基于云架构下的教学系统及决策方法与流程
本发明涉及教学系统领域,特别涉及一种基于云架构下的教学系统及决策方法。
背景技术:
目前在学校的教学过程中,课堂的教育方式基本是老师一个人以一种教学方法对一个班级中的许多学生,学生需要不断学习适应每一位老师。所谓的「因才施教」应该是指课后一对一的教学。所以,学生因为不同老师与不同地区对不同课程有着不同的理解,最后产生不同的喜好与结果。所以,尽管名师可以给大多数学生帮助,但不尽然都能到达每一位,对于现今强调创意与非记忆性的教学过程里面,急需一种辅助机制协助与众不同的学生进行深层的学习。
技术实现要素:
为了解决背景技术中的问题,本发明提供一种根据教学的不同状态、属性为学生选择不同教学机制的基于云架构下的教学系统及决策方法。
本发明解决其技术问题所采用的技术方案是一种基于云架构下的教学案例决策方法,决策方法包括:
(1)对决策问题进行详细的描述,包括该决策问题的目标、准则和子目标,以及该决策问题的可能产出及其目标;
(2)构建网络,所述网络由三部分组成,包括:saas层,包括该决策问题的目标、准则;paas层,包括该决策问题的子目标;iaas层,包括该决策问题的可能产出及其目标;
(3)初始化元素,所述元素包括群种n、初始的速度v和位置p,所述群种n包括教学质量x1、教学经济成本x2、和教学安全性x3;所述速度v代表元素间的关系密切度;所述位置p为每个群种内部的起点的初始位置;
(4)对元素及其组成的元素组进行适应值评估;
(5)确定元素、元素组的历史最优适应值;
(6)根据所得到的适应值数据建立并求解适应值矩阵;
(7)对每一控制准则的极限向量按照各准则权重进行加总,主要是对个可选方案的权重加总;
(8)根据各可选方案的权重值排序,计算每个案例的成本收益。
(9)根据各个案例的成本收益选出收益最大的案例作为优选案例。
构建网络后,首先构建无权重超矩阵,元素之间通过两两比较、归一化处理获得;然后依次构建多个判断矩阵,并对判断矩阵进行归一化处理,组成无权重超矩阵;其次在获得无权重超矩阵对元素组进行组间的比较,并依各准则进行元素组之间的比较,并将获得的各判断矩阵归一化,最后合并,再与无权重矩阵相乘,获得权重矩阵。
所述无权重超矩阵的构建包括:根据矩阵标度定义进行元素之间的比较。
所述监测案例选评模块第(4)、(5)步的所述适应值包括对于元素在元素组的适应值、元素组内部依赖适应值、元素组与元素组之间反馈关系适应值。
基于云架构下的教学系统包括:课后学习案例模块,所述课后学习案例模块包括传统型案例、小组分布型案例和人工智能辅助型案例;监测案例选评模块,所述监测案例选评模块具有所述决策方法。
所述传统型案例为一人对多人教学结合一人与多人共同学习模型,包括学习进度认证模块。
所述小组分布型案例为一人对多组教学结合各组共同学习模型,包括学习进度认证模块、计数模块。
所述人工智能辅助型案例为一人对多人教学结合一人与个人ai共同学习模型,包括学习进度认证模块、计数模块和数据模块。。
