意图理解装置以及方法与流程
本发明涉及根据语音识别结果估计用户的意图的意图理解装置以及其方法。
背景技术:
近年来,使用人们说的语言的语音识别结果来执行装置的操作的技术受到关注。该技术被用作移动电话、导航装置等的语音接口。作为现有的基本方法,具有以下这样的方法:例如装置预先存储假定的语音识别结果与操作的对应关系,当用户发出的语音的识别结果是假定的内容时,执行与该识别结果对应的操作。
该方法与用户手动操作的情况相比,可通过语音的发声进行直接操作,因此,作为快捷功能有效地发挥作用。另一方面,用户为了执行操作,需要发出装置等待的语言,当装置处理的功能增加时,用户不得不预先记住的语言增加。另外,一般情况下,在充分理解使用说明书后使用装置的用户较少,所以,没有理解的用户不知道为了进行操作要说什么,所以,还具有这样的问题:实际上,除了记住的功能的指令以外,无法利用语音进行操作。
因此,作为改良上述问题的技术,提出了以下这样的方法:即使用户没有记住用于达成目的的指令,装置也通过对话来引导用户达成目的。作为其实现的方法的一个重要技术,例如在专利文献1中公开了根据用户的发话来正确地估计该用户的意图的技术。
专利文献1的语音处理装置按照分别表示多个意图的多个意图信息,具有语言的词典数据库以及文法数据库,还将此前执行的指令的信息作为事先分数进行保持。该语音处理装置按照多个意图信息来计算音响分数、语言分数以及事先分数,作为表示根据用户发话而输入的语音信号相对于意图信息的一致度的分数,选择综合这些分数而获得的综合分数最大的意图信息。此外,还公开了以下的情况:语音处理装置根据综合分数来执行所选择的意图信息,在用户确认后执行或放弃。
但是,在专利文献1中,所定义的意图是“请告诉天气”、“请告诉时间”这种形式的唯一决定的意图,没有提及例如假定了包含在导航装置的终点设定中所需的多用的设施名这样的意图的处理。
现有技术文献
专利文献
专利文献1:日本特开2011-33680号公报
技术实现要素:
发明要解决的课题
在上述专利文献1的语音处理装置中,因为按照意图来设计语音识别结果,所以,仅仅是从多个不同的意图中进行选择、以及判定最终选择的意图信息的执行和放弃,不处理语音识别结果的次级候选。
例如,在用户听音乐的状态下作出“不听音乐”这样的发话的情况下,当“想听音乐”这样的第1候选和“不听音乐”这样的第2候选的意图作为结果求出时,选择第1候选的“想听音乐”。
此外,在导航装置的终点已经设定了“○○中心”的状态下用户为了追加途经地而作出“停在○×中心”这样的发话的结果是,在“停在○○中心”是第1候选的意图、“停在○×中心”是第2候选的意图的情况下也会选择第1候选的“停在○○中心”。
这样,具有以下这样的课题:因为现有装置不处理次级候选,所以,难以正确地理解用户的意图。其结果是,用户必须取消所选择的第1候选,再次作出发话。
本发明是为了解决上述这样的课题而完成的,其目的是提供利用输入语音来正确地理解用户的意图的意图理解装置以及方法。
解决问题的手段
本发明的意图理解装置具备:语音识别部,其识别用户用自然语言发出的一个语音,生成多个语音识别结果;词素分析部,其将语音识别结果分别转换为词素串;意图理解部,其根据词素串估计用户的发话的意图,从一个词素串中输出一个以上的意图理解结果候选和表示可能性的程度的分数;权重计算部,其计算每个意图理解结果候选的权重;以及意图理解校正部,其使用权重校正意图理解结果候选的分数,算出最终分数,根据该最终分数从意图理解结果候选中选择意图理解结果。
本发明的意图理解方法包括以下的步骤:语音识别步骤,识别用户用自然语言发出的一个语音,生成多个语音识别结果;词素分析步骤,将语音识别结果分别转换为词素串;意图理解步骤,根据词素串估计用户的发话的意图,从一个词素串中输出一个以上的意图理解结果候选和表示可能性的程度的分数;权重计算步骤,计算每个意图理解结果候选的权重;以及意图理解校正步骤,使用权重校正意图理解结果候选的分数来算出最终分数,根据该最终分数从所述意图理解结果候选中选择意图理解结果。
发明效果
根据本发明,根据一个语音生成多个语音识别结果,从语音识别结果分别生成意图理解结果候选,使用权重来校正意图理解结果候选的分数,算出最终分数,根据该最终分数从多个意图理解结果候选中选择意图理解结果,所以,能够从不仅包含与输入语音相对的语音识别结果的第1候选还包含次级候选的候选中选择最终的意图理解结果。因此,能够提供可正确地理解用户意图的意图理解装置。
根据本发明,根据一个语音生成多个语音识别结果,根据语音识别结果分别生成意图理解结果候选,使用权重来校正意图理解结果候选的分数,算出最终分数,根据该最终分数从多个意图理解结果候选中选择意图理解结果,所以,能够从不仅包含与输入语音相对的语音识别结果的第1候选还包含次级候选的候选中选择最终的意图理解结果。因此,能够提供可正确地理解用户意图的意图理解方法。
附图说明
图1是示出本发明的实施方式1的意图理解装置的结构的框图。
图2是示出将实施方式1的意图理解装置作为语音接口组装的导航装置的结构的框图。
图3是说明实施方式1的意图理解装置的动作的图,图3的(a)是设定信息的例子,图3的(b)是对话的例子。
图4是示出实施方式1的意图理解装置的各部的输出结果的图,图4的(a)是语音识别结果的例子,图4的(a)~图4的(d)是与语音识别结果1位~3位相对的意图理解结果候选等的例子。
图5是定义了实施方式1的意图理解装置的权重计算部所使用的制约条件与等待权重的对应关系的表。
图6是示出实施方式1的意图理解装置的动作的流程图。
图7是示出本发明的实施方式2的意图理解装置的结构的框图。
图8是说明实施方式2的意图理解装置的动作的图,示出对话的例子。
图9是示出实施方式2的意图理解装置的各部的输出结果的图,图9的(a)是语音识别结果的例子,图9的(b)~图9的(d)是与语音识别结果1位~3位相对的意图理解结果候选等的例子。
图10是示出实施方式2的意图理解装置的层次树的例子的图。
图11是图10的层次树的各节点的意图的列表。
图12是示出实施方式2的意图理解装置的权重计算部计算的等待权重的例子的图。
图13是示出实施方式2的意图理解装置的动作的流程图。
图14是示出图13的步骤ST20的具体动作的流程图。
图15是示出本发明的实施方式3的意图理解装置的结构的框图。
图16是示出实施方式3的意图理解装置的关键字表的例子的图。
图17是示出实施方式3的意图理解装置的关键字对应意图的例子的图。
图18是示出实施方式3的意图理解装置的各个部的输出结果的图,图18的(a)是语音识别结果的例子,图18的(b)~图18的(d)是与语音识别结果第1位~第3位相对的意图理解结果候选等的例子。
图19是示出实施方式3的意图理解装置的动作的流程图。
图20是示出图19的步骤ST31的具体动作的流程图。
图21是示出本发明的意图理解装置的变形例的框图。
图22是说明本发明的意图理解装置的动作的图,示出对话的例子。
具体实施方式
以下,为了更详细地说明本发明,根据附图说明用于实施本发明的方式。
实施方式1.
