机械学习装置及方法、机器人控制装置、机器人系统与流程
本发明涉及一种学习人的行为模式的机械学习装置、机器人控制装置、机器人系统及机械学习方法。
背景技术:
在现有技术中,为了确保人的安全,采用了如下的安全对策:在机器人驱动的期间,人不进入机器人的作业区域。例如,在机器人的周边设置安全栅,在机器人的驱动期间,禁止人进入到安全栅的内部。近年来,已知人与机器人协作来进行作业的机器人系统。在该机器人系统中,在机器人的周边不设置安全栅的状态下,机器人和人可以同时进行一个作业。
在日本特开2015-123505号公报中公开了与人进行协作作业的工业机器人。该机器人具备被底部支持的可动部、由刚性比可动部低的材质形成且覆盖可动部的周围的保护部件、设于可动部且检测经由保护部件输入的外力的检测器。
按照预先生成的动作程序驱动一般的工业机器人。或者,以通过由示教编程器等预先示教的示教点的方式驱动机器人。即,沿着预先决定的轨道驱动机器人。
在人与机器人协作来进行作业的机器人系统中,也可以预先设定机器人的轨道,沿着所生成的轨道驱动机器人。然而,在人与机器人协作来进行作业的情况下,有时作业方法并不一般。例如,在制造产品的工厂等,有时将工件从初始位置搬运至目标位置。为了搬运工件,有时人与机器人协作来抬起工件,搬运至目标位置。机器人可以抬起搬运物并进行搬运。在该情况下,抬起工件的方向和速度等,存在多个选项。
依存于针对工件的机器人的控制方法,人的负担度变化。例如,即使在进行同一作业的情况下,人的疲惫程度也变化,负担度还根据离人的距离或速度而变化。因此,优选适当地设定机器人的控制方法。然而,存在多个机器人的控制方法。此外,有时人的行为模式因作业内容而不同。因此,存在难以根据作业内容设定最佳的机器人的控制方法的问题。
技术实现要素:
根据本发明的第1实施方式,提供一种在人与机器人协作来进行作业的机器人的机械学习装置,其中,具备:状态观测部,其在上述人与上述机器人协作地进行作业的期间,观测表示上述机器人的状态的状态变量;判定数据取得部,其取得与上述人的负担度以及作业效率中的至少一方相关的判定数据;以及学习部,其根据上述状态变量以及上述判定数据,学习用于设定上述机器人的行为的训练数据集。
优选地,上述状态变量包括上述机器人的位置、姿势、速度以及加速度中的至少一个。优选地,上述判定数据包括上述机器人感知的负荷的大小或方向、上述机器人的周围感知的负荷的大小或方向、上述机器人的周围的负担度以及上述机器人的移动时间中的至少一个。
上述训练数据集包括对上述机器人的每个状态以及上述机器人的每个行为设定的表示上述机器人的行为的价值的行为价值变量,上述学习部包括:回报计算部,其根据上述判定数据以及上述状态变量设定回报;以及函数更新部,其根据上述回报以及上述状态变量,更新上述行为价值变量。优选地,上述机器人的加速度的绝对值越小,上述回报计算部设定越大的回报,上述机器人的移动时间越短,上述回报计算部设定越大的回报。
上述训练数据集包括对上述机器人的每个状态以及上述机器人的每个行为设定的上述机器人的学习模型,上述学习部包括:误差计算部,其根据上述判定数据、上述状态变量以及所输入的教师数据,计算上述学习模型的误差;以及学习模型变更部,其根据上述误差以及上述状态变量,更新上述学习模型。优选地,该机械学习装置还具备:人判别部,其判别与上述机器人协作地进行作业的人,对每个人生成上述训练数据集,上述学习部学习所判别出的人的上述训练数据集,或者,上述机械学习装置具备神经网络。优选地,上述机器人为工业机器人、场地机器人或服务机器人。
根据本发明的第2实施方式,提供一种机器人控制装置,其包括上述机械学习装置和行为控制部,其控制上述机器人的行为,上述机械学习装置包括:意图决定部,其根据上述训练数据集设定上述机器人的行为,上述行为控制部根据来自上述意图决定部的指令控制上述机器人的行为。
