自适应不同用户的智能显示装置的制作方法
本发明涉及显示领域,具体而言,尤其涉及一种自适应不同用户的智能显示装置。
背景技术:
单屏或多屏显示,在会展、培训、酒店、商场等等领域得到广泛的商业应用。随着科技的飞速发展进步,显示装置的应用已经深入到各行各业中,尤其是液晶显示及led显示器已经愈发广泛,而目前又有许多广告牌或宣传牌直接采用显示器作为其播放内容的媒介,所以使得显示装置的使用范围更加广泛。
在日常生活中,许多城市中的交通道路人流量、车流量很大,许多商家借此在十字路口、转弯路口、与马路相邻的某些住宅小区门口及学校门口等场所设置一些用于播放公益广告的显示装置和用于播放阅读、科普或广告的显示装置等作为广告宣传设施。但是,现今的道路上的显示屏等设施功能单一,广告形式往往过于单一,而且播放的次序往往是预设的,广告无法做到自适应不同用户的人群,无法与大众形成互动,影响了广告的效果,同时容易使行人产生视觉疲劳,既造成了资源的浪费又无法产生预期的广告效果。
技术实现要素:
本发明的目的是克服现有技术存在的不足,提供一种自适应不同用户的智能显示装置。
本发明的目的通过以下技术方案来实现:
一种自适应不同用户的智能显示装置,至少包括设置在显示装置上用于储存至少一将被显示的多媒体数据物件的储存装置、用以决选一所述储存装置内的多媒体数据物件的处理装置以及用以将所述处理装置选择的多媒体数据物件进行播放的播放器,还包括与所述处理装置连接的智能音箱,所述智能音箱用以对用户的语音信息进行解析并回应相应的视音频信息或/和用以对用户的人脸进行识别并在所述播放器上播放相应年龄段的视频或图片信息。
优选的,所述播放器至少包括用于播放公益广告或公益宣传的第一显示装置和用于播放阅读、科普或广告的第二显示装置。
优选的,所述智能音箱包括用以对用户的语音信息进行解析的语音识别装置,所述语音识别装置至少包括用于获取用户语音信息的语音获取装置,所述语音获取装置与内置有存储器、运算器及处理器的神经计算棒连接,所述神经计算棒用以对所述语音获取装置所接收的语音信息进行解析,解析完成后在其内置的存储器中进行搜索相应答案,并将相应答案转换成文本信息或/和视频或图片信息发送至所述处理装置,所述处理装置接收到所述神经计算棒传送的相应答案在所述播放器中以文本或/和视频或图片信息显示出来。
优选的,所述语音识别装置内还包括麦克风,所述麦克风与所述神经计算棒连接。
优选的,所述智能音箱包括用于对用户的人脸进行识别的人脸识别装置,所述人脸识别装置至少包括依次连接的用于监测区域空间内来自人体的红外线的红外传感器、用以对所述红外传感器所检测的人体从不同角度同时进行拍摄视角图像的摄像头组以及用以对所述摄像头组拍摄的图像进行人脸图像捕捉的人脸捕捉装置,所述人脸捕捉装置与用于初步估计所述人脸捕捉装置所捕捉的人脸的偏航角,并检测到偏航角最小的人脸视角图像的正脸估计装置连接;所述人脸识别装置还包括从一个姿态正的人脸三维模型获得所述正脸估计装置的预定人脸特征点的三维坐标以及从所述正脸估计装置中检测所述预定人脸特征点的二维坐标,根据获得的所述预定人脸特征点的二维坐标和三维坐标计算相对于拍摄所述具有偏航角最小的人脸的视角图像的图像捕捉设备的第一头部姿态的姿态估计装置,所述姿态估计装置与所述正脸估计装置连接,所述人脸识别装置将识别后的用户的年龄段传送至内置有存储器、运算器及处理器的神经计算棒,所述神经计算棒对所述人脸识别装置传输的数据进行解析,解析完成后在其内置的存储器中进行搜索相应答案,并将相应答案转换成相应数据发送至处理装置,所述处理装置接收到所述神经计算棒传送的相应答案在所述播放器中以文本或/和视频或图片信息显示出来。
优选的,所述姿态估计装置还包括:
三维坐标获取模块,根据预定人脸特征点在所述人脸三维模型上的位置,获得预定人脸特征点的三维坐标;
特征点检测模块,从所述检测的视角图像中检测预定人脸特征点,并获得检测的预定人脸特征点的二维坐标;
姿态估计模块,利用获得的预定人脸特征点的二维坐标和三维坐标来计算第一头部姿态。
优选的,所述姿态估计装置计算的所述第一头部姿态包括俯仰角、偏航角、滚转角,其中,
偏航角
俯仰角
滚转角
其中,头部姿态信息
其中,a为预定人脸特征点的三维坐标,b为预定人脸特征点的二维坐标。
优选的,所述姿态估计装置将正脸图像发送至皮肤分析装置,所述皮肤分析装置用以对正脸的色泽和色度进行检测,并将检测后的数据与所述皮肤分析装置内置的数据库进行对比,从而判定出人体的年龄段,所述皮肤分析装置将判定后的数据发送至所述处理装置。
优选的,所述姿态估计装置将正脸图像发送至图像处理模块,所述图像处理模块用于对人脸的正脸图像进行灰度化、光照补偿预处理,从而获得灰度图像,所述图像处理模块与用于从所述图像处理模块上提取出人脸部分特征值的特征提取模块连接,所述特征提取模块与用于将所述特征提取模块提取出的人脸部分特征值与人脸数据库存储区所存储的各年龄段的人脸数据进行比对的人脸分析模块连接,所述人脸分析模块将对比后的数据发送至所述处理装置。
优选的,所述智能音箱与后端平台连接,所述后端平台与复数个客户端无线连接,所述客户端上设有app软件。
本发明的有益效果主要体现在:结构简单精巧,通过人脸识别装置可以根据不同用户、不同性别选择性播放与其相适应的公益广告、科普、阅读及公益宣传等,以满足不同人的需求,同时,语音识别装置可和神经计算棒相配合通过视音频多元化的方式实现对用户的问题的回答,与用户之间形成互动,极大的增加了趣味性。
