一种声纹识别系统及方法与流程
本发明涉及信息技术领域、传感信号处理以及人工智能领域,特别涉及一种基于卷积神经网络的声纹识别系统及方法。
背景技术:
随着信息技术发展,互联网的普及,以及物联网时代的到来,需要用到人的身份识别的应用场合越来越多,传统需求方面,有各种网上账户的需要,在线支付,或者门禁等等,而随着物联网及人工智能的应用推广,越来越多的电器或者设备将具有更多的智能,设备也将根据不同人的习惯特点进行特色的服务,此时就需要身份识别。
这种情况下,对身份识别的安全性、可靠性和便利性要求越来越高,传统的依靠输入密码的方式非常麻烦,容易遗忘和被盗,近来身份识别技术逐渐往人的生理特征识别技术方面发展,比如指纹,人脸,声纹识别等等。
声纹识别是其中可能被广泛应用的一种生理特征识别技术,其具有稳定性,安全性,和方便性,相对于指纹,密码等,可以实现无接触的识别,甚至可以在人机对话过程中自动完成,声纹是指说话人语音频谱的信息图,由于每个人的发音器官不同,所发出来的声音及音调各不相同,因此,声纹作为基本特征来实现人的身份识别具有实际的不可替代性和稳定性,将会有很广泛的应用。
目前声纹识别的流程方法是首先对说话人的语音特征进行提取,建立声纹模型库,在识别过程中根据系统已有的声纹模型库对输入语音的特征参数进行模式匹配计算,从而实现识别判断,这种参数的提取主要是基于说话人发生器官,如声门、鼻道等的特殊结构而提取出说话人话音的短时谱特征(即基音频率谱及其固有特征)。
然而相较于指纹识别和人脸识别已经开始广泛应用,声纹识别技术的准确性和成熟度目前还不够高,当前的技术方法仍然具有其局限性,仅仅根据短时谱特征来进行判别,其特征维度不够,从而导致对个体差异的适应不够。
当前人工智能采用人工神经网络模型进行大数据训练之所以能够取得非常高的智能识别准确度,就在于通过神经网络模型和大数据结合能够训练出更多维度特征模型来,从而实现更高精度的匹配识别。
技术实现要素:
本发明的目的在于提供一种能够获得高精度匹配识别的基于卷积神经网络(CNN)的声纹识别方法。
为了达到上述目的,本发明提供了如下技术方案。
一种声纹识别系统,其包括:声谱图转换模块、CNN声纹特征提取模块、CNN参数模块、用户声纹特征模型库模块和声纹特征谱匹配解码模块,外部声音输入所述声谱图转换模块,所述声谱图转换模块将所述外部声音进行转换并将转换结果输入所述CNN声纹特征提取模块,所述CNN声纹特征提取模块从所述CNN参数模块中读取CNN参数结合所述转换结果进行声纹特征提取并将提取结果输入所述声纹特征谱匹配解码模块,在所述声纹特征谱匹配解码模块中,将所述提取结果与所述用户声纹特征模型库中的用户声纹特征进行匹配解码识别,识别结果输出即为身份识别结果。
作为本发明的优选方案,所述CNN参数是在上述声纹识别系统识别前由大数据训练得到,所述用户声纹特征是在使用上述声纹识别系统前由所述声谱图转换模块、CNN声纹特征提取模块和CNN参数模块运行采集而成并存放入所述用户声纹特征模型库待调用。
一种包含上述声纹识别系统的声纹识别方法,其包括以下步骤:
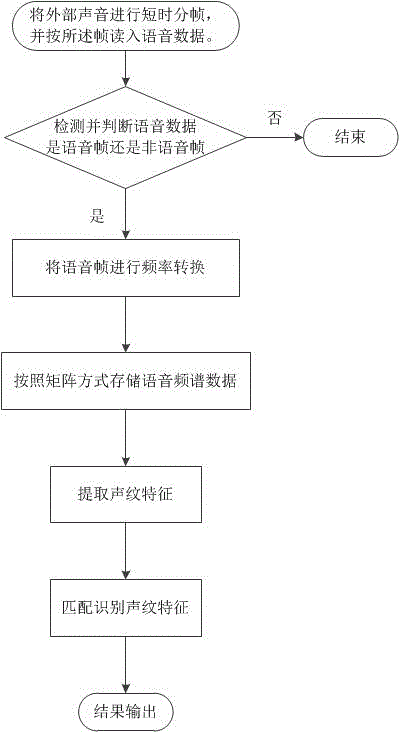
步骤一、将外部声音进行短时分帧,并按帧读入语音数据,为保证所述帧与帧之间的连续性,所述帧与帧切割边缘可以有一定的重复;
步骤二、检测所述语音数据,判断所述语音数据是语音帧还是非语音帧,是则进入下一步骤,否则结束流程,当检测到所述语音数据是语音帧时,将所述语音帧及所述语音帧开始前或结束后靠近部分的语音帧一起输出;
步骤三、将所述语音帧及所述语音帧开始前或结束后靠近部分的语音帧进行频率转换,即进行快速傅立叶变换(FFT),形成语音频谱数据;
步骤四、将所述语音频谱数据按照矩阵方式进行存放,所述矩阵的行是时间帧序列,所述矩阵的列是频率序列,所述矩阵就是二维的时间-频率声谱图,所述时间-频率声谱图是将频率当作一维,时间当作另一维,构成的二维图谱,也叫声谱图;