根据本发明的第3实施方式,提供一种机器人系统,其包括上述的机器人控制装置、辅助人的作业的机器人、安装在上述机器人上的末端执行器。上述机器人包括:力检测器,其输出与来自上述人的力对应的信号;以及状态检测器,其检测机器人的位置以及姿势,上述判定数据取得部根据上述力检测器的输出取得上述判定数据,上述状态观测部根据上述状态检测器的输出取得上述状态变量。上述状态检测器可以包括人感传感器、压力传感器、电动机的转矩传感器以及接触传感器中的至少一个。该机器人系统具备:多个机器人;多个机器人控制装置;以及相互连接多个上述机器人控制装置的通信线,多个上述机器人控制装置中的各个机器人控制装置个别地学习进行控制的机器人的上述训练数据集,经由通信线发送所学习的信息来共享信息。
根据本发明的第4实施方式,提供一种人与机器人协作来进行作业的机器人的机械学习方法,其中,包括如下步骤:在上述人与上述机器人协作来进行作业的期间,观测表示上述机器人的状态的状态变量的步骤;取得与上述人的负担度以及作业效率中的至少一方相关的判定数据的步骤;以及根据上述状态变量以及上述判定数据,学习用于设定上述机器人的行为的训练数据集的步骤。
附图说明
通过参照以下的附图,更明确地理解本发明。
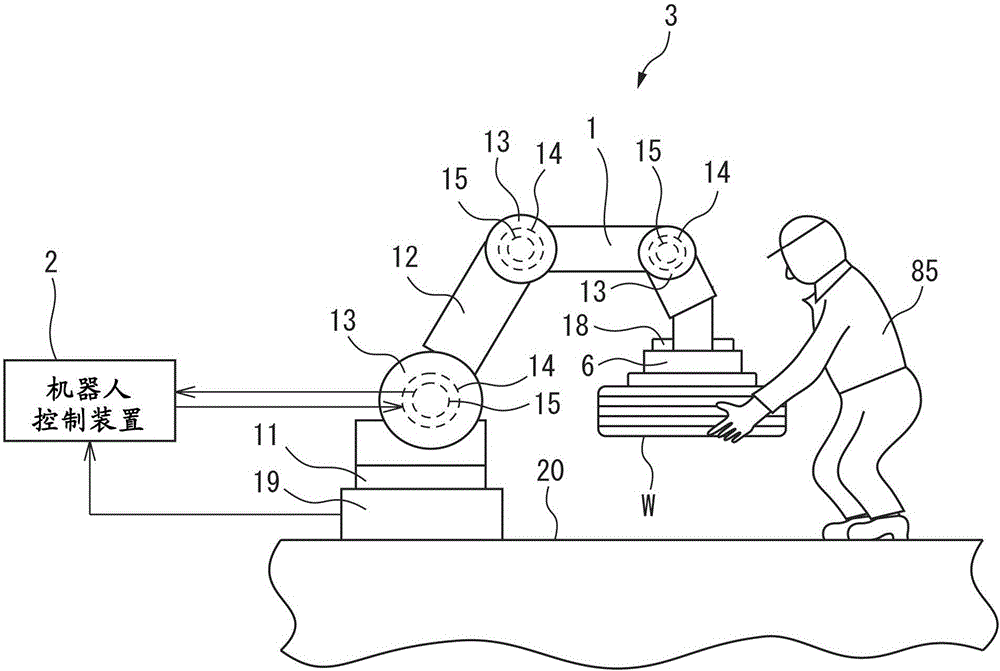
图1是概要性地表示实施方式中的机器人和人进行协作作业的情况的图。
图2是表示实施方式中的一例的机器人系统的框图。
图3是示意性地表示神经元的模型的图。
图4是示意性地表示组合图3所示的神经元而构成的三层的神经网络的图。
图5是说明搬运工件的路径的概要图。
图6是说明机器人前端点的移动点的图。
图7是说明机器人前端点的移动点的放大图。
图8是表示实施方式中的其他例子的机器人系统的框图。
图9是表示图2所示的机器人系统的变形例的框图。
具体实施方式
以下,参照附图对实施方式中的机械学习装置、机器人控制装置、机器人系统以及机械学习方法进行说明。然而,应当理解本发明并不限定于附图或以下说明的实施方式。
在机器人系统中,人和机器人协作地进行预先决定的作业。在本实施方式中,示出了人和机器人协作来搬运工件的例子并进行说明。
图1表示本实施方式中的机器人系统的概要图。图2表示本实施方式中的一例的机器人系统的框图。参照图1和图2,机器人系统3具备辅助工件W的搬运的机器人1和控制机器人1的机器人控制装置2。本实施方式的机器人1是包含臂部12和多个关节部13的多关节机器人。机器人系统3具备安装在机器人1上的作为末端执行器的手部6。手部6具有把持或释放工件W的功能。末端执行器并不限定于手部,可以使用与作业内容对应的末端执行器。
机器人1包括驱动各个关节部13的臂部驱动装置44。臂部驱动装置44包括配置于关节部13的内部的臂部驱动电动机14。臂部驱动电动机14进行驱动,从而可以使臂部12通过关节部13弯曲成所希望的角度。此外,本实施方式的机器人1形成为整个臂部12可围绕向铅垂方向延伸的旋转轴进行旋转。臂部驱动电动机14包括使臂部12旋转的电动机。
机器人1具备打开或关闭手部6的手部驱动装置45。本实施方式的手部驱动装置45包括驱动手部6的手部驱动缸18、用于向手部驱动缸18提供压缩空气的空气泵以及电磁阀。
机器人1具备支持臂部12的底座部11。本实施方式中的机器人1具备用于检测向底座部11作用的力的力检测器19。向底座部11作用的力相当于作用于机器人1的力。力检测器19输出与来自人的力对应的信号。本实施方式的力检测器19被固定在地面20。
作为力检测器19,可以采用可检测作用于机器人1的力的大小以及力的方向的任意的检测器。本实施方式的力检测器19包括与底座部11连接的金属基材和安装于基材表面的应变传感器。并且,力检测器19可以根据由应变传感器检测出的变形量,计算出作用于机器人1的力。
本实施方式的机器人1包括用于检测机器人的位置以及姿势的状态检测器。状态检测器检测出机器人前端点的位置以及机器人1的姿势。本实施方式的状态检测器包括安装于各臂部驱动电动机14的旋转角检测器15。旋转角检测器15检测出臂部驱动电动机14驱动时的旋转角。可以根据各臂部驱动电动机14的旋转角,检测出机器人1的位置、姿势、速度以及加速度。