附图说明
下面结合附图对本发明技术方案作进一步说明:
图1:本发明的结构示意图;
图2:本发明人脸识别装置的结构示意图;
图3:本发明语音识别装置的结构示意图。
具体实施方式
以下将结合附图所示的具体实施方式对本发明进行详细描述。但这些实施方式并不限于本发明,本领域的普通技术人员根据这些实施方式所做出的结构、方法、或功能上的变换均包含在本发明的保护范围内。
如图1至图3所示,本发明揭示了一种自适应不同用户的智能显示装置,至少包括设置在显示装置上用于储存至少一将被显示的多媒体数据物件的储存装置1、用以决选一所述储存装置1内的多媒体数据物件的处理装置2以及用以将所述处理装置2选择的多媒体数据物件进行播放的单屏或多屏的播放器3,所述播放器3上还可设有gpu,用以对所述播放器3进行图形处理,可采用触摸屏,所述触摸屏也为电容式触摸屏,所述的电容式触摸屏包括一基材,所述基材的正面为触控操作面,所述基材的背面依次贴覆有一成像层和一用于感应触控信号的导线层;所述成像层为正投影成像层或者背投影成像层;所述导线层为由超细导线分别沿x轴和y轴方向绕制的、盘错交织的经纬线网,所述超细导线在交叉点处相互绝缘,每个网格所围设的空间构成一个感应单元,所述导线层的输出端与一感应信号采集控制集成电路连接。所述导线层上的感应单元彼此交错布置,或成蜂窝状、或成矩形状、或成不规则菱形状,所述感应单元之间的间隔大小相同或不同。所述导线层的输出端通过超细导线以压接或插接或焊接方式与所述感应信号采集控制集成电路上设置的、与所述超细导线输出匹配的引脚相接。
所述储存装置1可为快闪记忆体、随机存取记忆体、硬碟机、光碟片、或任意形式的大数据储存媒体。所述处理装置2耦接至储存装置1,并且自储存装置1取得多媒体数据物件。上述中所述处理装置2可为中央处理单元、微处理装置、或其它类似的装置,用以执行内嵌或储存于储存装置1的电脑可读取的程序码,以处理显示该多媒体数据物件的程序,可与安卓等系统兼容。
除了显示多媒体数据物件,处理装置2更为观赏由显示装置显示的多媒体数据物件的观赏者(即,显示装置的使用者)提供避免眼睛疲劳的功能,以避免观赏者因用眼过度而产生眼睛疲劳的情况。在一些眼睛疲劳的情况之下,可能进一步造成近视。值得注意的是,根据本发明所揭示的智能显示装置,所述显示装置可实施为一积体电路以及/或一播放器,所述播放器3,其耦接至一或多个播放装置3-1~3-n,用以播放由播放器所显示的多媒体物件数据。播放器3可以是任一可显示多媒体数据物件的装置,例vcd/dvd播放器3,而显示装置可以是电视机、屏幕、手机、投影机,或其它。根据本发明所揭示的智能显示装置,显示装置也可为可显示并播放多媒体数据物件的播放装置,例如电视机,其可透过电缆线以有线的方式、或透过无线电接口(interface)以无线的方式、或透过互联网接收多媒体数据物件(例如,电视节目)。
当接收到要被播放的多媒体数据物件时,处理装置2可决定多媒体数据物件的一物件类别,并根据一播放模式显示该多媒体数据物件,其中播放模式是根据物件类别被选择或决定。当多媒体数据物件为一影片或一电视节目时,多媒体数据物件的物件类别可以是影片或电视节目的型态、制作影片或电视节目的方法、影片或电视节目的类型、或其它。更具体的说,处理装置2可决定多媒体数据物件是否为电影或电视节目、多媒体数据物件是否为使用2d或3d技术制作的物件、3d的多媒体数据物件是使用哪种3d影片制作方法(例如,红蓝色片(anaglyph)、偏光(polarization)、遮影(eclipse)、或其它方法)制作出来的、多媒体数据物件是否为新闻节目、谈话节目、影集、或其它、多媒体数据物件是否为恐怖片、爱情片、文艺片、动作片、或其它。物件类别可被储存于多媒体数据物件的标头档中的特定栏位,或者被储存于多媒体数据物件的目录中。例如,当多媒体数据物件被储存于蓝光碟片中时,标头档的格式栏位可提供这些信息(例如,关于被储存的影片档是2d或3d的影片)。又例如,当多媒体数据物件为被广播的数位电视的电视节目时,物件类别可由广播的电子节目表(electronicprogramguide,简称epg)中取得。
处理装置2还可与移动ai芯片连接,通过使用神经处理引擎,来获得更快的运行速度,其运行速度比普通状态下的cpu处理器的运行速度快四倍之多,同时,还可对储存装置1及播放器3进行系统优化,使其运行速度得到极大,当然了,本发明中所述处理装置2不仅限于与所述移动ai移动芯片连接,还可与其他芯片连接,通过芯片来提高其反应速度以及系统优化均处于本发明所保护的范围内。
在决定多媒体数据物件的物件类别后,处理装置2可包含cpu处理系统,可在开始显示多媒体数据物件后,根据物件类别决定是否观赏该多媒体数据物件的一观赏者已发生或即将发生眼睛疲劳的情况,用以为观赏者提供可避免眼睛疲劳的功能。在取得一多媒体数据物件并决定该多媒体数据物件的一物件类别(后,处理装置根据一播放模式显示该多媒体数据物件。所述处理装置2可根据物件类别决定或选择播放模式。在显示多媒体数据物件的期间,处理装置更取得观赏多媒体数据物件的一观赏者的眼睛疲劳相关信息,并根据物件类别以及/或取得的信息决定观赏者是否已发生或即将发生眼睛疲劳。当处理装置决定观赏者已发生或即将发生眼睛疲劳时,处理装置可根据物件类别调整用以显示多媒体数据物件的播放模式。
