基于骨传导高噪声环境下的语音识别系统的制作方法
本发明涉及一种语音识别系统,特别是涉及一种基于骨传导高噪声环境下的语音识别系统。
背景技术:
语音是人类交流最方便的一种方式,如用语音实现操作则会带来很大方便,目前一般的语音识别系统,采用模拟滤波和MCU(单片机)语音处理,由于模拟滤波装置体积大,过滤噪声范围由元件参数制约,调整不方便,过滤噪声范围易受环境温度影响,而简单的数字语音储存、语音识别技术,受环境噪声和音量的影响大,语音识别的效果差,造成识别出错,引起操作或控制失误。
技术实现要素:
针对现有技术中的缺陷,本发明的目的是提供一种基于骨传导高噪声环境下的语音识别系统,其克服现有装置滤波调整不方便、通用性差、体积大、结构复杂、受环境噪声和音量的影响大、语音识别的效果差、易造成识别出错、引起操作或控制失误等问题。
根据本发明的一个方面,提供一种基于骨传导高噪声环境下的语音识别系统,其特征在于,其包括:
送话器,用于发送语音;
语音接收模块,用于接收训练语音或辨识语音;接收训练语音,储存使用者的语音命令;接收辨识语音,与多个训练语音比较辨识,并按功能设置,通过开关量IO接口输出不同的操作逻辑信号;
驱动电路模块,用于放大控制电路的信号;
逻辑开关量IO接口,用于执行不同的操作、控制电路实现对多种设备的控制,用于对压力、流量、温度进行调节;
控制设定模块,用于控制、设定工作;
工作状态显示模块,用于显示整个系统工作状况;
通信接口模块,用于连接通信设备;
语音处理模块,用于处理语音信号;语音处理模块包括相互连接的语音回放模块和DSP模块,语音回放模块用于实现清晰的语音通信或在对操作命令识别后,按功能设置进行相应操作时,为进一步提高操作正确率,在每一个指令收到后,系统会通过语音回放回馈给使用者,便于及时确认;DSP模块用于接收训练语音或辨识语音;对环境噪声进行过滤、消噪和语音信号的闭环音量自动调节,使语音不受环境噪声和音量的影响,实现清晰的通信或正确的语音训练储存和语音识别;DSP模块包括DA转换模块、数字滤波模块、PID控制模块和AD转换模块,DA转换模块用于将数字信号转换为模拟信号;数字滤波模块用于对信号进行处理;PID控制模块用于测量、比较和执行实际值和期望值;AD转换模块用于将模拟信号转换为数字信号;
信号调理模块,使语音信号达到A/D要求;
受话器,用于接收语音。
优选地,所述DSP模块包括以下步骤的工作过程:
步骤一,接收语音信号;
步骤二,进行DA转换;
步骤三,进行数字滤波处理;
步骤四,存储识别信号;
步骤五,经开关量IO,进行调节控制;
步骤六,进行AD转换和回放。
优选地,所述DSP模块采用数学运算处理方法实现正确识别,并进行相应操作。
优选地,所述DSP模块采用TI公司TMS320LF2407A控制器,TMS320LF2407A与通用的CPU和微处理器相比,价格低、应用广泛、有很强的数字信息处理功能,它集C2xx内核增强型TMS320设计结构及低功耗、高性能、优化外围电路于一体,16位数字信号处理,带有硬件乘法器和乘加指令,每条指令在25ns完成,语音经10位高速AD转换器语音转换等数字信息处理能力为本发明提供合适的硬件基础;DSP具有程控性、重复性,抗干扰性能好,能够实现自适应算法、数据压缩,它具有模拟信号的无法替代的特性。
优选地,所述PID控制模块具有闭环音量自动调节,闭环音量自动调节采用离散量PID调节,使语音不受环境噪声和音量的影响。
优选地,所述PID控制模块具有语音训练,用于从DSP对采集到的语音样本进行分析处理中,提取出语音特征信息,建立一个特征模型,存储于存储器中。
优选地,所述PID控制模块具有语音识别,用于从DSP对采集到的语音样本进行类似的分析处理中,提取出语音的特征信息,然后将这个特征信息模型与已有的特征模型信号进行对比,如果二者达到了一定的匹配度,则输入的语音被识别,作出相应动作。