另外,作为状态检测器,除了旋转角检测器15外,例如可以使用摄像机、人感传感器、压力传感器、电动机的转矩传感器以及接触传感器等。即,作为状态观测部51观测的状态变量,除了旋转角检测器15的输出外,也可以是从摄像机、人感传感器、压力传感器、电动机的转矩传感器以及接触传感器等得到的数据(状态量)。当然,这些摄像机、人感传感器、压力传感器、电动机的转矩传感器以及接触传感器等例如可以直接设于机器人1(手部6)的预定位置,或者也可以安装在机器人1周边的恰当的位置。
根据机器人控制装置2的动作指令驱动机器人1。机器人控制装置2包括运算处理装置,该运算处理装置具有经由总线相互连接的CPU(Central Processing Unit,中央处理单元)、RAM(Random Access Memory,随机存取存储器)以及ROM(Read Only Memory,只读存储器)等。机器人控制装置2包括存储各种信息的存储部59。机器人控制装置2包括控制臂部驱动装置44以及手部驱动装置45的行为控制部43。根据来自行为控制部43的动作指令,臂部驱动装置44以及手部驱动装置45进行驱动。
本实施方式的机器人控制装置2包括推定从机器人1的外侧向机器人1施加的外力的外力计算部46。通过力检测器19检测出的力包括因机器人1的质量以及机器人的动作产生的内力、从机器人1的外侧向机器人1施加的外力。
在没有从机器人1的外侧施加力的状态下,外力计算部46计算出在机器人1动作时因自重而作用于机器人1的内力。可以根据通过旋转角检测器15的输出而检测出的机器人的位置、姿势以及机器人的质量等,计算出内力。机器人1的质量等可以预先存储在存储部59中。外力计算部46从由力检测器19检测出的力减去内力来计算出外力。外力相当于人85向工件施加的力。
机器人控制装置2包括输入部41以及显示部42。显示部42形成为可显示与机器人1的运转相关的信息。作为显示部42,可以示例液晶显示装置。输入部41形成为人可向机器人控制装置2输入所希望的指令。作为输入部41,可以示例键盘等。
图5是说明在本实施方式的机器人系统中,搬运工件的路径的概要图。参照图1和图5,在本实施方式中,进行将配置于地面20的工件W搬运到作业台81的上表面的作业。例如,工件W为重量较大的工件。若人85想要搬运这样的工件,则非常疲惫或难以搬运。本实施方式的工件W为汽车轮胎。
在搬运工件W的情况下,如箭头91~93所示,存在多条搬运工件W的路径。此外,存在人85需要较大力的区间,或较小的力就足够的区间等。此外,即使工件W的位置相同,也存在机器人1的各种姿势。
参照图2,本实施方式的机器人控制装置2具备机械学习装置5,该机械学习装置5学习人的行为模式,学习机器人的控制方法以便对人进行适当的辅助。本实施方式的机械学习装置5在机器人1驱动的期间中的预先决定的移动点,选择判断为最佳的机器人1的行为。即,机械学习装置5发送在判断为最佳的驱动模式下驱动机器人1的指令。
机械学习装置5具备状态观测部51,该状态观测部51在人85和机器人1协作进行作业的期间,取得表示机器人1的状态的状态变量。本实施方式的状态变量为机器人1的位置、姿势、速度以及加速度。例如,可以将机器人前端点的位置、速度、加速度用作状态变量。可以根据旋转角检测器15的输出检测出机器人1的位置、姿势、速度以及加速度。向状态观测部51输入旋转角检测器15的输出信号。
作为状态变量,并不限于该形态,可以使用表示机器人的状态的任意的变量。例如,状态观测部51可以取得机器人1的位置、姿势、速度、加速度中的至少一个变量。
机械学习装置5具备取得与人85的负担相关的判定数据的判定数据取得部52。本实施方式的判定数据包括搬运工件W时人85施加的力的大小以及人85施加的力的方向。此外,本实施方式的判定数据包括移动工件W时的移动时间。
本实施方式的判定数据取得部52根据力检测器19的输出取得判定数据。通过外力计算部46计算出的外力的大小相当于人85的力的大小。通过外力计算部46计算出的外力的方向相当于人85向工件W施加的力的方向。判定数据取得部52从外力计算部46接收人的力的大小以及人的力的方向。
