重复文本的检测方法及装置与流程
本发明实施例涉及大数据分析技术领域,尤其涉及一种重复文本的检测方法及装置。
背景技术:
在互联网大规模普及的今天,各种资源呈爆炸式增长,越来越庞大的互联网促进了搜索引擎技术的不断发展,使它越来越成为人们从网络上获取信息的主要手段。但是,互联网上有大量的重复网页信息。为了提高搜索引擎提供的搜索结果的有效性,文本的重复检测就成为了互联网企业提高搜索引擎质量的关键技术。
在文本的重复检测技术中,一种十分常用的技术就是基于哈希算法而完成的。这种技术已经相当成熟,运行效率和鲁棒性都是能够满足搜索引擎目前的需要。当时,利用哈希算法完成的文本重复检测有一个缺点,就是在面对短文本的重复检测时,会出现运行效率不高的情况。
技术实现要素:
针对上述技术问题,本发明实施例提供了一种重复文本的检测方法及装置,以实现对短文本的有效的重复检测处理。
一方面,本发明实施例提供了一种重复文本的检测方法,所述方法包括:
获取待检测文本;
将所述待检测文本区分为短文本及长文本;
对所述短文本采用基于文本关联的重复检测;
对所述长文本采用基于局部敏感哈希算法的重复检测。
另一方面,本发明实施例还提供了一种重复文本的检测装置,所述装置包括:
文本获取模块,用于获取待检测文本;
文本区分模块,用于将所述待检测文本区分为短文本及长文本;
短文本检测模块,用于对所述短文本采用基于文本关联的重复检测;
长文本检测模块,用于对所述长文本采用基于局部敏感哈希算法的重复检测。
本发明实施例提供的重复文本的检测方法及装置,通过获取待检测文本,将所述待检测文本区分为短文本及长文本,对所述短文本采用基于文本关联的重复检测,对所述长文本采用基于局部敏感哈希算法的重复检测,实现了对短文本的有效的重复检测处理。
附图说明
通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1是本发明第一实施例提供的重复文本的检测方法的流程图;
图2是本发明第二实施例提供的重复文本的检测装置的结构图。
具体实施方式
下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。
第一实施例
本实施例提供了重复文本的检测方法的一种技术方案。
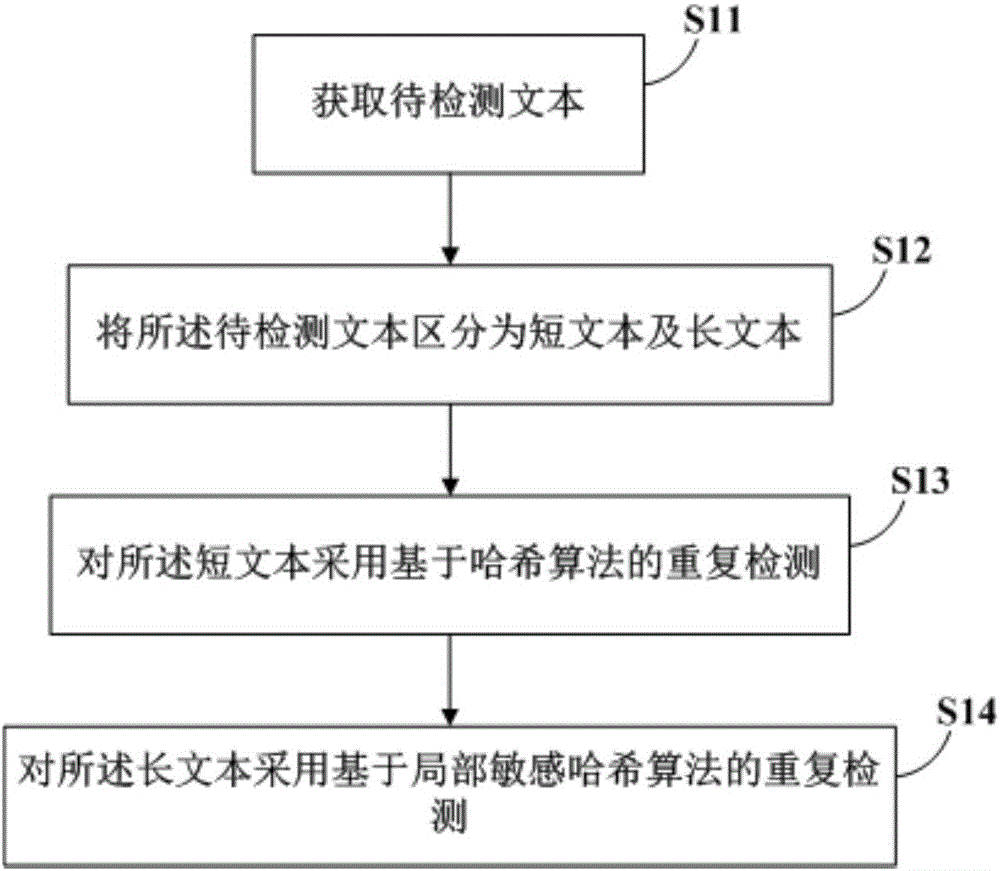
参见图1,重复文本的检测方法包括:
S11,获取待检测文本。
上述对待检测文本的获取可以是通过网络爬虫程序由互联网获取,也可以是从指定的语料数据库中获取。
如果通过上述获取手段获取到的待检测文本的正确性难以判断,则一般在获取到原始的待检测文本之后还需要对原始的文本进行一次数据清洗的操作。经过数据清洗之后,保留下来的待检测文本就是进行重复文本检测的原始语料。
S12,将所述待检测文本区分为短文本及长文本。
优选的,可以根据实际的检测需要预先构造对短文本及长文本进行区分的区分规则。在实际进行短文本及长文本区分时,应用上述规则。
更为优选的,可以预先设定一个区分短文本及长文本的文本长度阈值,当待检测文本的文本长度大于这个长度阈值时,待检测文本是长文本,而当待检测文本的文本长度小于或者这个等于这个长度阈值时,待检测文本是短文本。