所述储存装置1内可事先储存多个观赏者的眼睛疲劳相关信息。这些信息可透过不同的方式取得。例如,处理装置可提供一接口(例如,于一首页目录或是一特定的目录中的使用者接口(userinterface,简称ui)),用以与使用者互动,以收集时间相关信息,例如当使用者开始观赏影片多久后,经过多久时间使用者会感觉疲倦或眼睛开始感觉疲劳,或者使用者所设定的预防眼睛疲劳时间(即,当预防眼睛疲劳时间到时,使用者希望被提醒要闭眼休息)。处理装置可更进一步分析这些收集到的时间信息,以取得各使用者的使用习惯,并将取得的使用者使用习惯储存起来作为各使用者的眼睛疲劳相关信息。
以下将介绍一些处理装置2取得使用者的眼睛疲劳相关信息的案例。值得注意的是以下并非用以限定本发明的范围。如所述处理装置2首先辨识使用者的身份。辨识身份的方法可以是透过指纹辨识(例如,使用者可透过遥控器控制显示装置的操作)、或者透过显示装置所提供的使用者接口接收使用者所输入的身份信息。无论是透过输入指纹或透过使用者接口,待使用者输入身份信息后,处理装置2可接收到夹带着使用者身份相关信息的对应信号。
当使用着的身份被辨识出来后,处理装置2可提供另一接口与使用者互动,藉此使用者可输入其使用习惯,或所谓的时间信息。例如,当使用者开始观赏影片多久后,经过多久时间使用者会感觉疲倦或眼睛开始感觉疲劳,或者上述的预防眼睛疲劳时间。处理装置2可接收到夹带使用者所输入的时间信息的一回应信息。所述处理装置2也可通过遥控器上的特定按键取得时间信息,其中此按键,上述中所述遥控器的按键,可为特别设计用来收集时间信息的按键。例如,当使者在观看影片或电时节目时,一旦使用者感到疲倦或眼睛开始感觉疲劳时,可按下此特定的按键(即,让特定的按键由一状态改变为另一状态),用以通知处理装置2。通知的信息可在特定的按键被按下后,被传送至处理装置2。接收到通知信息后,处理装置2可调整显示模式,并进一步因应该通知信息计算使用者开始感觉疲倦或该观赏者的眼睛开始感觉疲劳的时间。例如,处理装置2可得知使用者已经观看影片或电时节目多久了,并藉此取得时间信息。无论是使用者自己输入或者透过上述特定的按键输入,处理装置2都可以得到包含使用者眼睛疲劳相关信息的相关回应信息或通知信息。处理装置2可接着将取得的信息储存于储存装置1,作为处理多媒体数据物件的参考信息。
值得注意的是,使用者的眼睛疲劳相关信息可分别对应于不同的使用者被储存,甚至可分别对应于不同的物件类别被储存。更具体的说,处理装置2可分别针对不同使用者储存对应的眼睛疲劳相关信息。此外,对于各使用者,眼睛疲劳相关信息(以下简称为疲劳信息)可更进一步根据不同的物件类别被分类。例如,处理装置2可分别储存使用者观赏2d影片、3d影片、新闻、影集、或其它多媒体数据物件的疲劳信息。又例如,处理装置2可更分别储存使用者观赏不同类型的电影的疲劳信息,例如恐怖电影、爱情电影、文艺电影、动作电影、或其它。疲劳信息可以表格的形式被储存于储存装置1内,并且当需要时,处理装置2可通过查表取得一特定使用者以及/或一特定的物件类别的疲劳信息。
所述处理装置2也为使用者将一或多个特定的物件类别相关的疲劳信息储存于储存装置1内,并且根据一既定法则推导出未被储存于储存装置1内的其它物件类别相关的疲劳信息。例如,处理装置2可储存使用者观赏2d影片时的相关疲劳信息(例如,观赏2d影片时,使用者多久开始觉得疲倦或眼睛疲劳,或者上述的预防疲劳时间),并根据2d影片相关的疲劳信息推导出该使用者观赏3d影片时的疲劳信息。更具体的来说,假设观赏2d影片的疲劳信息为2小时,处理装置2可,例如将2乘上一个既定的数值(例如,0.75),推导出观赏3d影片的疲劳信息为1.5小时。因此,当处理装置2显示3d多媒体数据物件达1.5小时后,处理装置2可调整显示模式(以下段落将作详细的介绍)。如此一来,由于使用者可以不需手动为各种物件类别分别输入疲劳信息,使用便利性可大幅提升,此外用以储存疲劳信息的记忆体空间也可被优化。
进一步,本发明中优选所述播放器3至少包括用于播放公益广告或公益宣传的第一显示装置31和用于播放阅读、科普或广告的第二显示装置32,采用两个显示装置用以满足各式人群的需求,同时又可以宣传正能量,当然,也可以为上述中所涉及的多个显示装置。上述中公益广告和公益宣传可用于政治环境下的宣传,是党的宣传工作新渠道,是继报纸、电视、广播、网络外又开辟的一条宣传工作的主战场,可深入宣传贯彻党和国家领导人的重要精神,以社会主义核心价值观为引路,为正确舆论引导“铺路搭桥、深入生活、深入群众”,为实现“两个一百年”奋斗目标,为实现中华民族伟大复兴中国梦提供强大的价值引导力、文化凝聚力和精神推动力,本发明中所用的播放器3主应用在户内落地式或悬挂式,当然,所述播放器3不局限于上述中所述第一显示装置31和第二显示装置32。