机器人控制装置2具备测定作业时间的移动时间测定部47。本实施方式的移动时间测定部47计算出在后述的移动点之间移动时的移动时间。本实施方式的移动时间测定部47根据行为控制部43的指令计算出移动时间。将通过移动时间测定部47测定出的移动时间发送给判定数据取得部52。
作为判定数据,并不限于上述形态,可以采用与人的负担度以及作业效率中的至少一方相关的任意数据。例如,作为判定数据,除了机器人感知的负荷的大小及其方向、周围的人或物所感知的负荷的大小及其方向、周围的人或物的负担度以及移动时间等外,还可以利用来自摄像机、人感传感器、压力传感器等的信息。另外,在本说明书中,人除了实际与机器人协作来进行处理(作业)的作业者外,例如还包括如下的各种人:不直接操作机器人,但在机器人周边观察处理的人,或者偶尔通过机器人附近的人。
本实施方式的机械学习装置5具备学习部54,该学习部54根据状态变量和判定数据学习用于设定机器人的行为的训练数据集。学习部54从状态观测部51取得状态变量。此外,学习部54从判定数据取得部52取得判定数据。训练数据集是根据状态变量和判定数据决定的行为的价值信息的集合。机械学习装置5可以通过比较与训练数据集的状态以及行为相关的值来设定机器人的驱动方法。另外,本实施方式的应用并不限定于工业机器人,例如,当然也可以应用于场地机器人、服务机器人。
在此,对机械学习装置进行说明。机械学习装置具有如下的功能:通过解析从输入到装置的数据集合中提取其中的有用的规则、知识表现、判断基准等,输出该判断结果,并且进行知识的学习(机械学习)。机械学习方法有多种,例如大致分为“有教师学习”、“无教师学习”以及“强化学习”。而且,实现这些方法时,还有学习特征量其本身的提取的、称为“深层学习(Deep Learning)”的方法。
另外,图2所示的机械学习装置5应用了“强化学习”,此外,参照图9后述的机械学习装置7应用了“有教师学习”。这些机械学习(机械学习装置5、7)也可以使用通用的计算机或处理器,但若例如应用GPGPU(General-Purpose computing on Graphics Processing Units,通用计算图形处理单元)、大规模PC群集等,则能够进行更高速处理。
首先,有教师学习是如下方法:通过向机械学习装置大量提供教师数据即某输入和结果(标签)的数据的组,学习这些数据集中的特征,通过归纳获得根据输入推定结果的模型(学习模型)即其关系性。例如,能够通过后述的神经网络等算法来实现。
此外,无教师学习是如下方法:通过向学习装置仅大量提供输入数据,学习输入数据如何分布,即使不提供对应的教师输出数据,也能够通过对输入数据进行压缩、分类、整形等的装置进行学习。例如,能够在相似者之间对这些数据集中的特征进行聚类。使用该结果设置某基准,并进行使之最佳化的输出分配,由此能够实现输出的预测。
另外,作为无教师学习与有教师学习的中间的问题设定,有称为半有教师学习的学习,这例如对应于如下的情况:存在仅部分输入和输出的数据组,除此以外为仅输入的数据。在本实施方式中,在无教师学习中利用即使不使机器人实际移动也能够取得的数据(图像数据、模拟数据等),由此能够有效地进行学习。
接着,对强化学习进行说明。首先,作为强化学习的问题设定,按如下方式进行思考。
·机器人观测环境状态,决定行为。
·环境按照某种规则变化,并且,有时自身的行为也会对环境产生变化。
·每次实施行为时,返回回报信号。
·想要最大化的是将来的(折扣)回报的合计。
·从完全不知道或不完全知道行为引起的结果的状态起开始学习。即,机器人实际行为后,可以初次将该结果作为数据而得到。换句话说,需要一边试错一边探索最佳行为。
·也可以将进行了事先学习(上述的有教师学习、逆强化学习的方法)的状态设为初始状态,从较佳的开始地点开始学习以便模拟人的动作。
在此,强化学习是指如下的方法:除了判定和分类外,通过学习行为,根据行为对环境产生的相互作用来学习恰当的行为,即学习进行用于使将来得到的回报最大化的学习的方法。以下,作为例子,在Q学习的情况下继续说明,但并不限定于Q学习。
