子λ,因此,根据公式(6)计算疾病d的语义值:
然后,通过公式(7)计算疾病a和疾病b之间的语义相似性:
其中,da(t)表示疾病t对疾病a的贡献值,db(t)表示疾病t对疾病b的贡献值,由此可见,疾病a和疾病b之间的语义相似性依赖于两者之间的共同疾病的数量,数量越大,相似性越大,dss1是基于疾病语义相似性模型1计算得到的一个383行和383列的疾病语义相似性矩阵,
最后,采用疾病语义相似性模型2,构建疾病语义相似性矩阵dss2,每种疾病可以描述为分层dag,其中父节点代表更普遍的疾病,而子节点代表更具体的疾病,根据疾病语义相似性模型1,同一层dag(d)中不同疾病对疾病d语义值的贡献处于同一水平,然而,这些疾病可能出现在其他dag中,并且它们出现的dag的数量可能不同,因此,区分这些疾病的贡献,其他dag中出现的疾病的贡献应该更少发生在dag较少的特定疾病中,疾病t对疾病d的语义值的贡献计算如公式(8):
疾病d的语义值定义如公式(9):
疾病a和疾病b之间的语义相似性计算如公式(10):
dss2是基于疾病语义相似性模型2计算得到的一个383行和383列的疾病语义相似性矩阵;
4)使用相似网络融合算法整合疾病和mirna的相似性:每一个疾病-疾病相似性矩阵可能会包含噪声数据,采用相似网络融合算法snf,将疾病高斯相互作用属性核相似性矩阵kd、疾病语义相似性矩阵dss1和疾病语义相似性矩阵dss2,这三个已知的疾病-疾病相似矩阵融合在一起,从而得到一个更有用、更可靠的、信息更加丰富的疾病-疾病矩阵,snf甚至可以从少量样本中获得有用信息,并且对噪声和数据异质性具有鲁棒性,它是一种基于非线性消息传递的方法,它迭代地更新每个网络并使其与其他网络越来越相似,每一个疾病-疾病相似矩阵可以表示为图g={d,e},其中d={d1,d2,…,dn}为疾病的集合,e是连接疾病-疾病的边的集合,每条边上都有相似权重,将相应的相似性矩阵记为w,w(i,j)表示为疾病di和疾病dj的相似性,从疾病高斯相互作用属性核相似性矩阵kd、疾病语义相似性矩阵dss1和疾病语义相似性矩阵dss2,这三个已知的疾病-疾病相似矩阵中计算得到一个最终的疾病-疾病相似矩阵,在每个矩阵上定义了一个全稀疏核,全稀疏核标准化后权值矩阵为p=d-1w,其中d为一个对角矩阵,d(i,j)=∑jw(i,j),由于p涉及w对角线的自相似性,可能会导致p数值的不稳定性,所以更好的标准化如公式(11):
用ni表示在疾病-疾病相似网络中di的邻居,用knn算法衡量局部亲和力如公式(12):
考虑到疾病与邻居之间的相似性比疾病与远程疾病之间的相似性更加可靠,通过图扩散,可以将相似性传播到远程疾病,矩阵p携带疾病-疾病相似网络的所有信息,矩阵s携带网络的局部相似信息,然后,进行如公式(12)迭代计算:
这里pt(i)是t(>=0)次迭代后第i个相似矩阵(网络),s(i)是第i个相似矩阵网络的knn矩阵,m是相似网络的数量,由于s是p的knn邻域矩阵,它包含p的最重要信息,并且还减轻了p中的噪声效应,在每次迭代中,每个相似性矩阵网络可以从其他相似性矩阵网络获得可靠信息,并且还用其他相似性矩阵网络更新自身,在t次迭代之后,融合矩阵网络计算如公式(14):
