一种早期预测妊娠糖尿病模型的建立方法与流程
本发涉及一种预测方法,尤其涉及一种早期预测妊娠糖尿病的方法。
背景技术:
妊娠期糖尿病(gestationaldiabetesmellitus,gdm)是指妊娠期首次发生的糖代谢异常,所有的患者孕前均没有糖尿病史。随着高热量饮食、少动生活方式的流行和妊娠年龄的增长,gdm发病率逐年上升。2019年国际糖尿病联盟(idf)公布的地图数据显示,全球2000万(1/6)的孕妇中有某种形式的妊娠高血糖,其中妊娠期糖尿病(gdm)占84%。idf估计在2030之前,1830万新生儿会受妊娠高糖影响,我国多中心数据显示gdm发病率为17.5%,随着我国二胎政策开放,这一比例必将持续上升。gdm会导致产妇和新生儿多种围产期不良结局的增加,研究显示早期对gdm患者进行饮食、运动控制可有效改善多种不良结局。基于以上情况,开发针对早期预测gdm的有效方法,对于优生优育具有重要的意义和价值。
然而目前临床上缺乏简单直观且经济的gdm早期预测方法。最新指南(2019ada)建议孕妇一般在孕24-28周时行75g-葡萄糖耐量检测(oralglucosetolerancetest,ogtt)来诊断gdm,但是指南只列举了危险因素,缺乏可量化的评价标准,无法个体化评估孕妇孕中晚期发生gdm的风险大小。
技术实现要素:
本发明提供一种早期预测妊娠糖尿病的方法,以克服现有技术的缺陷。
为实现上述目的,本发明提供一种早期预测妊娠糖尿病的方法,包括以下步骤:步骤一、临床回顾性收集若干例孕期血糖正常和患有妊娠期糖尿病的已生产孕妇,,作为总收集例,收集各例信息数据;信息数据包括基本信息、现病史与既往史、月经史、家族史及实验室检查;步骤二、在步骤一的总收集例中随机抽取若干例作为训练集;利用python语言,运用软件编译“是否”型的lightgbm模型;设置模型参数,然后导入训练集各例的信息数据和最终是否患妊娠期糖尿病结果,构建lightgbm预测模型;信息数据为n个,则导入的数据格式为:(x1,x2,.....,xn,y);x1、x2、.....、xn分别为n个信息数据的导入数值,y是孕妇最终是否进展为妊娠期糖尿病,定义y=1表示孕妇最后发生了妊娠期糖尿病,y=0表示孕妇血糖处于正常范围;步骤三、将待预测孕妇的信息数据输入步骤二构建的lightbgm预测模型,得到未来发生妊娠期糖尿病风险的预测风险值,根据预测风险值确定预测孕妇是否会患病。
其中,lightgbm是对传统的gbdt算法的优化,加入了基于梯度的单边采样(gradient-basedone-sidesampling,goss)和互斥特征捆绑(exclusivefeaturebundling,efb)的算法,通过goss可实现对样本进行采样来计算梯度,而不是使用所用的样本点来计算梯度;利用efb将某些特征进行捆绑在一起来降低特征的维度,是寻找最佳切分点的消耗减少,而不是使用所有的特征来进行扫描获得最佳的切分点,这样大大的降低的处理样本的时间复杂度,并且不会造成精度的降低。