Q学习是在某环境状态s下学习用于选择行为a的价值Q(s,a)的方法。换句话说,在某状态s时,将价值Q(s,a)最高的行为a选择为最佳行为即可。但是,最初,对于状态s和行为a的组合,完全不知道价值Q(s,a)的正确值。因此,智能体(行为主体)在某状态s下选择各种行为a,针对此时的行为a提供回报。由此,智能体选择更佳的行为,即学习正确的价值Q(s,a)。
并且,行为的结果,想要使将来得到的回报的合计最大化,因此以最终Q(s,a)=E[Σ(γt)rt]为目标。在此,E[]表示期待值,t为时刻,γ为后述的称为折扣率的参数,rt为时刻t的回报,Σ为时刻t的合计。该式中的期待值是按照最佳的行为发生状态变化时所取的值,不知道该值,因此一边探索一边学习。例如,可以通过下式(1)表示这样的价值Q(s,a)的更新式。
在上述式(1)中,st表示时刻t的环境状态,at表示时刻t的行为。通过行为at,状态变化为st+1。rt+1表示根据该状态变化得到的回报。此外,附有max的项为在状态st+1下选择此时获知的Q值最高的行为a时的Q值乘上γ而得的项。在此,γ为0<γ≤1的参数,称为折扣率。此外,α为学习系数,设为0<α≤1的范围。
上述的式(1)表示如下方法:根据尝试at的结果而返回的回报rt+1,更新状态st下的行为at的评价值Q(st,at)。即,表示若基于回报rt+1和行为a的下个状态下的最佳行为max a的评价值Q(st+1,max at+1)的合计大于状态s下的行为a的评价值Q(st,at),则将Q(st,at)设为较大,相反,若小于状态s下的行为a的评价值Q(st,at),则将Q(st,at)设为较小。换句话说,作为结果,使某状态下的某行为的价值接近基于作为结果而立即返回的回报和该行为的下个状态下的最佳行为的价值。
在此,Q(s,a)的计算机上的表现方法有:对于所有状态行为对(s,a),将其值作为表而保持的方法;以及准备近似Q(s,a)的函数的方法。在后者的方法中,能够通过概率梯度下降法等方法来调整近似函数的参数,由此实现上述式(1)。另外,作为近似函数,可以使用后述的神经网络。
此外,作为有教师学习、无教师学习的学习模型,或者强化学习中的价值函数的近似算法,可以使用神经网络。图3是示意性地表示神经元的模型的图,图4是示意性地表示组合图3所示的神经元而构成的三层神经网络的图。即,神经网络例如由模仿图3所示的神经元的模型的运算装置以及存储器等构成。
如图3所示,神经元输出针对多个输入x(在图3中,作为一例为输入x1~输入x3)的输出(结果)y。对各输入x(x1,x2,x3)乘以与该输入x对应的权值w(w1,w2,w3)。由此,神经元输出通过下式(2)表现的结果y。另外,输入x、结果y以及权值w全部为向量。此外,在下式(2)中,θ为偏置,fk为激活函数。
参照图4,说明组合图3所示的神经元而构成的三层的神经网络。如图4所示,从神经网络的左侧输入多个输入x(在此,作为一例为输入x1~输入x3),从右侧输出结果y(在此,作为一例为结果y1~输入y3)。具体地,输入x1、x2、x3乘以对应的权值后输入3个神经元N11~N13中的各个神经元。将这些对输入乘以的权值统一表述为W1。
神经元N11~N13分别输出z11~z13。在图4中,这些z11~z13被统一表述为特征向量Z1,可以视为提取出输入向量的特征量而得的向量。该特征向量Z1为权值W1与权值W2之间的特征向量。z11~z13乘以对应的权值后分别输入2个神经元N21、N22中的各个神经元。将这些对特征向量乘以的权值统一表述为W2。
神经元N21、N22分别输出z21、z22。在图4中,将这些z21、z22统一表述为特征向量Z2。该特征向量Z2为权值W2与权值W3之间的特征向量。z21、z22乘以对应的权值后分别输入到3个神经元N31~N33的各个神经元。将这些对特征向量乘以的权值统一表述为W3。
