基于说话人识别技术的口语测评身份认证方法与流程
本发明属于信息处理领域,具体涉及基于说话人识别技术的口语测评身份认证方法。
背景技术:
英语作为一门外语,学习起来比较不易,需要在日常生活、教学中营造充分的语言环境,来辅助学员学习,因此口语测评便成为了广泛使用的手段之一。老师在课堂上会尽力营造语言环境,帮助学员学习英语,但这不能够让老师完全掌握每个学员的真实情况以及学习过程中需要纠正的发音等其它问题。口语测评就可以解决这个问题,口语测评用于课下学员自行完成口语测试,并将测试结果上传给老师,老师能够了解每个学员的真实情况,并纠正不同学员的发音等。这就要求口语测评系统中增加身份识别的功能,对测评人的身份进行判断。
常用的身份识别技术包括指纹、虹膜、人脸、手写签名、以及语音的身份认证技术。语音是身份信息的重要载体,与人脸、指纹等其他生物特征相比,语音的获取成本低廉,使用简单,便于远程数据采集,且基于语音的人机交流界面更为友好,因此说话人识别技术成为重要的自动身份认证技术。
为此亟需提供一种基于说话人识别技术的口语测评身份认证方法,能够准确高效地对口语测评过程中测评人的身份进行识别。
技术实现要素:
针对现有技术中的缺陷,本发明提供一种基于说话人识别技术的口语测评身份认证方法,能够准确高效地对口语测评过程中测评人的身份进行识别。
基于说话人识别技术的口语测评身份认证方法,包括以下步骤:
S1:用户注册时,获取并分析用户的语音信息,得到标准语音模板,初始化身份认证分数;
S2:当用户启动口语测评功能时,根据测评的总时长T、身份认证分数S计算得到认证次数和认证时间;
S3:当认证时间到达时,获取用户的语音信息,并与标准语音模板进行对比,如果匹配,本次认证成功;否则返回步骤S3对下一次认证时间进行监测;
S4:根据本次口语测评的认证结果更新身份认证分数。
优选地,所述步骤S1还包括:实时检测是否接收到老师反馈的身份认证分数,如果是,更新身份认证分数。
优选地,所述步骤S1中,所述语音信息为多条,通过麦克风直接获取或是从用户的测试数据库中调取。
优选地,所述步骤S2具体为:
S2a:计算认证次数A,A=5T/S;
S2b:计算认证时间:Pi=Pi-1+B;其中,Pi-1=0,B为0~12S之间的随机数。
优选地,所述步骤S3具体为:
S3a:当认证时间Pi到达时,设定认证错误次数为0;
S3b:判断在预设的延长时间内是否接收到用户的语音信息,如果是,执行步骤S3c;否则,认证失败次数累积1,返回步骤S2;
S3c:认证错误次数是否达到预设的认证错误上限值,如果是,认证失败次数累积1,返回步骤S2;否则,执行步骤S3d;
S3d:将接收的语音信息与标准语音模板进行对比,如果匹配,返回步骤S3a对下一次认证时间进行监测;如果不匹配,认证错误次数累加1,返回步骤S3b。
优选地,所述步骤S4中,身份认证分数为认证失败次数的倒数。
优选地,该方法分析用户的语音信息时,首先构建若干个分类器,然后将分类器进行融合,得到标准语音模板。
优选地,所述分类器的构建方法如下:
首先,提取语音信息相应的JFA话者超向量,从JFA超向量中的均值向量中选取一个新的维度较低的子空间;然后,采用主成分分析方法对该子空间中的特征向量进行最优降维,将其投影到维度为J的低维子空间中;其次,在该低维子空间中,应用随机采样技术得到若干个随机子空间;最后,对于每个随机子空间,分别进行类内协方差规整以及非参数线性区分分析,从而得到每个随机子空间对应的投影矩阵,即分类器。