需要理解的是,构建的区分规则可以不仅仅以上述列举的长度参数作为判定要素,还可以引入除文本长度以外的其他参数作为判定要素。比如,可以将文本内容作为上述区分规则中的判定要素之一。
另外,还可以以预先构建的分类器完成对短文本及长文本的区分。如果以分类器完成长短文本的区分,则分类器的输入参数可以有多种。比如,分类器的输入参数可以包括:文本长度、特征语段等。
S13,对所述短文本采用基于文本关联的重复检测。
由于对待检测的短文本直接应用哈希算法,会出现运行效率不高的情况,在本实施例中,采用首先将待检测的短文本关联至一个长文本,再根据对长文本应用哈希算法的重复检测结果,判断待检测的短文本是否出现了重复。
上述文本关联是指对同一主题的文本进行关联。例如,微博的主帖和该主帖所有的回帖可以关联;或者论坛的主帖和该主帖所有的回帖可以关联到一起。然后对同一主题的短文本,通过hash算法进行重复性检测。
采用上述的方式实现对短文本的重复检测,不仅克服了在短文本上直接应用哈希算法而造成的运行效率问题,而且重复检测的准确性也十分有保障。
S14,对所述长文本采用基于局部敏感哈希算法的重复检测。
遇到待检测文本是长文本的情况时,采用局部敏感哈希(Local sensitive hash,LSH)算法对待检测文本进行重复检测。上述局部敏感哈希算法包括:MinHash算法,或者SimHash算法。具体的,对长文本的重复检测可以是:基于MinHash算法,或者SIMHash算法生成长文本的文件指纹,并基于所述文件指纹进行重复检测。
本实施例通过获取待检测文本,将所述待检测文本区分为短文本及长文本,对所述短文本采用基于文本关联的重复检测,以及对所述长文本采用基于局部敏感哈希算法的重复检测,实现了对短文本的有效的重复检测处理。
第二实施例
本实施例提供了重复文本的检测装置的一种技术方案。在该技术方案中,所述重复文本的检测装置包括:文本获取模块21、文本区分模块22、短文本检测模块23,以及长文本检测模块24。
所述文本获取模块21用于获取待检测文本。
所述文本区分模块22用于将所述待检测文本区分为短文本及长文本。
所述短文本检测模块23用于对所述短文本采用基于文本关联的重复检测。
所述长文本检测模块24用于对所述长文本采用基于局部敏感哈希算法的重复检测。
进一步的,所述文本区分模块22具体用于:基于规则或者分类器,将所述待检测文本区分为短文本及长文本。
进一步的,所述短文本检测模块23包括:文本关联单元,以及检测单元。
所述文本关联单元用于对所述短文本进行短文本关联。
所述检测单元用于对关联后的文本进行基于哈希算法的重复检测。
进一步的,所述长文本检测模块24具体用于:采用局部敏感哈希算法生成所述长文本的文件指纹,并基于所述文件指纹进行重复检测。
进一步的,所述局部敏感哈希算法包括:MinHash算法,以及S imHash算法。
本领域普通技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个计算装置上,或者分布在多个计算装置所组成的网络上,可选地,他们可以用计算机装置可执行的程序代码来实现,从而可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件的结合。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!