本发明的有益效果是:提供一种基于云架构下的教学系统,通过决策方法对教学实际状况的参数指标量化考核,通过监测案例选评模块选择最适合学生的课后学习教学案例,提高学生的学习效果。
附图说明
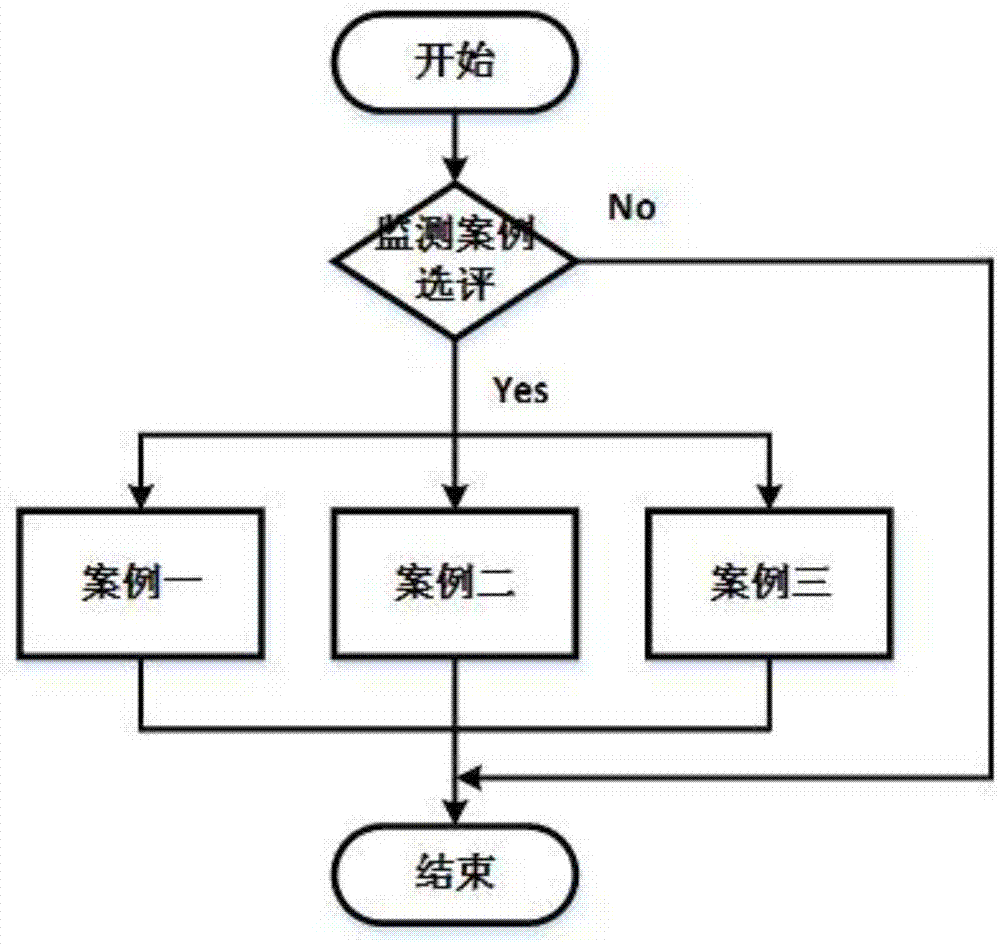
图1为本发明实施例的流程示意图。
图2为本发明实施例的监测案例选评模块的流程示意图。
图3为本发明实施例的网络云架构示意图。
图4为本发明实施例的适应值计算流程图。
图5为本发明实施例的传统型案例流程图。
图6为本发明实施例的小组分布型案例流程图。
图7为本发明实施例的人工智能辅助型案例流程图。
图8为判断矩阵标度定义表。
图9为极限超矩阵表。
图10为备选案例指标表。
图11教学方法适应值的拟合值表。
具体实施方式
下面结合附图对本发明实施例作进一步说明:
本发明实施例中,由监测案例选评模块根据教学实际状况的参数选出最适合的案例,三种教学案例(案例一、案例二和案例三)分别用a、b、c表示。系统框图如图1所示。
其中,案例一为传统型案例,指的是一人对多人教学结合一人与多人共同学习。一位老师以及全部n位学生,一位学生随机与同学共同学习m次,忽略不记授课的1次(n位),辅导学习n位学生m次,则最大时间复杂度o(n*m),平均时间复杂度o(n/2*m),意思是单个学生或是累计成果超过平均量,则代表过多的指导量。解决方式是老师需要再次全体授课一次或是需要有助教支持辅导学习。一对一的课后指导过程如图5所示。
案例二为小组分布型案例,指的是一人对多组教学结合各组共同学习。其中,已知每组有l位学生,一共n位学生。一位老师,共有n/l组的学生;各组学生随机与小组同学共同学习。若每组l位学生则这里用l次,略不记授课的1次(n/l组),群组互相学习l位学生l!次,全部群组互相学习的次数最多为n/l*l!=n*(l-1)!。所有组一半以上之间互相学习的次数为(1/2)*(n/l)*l!,每组组员一半以上互相学习的次数为(n/(l/2))*(l/2)!,每组组员一半以上和所有组一半以上的组合互相学习的次数为n/2*(l-1)!+n*(l/2-1)!。则最大时间复杂度为o(n*(l-1)!)。平均时间复杂度o((n/2)*(l-1)!+n*(l/2-1)!),意思是单组学生内部累计成果超过1/2量同时整体每组都学生内部累计成果超过1/2量,则代表过多的讨论量,解决方式是老师需要再次全体授课一次或是需要有助教支持辅导超过的各组。小组分布形式的课后指导过程如图6所示。
案例三为人工智能辅助型案例,指的是一人对多人教学结合一人与个人ai共同学习。其中,一位老师,n位学生;一位学生,随机与ai学习m次。忽略不记授课的1次(n位),每位学生经由m次人工智能的辅导学习。δ代表发生错误的临界次数。则最大时间复杂度为o(m)。只要发生错误超过δ次临界次数,则代表人工智能的指导存在异常,解决方式是老师需要再次全体授课一次或是需要有助教支持辅导学习并重建经验数据。