优选地,采用动态融合方法对分类器的输出进行融合。
优选地,所述动态融合方法具体为:
首先,对来自大量说话人的开发集语音数据集X进行分析,根据一定的准则将其划分为K个子集SK;然后,用每个分类器对各个子集中的语音数据进行测试,统计相应的得分输出;最后,将得分平均值作为确定分类器在各个集合上的权重。
由上述技术方案可知,本发明提供的基于说话人识别技术的口语测评身份认证方法,能够根据学员以往的身份识别结果更新身份认证次数,从而得到下次口语测评中的认证次数,根据学员以往口语测评的诚信度确定下次认证次数,诚信度差,增加下次口语测评过程中的认证次数,从而实现准确高效地对口语测评过程中测评人的身份进行识别。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
图1为基于说话人识别技术的口语测评身份认证方法的流程图。
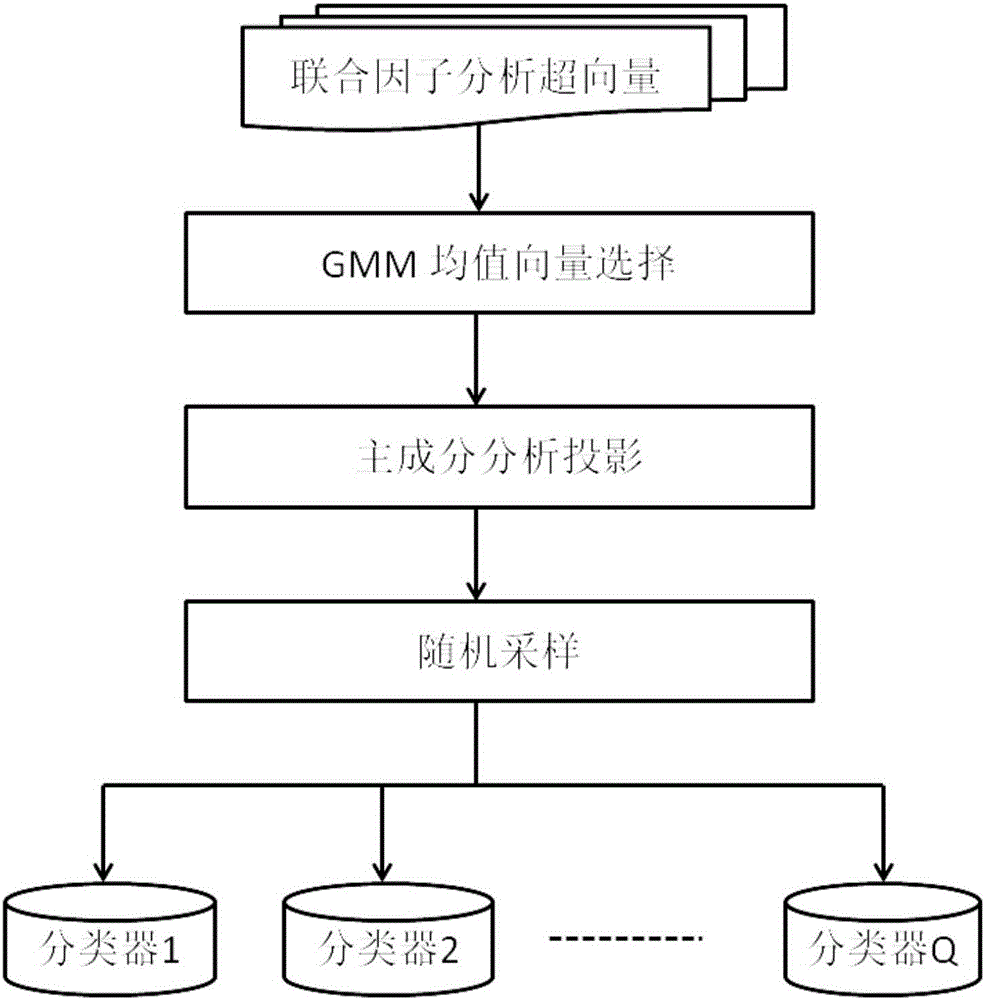
图2为基于联合因子分析超向量的多分类器构建示意图。
图3为基础分类器局部分类置信度的确定方法示意图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。需要注意的是,除非另有说明,本申请使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
基于说话人识别技术的口语测评身份认证方法,如图1所示,包括以下步骤:
S1:用户注册时,获取并分析用户的语音信息,得到标准语音模板,初始化身份认证分数;
S2:当用户启动口语测评功能时,根据测评的总时长T、身份认证分数S计算得到认证次数和认证时间;
S3:当认证时间到达时,获取用户的语音信息,并与标准语音模板进行对比,如果匹配,本次认证成功;否则返回步骤S3对下一次认证时间进行监测;
S4:根据本次口语测评的认证结果更新身份认证分数。
采用该方法实现口语测评过程的身份认证时,避免了每答一道题就需要进行一次身份认证,认证次数过多,降低了口语测评的效率。同时也避免了身份认证次数太少,起不到监督的作用。该方法通过上次口语测评的诚信度(即身份认证分数)来决定下次口语测评过程中的身份认证次数,即身份认证分数越低,诚信度越差,说明学员存在作弊行为的可能性越高,针对这种学员,增加下次口语测评过程中身份认证次数。反之,针对身份认证分数越高,诚信度越好的学员,减小下次口语测评过程中身份认证次数。具体实施时,身份认证分数的取值范围为0~10。用户注册时,默认身份认证分数为1,处于最低等级。该方法能够根据学员以往的身份识别结果更新身份认证次数,从而得到下次口语测评中的认证次数,根据学员以往口语测评的诚信度确定下次认证次数,诚信度差,增加下次口语测评过程中的认证次数,从而实现准确高效地对口语测评过程中测评人的身份进行识别。
所述步骤S1还包括:实时检测是否接收到老师反馈的身份认证分数,如果是,更新身份认证分数。该方法还可以接收老师反馈的身份认证分数,如果老师在听测评结果的过程中,发现学员有作弊或找人代读的现象时,可以根据作弊程度评分,作弊程度严重,分数越低。通过老师反馈身份认证分数和以往统计的学员的诚信度两方面来监控学员的口语测评,能够更好地实现对学员的监督,能够高效完成口语测评。