goss算法描述:输入训练数据,设定迭代步数d,大梯度数据的采样率a,小梯度数据的采样率b。(1)根据样本点的梯度的绝对值对它们进行降序排序;(2)对排序后的结果选取前a*100%的样本生成一个大梯度样本点的子集;(3)对剩下的样本集合(1-a)*100%的样本,随机的选取b*(1-a)*100%个样本点,生成一个小梯度样本点的集合;(4)将大梯度样本和采样的小梯度样本合并;(5)将小梯度样本乘上一个权重系数;(6)使用上述的采样的样本,学习一个新的弱学习器;(7)不断地重复(1)-(6)步骤直到达到规定的迭代次数或者收敛为止。通过上面的算法可以在不改变数据分布的前提下不损失学习器精度的同时大大的减少模型学习的速率,输出训练好的强学习器。
feb算法描述:(1)构造一个边带有权重的图,其权值对应于特征之间的总冲突;(2)通过特征在图中的度来降序排序特征;(3)检查有序列表中的每个特征,并将其分配给具有小冲突的现有bundling,或创建新bundling。这是一种更加高效的算法,改变了既往排序策略,将按度数排序改为按非0值数量排序,最后得到特征捆绑集合bundles。
进一步,本发明提供一种早期预测妊娠糖尿病的方法,还可以具有这样的特征:其中,基本信息包括孕妇年龄、孕前身高、孕前体重、血压、学历、月经史和孕产次;现病史与既往史包括是否有多囊卵巢综合征、慢性高血压和妊娠期糖尿病病史;月经史包括初潮年龄、月经是否规律;家族史指是否有糖尿病家族史;实验室检查包括早孕期肝功能和血浆空腹血糖、孕14-20周生化检查和血常规。
进一步,本发明提供一种早期预测妊娠糖尿病的方法,还可以具有这样的特征:其中,早孕期肝功能包括谷丙转氨酶和谷草转氨酶;孕14-20周生化检查包括谷丙转氨酶、谷草转氨酶、甘油三酯、胆固醇、高密度胆固醇脂蛋白、低密度胆固醇脂蛋白和空腹血糖;血常规包括血红蛋白、白细胞和血小板。
进一步,本发明提供一种早期预测妊娠糖尿病的方法,还可以具有这样的特征:其中,步骤二中,对导入的信息数据进行多轮迭代,采用损失函数的负梯度作为当前决策树的残差近似值,去拟合新的决策树,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练后得到强学习器,循环迭代至auc无法再提高时,则停止训练,生成lightgbm预测模型。
进一步,本发明提供一种早期预测妊娠糖尿病的方法,还可以具有这样的特征:其中,步骤二中,在lightgbm预测模型构建完成后,将总收集例中剩余例作为验证集,将验证集的信息数据导入lightgbm预测模型中,运用python语言中的sklearn机器学习模块的roc-curve和auc方法进行roc曲线代码编译,输出验证集模型roc曲线下面积,验证lightgbm预测模型。
进一步,本发明提供一种早期预测妊娠糖尿病的方法,还可以具有这样的特征:其中,步骤三中,得到未来发生妊娠期糖尿病风险的预测风险值为y',y'>50%定义为会发生妊娠期糖尿病,输出标签值为1,y'<50%定义为不会发生妊娠期糖尿病,输出标签值为0。
进一步,本发明提供一种早期预测妊娠糖尿病的方法,还可以具有这样的特征:其中,步骤二中,模型参数为:最大深度(max_depth)为10;叶子节点数量(num_leaves)为50;学习率(learning_rate)为0.005;评估指标(eval_metric)为曲线下面积。
其中,lightgbm通过leaf-wise策略来生长树。每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同level-wise相比,在分裂次数相同的情况下,leaf-wise可以降低更多的误差,得到更好的精度。但是,当样本量较小的时候,leaf-wise可能会造成过拟合。所以,lightgbm可以利用额外的参数max_depth(最大深度)来限制树的深度并避免过拟合,一般设置该值为5—10即可,可用来显式地限制树的深度,我们将模型‘max_depth’设为10。
