一种基于语音识别的农产品信息采集方法和系统与流程
本发明涉及农产品信息采集技术领域,更具体地说,特别涉及一种基于语音识别的农产品信息采集方法和系统。
背景技术:
随着我国农产品质量安全体系的建立和各项制度的不断完善,农产品质量安全信息的采集成为重要环节;但信息采集具有实时性强、覆盖面广、传统设备操作性差等特点。如何提高工作效率、减少人工重复劳动,是实现农产品质量安全生产与追溯、农产品市场监控及预警过程中亟待解决的问题。语言是人类沟通的最自然形式,其中蕴含大量的信息,语言交流也是农业生产中重要的通信手段。随着语音识别技术的迅速发展,将语音信息转化为便于计算机的处理文本信息,使得语音信息应用于农业生产成为可能。
语音识别(Speech Recognition),也称自动语音识别或机器语音识别,是通过计算机将人类语音信号转换为文本序列的过程。它涉及到人工智能与模式识别、数字信号处理、统计与概率、认知心理学、语音学、语言学等学科领域,是一门非常复杂的交叉学科。
语音识别的研究已经吸引了60年的极大关注。20世纪80年代中期,隐马尔科夫模型(HiddenMarkovModel,HMM)作为语音信号的一种统计模型,在语音信号处理的各个领域得到广泛应用,进而成为一个公认的研究热点,也是目前语音识别的主流研究途径。20世纪90年代,语音识别已从实验室走向实用化,如语音导航、语音听写、电话网络自动呼叫处理及票务查询等。近年来,鲁棒的语音识别、基于语音段的建模方法、隐马尔科夫模型和人工神经网络的结合成为研究的热点;另一方面,为了语音识别实用化的需要,语者自适应、听觉模型以及进一步的语言模型的课题倍受关注。
语音识别在农业领域的应用研究较薄弱。由于语音识别的学科综合性较强,加之手持式设备处理能力的限制,农业领域人员开发语音处理系统存在困难;而信息技术领域研究人员多注重通用、大词汇量、连续语音识别方法的研究。虽然目前有不少语音识别方面的研究成果产品,但仍缺乏基于手持设备的农业语音采集技术、方法或二次开发工具,在移动设备农业语音信息采集方法研究方面,目前仍处于空白。
农产品信息采集作为质量追溯、信息发布的关键和基础,采集技术和作业场景复杂多样。从技术上看,采集方式可分为两类:①原始信息采集。如生产记录、生长环境、农产品等级和价格等数据,需人工采集。嵌入式手持设备是此类任务的主流硬件平台。②数字化自动采集。通过传感器自动采集环境信息(温度、湿度等),通过条形码、RFID等技术自动采集原料信息(产地、时间等)。对于已完成数字化处理的数据,现有技术设备已经能够很好地解决其采集的问题,而对于只能通过人工干预进行采集的信息,由于大部分需要在进行农产品生产、管理工作的同时完成信息采集,而现有的设备和系统主要采用基于视觉/手动方式来完成采集,采集信息的同时必然导致工作效率降低。
技术实现要素:
本发明的目的在于提供一种农业语音信息识别的方法,该方法包括模型训练阶段和识别阶段。模型训练阶段包括声学模型训练和语言模型训练两部分。声学模型的建模单元为上下文三音子。声学模型训练的步骤是:第一步,对声音信号进行预处理;第二步,提取稳定的声学特征;第三步,通过人工采集大量的语音样本建立语音语料库;最后一步,采用向前向后算法进行模型的训练,得到稳定的声学模型。语言模型的训练的步骤是:第一步,对特定的应用场景用文本提取工具提取大量的文本,第二步,建立语料库,并对其语义分析和语法结构进行推断,进而形成语言模型。识别阶段的步骤是:第一步,在前端对输入语音信号进行特征提取,得到的特征向量与声学模型进行声学对比;第二步,从发音词典中选出概率分布最为接近的候选词,再利用语言模型进一步进行约束,得到最终的农业信息文本。
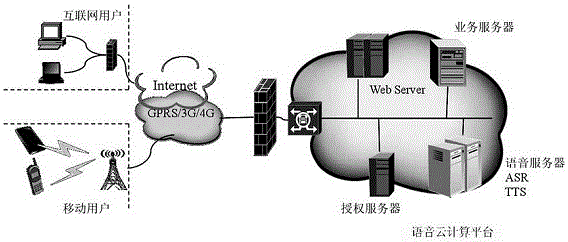
一种基于语音识别的农产品信息采集系统,包括移动终端、移动互联网、语音云计算平台;语音云计算平台包括语音服务器、业务服务器、授权服务器;语音服务器提供自动语音识别服务和语音合成服务。