最后,神经元N31~N33分别输出结果y1~结果y3。神经网络的动作中有学习模式和价值预测模式。例如,在学习模式中,使用学习数据集学习权值W,在预测模式中使用其参数判断机器人的行为。另外,方便起见,写成了预测,但也可以是检测/分类/推论等多种任务。
在此,能够进行在线学习和批学习,其中,在线学习为即时学习在预测模式下实际使机器人动作而得到的数据,并反映到下个行为;批学习是使用预先收集的数据群进行统一学习,以后一直用该参数进行检测模式。或者,也可以进行其中间的、每当一定程度的数据积压时插入学习模式。
此外,可以通过误差反向传播法(Back propagation)学习权值W1~W3。另外,误差信息从右侧进入并流向左侧。误差反向传播法是如下的方法:针对各神经元,调整(学习)各个权值以使输入了输入x时的输出y与真正的输出y(教师)的差值变小。
这样的神经网络为三层以上,还可以进一步增加层(称为深层学习)。此外,也可以自动地仅从教师数据获得阶段性地提取输入的特征并返回结果的运算装置。因此,一实施方式的机械学习装置5为了实施上述的Q学习(强化学习),如图2所示,具备例如状态观测部51、学习部54以及意图决定部58。但是,如上所述,应用于本发明的机械学习方法并不限定于Q学习。即,可以应用在机械学习装置中能够使用的方法即“有教师学习”、“无教师学习”、“半有教师学习”以及“强化学习(Q学习以外的强化学习)”等各种方法。
图6是说明本实施方式的移动点的概要图。在图6中,为了简化说明,示出了机器人前端点在二维平面上移动的例子。工件W从初始位置88被搬运至目标位置89。在机器人前端点有可能移动的区域中格子状地设定了移动点P。移动点P成为机器人前端点通过的点。机器人前端点从与初始位置88对应的移动点P00移动至与目标位置89对应的移动点Pnm。
图7表示说明机器人前端点的移动的概要图。在本实施方式中,在各个移动点P预先决定了机器人前端点的移动方向。箭头94~97所示的方向为机器人前端点的移动方向。当机器人前端点位于1个移动点P时,通过下个行为,机器人前端点移动到相邻的其他移动点P。在图7所示的例子中,当机器人前端点配置于移动点P11时,机器人前端点向移动点P12、P21、P10、P01中的某个点移动。
在本实施方式中,进行各种机械学习方法中的采用了上述的Q学习的强化学习。此外,本实施方式的训练数据集包括多个行为价值变量Q。另外,如上所述,本实施方式可以应用“有教师学习”、“无教师学习”、“半有教师学习”以及“强化学习(包括Q学习)”等各种方法。
在本实施方式中,状态st对应于机器人1的状态变量。即,状态st包括机器人1的位置、姿势、速度以及加速度等。行为at关于机器人前端点的移动,例如相当于箭头94~97所示的方向的移动。行为at例如包括与箭头94~97所示的方向的移动相关的机器人1的位置、姿势、速度以及加速度等。
本实施方式的学习部54在每次进行工件W的搬运时更新行为价值变量Q。学习部54包括设定回报的回报计算部55和更新行为价值变量Q的函数更新部56。回报计算部55根据判定数据取得部52取得的判定数据设定回报rt。此外,回报计算部55也可以根据由状态观测部51取得的状态变量设定回报rt。
回报计算部55可以设定人的负担(负担度)越小,作业效率越高则越大的回报rt。例如,在工件W大幅度减速或大幅度加速的情况下,对人的负担增大,作业效率变低。即,可以认为机器人1的加速度的绝对值(加速度的大小)越小,则人的负担越小,作业效率越高。另外,若加速度的绝对值大,则机器人1急剧进行动作,因此可以判别为非优选的状态。因此,回报计算部55可以设定机器人1的加速度的绝对值越小则越大的回报。此外,人施加的力的大小越小越好。因此,回报计算部55可以设定人施加的力的大小(向机器人施加的外力的大小)越小则越大的回报。
并且,将工件W从初始位置88搬运至目标位置89的作业时间越短,则人的负担越小,作业效率越高。因此,回报计算部55设定移动点P之间的移动时间越短则越大的回报。此外,在图5的形态下,若工件W向下移动,则搬运路径变长。因此,在机器人前端点的位置向下侧移动,或人施加的力的方向为下侧的情况下,回报计算部55设定小的回报。在此,作为人的负担度,不仅表示对人的负担的程度,还包括基于各种原因的负荷,例如对人的意外的接触或按压等,并且,除了人,例如还可以包括对周围的物品的负担度。