叶子节点数量(num_leaves)是控制树模型复杂度的主要参数,原则上调整num_leaves的取值时,应该让其小于.我们的模型设置参数为‘num_leaves’为50。
学习率(learning_rate)作为监督学习以及深度学习中重要的超参,其决定着目标函数能否收敛到局部最小值以及何时收敛到最小值。合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。通过使用较小的learning_rate,我们可以得到更好的准确率,我们的模型的学习率为0.005
曲线下面积(areaundercurve,auc)指roc曲线下与坐标轴围成的面积,这是评价一个模型好坏的评价指标,可清晰地反应一个分类器的效果好坏,auc越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
进一步,本发明提供一种早期预测妊娠糖尿病的方法,还可以具有这样的特征:其中,步骤一中,总收集例中,孕期血糖正常和患有妊娠期糖尿病的已生产孕妇的比例为1:1。
进一步,本发明提供一种早期预测妊娠糖尿病的方法,还可以具有这样的特征:其中,步骤二中,软件为spyder或者jupyternotebook。
本发明的有益效果在于:本发明提供一种早期预测妊娠糖尿病的方法,通过利用目前已普及的电子病历系统的大数据,采用lightgbm模型,深度分析孕妇早孕期(<13周)产检数据,得到不同孕妇未来发生妊娠糖尿病的具体风险。
本方法的lightgbm预测模型可以利用早孕期简单可得的产检数据,大幅度提升早期预测妊娠糖尿病的准确度,模型曲线下面积达80%以上,预测准确率近乎达80%。此外,我们的模型能够具体输出每个病人发生gdm的风险的预测值,实现个体化诊疗。且整个方法通过计算机软件完成,快速简单准确。本发明具有实施简单便捷、结果准确性高等优点。
附图说明
图1为软件连续迭代至停止训练截图;
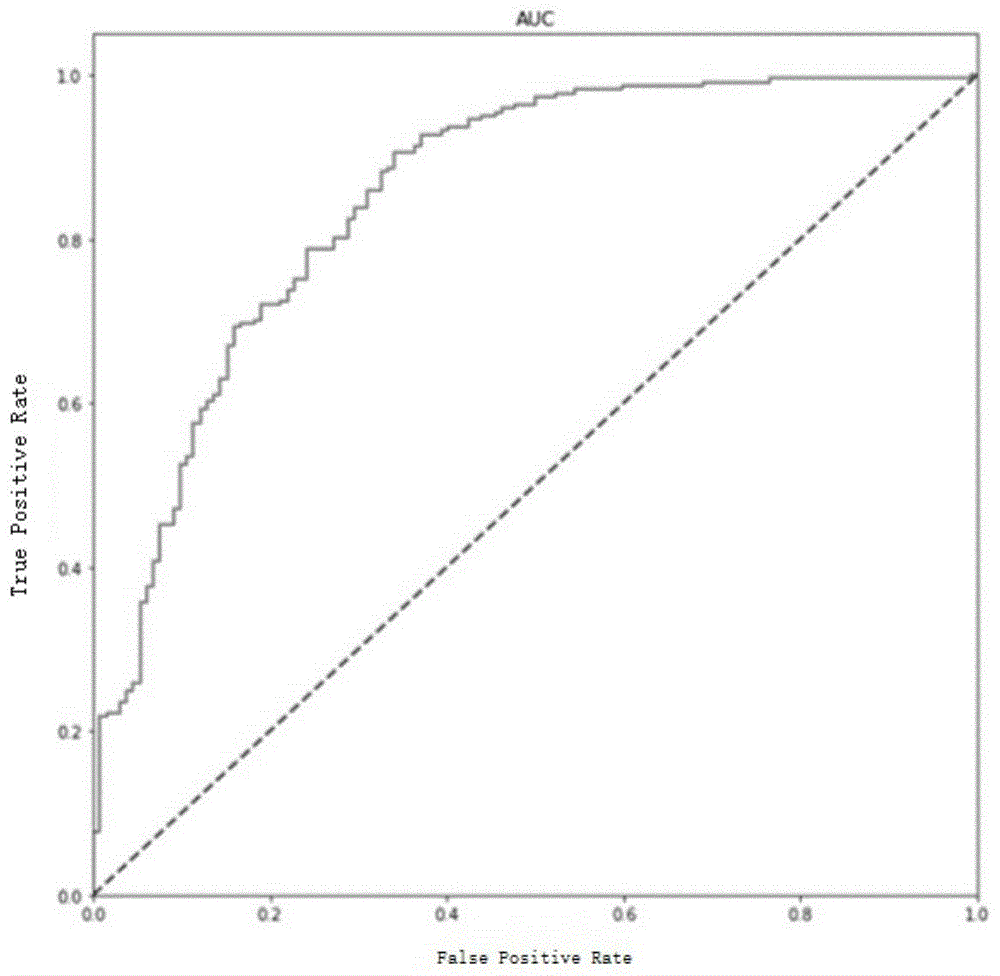
图2是验证集模型roc曲线下面积图;
图3是部分预测孕妇的预测风险值y'的输出截图;
图4是预测结果准确率的计算截图。
具体实施方式
以下结合具体实施例对本发明作进一步说明。
本发明提供一种早期预测妊娠糖尿病的方法,包括以下步骤:
步骤一、临床回顾性收集若干例孕期血糖正常和患有妊娠期糖尿病的已生产孕妇,作为总收集例,收集各例信息数据。信息数据包括基本信息、现病史与既往史、月经史、家族史及实验室检查。其中,基本信息包括孕妇年龄、孕前身高、孕前体重、血压、学历、月经史和孕产次。现病史与既往史包括是否有多囊卵巢综合征、慢性高血压和妊娠期糖尿病病史。月经史包括初潮年龄、月经是否规律。家族史指是否有糖尿病家族史。实验室检查包括早孕期肝功能(谷丙转氨酶和谷草转氨酶)和血浆空腹血糖、孕14-20周生化检查(谷丙转氨酶、谷草转氨酶、甘油三酯、胆固醇、高密度胆固醇脂蛋白、低密度胆固醇脂蛋白和空腹血糖)和血常规(血红蛋白、白细胞和血小板)。
其中,总收集例中,孕期血糖正常和患有妊娠期糖尿病的已生产孕妇的比例越接近1:1,模型曲线下面积越高,预测模型的预测能力越好。优选的,总收集例中,孕期血糖正常和患有妊娠期糖尿病的已生产孕妇的比例为1:1。