如图7所示,该图显示某老师交由以人工智能助理的课后指导过程。在ai助理的辅助之下,其中i为不同科目与专长的人工智能助理,流程图内的外来数据,属于真实数据,来自于网络与社群讨论区的经验。所谓的内部数据,属于训练数据,来自于个人已往的经验,包含对的经验和错误的经验。δ为允许人工智能助理发生错误的临界次数。也就是说,倘若经由人工智能助理辅助学习后仍旧失败,则需要老师再次指导并且记忆成为内部数据,然后这部分学习重点将重新训练,提升成功率。
监测案例选评算法为结合anp与pso-rbf的决策算法,称为快速anp决策算法,其流程图如图2所示,
(1)首先对决策问题进行详细的描述,包括该决策问题的目标、准则和子目标,以及该决策问题的可能产出及其目标;
(2)网络由三部分组成。一部分是saas层,包括该决策问题的目标、准则;另一部分是paas层,包括该决策问题的子目标;还有一部分是iaas层,包括该决策问题的可能产出及其目标。paas层是根据saas层的准则建立的,并且反应了在paas层相应目标的准则下网内的元素或元素组是如何相互影响的;
(3)初始化群种n、初始的速度v和位置p;
(4)使用真实目标函数对元素在元素组,元素组在元素群的适应值评价,并存放到数据库内;
(5)确定元素历史最优值,得到元素在元素组中的适应值;
(6)确定元素组历史最优值,得到元素组在元素群的适应值;
(7)对于元素在元素组的适应值,元素组内部依赖适应值,元素组与元素组之间反馈关系适应值是否都求得,如果是则进行下一步,如果否则把还没有计算的适应值计算出;
(8)根据所得到的适应值数据建立适应值矩阵;
(9)求解适应值矩阵;
(10)对每一控制准则的极限向量按照各准则权重进行加总,主要是对个可选方案的权重加总;
(11)根据各可选方案的权重值排序,在采用bocr准则时,可根据不同的成本收益方法计算每个方案的成本收益,并排序;
(12)找出最佳方案。
图3所示为云架构下教学案例构建的anp网络结构,saas层中包含决策目标即教学案例选择,以及决策准则;paas层包含saas层中决策准则下的小准则;iaas层包含三种教学案例,各层数量的多少是云架构下anp网络结构弹性的表现。
对于群种n、速度v和位置p,如图3,anp网络结构中所示,n为3个群种(教学质量x1、教学经济成本x2、和教学安全性x3)。速度v在群种之间的速度若为1(教学质量x1→教学成本x2),群种内子准则的速度则为群种间的2倍(钟点课时费x21→总课时费x22),代表关系更密切。p指出每个群种内部,起点的初始位置(性别分班x11,总课时费x22,和学生家庭背景x33)。
在确定教学案例选择anp网络结构后,首先需要构建无权重超矩阵,即元素之间根据矩阵标度定义表,如图8,通过两两比较、归一化处理获得,然后依次构建多个判断矩阵,并对判断矩阵进行归一化处理,组成无权重超矩阵。其次在获得无权重超矩阵对元素组进行组间的比较,并依各准则进行元素组之间的比较,并将获得的各判断矩阵归一化,最后合并,再与无权重矩阵相乘,即可获得权重矩阵,依据该权重超矩阵可最终获得如图9所示的极限超矩阵。该极限超矩阵的各列相应数值相同,这是因为该anp网络是一个具有外部反馈且带有内部依赖关系的网络。