此外,回报计算部55可以根据任意的人的行为设定回报。例如,在工件W与作业台81碰撞的情况下,回报计算部55可以设定小的正的回报或负的回报。
在回报的设定中,例如人可以预先决定与力的大小等变量对应的回报的值,并存储在存储部59中。回报计算部55可以读入存储于存储部59的回报来设定。或者,预先使存储部59存储人用于计算回报的计算式,回报计算部55根据计算式计算出回报。
接着,函数更新部56使用上述的式(1)或式(2)更新行为价值变量Q。即,根据实际的机器人的行为以及人施加的力,更新预先决定的移动点的机器人的行为的价值。
另外,人也可以预先设定各个移动点P的行为价值变量Q的初始值。另外,人也可以预先设定随机的初始值。
机械学习装置5包括根据训练数据集设定机器人1的行为的意图决定部58。本实施方式的意图决定部58根据通过学习部54更新的行为价值变量Q设定机器人1的行为。例如,意图决定部58可以选择行为价值变量Q最大的行为。在本实施方式的强化学习中使用ε-greedy方法。在ε-greedy方法中,意图决定部58以预先决定的概率ε设定随机的行为。此外,意图决定部58以概率(1-ε)设定行为价值变量Q最大的行为。即,意图决定部58通过概率ε的比例选择与被认为最佳的行为不同的行为。通过该方法,有时可以发现比判定为最佳的机器人的行为更好的机器人的行为。
将通过意图决定部58设定的机器人1的行为指令发送给行为控制部43。行为控制部43根据来自意图决定部58的指令控制机器人1和手部6。
这样,本实施方式的机械学习方法包括如下的步骤:在人与机器人协作来作业的期间,取得表示机器人的状态的状态变量;以及取得与人的负担度以及作业效率中的至少一方相关的判定数据。机械学习方法包括根据状态变量和判定数据,学习用于决定机器人的行为的训练数据集的步骤。
本实施方式的机械学习装置以及机械学习方法重复进行工件W的搬运,由此可以根据人的行为模式学习机器人的控制方法。并且,能够设定人的负担较小、作业效率高、作业时间更短的最佳的机器人的控制方法。
另外,作为在机械学习装置以及机械学习方法中进行的机械学习,并不限于上述方式,可以进行任意的机械学习。例如,机械学习装置也可以通过深层学习使用神经网络来多层化并设定最佳的行为。代替使用将多个行为以及多个状态设为函数的行为价值变量表,也可以使用输出给出预定状态时的与各个行为对应的行为价值变量的神经网络。
在上述的实施方式中,格子状地配置了移动点,但并不限于该形态,也可以以任意形态设定移动点。此外,通过缩小移动点之间的间隔,能够使机器人的动作变得流畅。在上述的实施方式中,在平面上设定了移动点,因此机器人的移动成为平面状,但通过将移动点配置于三维空间,能够使移动点三维地移动。
参照图5,本实施方式的机械学习装置5包括判别人的人判别部57。预先生成每个人的训练数据集。存储部59存储每个人的训练数据集。在本实施方式中,人85向输入部41输入每个人的编号。人判别部57根据所输入的编号从存储部59读入与人对应的训练数据集。然后,学习部54学习与人对应的训练数据集。通过进行该控制,可以对每个人设定基于人的行为模式的机器人的控制方法。即,可以对每个人实施最佳的机器人的控制。例如,人有高个的人、矮个的人、腰腿强壮的人、臂力强的人等各种人。能够与各个人对应地实现最佳的机器人的控制。
另外,作为判别人的控制,并不限于上述方式,可以采用任意的方法。例如,可以在机械学习装置中配置编号读取装置。人持有记载了个别编号的牌。然后,编号读取装置读取编号并将结果发送给人判别部。人判别部可以根据所读取的编号来判别人。
图8是表示本实施方式的其他机器人系统的框图。在其他机器人系统(制造系统)4中进行分散学习。如图8所示,其他机器人系统4具备多个机器人和多个机器人控制装置。机器人系统4具备第1机器人1a和第2机器人1b。机器人系统4具备安装于第1机器人1a的第1手部6a和安装于第2机器人1b的第2手部6b。这样,其他机器人系统4具备2个机器人1a、1b和2个手部6a、6b。