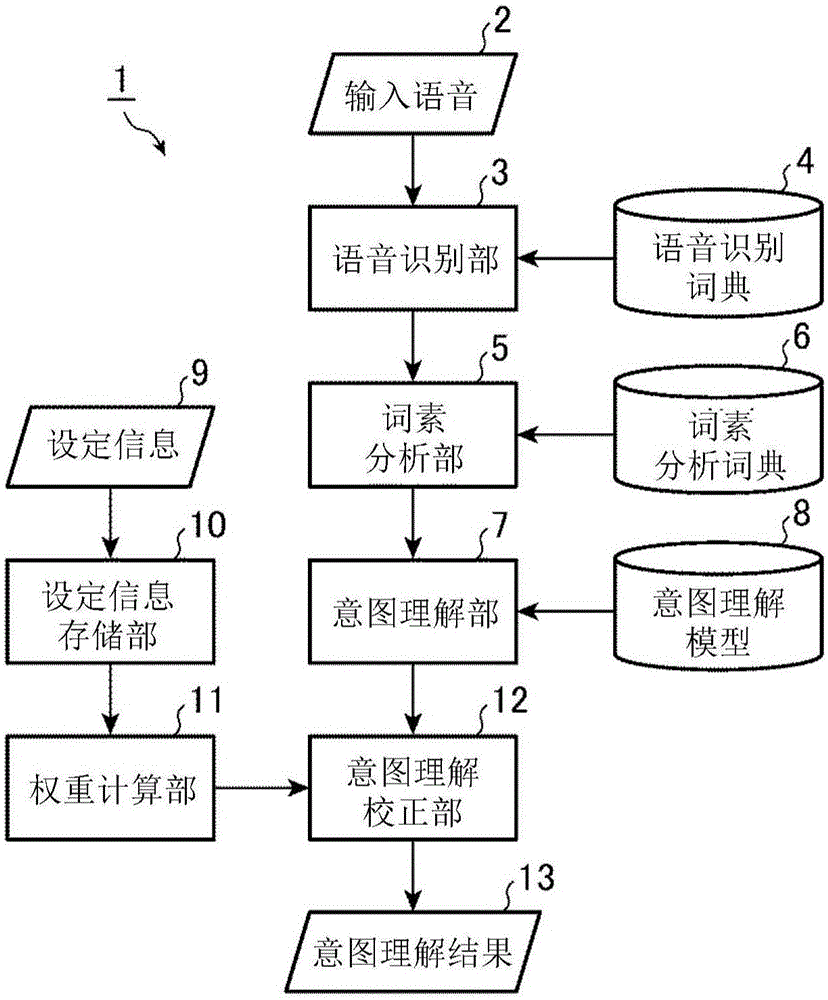
如图1所示,本发明的实施方式1的意图理解装置1具备:语音识别部3,其对用户发出的输入语音2进行语音识别,转换为文本;语音识别部3在语音识别中使用的语音识别词典4;词素分析部5,其将语音识别结果分解为词素;词素分析部5在词素分析中使用的词素分析词典6;意图理解部7,其根据词素分析结果生成意图理解结果的候选;用于供意图理解部7估计用户的意图的意图理解模型8;设定信息存储部10,其存储控制对象设备的设定信息9;权重计算部11,其使用设定信息存储部10的设定信息9计算权重;以及意图理解校正部12,其使用权重来校正意图理解结果的候选,从中选择最终的意图理解结果13并输出。
意图理解装置1由未图示的CPU(Central Processing Unit)构成,该CPU通过执行内部存储器存储的程序,实现作为语音识别部3、词素分析部5、意图理解部7、权重计算部11以及意图理解校正部12的功能。
语音识别词典4、词素分析词典6、意图理解模型8以及设定信息存储部10由HDD(Hard Disk Drive)、DVD(Digital Versatile Disc)、存储器等构成。
图2是示出将意图理解装置1作为语音接口组装的导航装置100的结构的框图。该导航装置100是基于语音的控制对象。语音输入部101由麦克风等构成,将用户发出的语音转换为信号,将其作为输入语音2输出至意图理解装置1。导航控制部102由CPU等构成,执行从当前地到终点的路径的搜索以及引导等功能。终点等的设定信息9从导航控制部102输出至意图理解装置1。另外,该导航控制部102从意图理解装置1接收意图理解结果13,执行意图理解结果13所示的操作,或者将关于意图理解结果13的语音信号输出到语音输出部103。语音输出部103由扬声器等构成,再现从导航控制部102输入的语音信号。
此外,可以使用不同的CPU构成意图理解装置1和导航控制部102,也可以使用1个CPU构成意图理解装置1和导航控制部102。
例如,以“<主意图>[<槽名>=<槽值>、···]”这样的形式来表现意图。具体地说,以“终点设定[设施=?]”以及“终点设定[设施=$设施$(=○○店)]”这样的方式表现。“终点设定[设施=?]”表示这样的状态:虽然用户希望设定终点,但尚未决定具体的设施名。“终点设定[设施=$设施$(=○○店)]”表示这样的状态:用户将“○○店”这样的具体设施设定为终点。
作为意图理解部7进行的意图理解方法,例如可利用最大熵法等方法。具体地说,意图理解模型8大量地保持“终点、设定”这样的独立单词(以下,称为特征)与“终点设定[设施=?]”这样的正确意图的组。意图理解部7例如从“希望设定终点”这样的输入语音2的词素分析结果中提取“终点、设定”这样的特征,利用统计的方法从意图理解模型8中估计哪个意图有多大的可能性。意图理解部7输出意图与表示该意图的可能性的分数的组的列表作为意图理解结果的候选。
以下,说明意图理解部7执行利用最大熵法的意图理解方法的情况。
图3的(a)是实施方式1中的设定信息9的例子,图3的(b)是对话的例子。
在基于语音的控制对象是导航装置100的情况下,在设定信息9中包含有无终点以及经由地的设定,在进行了设定的情况下包含该终点或经由地的名称,此外还包含所显示的地图的类型等信息。意图理解装置1的设定信息存储部10存储导航装置100的导航控制部102所输出的设定信息9。在图3的(a)的例子中,在设定信息9中包含“终点:△△”和“经由地:○○”的信息。
图3的(b)表示在导航装置100与用户之间从上依次进行对话的情况。在对话内容中,各行的行头的“U:”表示用户发出的输入语音2,“S:”表示来自导航装置100的应答。
图4是意图理解装置1的各部的输出结果的例子。
图4的(a)表示语音识别部3所输出的语音识别结果的例子。语音识别结果是“○○是目的地”这样的语音识别结果与表示该语音识别结果的可能性的似然度的组的列表,按照似然度从高到低的顺序排列。