所述智能音箱4包括用以对用户的语音信息进行解析的语音识别装置5,所述语音识别装置5至少包括一种能够按照事先设定或存储的指令,自动进行数值计算和/或信息处理的电子设备,其硬件包括但不限于微处理装置、专用集成电路(applicationspecificintegratedcircuit,asic)、可编程门阵列(fieldprogrammablegatearray,fpga)、数字处理装置(digitalsignalprocessor,dsp)、嵌入式设备等。所述语音识别装置5还可包括用户设备。所述用户设备包括但不限于任何一种可与用户通过键盘、鼠标、遥控器、触摸板或声控设备等方式进行人机交互的电子产品,例如,个人计算机、平板电脑、智能手机、个人数字助理(personaldigitalassistant,pda)、游戏机、交互式网络电视(internetprotocoltelevision,iptv)、智能式穿戴设备等。其中,所述用户设备所处的网络包括但不限于互联网、广域网、城域网、局域网、虚拟专用网络(virtualprivatenetwork,vpn)等,所述用户设备所处的网络也可以为其他网络设置。
需要说明的是,所述用户设备仅为举例,其他现有的或今后可能出现的用户设备如可适应于本发明,也应包含在本发明的保护范围以内,并以引用方式包含于此。
当所述语音识别装置5至少包括用于获取用户语音信息的语音获取装置51,用于当用户输入语音信息时,获取该用户输入的语音信息,利用基于预设模型的大词汇量语音识别方法(例如,基于隐马尔可夫模型的大词汇量语音识别方法)对所输入的语音信息进行识别得到第一语音识别结果,利用基于辅助语音数据包的语音识别方法(例如,根据该用户当前的地理位置信息调用与该地理位置信息相对应的辅助语音数据包进行识别得到第二语音识别结果。所述语音获取装置51通过比较第一语音识别结果和第二语音识别结果得到一个最优识别结果,不仅提高了语音识别率,还提高了用户的体验。
所述语音识别装置5还可以与tpu连接,用以基于深度学习语音识别模型的语音搜索服务,其具有更强大、更高效的处理芯片。
所述语音获取装置51与内置有存储器、运算器及处理器的神经计算棒52连接,所述神经计算棒52内置了存储器、运算器、处理器等高级芯片,其实就是一个微型电脑,可实现对所述语音获取装置51所获取的数据的解析,所述神经计算棒52的存储器用于存储安裝于所述语音识别装置5中的软件程序及数据。该存储器可以是所述语音识别装置5的内部存储器,例如所述语音识别装置5的硬盘或者内存。该存储器也可以是所述语音识别装置5的外部存储设备,例如所述语音识别装置5上的插接式硬盘、智能媒体卡(smartmediacard,smc)、安全数字卡(securedigitalcard,sd)、快闪存储器卡(flashcard)等储存单元。进一步地,所述存储器还可以既包括所述语音识别装置5的内部存储器,也可以包括外部存储设备。
本发明中,所述存储器中不仅可以存储社会主义核心价值观的观念,还可存储如中华传统美德,例如:百德孝为先等美德,也可以存储旅游景点的画面、语言及文本,例如:桂林山水甲天下的语言、乌江的画面及阳朔山水甲桂林等画面等,同时,也可以存储医疗知识,例如当用户身体感到不适时,可根据自身症状对提出疑问,所述存储器内存储有相应的答案;所述存储器还可以教育知识,甚至还可以存储科普知识。
在本发明中,所述存储器中预先存储有多个辅助语音数据包及与该多个辅助语音数据包相对应的语音信息。所述辅助语音数据包可以是基于地理位置的语音数据包,对应地,所述存储器中存储的是具有该地理位置语音特征的语音信息。
在本发明中,所述的地理位置是以地市为单位进行划分的。在其他实施例中,对于方言复杂的地理位置,还可细分到地市以下的区域,例如,以县级市为单位进行划分或者以设定的区域为单位进行划分。
由于在同一地理位置,所讲的普通话也会存在口音和方言的区别。或者即使不在同一地理位置,方言或者口音也有可能相同,因此,所述存储器中存储的基于地理位置的语音数据包在其他的一些实施例中进一步包括基于方言和地理位置的语音数据包及基于口音和地理位置的语音数据包。
例如,基于方言和地理位置的语音数据包可以包括:粤语_香港、粤语_广州、闽南语_泉州、闽南语_厦门。基于口音和地理位置的语音数据包可以包括:口音_福建、口音_广州。需要说明的是,基于口音和地理位置的语音数据包包括,但不限于,声母、韵母的吐字方式以及前舌音和后舌音的吐字方式。
本发明中,所述存储器中还存储有旅游信息、医疗信息、教育信息、价值观等信息,所述处理器根据所述语音获取装置51所获取的语音,提取特征,对特征进行解析,所述神经计算棒52根据其储存器中所存在的知识对所述语音获取装置51所获取的语音所获取的语音进行答复。
在本发明中,所述神经计算棒52的处理器是一个或者多个中央处理装置(centralprocessingunit,cpu)、微处理装置或其他数字处理芯片等。该处理器用于执行软件程序代码或运算数据,例如执行所述的语音识别装置5。本实施例中,所述处理器接收用户输入的语音信息,同时获取该用户当前的地理位置信息,在进行语音识别时,结合基于预设模型的大词汇量语音识别(例如,基于隐马尔可夫模型的大词汇量语音识别方法,或者基于人工神经网络模型的语音识别方法)和基于辅助语音数据包的语音识别(例如,基于地理位置的辅助语音数据包的语音识别)分别输出第一识别结果和第二识别结果,根据用户比较第一识别结果和第二识别结果做出的选择,动态调整基于预设模型的大词汇量语音识别和基于辅助语音数据包的语音识别的权重,以提高语音识别的准确率。
所述处理器与所述语音识别装置5、存储单元、语音输入单元通讯连接。通讯可以通过串行外围设备接口总线(universalserialbus,usb)或其他通信路径或协议来实现。
所述语音识别装置5内还包括麦克风53,所述麦克风53与所述神经计算棒52连接,所述显示单元包括,但不限于,麦克风。