步骤二、在步骤一的总收集例中随机抽取若干例作为训练集。利用python语言,运用spyder或者jupyternotebook软件编译“是否”型的lightgbm模型。设置模型参数,然后导入训练集各例的信息数据和最终是否患妊娠期糖尿病结果,建立lightgbm预测模型。
其中,模型参数为:
最大深度(max_depth)为10;
叶子节点数量(num_leaves)为50;
学习率(learning_rate)为0.005;
评估指标(eval_metric)为曲线下面积。
信息数据为n个,则导入的数据格式为:(x1,x2,.....,xn,y)。
其中,x1、x2、.....、xn分别为n个信息数据的导入数值,y是孕妇最终是否进展为妊娠期糖尿病,定义y=1表示孕妇最后发生了妊娠期糖尿病,y=0表示孕妇血糖处于正常范围。
具体的,对导入的数据进行多轮迭代,采用损失函数的负梯度作为当前决策树的残差近似值,去拟合新的决策树,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练后得到强学习器,循环迭代至auc无法再提高时,则停止训练,生成lightgbm预测模型。
本实施例中,在总收集例中随机抽取70%总收集例作为训练集,采用python语言进行代码编辑,编译环境为spyder或者jupyternotebook软件,设置参数后,导入训练集各例的信息数据和最终是否患妊娠期糖尿病结果,即(x1,x2,.....,xn,y),进行多轮迭代,当连续迭代200次auc无法再提高时,则停止训练,如图1所示,生成最终的lightgbm预测模型。
在lightgbm预测模型构建完成后,将总收集例中剩余例作为验证集,将验证集的信息数据导入lightgbm预测模型中,运用python语言中的sklearn机器学习模块的roc-curve和auc方法进行roc曲线代码编译,输出验证集模型roc曲线下面积,验证lightgbm预测模型。
在本实施例中,将总收集例中剩余例,即剩余30%总收集例作为验证集,将验证集的信息数据导入lightgbm预测模型中,运用python语言中的sklearn机器学习模块的roc-curve和auc方法进行roc曲线代码编译,输出验证集模型roc曲线下面积为0.864,如图2所示。
步骤三、将待预测孕妇的信息数据输入步骤二构建的lightgbm预测模型,得到未来发生妊娠期糖尿病风险的预测风险值,根据预测风险值确定预测孕妇是否会患病。
其中,得到未来发生妊娠期糖尿病风险的预测风险值为y',y'>50%定义为会发生妊娠期糖尿病,输出标签值为1;y'<50%定义为不会发生妊娠期糖尿病,输出标签值为0。
本实施例中,将若干例待预测孕妇的信息数据输入步骤二构建的lightgbm预测模型,个体化输出每位孕妇的未来发生妊娠期糖尿病风险的预测风险值y',每个孕妇的预测风险值y'以逗号隔开,部分预测风险值y'的输出如图3所示,孕妇1孕中晚期发生妊娠期糖尿病的风险为94.2%,孕妇2孕中晚期发生妊娠期糖尿病的风险为2.5%。
将孕妇的预测结果与最终孕妇实际是否发生妊娠期糖尿病的真实值进行比较,发现我们的lightgbm预测模型最终预测妊娠期糖尿病的准确率为79.9%,结果如4图所示。
- 还没有人留言评论。精彩留言会获得点赞!