所述步骤S1中,所述语音信息为多条,通过麦克风直接获取或是从用户的测试数据库中调取。该方法在启动口语测评之前,还可以设有试用模板,试用模板用于模拟正式口语测评的场景,在用户进入试用模板使用时,将用户的语音信息存入测试数据库,作为后期标准语音模板调用的基础。
所述步骤S2具体为:
S2a:计算认证次数A,A=5T/S;
S2b:计算认证时间:Pi=Pi-1+B;其中,Pi-1=0,B为0~12S之间的随机数。
认证次数A与测评的总时长T成正比,与身份认证分数S成反比,即总时长T越长,认证次数越多,身份认证分数S越高,认证次数越少。A采用四舍五入法取整。认证时间的选取是随机的,随机的认证时间能够更准确的了解到学员的真实情况。当认证时间Pi大于总时长T时,设定Pi等于总时长T,T和B单位为秒,S的单位为次。
所述步骤S3具体为:
S3a:当认证时间Pi到达时,设定认证错误次数为0;
S3b:判断在预设的延长时间内是否接收到用户的语音信息,如果是,执行步骤S3c;否则,认证失败次数累积1,返回步骤S2;
S3c:认证错误次数是否达到预设的认证错误上限值,如果是,认证失败次数累积1,返回步骤S2;否则,执行步骤S3d;
S3d:将接收的语音信息与标准语音模板进行对比,如果匹配,返回步骤S3a对下一次认证时间进行监测;如果不匹配,认证错误次数累加1,返回步骤S3b。
认证错误上限值用于衡量在一次身份认证过程中最多错误次数,优选为3。认证错误原因可能为找别人代读、语音信号收到干扰、周围环境复杂等引起的。延长时间主要用于衡量语音信号的有效性。由于认证时间是随机的,所以如果是本人在做口语测评时,当随机弹出需要进行认证时,则能够快速接收到用户的语音信息,并进行认证。如果是找别人代读,则可能就需要代读人找到用户进行认证,自然接收到用户的语音信息的时间就要长些。所以延长时间不宜设置太长,优选为5-10秒。如果延长时间到达时,依然没有接收到用户的语音信息,则认为此次身份认证失败。如果在延长时间内接收到语音信息,如果匹配此次身份认证成功。如果不匹配,认证错误,当认证错误次数到达认证错误上限值时,判定为此次身份认证失败。
所述步骤S4中,身份认证分数为认证失败次数的倒数。即认证失败次数越多,身份认证分数越少,则下次口语测评过程中认证次数就越多。反之,认证失败次数越少,身份认证分数越大,则下次口语测评过程中认证次数就越少。
本实施例针对说话人识别方法,提出一种动态自适应的多分类器融合方法。在此方法中,充分考虑了各个基础分类器的局部分类性能,避免线性融合方法中权重较高的分类器将权重较低的分类器的局部分类能力淹没,进而提高对测试语音的识别结果可靠度。该方法分析用户的语音信息时,首先构建若干个分类器,然后将分类器进行融合,得到标准语音模板。
1、分类器的构建。
如图2所示,本发明中以联合因子分析话者超向量(JFA)作为说话人的特征表达,采用双层子空间采样方法来构建多个基础分类器,该算法中的第一层子空间采样是针对组成联合因子分析话者超向量的各个高斯成分的均值来进行的,目的是去除一部分冗余信息,确定一个合适维度的子空间;第二层则是在第一层子空间经过PCA最优降维后所得到的更低维度的子空间中进行随机采样,形成若干个新的子空间。
联合因子分析话者超向量与传统的GMM-UBM均值超向量在组成结构上是一样的,都可以看成是由GMM模型中各个高斯成分的均值向量按顺序拼接而成。所以本发明提出的子空间采样算法中的第一层子空间的采样是以联合因子分析超向量中的均值向量为基本单元的来进行的。具体来讲,给定第i个说话人的第h条语音的情况下,假设UBM模型的高斯成分数目为N,则该条语音数据相应的JFA超向量Mih可以表示为N个高斯均值向量的组合:Mih=[mih1,mih2,...,mihN]。主要步骤包括:
1)提取开发集中每条语音相应的JFA话者超向量Mih。
2)为了在高维原始特征空间中初步去除一部分冗余信息,从组成JFA超向量中的均值向量中选取一部分形成一个新的维度较低的子空间,该子空间包含了JFA超向量中的大部分有用信息,设该子空间中的低维度特征向量Sih表示为:Sih=[m'ih1,m'ih2,...,m'ihk]。
3)由于特征向量Sih仍然具有较高的维度,且各个维度的数值分布比较稀疏,所以仍包含着大量的冗余信息。接下来采用主成分分析方法对特征向量Sih进行最优降维,将其投影到维度为J的低维子空间中。
4)在经过PCA降维后所得到的子空间中,应用随机采样技术得到若干个随机子空间。
5)对于每个随机子空间,分别进行类内协方差规整以及非参数线性区分分析,从而得到一个投影矩阵,相应于每个随机子空间的投影矩阵可以表示为两个投影矩阵的乘积,即类内协方差规整投影矩阵与非参数线性区分分析投影矩阵的乘积。
根据以上步骤中的子空间分析结果,对于每个子空间可以得到一个子空间分类器。
2、自适应多分类器融合。
如图3所示,本发明采用在PCA空间进行随机采样的方法来构建基础分类器,该方法基于不同的特征子集进行,所以各个基础分类器之间既有差异性又有一定的互补性。采用动态融合方法将多个基础分类器的输出进行有效融合,则可以大幅提高说话人确认系统的性能。
在训练阶段,为了对基础分类器的局部分类能力进行评价,首先对来自大量说话人的开发集语音数据集X进行分析,根据一定的准则将其划分为K个子集S1,S2,...,SK,划分到同一集合中的语音数据之间在某种程度上具有一定的相似性,再用每个基础分类器对各个集合中的语音数据进行测试,统计相应的得分输出,最后将得分平均值作为确定分类器在各个集合上的测试结果置信度的依据。通过这种方式,可以获得基础分类器在各个集合上的分类能力,最终确定融合算法中每个基础分类器在各个集合上的置信度向量w1,w2,...,wQ。每个置信度向量包含K个值,代表该分类器对某一集合上的分类置信度。
结合本文要解决的问题,动态多分类器融合过程可以概括为以下几个步骤:
1)选定合适的开发集语料库,设该语料库包含N个不同的说话人,每个说话人有两条语音数据。在开发集语料中,从每个说话人语音中取出一条组成训练集X1,剩余的作为参照集X2。
2)根据联合因子分析理论,提取开发集语料中所有语音的说话人因子,假设来自训练集的说话人因子序列表示为
3)以Y1作为输入,训练出一个混合成分数目较小的高斯混合模型,表示为λ={wi,μi,Σi},i=1,...,K。其中参数wi、μi和Σi分别代表高斯混合模型中各个高斯成分的权重、均值和协方差。设说话人因子对GMM模型中第i个高斯成分的占有率为当时,将划分到第k个子集Sk中去,通过这种方式,将训练集中的所有说话人因子划分到K个不同的集合中。
4)按照上一步骤中对说话人因子的划分结果,将相应的训练语音也分成K个集合。
5)对于某一集合Sk,将其中的训练语音及其对应的来自于同一说话人的参照集中的语音数据投影到第q个随机子空间中,分别得到训练语音和参照语音的参考向量。
6)计算出训练语音和参照语音参考向量之间的余弦距离,以此作为第q个NLDA分类器的测试得分输出。