每次迭代计算后要对矩阵pt进行标准化,以确保矩阵是满秩的。以上通过相似网络融合算法,将疾病高斯相互作用属性核相似性矩阵kd、疾病语义相似性矩阵dss1、疾病语义相似性矩阵dss2进行融合,得到最终的一个疾病-疾病相似性矩阵ds,以同样的方法,得到最终的mirna-mirna相似性矩阵ms;
5)依据双随机游走模型来预测mirna-疾病关联关系:
在mirna网络上随机游走如公式(15):rwm=α·mdt-1·ms+(1-α)·a(15),
在疾病网络上随机游走如公式(16):rwd=α·ds·mdt-1+(1-α)·a(16),
其中,α是衰减因子,ms是mirna相似矩阵,ds是疾病相似矩阵,a为mirna-疾病关联矩阵,rwm和rwd分别表示在mirna相似网络和疾病相似网络上基于随机游走的预测mirna-疾病关联关系得分概率矩阵,最后,综合rwm和rwd得到最终的mirna-疾病关联关系得分概率矩阵。
本技术方案的有益效果如下:
本技术方案提供一种基于双随机游走模型的mirna-疾病关联预测方法来预测mirna-疾病的关联关系,从而有助于人类对疾病机制的理解,药物的发现和疾病的治疗、诊断和预后,本技术方案的方法预测mirna-疾病之间的关联关系,较现有的计算方法预测准确率高、耗时短,并且降低了以往传统生物实验方法所带来的巨大成本。
附图说明
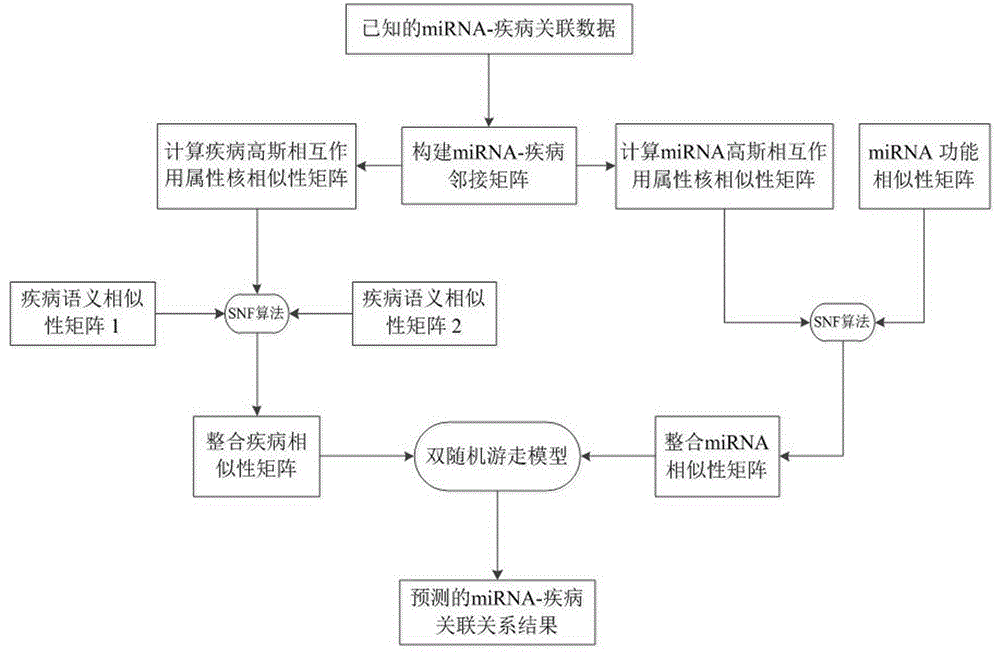
图1为实施例方法流程示意图;
图2为实施例方法在留一法交叉验证和5折交叉验证实验下的比较示意图;
图3为实施例方法与其他方法在留一法交叉验证实验下的比较示意图;
图4为实施例方法预测出的前50个与乳腺癌相关的mirna。
具体实施方式
下面结合附图和实施例对本发明内容做进一步的阐述,但不是对本发明的限定:
实施例:
参照图1,一种基于双随机游走模型的mirna-疾病关联预测方法,包括如下步骤:
1)获取mirna-疾病关联数据集,构建关于mirna-疾病关联的邻接矩阵:从hmdd数据库中获取经生物实验证实的mirna-疾病关联数据,得到5430对不同的mirna和疾病关联数据,其中涉及疾病种类383种,mirna种类495种,定义d={d(1),d(2),d(3),...,d(nd)}来记nd种疾病的集合,m={m(1),m(2),m(3),...,m(nm)}来记nm种mirna的集合,构建邻接矩阵mdna×nm表示mirna和疾病关联数据的关系,当疾病d(i)和mirnam(j)被验证为关联时,邻接矩阵mdnd×nm中md(i,j)的值设为1;反之,md(i,j)的值设为0,表示未知的关联;
2)分别构建mirna和疾病的高斯相互作用属性核相似性矩阵:依据步骤1)建立的邻接矩阵mdnd×nm,首先,构建mirna高斯相互作用属性核相似性矩阵km:mirnam(i)和m(j)的高斯相互作用属性核相似性计算如公式(1)和公式(2)所示:
km(m(i),m(j))=exp(-γm||md(m(i))-md(m(j))||2)(1),
其中,md(m(i))和md(m(j))分别表示邻接矩阵md的第i列向量和第j列向量,||·||是求向量的范数,参数γm定义为高斯相互作用属性核的带宽,由所有mirna两两之间的高斯相互作用属性核相似性构建mirna高斯相互作用属性核相似性矩阵km;
其次,构建疾病高斯相互作用属性核相似性矩阵kd:疾病d(i)和d(j)之间的高斯相互作用属性核相似性计算如公式(3)和公式(4)所示:
kd(d(i),d(j))=exp(-γd||md(d(i))-md(d(j))||2)(3),
其中,md(d(i))和md(d(j))分别表示邻接矩阵md的第i行向量和第j行向量,||·||是求向量的范数,参数γd定义为高斯相互作用属性核的带宽,由所有疾病两两之间的高斯相互作用属性核相似性构建疾病高斯相互作用属性核相似性矩阵kd;
3)构建mirna功能相似性矩阵以及疾病语义相似性矩阵:首先,构建mirna功能相似性矩阵mfs,先从网站:http://www.cuilab.cn/获取mirna功能相似性分数,然后,构建具有495行和495列的mirna功能相似性矩阵mfs,其中元素mfs(i,j)表示mirnam(i)和mirnam(j)之间的功能相似性分数,其次,采用疾病语义相似性模型1,构建疾病语义相似性矩阵dss1,mesh数据库提供了疾病的严格分类系统,每一种疾病都可以定义为有向无环图(dag),dag是由数据节点和连接边组成,给定一种疾病d,dag=(d,t(d),(e(d)),其中t(d)表示祖先节点及其自身,e(d)表示d的连接边的集合,疾病t是t(d)中的一个节点,对疾病d的贡献值计算如公式(5):
定义疾病d对自身的贡献值为1,而对其他疾病的贡献值则取决于语义贡献因子λ,因此,根据公式(6)计算疾病d的语义值:
然后,通过公式(7)计算疾病a和疾病b之间的语义相似性:
其中,da(t)表示疾病t对疾病a的贡献值,db(t)表示疾病t对疾病b的贡献值,由此可见,疾病a和疾病b之间的语义相似性依赖于两者之间的共同疾病的数量,数量越大,相似性越大,dss1是基于疾病语义相似性模型1计算得到的一个383行和383列的疾病语义相似性矩阵,
最后,采用疾病语义相似性模型2,构建疾病语义相似性矩阵dss2,每种疾病可以描述为分层dag,其中父节点代表更普遍的疾病,而子节点代表更具体的疾病,根据疾病语义相似性模型1,同一层dag(d)中不同疾病对疾病d语义值的贡献处于同一水平,然而,这些疾病可能出现在其他dag中,并且它们出现的dag的数量可能不同,因此,区分这些疾病的贡献,其他dag中出现的疾病的贡献应该更少发生在dag较少的特定疾病中,疾病t对疾病d的语义值的贡献计算如公式(8):
疾病d的语义值定义如公式(9)::
疾病a和疾病b之间的语义相似性计算如公式(10):
dss2是基于疾病语义相似性模型2计算得到的一个383行和383列的疾病语义相似性矩阵;
4)使用相似网络融合算法整合疾病和mirna的相似性:每一个疾病-疾病相似性矩阵可能会包含噪声数据,采用相似网络融合算法snf,将疾病高斯相互作用属性核相似性矩阵kd、疾病语义相似性矩阵dss1和疾病语义相似性矩阵dss2,这三个已知的疾病-疾病相似矩阵融合在一起,从而得到一个更有用、更可靠的、信息更加丰富的疾病-疾病矩阵,snf甚至可以从少量样本中获得有用信息,并且对噪声和数据异质性具有鲁棒性,它是一种基于非线性消息传递的方法,它迭代地更新每个网络并使其与其他网络越来越相似,每一个疾病-疾病相似矩阵可以表示为图g={d,e},其中d={d1,d2,…,dn}为疾病的集合,e是连接疾病-疾病的边的集合,每条边上都有相似权重,将相应的相似性矩阵记为w,w(i,j)表示为疾病di和疾病dj的相似性,从疾病高斯相互作用属性核相似性矩阵kd、疾病语义相似性矩阵dssl和疾病语义相似性矩阵dss2,这三个已知的疾病-疾病相似矩阵中计算得到一个最终的疾病-疾病相似矩阵,在每个矩阵上定义了一个全稀疏核,全稀疏核标准化后权值矩阵为p=d-1w,其中d为一个对角矩阵,d(i,j)=∑jw(i,j),由于p涉及w对角线的自相似性,可能会导致p数值的不稳定性,所以更好的标准化如公式(11):