所述神经计算棒52用以对所述语音获取装置51所接收的语音信息进行解析,解析完成后在其内置的存储器中进行搜索相应答案,并将相应答案转换成文本信息或/和视频或图片信息发送至所述处理装置2,所述处理装置2接收到所述神经计算棒52传送的相应答案在所述播放器3中以文本或/和视频或图片信息显示出来。
所述语音识别装置5至少包括语音获取装置51及神经计算棒52。本发明所称的模块是指一种能够被处理单元所执行并且能够完成固定功能的一系列计算机程序段,其存储在存储单元中。在本发明中,关于各模块的功能将在后续详述。
所述语音获取装置51,用于获取用户输入的语音信息。
在本发明中,用户可以直接通过所述语音识别装置5输入语音,所述获取模块51根据用户输入语音的内容获取语音信息。
所述第一语音识别模块,用于识别所述语音信息得到第一识别结果。
所述第二语音识别模块,用于识别所述语音信息得到第二识别结果。
在本实施例中,所述第一语音识别模块可以是基于预设模型的大词汇量语音识别模块,所述第二语音识别模块可以是基于辅助语音数据包的语音识别模块。即利用基于辅助语音数据包的语音识别模块协助基于预设模型的大词汇量语音识别模块进行语音识别。所述基于辅助语音数据包的语音识别模块可以是基于地理位置建立的辅助语音数据包的语音识别模块。在一些实施例中,所述语音识别装置5可以先执行所述第一语音识别模块识别所述语音信息,再执行所述第二语音识别模块识别所述第二语音信息。
在一些实施例中,为了提高识别效率,所述语音识别装置5可以并行执行所述第一语音识别模块与所述第二语音识别模块分别识别所述语音信息。利用基于预设模型的大词汇量语音识别模块识别所述语音信息时,同时利用所述基于辅助语音数据包的语音识别模块识别所述语音信息,即所述语音识别装置5以第一线程运行所述第一语音识别模块以识别所述语音信息,并行地一第二线程运行所述第二语音识别模块以识别所述语音信息。
在本实施例中,基于预设模型的大词汇量语音识别模块是指按照标准普通话建立的语音识别库,任何用户均可以调用所述语音识别库,按照标准普通话进行识别。基于预设模型的大词汇量语音识别不考虑方言和地理位置及/或口音和地理位置的影响。所述基于预设模型的大词汇量语音识别模块与现有技术中的相同。
所述基于辅助语音数据包的语音识别模块(为便于描述,下文简称为“辅助语音识别模块”)考虑方言和地理位置及/或口音和地理位置的影响,需要事先通过训练和学习建立基于地理位置的语音数据包。
所述显示模块,用于根据预先设置的规则显示所述第一语音识别结果和第二语音识别结果。
本实施例中,所述预先设置的规则由所述设置模块预先设置。所述设置模块可以为所述第一语音识别结果预先分配第一权重,为所述第二语音识别结果预先分配第二权重,根据权重值的大小确定对应该权重值的语音识别结果的显示方式。所述第一权重值和所述第二权重值的总和可以为一固定数,例如,为整数1。优选地,所述设置模块预先设置的第一权重值大于第二权重值,也就是说所述设置模块为第一语音识别方法分配的权重值大于为第二语音识别方法分配的权重值。
在其他实施例中,所述设置模块预先设置的规则还可以是,为所述第一语音识别结果预先设置第一识别分数,为所述第二语音识别结果预先设置第二识别分数,根据识别分数的大小确定对应该识别分数的语音识别结果的显示方式。优选地,所述设置模块预先设置的第一识别分数值大于第二识别分数值。
所述语音识别结果的显示方式包括,但不限于:显示的时间及/或显示的位置。但不限于显示的时间和显示的位置。
例如,所述设置模块预先设置的规则是为语音识别结果分配权重,则当预先设置的第一权重值大于预先设置的第二权重值时,所述显示模块可以在所述显示单元上将对应权重值大的第一语音识别结果显示在第一位置,如所述显示单元提供的用户界面的上半部分;当预先设置的第一权重值小于预先设置的第二权重值时,所述显示模块将对应权重值小的第一语音识别结果显示在第二位置,如所述显示单元提供的用户界面的下半部分。
此外,当预先设置的第一权重值大于预先设置的第二权重值时,所述显示模块在所述显示单元上显示第一语音识别结果,在预设时间之后(例如,2秒后)在所述电子设备1的显示单元上显示第二语音识别结果。
在本实施例中,所述的语音识别装置5进一步包括更新模块,用于结合获取的用户反馈信息更新所述预先设置的规则。
本实施例中,所述用户反馈信息可以根据用户的操作得到。例如,用户选取了第一语音识别结果,则所述获取模块51获取到的用户反馈信息表示最佳语音识别结果是利用第一语音识别方法得到的。若用户选取了第二语音识别结果,则所述获取模块51获取到的用户反馈信息表示最佳语音识别结果是利用第二语音识别方法得到的。
所述更新模块更新所述预先设置的规则可以是调整预先设置的权重值或者调整预先设置的识别分数值。
具体地,所述更新模块根据用户选取的语音识别结果,将对应该语音识别结果的权重值或者识别分数值变大,及/或将用户没有选取的语音识别结果对应的权重值或者识别分数值减小。例如,当获取的用户反馈信息是选取了第一语音识别结果,则所述更新模块将对应该第一语音识别结果的第一权重值或者第一识别分数值变大,及/或将对应第二语音识别结果的第二权重值或者第二识别分数值减小。当获取的用户反馈信息是选取了第二语音识别结果,则所述更新模块将对应该第二语音识别结果的第二权重值或者第二识别分数值变大,及/或将对应第一语音识别结果的第一权重值或者第一识别分数值减小。