图4的(b)是与图4的(a)的语音识别结果中的第1位的语音识别结果“○○是目的地”相对的意图理解结果候选、分数、等待权重以及最终分数,图4的(c)与第2位的语音识别结果“不去○○”相对,图4的(d)与第3位的语音识别结果“寻找○△”相对。意图理解部7输出“经由地设定[设施=$设施$]”这样的意图与分数的组的列表作为意图理解结果的候选。这些意图理解结果候选按照分数从高到低的顺序排列。权重计算部11按照意图理解部7输出的每个意图理解结果候选,计算等待权重。意图理解校正部12按照意图理解部7所输出的每个意图理解结果候选,使用等待权重计算最终分数。
图5是定义了制约条件与等待权重的对应关系的表。
例如,可认为在导航装置100的终点已被设定为“△△”的情况下,用户在下一次发话时再一次进行“将终点设定为△△”这样的意图的发话的可能性较低。由此,针对此制约条件,将意图“终点设定[设施=$设施$(=△△)]”的等待权重设定为“0.0”。另一方面,因为存在用户将终点变更为“?”(△△以外的场所)的可能性,所以,将意图“终点设定[设施=设施=$设施$(=?)]”的等待权重设定为“1.0”。另外,因为用户进行将与终点相同的“○○”设定为经由地的意图的发话的可能性较低,所以,将意图“经由地设定[设施=$设施$(=○○)]”的等待权重设定为“0.0”。此外,因为有时用户删除已经设定的经由地“○○”,所以,将意图“删除经由地[设施=$设施$(=○○)]”的等待权重设定为“1.0”。
权重计算部11保持如上所述地根据产生意图的可能性而事先定义的等待权重的信息,根据设定信息9选择与意图对应的等待权重。
意图理解校正部12使用以下的式(1),校正意图理解部7的意图理解结果的候选。具体地说,意图理解校正部12对从语音识别部3获得的语音识别结果的似然度与从意图理解部7获得的意图理解结果候选的意图理解分数进行乘法计算,来计算分数(相当于图4的(b)等所示的“分数”),对该分数与从权重计算部11获得的等待权重进行乘法运算,获得最终分数(相当于图4的(b)等所示的“最终分数”)。在本实施方式1中,如式(1)那样进行利用乘法运算的意图理解校正,但不限于该方法。
(似然度)×(意图理解分数)=(分数)
(分数)×(等待权重)=(最终分数)
···(1)
接着,参照图6的流程图,来说明意图理解装置1的动作。
这里,意图理解装置1被组装到作为控制对象的导航装置100,当用户按下未明示的对话开始按钮时,开始对话。另外,假设在设定信息存储部10中存储有图3的(a)所示的设定信息9,针对图3的(b)的对话内容进行意图理解过程的详细说明。
在检测到用户已按下导航装置100的对话开始按钮时,导航控制部102以语音的形式从语音输出部103输出提示对话开始的应答“发出哔的声音后,请说话”,继续使蜂鸣声鸣叫。另外,意图理解装置1使语音识别部3成为可识别的状态,成为等待用户发话的状态。
接着,如图3的(b)那样,当用户发出“不去○○”时,语音输入部101将该发话转换为语音数据,并输出至意图理解装置1的语音识别部3。意图理解装置1的语音识别部3使用语音识别词典4将输入语音2转换为文本,并且算出似然度,输出至词素分析部5(步骤ST11)。
接着,词素分析部5使用词素分析词典6,对语音识别结果进行词素分析,输出至意图理解部7(步骤ST12)。例如,语音识别结果“○○是目的地”的词素分析结果为“○○/名词、は/助词、目的地/名词、で/助词”。
接着,意图理解部7使用意图理解模型8,根据词素分析结果估计意图,并且算出分数,作为意图理解结果候选输出至意图理解校正部12(步骤ST13)。此时,意图理解部7从词素分析结果中提取使用于意图理解的特征,将该特征与意图理解模型8进行对照来估计意图。从图4的(a)的语音识别结果“○○是目的地”的词素分析结果中,提取“○○、目的地”这样的特征的列表,并获得图4的(b)的意图理解结果候选“经由地设定[设施=$设施$(=○○)]”及其分数“0.623”以及意图理解结果候选“设施检索[设施=$设施$(=○○)]”及其分数“0.286”。
然后,权重计算部11从设定信息存储部10中读入设定信息9,根据该设定信息9和图5所示的表来选择每个意图的等待权重,输出至意图理解校正部12(步骤ST14)。