用ni表示在疾病-疾病相似网络中di的邻居,用knn算法衡量局部亲和力如公式(12):
考虑到疾病与邻居之间的相似性比疾病与远程疾病之间的相似性更加可靠,通过图扩散,可以将相似性传播到远程疾病,矩阵p携带疾病-疾病相似网络的所有信息,矩阵s携带网络的局部相似信息,然后,进行如公式(12)迭代计算:
这里pt(i)是t(>=0)次迭代后第i个相似矩阵(网络),s(i)是第i个相似矩阵网络的knn矩阵,m是相似网络的数量,由于s是p的knn邻域矩阵,它包含p的最重要信息,并且还减轻了p中的噪声效应,在每次迭代中,每个相似性矩阵网络可以从其他相似性矩阵网络获得可靠信息,并且还用其他相似性矩阵网络更新自身,在t次迭代之后,融合矩阵网络计算如公式(14):
每次迭代计算后要对矩阵pt进行标准化,以确保矩阵是满秩的。以上通过相似网络融合算法,将疾病高斯相互作用属性核相似性矩阵kd、疾病语义相似性矩阵dss1、疾病语义相似性矩阵dss2进行融合,得到最终的一个疾病-疾病相似性矩阵ds,以同样的方法,得到最终的mirna-mirna相似性矩阵ms;
5)依据双随机游走模型来预测mirna-疾病关联关系:
在mirna网络上随机游走如公式(15):rwm=α·mdt-1·ms+(1-α)·a(15),
在疾病网络上随机游走如公式(16):rwd=α·ds·mdt-1+(1-α)·a(16),
其中,α是衰减因子,ms是mirna相似矩阵,ds是疾病相似矩阵,a为mirna-疾病关联矩阵,rwm和rwd分别表示在mirna相似网络和疾病相似网络上基于随机游走的预测mirna-疾病关联关系得分概率矩阵,最后,综合rwm和rwd得到最终的mirna-疾病关联关系得分概率矩阵。
验证:本实施例中mirna-疾病关联预测方法我们称之为birwmda方法,为了评估本例的方法,分别进行留一法交叉验证实验和5折交叉验证实验,实验结果如图2所示,在留一法交叉验证实验中,每次留下一条关联数据作为测试集,剩余的作为训练集,画roc曲线并计算auc值即roc曲线下的面积,auc值越大表示模型预测性能越好,本例方法birwmda的auc值达到0.9303;在5折交叉验证实验中,将数据集随机分为5组,其中一组作为测试集,剩余四组作为训练集,由于随机分割数据集会带来偏差问题,重复进行100次5折交叉验证实验,计算平均的auc值,本实施例方法birwmda的平均auc值达到0.9209,此时标准差为0.00026,birwmda方法还和现有的方法进行了比较,如图3所示,本例方法的auc值比其他方法的auc值都高,auc的值越高表明预测模型越好。
为了进一步评估本例的方法,本例进行了乳腺癌疾病案例研究,预测出的前50个与乳腺癌相关的mirna被证实有46个在dbdemc和mircancer数据库都得到了证实,如图4所示,其中hsa-mir-532和hsa-mir-652虽然没有收入到dbdemc和mircancer数据库,但是已在学术文献中得到证实与乳腺癌相关联。
- 还没有人留言评论。精彩留言会获得点赞!