其中,上述的权重值或者分数值的变大或减小可根据预先设置的比例或者数值进行。
所述第二语音识别模块包括调用子模块、下载子模块确定子模块。本发明所称的模块是指一种能够被处理单元所执行并且能够完成固定功能的一系列计算机程序段,其存储在存储单元中。在本实施例中,关于各模块的功能将在后续的实施例中详述。
所述获取模块51,还用于接收到用户的语音信息时,获取该用户当前的地理位置信息。
在本实施例中,所述获取模块51通过所述语音识别装置5内置的定位模块及/或网络连接模块获取所述电子设备1当前所在的地理位置信息。所述定位模块包括,但不限于:全球定位系统(globalpositioningsystem,gps)。所述所述网络连接模块包括,但不限于:第3代移动通信技术(the3rdgenerationtelecommunication,3g)、通用分组无线业务(generalpacketradioservice,gprs)以及无线保真技术(wirelessfidelity,wi-fi)。所述电子设备1当前所在的地理位置信息即被认为是该用户当前所在的地理位置信息。
在一些实施例中,所述获取模块51还可以通过接收用户设置的指令,并根据该用户设置的指令确定该用户当前的地理位置信息。
例如,所述语音识别装置5中设置有位置选择列表,该位置选择列表包括中国所有城市的名称。用户通过触发该位置选择列表,选择与用户输入语音信息相应的地理位置信息。
又如,所述语音识别装置5中设置有文本输入框,用户通过激活该文本输入框功能,在相应的界面中输入当前地理位置信息。
所述调用子模,用于根据所述地理位置信息调用对应的辅助语音数据包。
在本实施例中,所述调用子模块根据所述地理位置信息从所述存储单元中调用对应的辅助语音数据包。
所述存储单元中预先存储有辅助语音数据包及该辅助语音数据包包括的具有地理位置语音特征的语音信息。
例如,所述地理位置信息是广东,则所述调用子模块调用识别广东语音特征的辅助语音数据包。
在一些实施例中,如果所述语音识别装置5的存储单元中没有预先存储有对应所述地理位置信息的辅助语音数据包时,则所述获取模块51在获取用户当前的地理位置信息时,执行所述下载子模块。所述下载子模块从与所述语音识别装置5通讯连接的服务器下载该辅助语音数据包。所述通讯连接可以是无线通讯连接。所述辅助语音数据包由用户事先进行训练和学习得到并布署于所述服务器,下载子模块可以通过网络请求所述服务器发送对应所述地理位置信息的辅助语音数据包。
所述第二语音识别模块,用于根据所述辅助语音数据包识别所述语音信息得到第二语音识别结果。
在本实施例中,第二语音识别模块利用所述第二语音识别方法识别所述语音信息得到所述第二语音识别结果。
进一步地,为了解决即使在同一地理位置也会存在方言或者口音的差别而造成的语音识别率不高的问题,所述第二语音识别模块还可以包括确定子模块:用于根据所述语音信息确定该用户的语音类型。所述调用子模块基于所述语音类型和所述地理位置信息共同确定对应的辅助语音数据包。
该用户的语音类型由用户语言的发音和音调决定,可以包括方言和口音。
例如,用户的当前的地理位置为广州,用户的语音类型是口音(例如,粤语),则所述调用子模块调用“口音_广州”的辅助语音数据包识别所述语音信息。
在一些实施例中,所述获取模块51还可以通过获取所述显示单元提供的包括有文本输入框的界面上输入的信息获取用户的语音类型或其他方式也可使用。
更进一步地,为了避免用户临时去某地出差或者旅游时,所述获取模块51获取该用户当前的地理位置信息,所述调用子模块根据该当前的地理位置信息调用相应的辅助语音数据包造成识别率低时,所述获取模块51还用于获取用户当前的地理位置信息以及历史地理位置信息,所述调用子模块根据历史地理位置信息和当前地理位置信息确定调用的辅助语音数据包。
在本实施例中,所述历史地理位置信息是指用户的经常居住地的地理位置信息。
例如,用户当前的地理位置为广州,而用户的经常居住地在福建,则所述调用子模块调用识别福建语音特征的辅助语音数据包来识别所述语音信息。
综上所述,本发明实施例公开的一种语音识别系统,预先通过训练和学习得到多个辅助语音数据包,该辅助语音数据包是以地理位置为单位进行划分的语音数据库。同时基于用户的语音类型,辅助语音数据包进一步细分为基于方言和地理位置的辅助语音数据包,以及基于口音和地理位置的辅助语音数据包。利用基于预设模型的大词汇量语音识别模块识别用户的语音信息时,同时也利用用该辅助语音数据包识别用户的语音信息从而协助所述基于预设模型的大词汇量语音识别方法,不仅提高了用户的语音识别率,也提高了用户体验。
目前的人脸识别技术主要集中在二维图像方面,但由于受到光照、姿势、表情变化的影响,识别的准确度受到很大限制。针对人脸识别的难点,本发明揭示了一种利用三维信息进行人脸的识别。
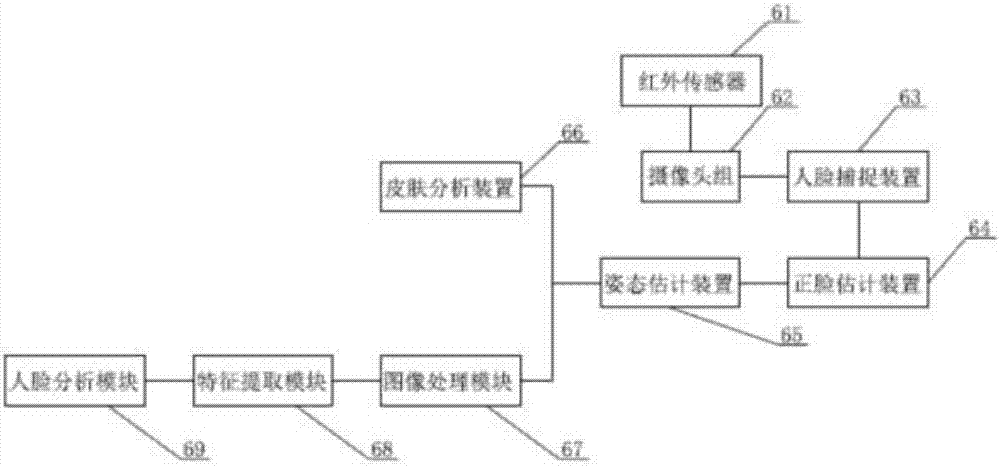
进一步的,所述智能音箱4包括用于对用户的人脸进行识别的人脸识别装置6,所述人脸识别装置6至少包括依次连接的用于监测区域空间内来自人体的红外线的红外传感器61,用以对所述红外传感器61所检测的人体从不同角度同时进行拍摄视角图像的摄像头组62以及用以对所述摄像头组62拍摄的图像进行人脸图像捕捉的人脸捕捉装置63,所述人脸捕捉装置63与用于初步估计所述人脸捕捉装置63所捕捉的人脸的偏航角,并检测到偏航角最小的人脸视角图像的正脸估计装置64;所述人脸识别装置6还包括从一个姿态正的人脸三维模型获得所述正脸估计装置64的预定人脸特征点的三维坐标以及从所述正脸估计装置64中检测所述预定人脸特征点的二维坐标,根据获得的所述预定人脸特征点的二维坐标和三维坐标计算相对于拍摄所述具有偏航角最小的人脸的视角图像的图像捕捉设备的第一头部姿态的姿态估计装置65,所述姿态估计装置65与所述正脸估计装置64连接。