接着,意图理解校正部12使用语音识别部3所计算的语音识别结果的似然度、意图理解部7计算的意图理解结果候选的分数和权重计算部11选择的等待权重,根据上式(1)来算出意图理解结果候选的最终分数(步骤ST15)。此时,意图理解校正部12按照语音识别结果的似然度从上位到下位的顺序且同一语音识别结果中的意图理解结果候选的分数从上位到下位的顺序,计算最终分数,每次计算都评价其最终分数。意图理解校正部12例如在发现最终分数X=0.5以上的意图理解结果候选的时刻,使该意图理解结果候选成为最终的意图理解结果13。
在图4的例子中,关于与输入语音2“不去○○”相对的第1位的语音识别结果“○○是目的地”,图4的(b)的意图理解结果候选第1位“经由地设定[设施=$设施$(=○○)]”的最终分数为“0.0”,第2位“设施检索[设施=$设施$(=○○)]”的最终分数为“0.286”,任意的意图理解结果候选都不满足最终分数是X以上的条件(步骤ST16“否”)。
因此,意图理解装置1针对第2位的语音识别结果“不去○○”反复进行步骤ST12~ST15的处理,其结果是,获得图4的(c)的意图理解结果候选第1位“经由地删除[设施=$设施$(=○○)]”的最终分数“0.589”和第2位“设施检索[设施=$设施$(=○○)]”的最终分数“0.232”。因为语音识别结果第2位且意图理解结果候选第1位的“经由地删除[设施=$设施$(=○○)]”的最终分数“0.589”满足X以上(步骤ST16“是”),所以,在此时刻,意图理解校正部12将“经由地删除[设施=$设施$(=○○)]”作为最终的意图理解结果13返回导航控制部102,结束处理。
导航控制部102在从意图理解装置1接收到意图理解结果13的“经由地删除[设施=$设施$(=○○)]”时,对语音输出部103进行指示,如图3的(b)那样以语音的形式输出“删除经由地○○。可以吗?”。在用户对其发出“是”的情况下,意图理解装置1通过语音输入部101受理该发出的输入语音2,判断为正确地进行了语音识别以及意图理解。另外,意图理解装置1针对“是”的输入语音2进行语音识别以及意图理解,将意图理解结果13输出至导航控制部102。导航控制部102根据该意图理解结果13,执行删除经由地“○○”的操作。
由此,在导航控制部102中,执行“经由地删除[设施=$设施$(=○○)]”,而不是具有语音识别结果的最大似然度以及意图理解结果的最大分数的“经由地设定[设施=$设施$(=○○)]”,能够排除误识别的影响。
以上,根据实施方式1,意图理解装置1构成为具备:语音识别部3,其识别用户以自然语言发出的一个输入语音2,生成多个语音识别结果;词素分析部5,其将语音识别结果分别转换为词素串;意图理解部7,其根据词素串估计用户发话的意图,从一个词素串输出一个以上的意图理解结果候选和分数;权重计算部11,其计算每个意图理解结果候选的等待权重;以及意图理解校正部12,其使用等待权重校正意图理解结果候选的分数,算出最终分数,根据该最终分数从意图理解结果候选中选择意图理解结果13。因此,可以从不仅包含与输入语音2相对的第1位的语音识别结果、还包含第2位以后的语音识别结果的结果中选择最终的意图理解结果13。因此,能够提供可正确地理解用户的意图的意图理解装置1。
另外,根据实施方式1,意图理解部7从多个语音识别结果中的具有可能性的语音识别结果依次生成意图理解结果候选,意图理解校正部12构成为,每当意图理解部7生成意图理解结果候选时,算出最终分数,选择该最终分数满足预先设定的条件X的意图理解结果候选作为意图理解结果13。因此,能够抑制意图理解装置1的运算量。
另外,根据实施方式1,权重计算部11构成为,使用根据意图理解校正部12所选择的意图理解结果13而工作的控制对象设备(例如,导航装置100)的设定信息9,计算等待权重。具体地说,权重计算部11构成为,具有对制约条件和满足该制约条件时的等待权重进行定义的图5这样的表,根据设定信息9来判断是否满足制约条件,选择等待权重。因此,能够估计与控制对象设备的状况相应的确切意图。
实施方式2.