本发明的积极进步效果在于:本发明无需任何模拟滤波器,装置完全集成化,使用DSP模块及相关技术,装置性能优良;从经济的角度讲,本发明使用的仅仅为一块通用DSP模块和少量普通电子元件组成的外围电路,由于采用通用电子器件,器件成本低廉,从应用的角度讲,语音是人类交流最方便的一种方式,用语音实现清晰的通信或相应的操作具有很广应用前景。本发明调整方便,通用性好,体积小,结构简单,不受环境噪声和音量的影响,语音识别的效果好,不会造成识别出错、引起操作或控制失误。本发明具有噪声抑制、音量自动调节、语音储存、语音识别等功能,利用DSP强大的数字信号处理能力,完成音源波频谱分量分析,然后根据所希望的频率特性进行滤波,同时对语音信号幅值进行离散量的闭环音量自动调节。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
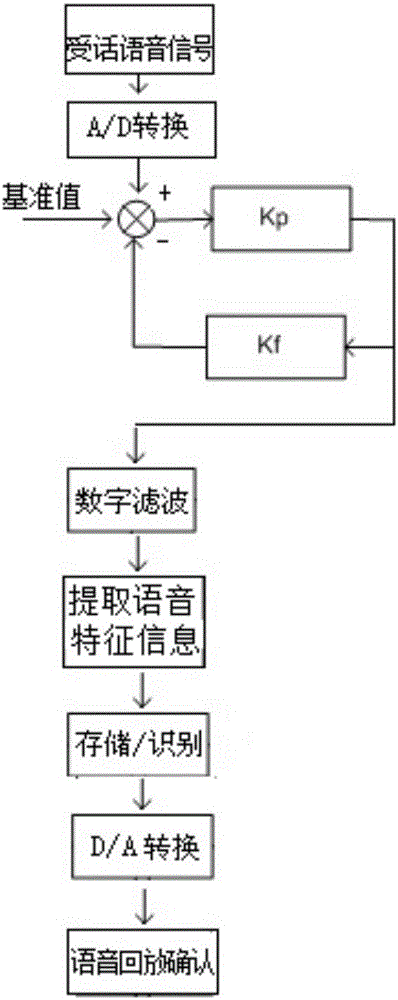
图1为本发明基于骨传导高噪声环境下的语音识别系统的原理框架图。
图2为本发明中PID控制模块的工作过程的流程图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
如图1所示,本发明公开了一种基于骨传导高噪声环境下的语音识别系统,其包括送话器、语音接收模块、驱动电路模块、逻辑开关量IO(输入输出)接口、控制设定模块、工作状态显示模块、通信接口模块、DA(数模)转换模块、PID(比例-积分-微分)控制模块、AD(模数)转换模块、DSP(数字信号处理)模块、语音处理模块、数字滤波模块、语音回放模块、信号调理模块、受话器,其中:
送话器,用于发送语音;
语音接收模块,用于接收训练语音或辨识语音;接收训练语音,储存使用者的语音命令;接收辨识语音,与多个训练语音比较辨识,并按功能设置,通过开关量IO接口输出不同的操作逻辑信号;
驱动电路模块,用于放大控制电路的信号;
逻辑开关量IO接口,用于执行不同的操作、控制电路实现对多种设备的控制,用于对压力、流量、温度进行调节;
控制设定模块,用于控制、设定工作;
工作状态显示模块,用于显示整个系统工作状况;
通信接口模块,用于连接通信设备;
语音处理模块,用于处理语音信号;语音处理模块包括相互连接的语音回放模块和DSP模块,语音回放模块用于实现清晰的语音通信或在对操作命令识别后,按功能设置进行相应操作时,为进一步提高操作正确率,在每一个指令收到后,系统会通过语音回放回馈给使用者,便于及时确认,使控制正确率达到100%;
DSP模块用于接收训练语音或辨识语音;对环境噪声进行过滤、消噪和语音信号的闭环音量自动调节,使语音不受环境噪声和音量的影响,实现清晰的通信或正确的语音训练储存和语音识别;DSP模块包括DA转换模块、数字滤波模块、PID控制模块和AD转换模块,DA转换模块用于将数字信号转换为模拟信号;数字滤波模块用于对信号进行处理;PID控制模块用于测量、比较和执行实际值和期望值;AD转换模块用于将模拟信号转换为数字信号;经过语音识别后,实现多种操作功能,针对不同语音命令进行操作或控制;为进一步提高正确率,在每一个指令收到后,系统会通过语音回放回馈给使用者,便于及时确认,使控制正确率达到100%,并由系统给控制接口以逻辑指令以执行下一步操作;整个系统工作状况由显示器指示;整个系统还能通过通信接口应用于多平台的控制,能走向工业机器人控制应用领域;
信号调理模块,使语音信号达到A/D要求;
受话器,用于接收语音。
如图2所示,DSP模块包括以下步骤的工作过程:
步骤一,接收语音信号;
步骤二,进行DA转换;
步骤三,进行数字滤波处理;
步骤四,存储识别信号;
步骤五,经开关量IO,进行调节控制;
步骤六,进行AD转换和回放。
所述DSP模块采用数学运算处理方法实现正确识别,并进行相应操作。
所述DSP模块采用TI公司TMS320LF2407A控制器,TMS320LF2407A与通用的CPU和微处理器(MCU)相比,价格低、应用广泛、有很强的数字信息处理功能,它集C2xx内核增强型TMS320设计结构及低功耗、高性能、优化外围电路于一体,16位数字信号处理,带有硬件乘法器和乘加指令,每条指令在25ns完成,语音经10位高速AD转换器语音转换等数字信息处理能力为本发明提供合适的硬件基础;DSP具有程控性、重复性,抗干扰性能好,能够实现自适应算法、数据压缩,它具有模拟信号的无法替代的特性。DSP模块对音源信号进行数学运算处理方法来达到频域滤波,并且对语音信号幅值进行离散量闭环音量自动调节。DSP模块对采集到的语音样本在滤波和音量自动调节之后,进行分析处理,提高匹配程度,达到正确语音识别。
