一种公共场所异常声音特征提取及识别方法与流程
技术特征:
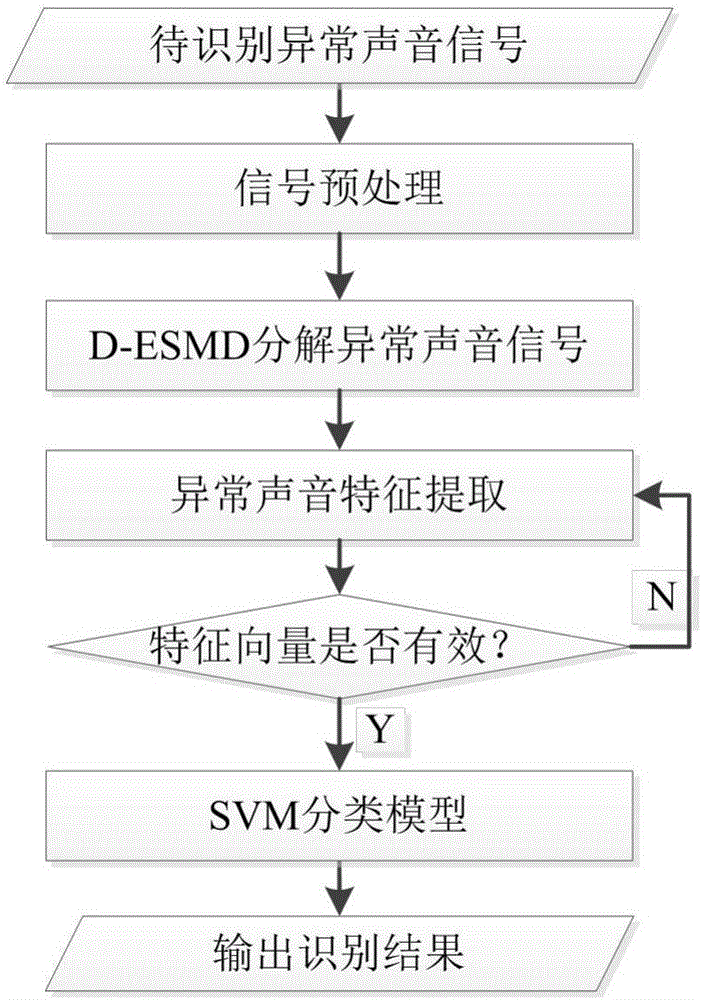
1.一种公共场所异常声音特征提取及识别方法,其特征在于,包括:公共场所待识别异常声音分解、特征提取和识别;具体实现步骤如下:
步骤1:输入公共场所待识别异常声音并进行预处理;
步骤2:采用改进的极点对称模态分解D-ESMD方法将待识别异常声音信号进行分解,得到各阶模态分量,每阶模态分量分别包含异常声音信号在不同频率段的特征;
步骤3:计算步骤2中得到的各阶模态分量相对于原始异常声音信号的能量比,并组合成向量形式进行归一化处理,作为待识别异常声音信号的特征向量;
步骤4:判断特征向量是否有效;若无效,跳转到步骤3;若有效,执行步骤5;
步骤5:公共场所待识别异常声音的识别过程:首先,在已经建立的异常声音库中随机选取每一类并且一定数量的训练样本,通过步骤2和步骤3求取其训练样本的特征向量并建立SVM分类模型;然后,利用建立的SVM分类模型对待识别异常声音的特征向量进行分类,得到分类识别结果;
所述的D-ESMD分解方法是在极点对称模态ESMD分解方法基础上,添加随机T分布噪声序列于公共场所待识别异常声音当中,采用对称中点插值方法替代ESMD的极值中点奇偶插值方法,对分解的模态分量计算排列熵值,并且改进模态分量筛选次数,进而完成各模态的复杂性检测,自适应得到异常声音有效模态分量;
所述的异常声音库中包括爆炸声、尖叫声、枪声、玻璃破碎声。
2.根据权利要求1所述的一种公共场所异常声音特征提取及识别方法,其特征在于,所述的D-ESMD分解方法的具体过程为:
步骤2.1确定添加T分布随机噪声次数N;
步骤2.2假设待识别异常声音信号为x,添加随机的T分布序列于待识别声音信号x中,得到加噪的异常声音信号Xi;
步骤2.3求取加噪过后异常声音信号Xi的极值点,连接相邻极值点,并将线段中点标记为Fi,补充左右边界点F0与Fn,采用对称中点插值方法替代ESMD的极值中点奇偶插值方法对n+1个极值中点构造插值曲线L*;
步骤2.4将Xi-L*作为输入,重复上述步骤2.3直到筛选次数达到最大值,得到第一阶模态分量M1i,计算模态分量的排列熵的值;如果该信号的排列熵的值大于约定阈值θ,则认为是异常声音模态分量,否则认为是噪声分量;
步骤2.5若模态分量M1i为异常声音模态分量,则将Xi-M1i作为输入信号,重复步骤2.3-步骤2.4,直到分解得到的模态分量Mni为噪声分量为止;
步骤2.6若i<N,则令i=i+1,重复步骤2.2至步骤2.5,每次添加的T分布噪声信号不同,直至进行N次分解为止,对得到所有的模态分量Mki求总体平均值,并将结果作为待分解信号的最终的模态分量Mk:
上式中,k是模态分量阶数,N为加噪次数。
3.根据权利要求1或2所述的一种公共场所异常声音特征提取及识别方法,其特征在于,所述的对称中点插值方法具体步骤为:
步骤3.1、假设输入信号为y,求取y的所有极大值点ymax与极小值点ymin;
步骤3.2、连接所有相邻极值点,并求取极值中点ymean;
ymean=(ymax+ymin)/2
步骤3.3、求取相邻极值中点的对称中点ym,同时采用三次样条插值方法对ym进行插值,得到最终插值曲线。
4.根据权利要求2所述的一种公共场所异常声音特征提取及识别方法,其特征在于,步骤2.4中筛选次数的最大值优先12。
5.根据权利要求2所述的一种公共场所异常声音特征提取及识别方法,其特征在于,排列熵的具体计算过程如下:
假设一个长度为N的时间序列信号x(i),i=1,2,…,N,对其进行延迟重构,得到如下时间序列:
式中,l为时间延迟,m为重构维数,对X(i)中m个元素进行升序排列,得到:
X′i={x(i+(j1-1)*l)≤x(i+(j2-1)*l)
≤…≤x(i+(jm-1)*l)}
因此,每一个向量X(i)都拥有一组排列序列:
Sg={j1,j2,j3,…jm}
式中,j表示重构分量中各元素所在列的索引;
其中,对于m个不同的符号必然会有m!种不同的排列;计算每种排列方式在X(i)中出现的概率p1、p2、…p3,则归一化后的排列熵为:
其中,N为时间序列长度,m为重构维数和l为时间延迟。
- 还没有人留言评论。精彩留言会获得点赞!