图7是示出实施方式2的意图理解装置20的结构的框图。在图7中对与图1相同或相当的部分标注相同的符号,并省略说明。该意图理解装置20具备:层级地表现意图的层次树21;以及根据层次树21的意图中的已激活的意图来计算等待权重的权重计算部22。
图8是实施方式2中的对话的例子。与图3的(b)相同,行头的“U:”表示用户发话,“S:”表示来自控制对象的装置(例如,图2所示的导航装置100)的应答。
图9是意图理解装置1的各部的输出结果的例子。图9的(a)是语音识别部3输出的语音识别结果及其似然度。图9的(b)~图9的(d)是意图理解部7输出的意图理解结果的候选及其分数、权重计算部22所输出的等待权重以及意图理解校正部12输出的最终分数。图9的(b)示出图9的(a)的第1位的语音识别结果“不去○○”的意图理解结果候选,图9的(c)示出第2位的语音识别结果“经由○○”的意图理解结果候选,图9的(d)示出第3位的语音识别结果“把○○作为目的地”的意图理解结果候选。
图10以及图11是层次树21的例子。如图10所示,在层次树21中,表示意图的节点是层级构造,越到根(上的层级)部,则越成为表示抽象意图的节点,越到叶(下的层级)部,则越成为表示具体意图的节点。例如,当比较第3层级的节点#9的“终点设定[设施=?]”与第4层级的节点#16的“目的设定[设施=$设施$(=○○店)]”这两个意图时,在上位的层级存在表示更抽象的意图的节点#9,表示填充了具体的槽值(例如,○○店)的意图的节点#16位于其下方。
位于第1层级的节点#1的意图“导航”是表示导航控制部102的导航功能的集合的抽象节点,表示个别的导航功能的节点#2~#5位于其下方的第2层级。例如,节点#4的意图“终点设定[]”表示这样的状态:虽然用户希望设定终点,但尚未决定具体的场所。当成为已设定终点的状态时,从节点#4转移到节点#9或节点#16。在图10的例子中示出根据图8所示的“设定目的地”这样的用户的发话激活了节点#4的状态。
层次树21根据导航装置100所输出的信息,激活意图节点。
图12是权重计算部22计算出的等待权重的例子。
根据“设定目的地”这样的用户发话,层次树21的节点#4的意图“终点设定[]”已被激活,所以,节点#4的枝叶方向的节点#9、#10的意图的等待权重成为1.0,其它意图节点的等待权重成为0.5。
后面叙述权重计算部22的等待权重的计算方法。
图13是示出意图理解装置20的动作的流程图。图13的步骤ST11~ST13、ST15、ST16与图6的步骤ST11~ST13、ST15、ST16的处理相同。
在步骤ST20中,权重计算部22参照层次树21,计算意图理解部7的意图理解结果候选的等待权重,输出至意图理解校正部12。
图14是示出图13的步骤ST20的具体动作的流程图。在步骤ST21中,权重计算部22对意图理解部7的意图理解结果候选与层次树21的被激活的意图进行比较。在意图理解部7的意图理解结果候选位于层次树21的被激活的意图的枝叶方向时(步骤ST22“是”),权重计算部22将等待权重设为第1权重a(步骤ST23)。另一方面,在意图理解部7的意图理解结果候选位于层次树21的被激活的意图的枝叶方向以外时(步骤ST22“否”),权重计算部22将等待权重设为第2权重b(步骤ST24)。在本实施方式2中,a=1、0,b=0.5。另外,在不存在被激活的意图节点时,使等待权重成为1.0。
接着,说明意图理解装置20的动作。
意图理解装置20的动作基本上与上述实施方式1的意图理解装置1的动作相同。本实施方式2与上述实施方式1的区别是等待权重的计算方法。
以下,关于图8所示的对话内容,详细地说明意图理解过程。与上述实施方式1相同,假定在作为控制对象的导航装置100(图2所示)中组装了意图理解装置20的情况。另外,当由用户按下未图示的发话开始按钮时,开始对话。在图8的最初的用户发话“设定目的地”的时刻,导航装置100没有取得任何来自用户的信息,所以,是在意图理解装置20的层次树21上不存在激活的意图节点的状态。
此外,层次树21根据意图理解校正部12所输出的意图理解结果13激活意图节点。
在对话开始后,当用户发出“设定目的地”时,该发话的输入语音2被输入到意图理解装置20。该输入语音2被语音识别部3识别(步骤ST11),被词素分析部5分解为词素(步骤ST12),意图理解部7算出意图理解结果候选(步骤ST13)。这里,假设对用户发话“设定目的地”正确地进行了识别而没有误识别、正确地理解了其意图,意图理解校正部12获得“终点设定[]”的意图理解结果13。导航控制部102为了使设定为终点的设施具体化,对语音输出部103进行指示,以语音的形式输出“设定终点。请说出场所”。另外,层次树21激活与意图理解结果13的“终点设定[]”相应的节点#4。
导航装置100进行了提示下一发话的应答,所以,继续与用户的对话,如图8那样,用户发出“把○○作为目的地”。意图理解装置20对该用户发话“把○○作为目的地”进行步骤ST11、ST12的处理。其结果,获得图9的(a)的语音识别结果“不去○○”、“经由○○”、“把○○作为目的地”的各个词素分析结果。接着,意图理解部7根据词素分析结果估计意图(步骤ST13)。这里,假设意图理解结果的候选成为图9的(b)的“经由地删除[设施=$设施$(=○○)]”和“终点设定[设施=$设施$(=○○)]”。
接着,权重计算部22参照层次树21计算等待权重(步骤ST20)。在此时刻,层次树21的节点#4为激活状态,权重计算部22根据此状态计算权重。