步骤五、所述时间-频率声谱图在CNN中进行声纹特征提取获得声纹特征;
步骤六、将所述声纹特征与用户声纹特征进行声纹特征匹配识别;
步骤七、识别结果输出。
作为本发明的优选方案,所述CNN参数在进行声纹识别前由大数据训练得到。
作为本发明的优选方案,所述用户声纹特征是在进行声纹识别前运行所述步骤一至步骤五后获得的结果,并将所述用户声纹特征放入所述声纹特征模型库中。
本发明声纹识别方法包括了3个过程:
过程一、所述CNN参数的大数据训练过程,该过程所用到的系统与前述所述用户声纹特征采集过程和所述声纹识别过程一样,即运行所述步骤一至步骤七,只是在流程上需要不断根据结果调整所述CNN参数,首先需要收集到大量的人声数据,每个人的声音数据需要多个,其次将部分所述人声数据用于特征采集,剩余部分所述人声数据用于声纹识别,当识别输出的身份匹配不正确时,修正所述CNN参数,直到最终识别正确;
过程二、所述用户声纹特征采集过程,所述用户声纹特征是在进行声纹识别前运行所述步骤一至步骤五后获得的结果,并将所述用户声纹特征放入所述声纹特征模型库中;
过程三、所述声纹识别过程,所述声纹识别过程是在所述CNN参数的大数据训练过程和所述用户声纹特征采集过程完成之后所进行的过程,运行所述步骤一至步骤七后获得的结果。
与现有技术相比,本发明的有益效果:
本发明将语音转成频率-时间的二维声谱图,利用卷积神经网络进行声谱图的特征提取,从而实现了更为准确的声纹识别。
附图说明
图1为本发明框图;
图2为本发明流程图。
具体实施方式
下面结合实施例及具体实施方式对本发明作进一步的详细描述,但不应将此理解为本发明上述主体的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
如图1所示,一种声纹识别系统,其包括:声谱图转换模块、CNN声纹特征提取模块、CNN参数模块、用户声纹特征模型库模块和声纹特征谱匹配解码模块,外部声音输入声谱图转换模块,声谱图转换模块将外部声音进行转换并将转换结果输入CNN声纹特征提取模块,CNN声纹特征提取模块从CNN参数模块中提取CNN参数结合转换结果进行声纹特征提取并将提取结果输入声纹特征谱匹配解码模块,在声纹特征谱匹配解码模块中,将提取结果与用户声纹特征模型库中的用户声纹特征进行匹配解码识别,识别结果输出即为身份识别结果,前述CNN参数是由大数据训练得到。
如图2所示,一种包含上述声纹识别系统的声纹识别方法,其包括以下步骤:
步骤一、将外部声音进行短时分帧,并按帧读入语音数据,本实施例中上述帧的时长为25ms,为保证所述帧与帧之间的连续性,所述帧与帧切割边缘可以有5ms重复;
步骤二、检测所述语音数据,判断语音数据是语音帧还是非语音帧,是则进入下一步骤,否则结束流程,当检测到语音数据是语音帧时,将语音帧及前述语音帧开始前或结束后时长为5ms的语音帧一起输出;
步骤三、将所述语音帧进行频率转换,即进行快速傅立叶变换(FFT),形成语音频谱数据;
步骤四、将所述语音频谱数据按照矩阵方式进行存放,所述矩阵的行是时间帧序列,所述矩阵的列是频率序列,所述矩阵就是二维的时间-频率声谱图;
步骤五、所述时间-频率声谱图在CNN中进行声纹特征提取获得声纹特征;
步骤六、将所述声纹特征与用户声纹特征进行声纹特征匹配识别;
步骤七、识别结果输出。
CNN参数是在进行声纹识别前由大数据训练得到,前述的训练过程所用到的系统与前述用户声纹特征采集过程和声纹识别过程一样,即运行前述步骤一至步骤七,只是在流程上需要不断根据结果调整CNN参数,首先需要收集到大量的人声数据,每个人的声音数据需要多个,其次将部分人声数据用于特征采集,剩余部分人声数据用于声纹识别,当识别输出的身份匹配不正确时,修正所述CNN参数,直到最终识别正确。
用户声纹特征是在进行声纹识别前运行上述步骤一至步骤五后获得的结果,并将用户声纹特征放入声纹特征模型库中待进行声纹识别时调用。
- 还没有人留言评论。精彩留言会获得点赞!