在DSP模块提供高速数字信号处理硬件基础上,进行有效数字信号处理技术开发,通过研究人类语音特色,进行细微的频谱分析,同时对各种环境噪声和各种装备工作时产生的噪声开展频谱研究和统计分析,鉴别出环境噪声与人类语音的差别,在此基础上,得出数字滤波传递函数,进行滤波,抑制环境噪声,开发出语音识别软件进行语音识别;语音识别对象是语音,决定音源质量的关键参数是“采样率”,只要选择采样率>48KHz就能达到CD音质,实现对语音的高音质精确采集,确保整体数据处理分析的精度;一般的MCU是难以达到的,并由DSP模块进一步作数字信号处理,完成噪声抑制,数值PID控制、数据压缩技术等;把语音信号处理要求和DSP模块的数字信息处理技术结合起来实现高质量语音通信和正确的语音识别。
DSP模块将语音信号从时域变换到频域形式通常采用傅立叶变换,对于离散化的周期信号而言,快速傅立叶变换(FFT)是分析语音波形的最好的算法之一,利用FFT能直接得到波形所含的各频谱分量。FFT是离散傅立叶变换(DFT)的一种快速算法;由于我们在计算DFT时一次复数乘法需用四次实数乘法和二次实数加法;一次复数加法则需二次实数加法;每运算一个X(k)需要4N次复数乘法及2N+2(N-1)=2(2N-1)次实数加法;所以整个DFT运算总共需要4N2次实数乘法和N*2(2N-1)=2N(2N-1)次实数加法;如此一来,计算时乘法次数和加法次数都是和N2成正比的,当N很大时,运算量是庞大的,因而需要改进对DFT的算法减少运算速度;根据傅立叶变换的对称性和周期性,将DFT运算中有些项合并和有限项简化。
设序列长度为N=2L,L为整数;将N=2L的序列x(n)(n=0,1,…,N-1),按N的奇偶分成两组,也就是说我们将一个N点的DFT分解成两个N/2点的DFT,它们又重新组合成一个如下式(1)所表达的N点DFT:
上式FFT运算序列是混乱的,但经分析,信号流程有一定规律—即位码倒置,本发明使用了位倒序的减接寻址方式和乘累加、移位累加指令实现;
利用快速傅立叶变换(FFT)对输入语音信号进行离散傅立叶变换分析其频谱,然后利用FIR数字滤波器,滤波器设计方法是利用滤波理论设计满足要求的传递函数H(s),依据H(s)求出相应的数字滤波器传递函数H(z),根据所希望的频率特性进行滤波,这种办法具有较好的频率选择性和灵活性。
所述PID控制模块具有闭环音量自动调节,闭环音量自动调节采用离散量PID调节,使语音不受环境噪声和音量的影响。
所述PID控制模块具有语音训练,语音训练用于从DSP对采集到的语音样本进行分析处理中,提取出语音特征信息,建立一个特征模型,存储于存储器中。
所述PID控制模块具有语音识别,语音识别用于从DSP对采集到的语音样本进行类似的分析处理中,提取出语音的特征信息,然后将这个特征信息模型与已有的特征模型信号进行对比,如果二者达到了一定的匹配度,则输入的语音被识别,作出相应动作。
本发明通过研究人类语音特色,同时通过对环境的各种噪声和各种装备工作时产生的噪声开展频谱研究和统计分析,鉴别出环境噪声与人类语音的差别,利用DSP强大的数字信号处理能力,完成音源波频谱分量分析,然后根据所希望的频率特性进行滤波,同时对语音信号幅值进行离散量的闭环音量自动调节,使语音不受环境噪声和音量的影响,实现高标准语音通信,通过与训练语音比较,实现语音识别,并按要求进行操作和控制。由于采用DSP有效地数字信号处理技术,使用数学运算方法对音源信号处理,省去了滤波器等器件,克服现有的识别语音装置通用性差、体积大、结构复杂、成本高等问题,取得了装置体积小、结构简单、频率选择方便、使用灵活、性能优良等有益效果。
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!