下面本发明简单阐述一下人脸识别装置如何消除姿态对人脸识别的影响,上述中选择采用所述红外传感器61主要是利用任何温度高于绝对零度的物体,都会向外部空间以红外线的方式辐射能量,而人体的温度通常在37°~39°,可以被所述红外传感器61所感知,当所述红外传感器61感知到人体后,所述摄像头组62获取从不同角度同时拍摄的对象(即,用户)的图像(以下称为视角图像),例如,摄像头组62可以从以适当位置和姿态布置在检测环境中的多个图像捕捉设备来获取视角图像,所述摄像头组62与用以对所述摄像头组62拍摄的图像进行人脸图像捕捉的人脸捕捉装置63连接,所述人脸捕捉装置63将所述摄像头组62所拍摄的视觉图像中人脸全部捕捉,并将其传至所述正脸估计装置64。
所述正脸估计装置64从接收的视角图像中检测具有偏航角最小(即,最接近零)的人脸的视角图像(即,人脸最正的视角图像)。本领域的技术人员可以理解,这里的偏航角最小是通常意义上的,即,相对于该视角图像这个平面来说的(例如,人们拿到一张照片时会评价照片中人的头是否摆得正,即,偏航角是否为零)。换句话说,从不同角度拍摄的视角图像中检测的具有偏航角最小的人脸的视角图像实际上是由目标对象的脸最正对的图像捕捉设备所拍摄的视角图像。通过上述检测,可以找到此时目标对象的脸最正对的所述摄像头组62中的一个。
正脸估计装置64将该视角图像中的人脸图像发送到姿态估计装置65,以作为用于更精确地估计头部姿态的人脸图像。姿态估计装置65在从正脸估计装置64接收的人脸图像中检测预定的人脸特征点(例如,眼角、鼻尖、鼻翼、嘴角、脸部轮廓点等)以得到预定的特征点的二维坐标,并从一个人脸三维模型获取所述预定的人脸特征点的三维坐标,然后根据上述检测的人脸特征点的二维坐标和三维坐计算对象的相对于拍摄所述具有偏航角最小的人脸的视角图像的图像捕捉设备的头部姿态(即,偏航角、俯仰角和滚转角)。具体地说,头部姿态估计模块13可包括:特征点检测模块、三维坐标获取模块、姿态估计模块和坐标转换模块。
所述特征点检测模块用于从具有偏航角最小的人脸的视角图像中检测预定的人脸特征点,并获得其二维坐标,检测的预定的人脸特征点的二维坐标可被表示为:
这里,n表示检测的人脸特征点的数量。
可通过使用主动形状模型(asm)来检测对象人脸图像中检测预定的人脸特征点以获得其二维坐标。由于利用asm来检测人脸特征点是公知的,将不再进行详细描述。此外,这里也可以利用其他的人脸特征点检测方法,本发明不限于仅使用asm。
由于正面人脸的特征点最为丰富、易于定位、并且对人脸姿态比较敏感,所以选择偏航角最小的人脸的视角图像能够更精确的进行头部姿态的估计。
所述三维坐标获取模块从一人脸三维模型获得所述预定的人脸特征点的三维坐标a,其可以被表示为:
在本发明中,由于三维坐标a和二维坐标b从不同的对象获得,为了计算两者的旋转关系,三维坐标a和二维坐标b是被归一化的。在本发明的一个实施例中,所述归一化是仅对三维坐标a和二维坐标b各自的坐标系的坐标原点的归一化。即,将坐标原点设置在所述预定的人脸特征点在各个坐标轴上的坐标的算数平均值处。此时,对于三维坐标a,
本发明不限于上述归一化,还可进一步对三维坐标a和二维坐标b的尺度进行归一化。但是,在本发明中,也可不对尺度进行归一化。
这里的人脸三维模型优选地为标准的人脸三维模型。此时,三维坐标a可以被预先存储。
所述姿态估计模块利用从特征点检测模块接收的预定的人脸特征点的二维坐标b和从三维坐标获取模块接收的三维坐标a来得到对象相对于人脸三维模型的头部姿态(即,偏航角、俯仰角和滚转角)。具体地说,a、b以及头部姿态信息x之间的关系可表示为:
a=bx,则:
其中,
这里,p为俯仰角,q为偏航角,v为滚转角。
此时获得的头部姿态是基于正脸估计装置64检测的具有偏航角最小的人脸的视角图像获得的,是相对于摄该具有偏航角最小的人脸的视角图像的图像捕捉设备的头部姿态。因此,为了获得以世界坐标系表示的头部姿态,根据拍摄该具有偏航角最小的人脸的视角图像的图像捕捉设备的世界坐标系坐标,将通过姿态估计模块获得的以基于所述图像捕捉设备的本地坐标系表示的头部姿态转换为以世界坐标系表示的头部姿态。由于进行坐标系转换是公知的技术,将不再进行详细描述。例如,可通过摄像机标定(cameracalibration)技术来进行上述坐标系转换。
此外,在获得三维坐标a时,优选使用人脸三维模型姿态正时(即,俯仰角、偏航角和滚转角都为零)获得的三维坐标a。本领域的技术人员可以理解,与前面提到的视角图像类似,这里的人脸三维模型姿态正也是一般意义上的,即根据现有技术通过三维坐标a计算的人脸三维模型的俯仰角、偏航角和滚转角为零。也即,三维坐标a和二维坐标b都是使用视角图像和人脸三维模型各自的绝对坐标系。此时,获取所述三维坐标时人脸三维模型相当于正对着捕捉具有偏航角最小的人脸的视角图像的图像捕捉设备。