将0.0643、0.0611、0.0689这三个值进行归一化处理可得教学案例a优先权为0.3309、教学案例b优先权为0.3145、教学案例c优先权为0.3546。看出教学案例c的优先权最大,所以应先选择教学案例c。
具体个体适应值构建的流程图如图4所示,流程图说明如下步骤:
(1)初始化设定。设定pso-rbf神经网络的结构和粒子群的相关参数。确定rbf神经网络的层数,每一层神经元的个数,每层神经元之间的关系以及微粒群的维数,并且对粒子的速度和位置进行随机初始化;
(2)构建rbf代理模型并对x进行估值。在数据库中寻找距离个体i最近的位置d+2个,在d+2个位置中保留到个体i最近的一个位置,利用其它d+1个位置信息构建rbf代理模型并且利用rbf代理模型对x进行估值;
(3)个体适应度函数值与个体历史最优位置适应值相比较。使用rbf神经网络去估计新位置xi(t+1)最近已经实际计算过的位置x个体的适应值
(4)个体的新位置适应度函数值与个体历史最优位置适应值相比较。使用rbf神经网络去估计xi(t+1)的适应值
案例的参数包括:性别、人数、钟点课时费、学生血型、学生配合度、师生距离、总课时、学生家庭背景和学生年龄层。
以三种教学案例的钟点课时费最低教学授课标准1.0为标准,其他三种教学案例彼此之间以相对比值表示。学生配合度(潜在危险)以好、偏好、中等、偏差、差这五个指标评比;性别分班用男、女、和混班这三个指标评选;师生的距离乃是依照教与学的实际距离来区分,有远距离教学、中等(并存)、和近距离教学两种。班级的人数分成大班、中班、和小班。学生血型可以有a、b、o、ab。总课时可以有几种,高强度课时、一般课时和基本课时。学生家庭背景包含差(贫户)、中(小康)、好(高所得)。学生年龄层有幼儿园、小学、中学、高中、大学、研究所、研究所以上。所有相关指标见备选教学案例指标表,如图10所示。
根据备选教学案例指标表的数据运用图2个体的适应值计算步骤算出各个教学案例对各准则依次的适应值的拟合值如图11所示。再根据算法计算得案例a的优先权为0.2502;案例b的优先权为0.2384;案例c的优先权为0.2957。按照教学方法优先权越大越优先选择,由此可见,案例c是最先选择优先。
本方法根据备选案例指标表对学习过程指标化后,通过监测案例选评模块选出最适合学生课后学习的案例,并在不同案例下进行不同的复习方式、方法,因不同学生的不同学习情况对学生进行“因材施教”的课后指导,提高学习效果。
各位技术人员须知:虽然本发明已按照上述具体实施方式做了描述,但是本发明的发明思想并不仅限于此发明,任何运用本发明思想的改装,都将纳入本专利专利权保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!