与现有技术相比,系统在云计算平台搭建识别引擎,并训练出稳定的声学模型,通过手持式移动终端采集语音信号,通过互联网发送到服务器端进行识别,词识别率达到95%以上,满足了农产品语音信息采集的需要,工作效率高。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明所述系统总体结构图。
图2是本发明所述系统通信原理图。
具体实施方式
下面结合附图对本发明的优选实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
参阅图2所示,本发明提供一种农业语音信息识别的方法,该方法包括模型训练阶段和识别阶段。模型训练阶段包括声学模型训练和语言模型训练两部分。声学模型的建模单元为上下文三音子。声学模型训练的步骤是:第一步,对声音信号进行预处理;第二步,提取稳定的声学特征;第三步,通过人工采集大量的语音样本建立语音语料库;最后一步,采用向前向后算法进行模型的训练,得到稳定的声学模型。语言模型的训练的步骤是:第一步,对特定的应用场景用文本提取工具提取大量的文本,第二步,建立语料库,并对其语义分析和语法结构进行推断,进而形成语言模型。识别阶段的步骤是:第一步,在前端对输入语音信号进行特征提取,得到的特征向量与声学模型进行声学对比;第二步,从发音词典中选出概率分布最为接近的候选词,再利用语言模型进一步进行约束,得到最终的农业信息文本。
语音识别的主要过程分为模型训练阶段和识别阶段,其过程如图1所示。模型训练包括声学模型的训练和语言模型训练两部分。声学模型当前主要采用上下文三音子为建模单元,通过人工采集大量的语音样本建立语音语料库,采用向前向后算法进行模型的训练,得到稳定的声学模型。在声学训练之前,需要对声音信号进行预处理、提取稳定的声学特征,当前主流的特征为MEL频率倒谱系数(Mel-FrequencyCepstralCoefficients,MFCC)或感知线性预测系数(PerceptualLinearPrediction,PLP)等,较好地解决了特征提取问题。语言模型的训练主要是文本信息的处理,首先对特定的应用场景用文本提取工具提取大量的文本,建立语料库,并对其语义分析和语法结构进行推断,进而形成一系列的语法规则,即语言模型。
识别过程是对语音信号进行解码(decoding)的过程,基于隐马尔科夫模型的解码过程可采用Viterbi算法。首先,在前端对输入语音信号进行特征提取,得到的特征向量与声学模型进行声学对比;然后,从发音词典中选出概率分布最为接近的候选词,再利用语言模型进一步进行约束,得到最终的识别结果。
本发明还在一种农业语音信息识别的方法的基础上,提供了一种基于语音识别的农产品信息采集系统,系统基于移动互联网和云计算平台,构建应用系统,如图2所示。利用手机平台作为移动终端,采集语音信息和实现人机交互,通过移动GPRS/3G/4G通信网络和HTTP协议,将采集到的语音信号发送到语音服务器进行识别,语音服务器依靠强大的云计算资源提供自动语音识别(ASR)服务,可根据业务需求提供语音合成服务(TTS)。Web服务器为语音服务、业务服务、授权服务提供访问支持,通过http协议实现可靠的通信任务。业务服务器实现各种信息查询、决策支持、预警信息发布等具体业务。互联网用户通过Internet实现业务信息的访问,同时也可以完成语音识别的功能,但显然不适合在作业现场完成。
经测试,使用本发明的方法和系统词识别率(WRR)达到95%以上,基本满足了农产品语音信息采集的需要。
虽然结合附图描述了本发明的实施方式,但是专利所有者可以在所附权利要求的范围之内做出各种变形或修改,只要不超过本发明的权利要求所描述的保护范围,都应当在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!