此外,三维坐标a可以不必是人脸三维模型姿态正时获得的三维坐标。由于利用式计算的头部姿态是相对于人脸三维模型的姿态,因此很容易理解,当三维坐标a在人脸三维模型姿态不正的情况下被获得时,可以利用人脸三维模型的姿态来补偿利用式计算的头部姿态,以得到与人脸三维模型姿态正时相同的结果。
本发明无需预先存储用户信息,实现了对人脸的精确捕捉,因此可以适应的范围更广,同时,可规避姿态对人脸识别技术的影响。
进一步,当所述姿态估计装置65将正脸图像发送至所述皮肤分析装置66后,通常需要对该图像进行预处理,这是因为待处理的人脸图像经常存在光照不均匀的问题,而这会直接影响到人脸的特征提取精度,因此对输入的图像必须进行光照处理以改善图像质量。一般地,灰度直方图可用于表示数字图像中每一个灰度级与其出现的频率之间的统计关系。对于偏暗、偏亮、亮度范围不足或对比度不足的图像进行直方图规定化,可以使得输入图像的直方图分布变换成近似特定的直方图。变换函数可以选用例如高斯、瑞利、对数、指数等形式的函数。在本实施例中采用对数变换形式:
式中,f(x,y)为输入图像,g(x,y)为输出图像,a、b、c是调整曲线的位置和形状而引入的参数。通过这种变换可以使图像低灰度范围得以扩展,高灰度范围能够被压缩,图像的灰度分布趋于均匀。优选地,对灰度变换后的图像再进行例如3×3的中值滤波,去除图像中引入的噪声信息,以改善图像质量。
提取人脸特征之后,使用根据本发明实施例的方法以获得所需的皮肤类型/问题所需输出结果,包括:检测皮肤色泽与色度、计算纹理对比度值、计算灰度平均值、并且将上述计算所得结果与该预设数据库进行匹配,并输出匹配所得的皮肤问题结果。
在本发明中,可以使用这样一种算法以检测皮肤色泽与色度,其中,以皮肤颜色矩阵的彩色/颜色强度分布表征来表征一彩色人脸图像。大多数的颜色分布信息可以由三个二阶矩阵来表示,其中,一线阶矩阵(μc)表征的是平均颜色,二线阶矩阵(δc)表征的是标准偏差,以及三阶矩表征的是偏斜度(θc)颜色。利用以下的数学公式,从这三个低次矩阵(μc、δc、θc)提取各三种色平面(r、g、b):
其中,m、n为图像的二维尺寸,i、j分别表示该像素点的所在行、列,c为颜色分量的值。其结果是,仅需要提取九个参数作为彩色人脸图像的特征,例如包括色平面参数(rgb)、平均颜色、标准偏差、偏斜度颜色、色泽色度值、纹理对比度、灰度平均值等,通过对以上皮肤色泽与色度的计算,可以得出输入人脸图像的对象皮肤色泽与色度等一系列参数数组。
在本发明中,以皮肤纹理检测算法计算纹理对比度值。纹理是人脸图像的特征,而纹理本身的一大特点是其图案的重复。在此,引入术语“纹理基元”,其意思即是指纹理的模式单元,纹理基元的大小、形状、颜色和取向可在很大的区间内变化,而且任意两个纹理之间的差异可以体现为纹理基元的变化程度。可构建一纹理共生矩阵,该纹理共生矩阵c(i,j)是由位移矢量dx、dy=(δx,δy)所定义的,其中δx、δy是分别在x方向和y方向上的位移,然后计算所有像素相隔位移dx、dy所具有的灰度级i和j。其也可能是由于图像中的纹理基元的空间统计分布,并且包含关于底层中的图像表面的结构布置等重要信息。然后,对矩阵c(i,j)中的每个元素进行归一化。通过对以上计算,可计算得出皮肤纹理的一系列参数数组,纹理对比度数值的计算公式为:
由此可得到输入人脸图像中对象皮肤纹理的对度比大小,也就能够表示对象皮肤纹理的深浅度。
在本实施例中,利用差和算法、以及该人脸图像的灰度值快速匹配算法,得到以下计算公式:
其中,e(si,j)与e(t)分别是用户皮肤子图si,j与所述皮肤分析装置66内置的数据库中的皮肤图像t(m,n)的灰度平均值。
然后,通过提取以上所得的数值,与所述皮肤分析装置66内置的数据库进行对比,从而判定出人体的年龄段,所述皮肤分析装置66将判定后的数据发送至所述处理装置2。
所述姿态估计装置65将正脸图像发送至图像处理模块67,所述图像处理模块67用于对人脸的正脸图像进行灰度化、光照补偿预处理,从而获得灰度图像,所述图像处理模块67与用于从所述图像处理模块67上提取出人脸部分特征值的特征提取模块68连接,所述特征提取模块68与用于将所述特征提取模块68提取出的人脸部分特征值与人脸数据库存储区所存储的各年龄段的人脸数据进行比对的人脸分析模块69连接,所述人脸分析模块69将对比后的数据发送至所述处理装置2。所述特征提取模块68包括至少包括眼部皱纹提取模块,以确定其年龄。
第一语音识别模块第二语音识别模块第一语音识别模块第二语音识别模块第一语音识别模块第二语音识别模块第一语音识别模块第二语音识别模块第一语音识别模块第二语音识别模块第一语音识别模块第二语音识别模块第二语音识别模块第二语音识别模块第二语音识别模块第二语音识别模块
更进一步,所述智能音箱4与后端平台连接,所述后端平台与复数个客户端无线连接,所述客户端上设有app软件。
本发明的有益效果主要体现在:结构简单精巧,通过人脸识别装置、语音识别装置及人机交互装置可以根据不同用户、不同性别选择性播放与其相适应的公益广告、科普、阅读及公益宣传等,以满足不同人的需求,同时,观看各自喜欢的广告、宣传及政事要闻不仅不会造成视觉疲劳,而且会带来超出预期的广告效应。
应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施方式中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!