首先,在步骤ST21中,将激活的节点#4的信息从层次树21传递到权重计算部22,并且将意图理解结果候选“经由地删除[设施=$设施$(=○○)]”和“终点设定[设施=$设施$(=○○)]”从意图理解部7传递到权重计算部22。权重计算部22比较已激活的节点#4的意图和意图理解结果候选,在意图理解结果候选位于激活节点#4的枝叶方向(即,节点#9以及节点#10)的情况下(步骤ST22“是”),将等待权重设为第1权重a(步骤ST23)。另一方面,在意图理解结果候选位于激活节点#4的枝叶方向以外的情况下(步骤ST22“否”),权重计算部22将等待权重设为第2权重b(步骤ST24)。
第1权重a为大于第2权重b的值。例如,在a=1.0、b=0.5的情况下,等待权重如图9的(b)所示。
接着,意图理解校正部12使用语音识别部3计算的语音识别结果的似然度、意图理解部7计算的意图理解结果候选的分数和权重计算部22计算的等待权重,根据上式(1)算出意图理解结果候选的最终分数(步骤ST15)。最终分数如图9的(b)所示。
接着,意图理解校正部12与上述实施方式1同样地判定最终分数是否满足条件X以上(步骤ST16)。这里,如果也把X=0.5作为条件,则与语音识别结果第1位“不去○○”相对的图9的(b)的意图理解结果候选“经由地删除[设施=$设施$(=○○)]”的最终分数“0.314”和“终点设定[设施=$设施$(=○○)]”的最终分数“0.127”都不满足条件。
因此,意图理解装置20针对语音识别结果第2位的“经由○○”反复进行步骤ST12~ST14、ST20、ST15的处理。其结果是,如图9的(c)那样求出意图理解结果候选“经由地删除[设施=$设施$(=○○)]”的最终分数“0.295”和“设施检索[设施=$设施$(=○○)]”的最终分数“0.116”,但这些也不满足X以上的条件。
因此,意图理解装置20针对语音识别结果第3位的“把○○作为目的地”反复进行步骤ST12、ST13、ST20、ST15的处理,其结果是,如图9的(d)那样求出意图理解结果候选“终点设定[设施=$设施$(=○○)]”的最终分数“0.538”。因为该最终分数满足X以上的条件,所以,意图理解校正部12将“终点设定[设施=$设施$(=○○)]”作为最终的意图理解结果13输出。层次树21根据意图理解结果13激活节点#16。
导航控制部102在从意图理解装置20接收到意图理解结果13的“终点设定[设施=$设施$(=○○)]”时,对语音输出部103进行指示,如图8那样,以语音的形式输出“将○○设定为终点。可以吗?”。在用户对此发出“是”的情况下,意图理解装置20通过语音输入部101受理该发话的输入语音2,判断为正确地进行了语音识别以及意图理解。另外,意图理解装置20对“是”的输入语音2进行语音识别以及意图理解,将意图理解结果13输出至导航控制部102。导航控制部102根据该意图理解结果13将“○○”设定为终点,从语音输出部103以语音的形式输出“已经把○○作为终点”,向用户通知已进行终点设定。
以上,根据实施方式2,权重计算部22构成为,以使得意图理解校正部12容易地选择出符合根据与用户的对话的流程而期待的意图的意图理解结果候选的方式进行加权。因此,能够估计与用户和控制对象设备的对话状况相应的确切意图。
另外,根据实施方式2,意图理解装置20具备层次树21,该层次树21使用越到根部则越成为抽象意图、越到叶部则越成为具体意图的树结构表现用户的意图,权重计算部22根据层次树21,以容易选择出相对于与刚刚选择的意图理解结果13对应的意图位于枝叶方向的意图理解结果候选的方式进行加权。这样,可通过利用意图的层次性校正与用户发话相对的意图,使控制对象设备根据确切的语音识别结果以及意图理解结果进行动作。
实施方式3.
图15是示出实施方式3的意图理解装置30的结构的框图。在图15中对与图1以及图5相同或相当的部分标注相同的符号并省略说明。该意图理解装置30具备:关键字表31,其存储与意图对应的关键字;关键字检索部32,其从关键字表31中检索与词素分析结果对应的意图;以及权重计算部33,其使对应于关键字的意图与层次树21的激活的意图进行比较,计算等待权重。
图16是关键字表31的一例。关键字表31存储意图与关键字的组。例如,针对意图“终点设定[]”,赋予“目的地”、“去”、“终点”等成为意图的特征表现的关键字。对除了层次树21的第1层级的节点#1之外的第2层级以下的各节点的意图赋予关键字。
以下,将与关键字对应的意图称为关键字对应意图。另外,将与层次树21的激活的意图节点对应的意图称为层次树对应意图。
图17是语音识别部3输出的语音识别结果、语音识别结果所包含的关键字、关键字检索部32检索到的关键字对应意图的例子。与语音识别结果“不去○○”的关键字“不去”对应的关键字对应意图为“经由地删除[]”,与语音识别结果“经由○○”的关键字“经由”对应的关键字对应意图为“经由地设定[]”,与语音识别结果“把○○作为目的地”的关键字“目的地”对应的关键字对应意图为“终点设定[]”。
图18的(a)是语音识别部3输出的语音识别结果及其似然度的例子。图18的(b)~图18的(d)是意图理解部7输出的意图理解结果候选及其分数、权重计算部33输出的等待权重以及意图理解校正部12输出的最终分数。图18的(b)示出图18的(a)的第1位的语音识别结果“不去○○”的意图理解结果候选,图18的(c)示出第2位的语音识别结果“经由○○”的意图理解结果候选,图18的(d)示出第3位的语音识别结果“把○○作为目的地”的意图理解结果候选。
图19是示出意图理解装置30的动作的流程图。图19的步骤ST11~ST13、ST15、ST16与图6的步骤ST11~ST13、ST15、ST16的处理相同。