机器人系统4具备控制第1机器人1a的第1机器人控制装置2a和控制第2机器人1b的第2机器人控制装置2b。第1机器人控制装置2a的结构以及第2机器人控制装置2b的结构与上述机器人控制装置2的结构相同。多个机器人控制装置2a、2b通过包含通信线21的通信装置相互连接。通信装置例如可以通过以太网(注册商标)实施通信。机器人控制装置2a、2b形成为可以通过通信交换相互的信息。
在机器人系统4中,多个机器人1a、1b和人协作来进行作业。在图8所示的例子中,通过2台机器人辅助人的作业。第1机器人控制装置2a个别地学习第1机器人1a的控制。此外,第2机器人控制装置2b个别地学习第2机器人1b的控制。并且,可以经由通信线21相互发送通过各个机器人控制装置学习的信息。
这样,第1机器人控制装置2a和第2机器人控制装置2b可以共享通过各个机器人控制装置2a、2b学习的信息。通过实施该控制,能够共享用于学习的行为模式等,增加学习次数。该结果,能够提高学习精度。
在上述实施方式中,示例了搬运工件W的协作作业,但作为协作作业,并不限于该方式,可以采用任意的协作作业。例如,可以示例机器人和人协作地将1个部件安装到预定装置的作业等。
图9是图2所示的机器人系统的变形例的框图,表示应用了有教师学习的机器人系统3’。如图9所示,机器人系统3’例如包括机器人1、手部6以及机器人控制装置2’。机器人控制装置2’包括机械学习装置7、输入部41、显示部42、行为控制部43、外力计算部46以及移动时间测定部47。机械学习装置7包括状态观测部71、判定数据取得部72、学习部74、人判别部77、意图决定部78以及存储部79。学习部74包括回报计算部55和函数更新部56。
即,从图9与上述图2的比较可知,在图9所示的变形例的机器人系统3’的学习部74中,将图2的学习部54中的回报计算部55和函数更新部56置换为误差计算部75和学习模型变更部76。另外,实质上,其他结构与图2所示的机械学习装置5中的结构相同,因此省略其说明。从外部向误差计算部75输入教师数据,例如进行与通过到此为止的学习得到的数据的误差变小的计算,通过学习模型变更部76更新学习模型(误差模型)。即,误差计算部75接受状态观测部71的输出以及教师数据等,例如计算带结果(标签)的数据与安装于学习部74的学习模型的输出的误差。在此,在向机器人控制装置2’输入的程序(机器人系统3’处理的动作)相同的情况下,教师数据可以保持使机器人系统3’进行处理的预定日的前日为止得到的带结果(标签)的数据,在该预定日向误差计算部75提供带结果(标签)的数据。
或者,通过存储卡或通信线路向该机器人系统3’的误差计算部75提供通过在机器人系统3’的外部进行的模拟等得到的数据或其他机器人系统的带结果(标签)的数据作为教师数据。并且,例如通过内置于学习部74的闪速存储器(Flash Memory)等非易失性存储器保持带结果(标签)的数据,在学习部74中可以直接使用该非易失性存储器所保持的带结果(标签)的数据。
以上,在考虑具备多个机器人系统3’(3)的制造系统(制造设备)的情况下,例如对每个机器人系统3’(3)设置机械学习装置7(5),对每个机器人系统3’(3)设置的多个机械学习装置7(5)例如可以经由通信介质相互共享或交换数据。此外,机械学习装置7(5)例如也可以存在于云服务器上。
通过本发明,提供一种能够学习人的行为模式,设定对人进行适当的辅助的机器人的控制方法的机械学习装置、机器人控制装置、机器人系统以及机械学习方法。
以上,对实施方式进行了说明,但在此记载的所有例子或条件是以帮助理解应用于发明和技术的发明概念为目的而进行的记载,所记载的例子或条件并不特别限制发明的范围。此外,说明书的这样的记载并不表示发明的优点和缺点。虽然详细地记载了发明的实施方式,但应理解为在不脱离发明的主旨以及范围的情况下能够进行各种变更、置换、变形。
- 还没有人留言评论。精彩留言会获得点赞!