在步骤ST30中,关键字检索部32从关键字表31中检索与词素分析结果对应的关键字,取得与检索的关键字对应的关键字对应意图。关键字检索部32向权重计算部33输出所取得的关键字对应意图。
图20是示出图19的步骤ST31的具体动作的流程图。在步骤ST32中,权重计算部33对意图理解部7的意图理解结果候选、层次树21的激活的层次树对应意图、关键字检索部32的关键字对应意图进行比较。在意图理解结果候选与关键字对应意图、层次树对应意图都不一致的情况下(步骤ST32“否”),权重计算部33将等待权重设为第3权重c。
在意图理解结果候选与层次树对应意图一致的情况下(步骤ST32“是”且步骤ST34“是”),权重计算部33将等待权重设为第4权重d(步骤ST35)。此外,在步骤ST34“是”中,可能存在意图理解结果候选与层次树对应意图、关键字对应意图双方一致的情况。
在意图理解结果候选与层次树对应意图不一致而仅与关键字对应意图一致的情况下(步骤ST34“否”),权重计算部33将等待权重设为第5权重e(步骤ST36)。
在本实施方式3中,假设c=0.0、d=1.0、e=0.5。即,如果意图理解结果候选与层次树对应意图一致,则等待权重成为1.0,如果与层次树对应意图不一致而与关键字对应意图一致,则成为0.5,如果与层次树对应意图、关键字对应意图都不一致,则成为0.0。
接着,说明意图理解装置30的动作。
意图理解装置30的动作基本上与上述实施方式1、2的意图理解装置1、20的动作相同。本实施方式3与上述实施方式1、2的区别是等待权重的计算方法。
以下,详细地说明图8所示的对话内容中的用户发话“把○○作为目的地”的意图理解过程。与上述实施方式1、2同样,假定在作为控制对象的导航装置100(图2所示)中组装了意图理解装置30的情况。
另外,层次树21引用图10以及图11。
用户发话“把○○作为目的地”的输入语音2被语音识别部3识别(步骤ST11),被词素分析部5分解为词素(步骤ST12),意图理解部7算出意图理解结果的候选(步骤ST13)。然后,可获得图18的(b)这样的意图理解结果候选“经由地删除[设施=$设施$(=○○)]”及其分数“0.623”以及“终点设定[设施=$设施$(=○○)]”及其分数“0.127”。
接着,关键字检索部32从关键字表31中检索与词素分析部5的词素分析结果对应的关键字,取得与检索出的关键字对应的关键字对应意图。因为在“不去○○”的词素分析结果中存在图16的“不去”这样的关键字,所以,关键字对应意图成为“经由地删除[]”。
接着,权重计算部33计算等待权重(步骤ST31)。在此时刻,层次树21的节点#4是激活状态,节点#4的层次树对应意图是“终点设定[]”。
首先,在步骤ST32中,层次树21对权重计算部33输出已激活的节点#4的层次树对应意图“终点设定[]”。另外,意图理解部7对权重计算部33输出用户发话“不去○○”的意图理解结果候选第1位“经由地删除[设施=$设施$(=○○)]”。此外,关键字检索部32对权重计算部33输出关键字对应意图“经由地删除[]”。
因为意图理解结果候选第1位的“经由地删除[设施=$设施$(=○○)]”与关键字对应意图“经由地删除[]”一致(步骤ST32“是”且步骤ST34“否”),所以,权重计算部33将意图理解结果候选第1位的等待权重设为第5权重e(=0.5)(步骤ST35)。
这里,权重计算部33还把层次树21的父子关系包含在内判断一致,因为“经由地删除[设施=$设施$(=○○)]”是“经由地删除[]”的子,所以,判断为一致。
另一方面,因为意图理解结果候选第2位“终点设定[设施=$设施$(=○○)]”与层次树对应意图“终点设定[]”一致(步骤ST32“是”且步骤ST34“是”),所以,权重计算部33将意图理解结果候选第2位的等待权重设为第4权重d(=1.0)(步骤ST36)。
最终,如图18的(b)那样,求出与第1位的语音识别结果“不去○○”相对的第1位的意图理解结果候选“经由地删除[设施=$设施$(=○○)]”的最终分数“0.312”、第2位的意图理解结果候选“终点设定[设施=$设施$(=○○)]”的最终分数“0.127”。因为第1位、第2位的最终分数都不满足X以上的条件,所以,意图理解装置30针对第2位的语音识别结果“经由○○”,进行步骤ST12、ST13、ST30、ST31、ST15的处理。
其结果是,如图18的(c)那样,“经由○○”的意图理解结果候选第1位“经由地删除[设施=$设施$(=○○)]”以及第2位“设施检索[设施=$设施$(=○○)]”分别设定等待权重“0.0”(=c),最终分数分别为“0.0”,这里也不满足X以上的条件。
因此,处理对象转移至第3位的语音识别结果“把○○作为目的地”,如图18的(d)那样,意图理解结果候选第1位“终点设定[设施=$设施$(=○○)]”的最终分数满足X以上的条件,所以,作为意图理解结果13进行输出。由此,与上述实施方式2同样地将“○○”设定为终点。
以上,根据实施方式3,意图理解装置30具备关键字检索部32,其从定义了意图与关键字的对应关系的关键字表31中检索与词素串一致的关键字,并取得与该检索的关键字对应的关键字对应意图,权重计算部33构成为,使用层次树对应意图和关键字对应意图来计算等待权重。因此,可利用意图的层级性和作为意图的特征表现的关键字来校正与用户发话相对的意图,并能够使控制对象设备根据确切的语音识别结果以及意图理解结果进行动作。
此外,在上述实施方式1~3中,虽然说明了日语的例子,但也可以按照各种语言变更与意图理解相关的特征提取方法,由此,能够应用于英语、德语以及中文等各种语言。
另外,在单词是用特定的符号(例如,空格)划分的语言的情况下,如果难以分析语言的构造,则可以针对输入语音2的自然语言文本,利用模式匹配这样的方法提取“$设施$”、“$住所$”等槽值,然后,直接执行意图理解处理。
此外,在上述实施方式1~3中,通过利用词素分析部5分析语音识别结果的文本来进行意图理解处理的准备,但是,根据语音识别部3的识别方法的不同,有时存在语音识别结果本身包含词素分析结果的情况,在此情况下,可以省略词素分析部5和词素分析词典6,在语音识别处理之后直接执行意图理解处理。
另外,在上述实施方式1~3中,作为意图理解的方法,以假定基于最大熵法的学习模型的例子进行了说明,但不是限定意图理解方法。
此外,在上述实施方式3中,构成为,权重计算部33使用层次树对应意图和关键字对应意图来计算等待权重,但即便不使用层次树21而根据关键字表31的关键字在词素分析结果中出现的次数来变更意图理解结果候选的分数,也能够计算等待权重。
例如,在用户发话中出现了对于确定“不去”、“经由”这样的意图而言重要的单词的情况下,意图理解部7通常对用户发话“不去○○”使用“○○、不去”这样的特征进行意图理解处理。取而代之,也可以通过像“○○、不去、不去”这样地重复位于关键字表31中的关键字,意图理解部7计算在估计意图时根据“不去”的个数而加权的分数。
另外,在上述实施方式1~3中,按照多个语音识别结果中的似然度从高到低的顺序依次进行意图理解处理,在发现最终分数满足X以上的条件的意图理解结果候选的时刻结束处理,但在意图理解装置的运算处理中存在富余的情况下,对全部语音识别结果进行意图理解处理来选择意图理解结果13的方法也是可行的。
此外,在上述实施方式1~3中,虽然在执行与意图理解结果13对应的操作之前向用户确认是否可以执行(例如,图3的(b)的“删除经由地○○。可以吗?”),但也可以根据意图理解结果13的最终分数来变更是否进行确认。
另外,例如,也可以是,在将语音识别结果第1位的意图理解结果候选被选择为意图理解结果13的情况下不进行确认、在第2位以后的意图理解结果候选被选择为意图理解结果13的情况下进行确认等,根据名次变更是否进行确认。
另外,例如,也可以是,在用等待权重进行校正之前的分数最高的意图理解结果候选被选择为意图理解结果13的情况下不进行确认,在分数比其低的意图理解结果候选被选择为意图理解结果13的情况下进行确认等,根据分数的大小变更是否进行确认。
这里,图21示出意图理解装置40的变形例。意图理解装置40具备:语音输入部41,其将用户发出的语音转换成信号,并取得该信号作为输入语音;意图确认处理部42,其在意图理解校正部12排除可能性最大的意图理解结果候选(即,利用等待权重校正之前的分数大的意图理解结果候选)并将其以外的意图理解结果候选选择为意图理解结果13的情况下,向用户确认是否采用该意图理解结果13而决定可否采用;以及语音输出部43,其输出意图确认处理部42所生成的意图理解结果确认用的语音信号。这些语音输入部41、意图确认处理部42以及语音输出部43发挥与图2所示的语音输入部101、导航控制部102以及语音输出部103相同的作用,通过如图3的(b)那样的“删除经由地○○。可以吗?”的语音输出,向用户确认可否采用意图理解结果13。
此外,向用户的确认方法除了语音输出之外,还可以是画面显示等。
此外,在上述实施方式2、3中,虽然利用层次树21的树结构表现了意图的层次性,但并非必需是完整的树结构,如果是不包含环结构的曲线结构,也能够进行同样的处理。
此外,在上述实施方式2、3中,虽然在意图理解处理中仅利用了本次的用户发话,但在层次树21的层次变化过程中的发话的情况下,也可以使用从包含本次之前的用户发话在内的多个发话中提取的特征来进行意图理解处理。由此,能够估计根据通过多个部分发话获得的部分信息难以估计的意图。
这里,使用图22所示的对话内容作为例子进行说明。
在上述实施方式2的情况下,从最初的用户发话“设定目的地”中提取“目的地、设定”作为特征。另外,从第2个的发话“○○”中提取“$设施$(=○○)”作为特征。作为结果,通常在第2个的发话中仅使用“$设施$(=○○)”进行意图理解处理(图13的步骤ST13)。
另一方面,在考虑是否是层次变化过程中的情况下,最初的发话“设定目的地”是层次树21的节点#4、第2个的发话与节点#4为父子关系的可能性高,所以,对第2个发话使用“目的地、设定、$设施$(=○○)”这3个特征进行意图理解处理,由此可获得更确切的意图理解结果。
另外,在上述实施方式1~3中,虽然作为意图理解装置的控制对象设备,以图2的导航装置100为例,但不限于导航装置。另外,在图2中将意图理解装置内置于控制对象设备,但也可以外置。
除了上述以外,本发明在其发明的范围内,可进行各实施方式的自由组合、各实施方式的任意构成要素的变形或者在各实施方式中省略任意的构成要素。
工业上的可利用性
如以上那样,本发明的意图理解装置使用输入语音来估计用户的意图,所以,适合用于手动难以操作的汽车导航装置等的语音接口。
标号说明
1、20、30、40意图理解装置,2输入语音,3语音识别部,4语音识别词典,5词素分析部,6词素分析词典,7意图理解部,8意图理解模型,9设定信息,10设定信息存储部,11、22、33权重计算部,12意图理解校正部,13意图理解结果,21层次树,31关键字表,32关键字检索部,41、101语音输入部,43、103语音输出部,42意图确认处理部,100导航装置,102导航控制部。
- 还没有人留言评论。精彩留言会获得点赞!