7)计算第q个NLDA分类器在集合Sk上的所有测试得分的平均值作为该分类器在集合Sk上的分类置信度。相应的,该基础分类器的局部分类置信度向量可以表示为
8)在多分类器融合阶段,对于某一待测语音,首先按照联合因子分析理论提取其相应的说话人因子,然后再根据训练过程中对开发集数据的划分准则将待测语音数据划分到某一集合Sk中去,最后以各个基础分类器在集合Sk上的分类置信度值作为权重对所有基础分类器的输出进行线性融合。
基础分类器局部分类置信度的确定过程中,假设某些说话人的个性特征之间具有一定的相似性,且这些具有相似性的说话人的语音特征在分布规律上也有一定的相似性,在特征空间中处于某一个局部区域中。本发明中,将不同长度的说话人语音特征向量序列通过联合因子分析技术转换成具有固定长度且去除了部分信道影响的JFA话者超向量。JFA话者超向量在高维特征空间中的分布情况反应了不同说话人个性特征的分布。而本章中采用说话人因子的分布来近似模拟JFA话者超向量的分布情况,这是由于:
1)JFA话者超向量往往具有很高的维度,采用常用的统计数学模型很难对高维向量的分布规律进行准确建模。
2)为了保证不丢失大部分有用信息,将JFA话者超向量投影到非参数线性区分子空间后仍然具有较高的维度。
3)说话人因子相对于上一步骤中的投影后的JFA话者向量来说维度较低,且说话人因子的提取过程也是基于联合因子分析算法的,所以也包含了必要的说话人个性信息,可以反映JFA话者超向量的分布。
从以上内容可以看出,在本发明提出的多分类器融合方法中,根据待测语音数据在说话人因子空间中所处的区域来确定各个基础分类器在得分融合过程中的权重。由于每条待测语音的说话人因子具有不同的分布情况,所以各个基础分类器的权重是随着待测语音的不同而动态变化的。值得说明的是,本发明的多分类器融合算法中,各个基础分类器的融合权重可以在测试之前确定,这种方式大大提高了融合系统的实时性。
3、评测系统性能。
实验数据取自NIST 2008说话人评测数据库,其中训练和测试语音仍选用核心评测任务中的男性电话训练对电话测试部分作为评测数据集来衡量说话人确认系统的性能。UBM的训练数据来自Switchboard II phase 2,Switchboard II phase 3,Switchboard Cellular Part 2以及NIST SRE 2004,2005,2006中的电话语音数据,共有2048个高斯成分。
用以训练非参数子空间区分分析投影矩阵的开发集数据均取自NIST SRE 2004、2005、2006数据库中的电话语音,共包含563个说话人,每个说话人有8条语音数据。
联合因子分析系统中UBM与以上所述相同,说话人空间载荷矩阵的秩为300,本征信道空间载荷矩阵的秩为100,残差载荷矩阵由UBM模型中的各个高斯成分的对角协方差矩阵中的对角线元素拼接而成。
本发明中所采用的主成分分析、类内协方差规整以及非参数线性区分分析投影矩阵的维度分别为:(51×k)×J,(E1+E2)×799,799×550。随机子空间的数目即基础分类器的数目Q设定为10。非参数线性区分分析中,近邻样本的数目设定为4。
经过原始特征空间中的子空间采样后,我们获得了新的特征向量Sih。假设在第一层子空间采样中,我们最终选取了排序后的JFA话者超向量中的前1280个高斯均值向量。但是该特征向量的维度相对于开发集中的训练样本来说仍然很高。所以为了训练出稳定可靠的子空间分类器,需要将新的特征向量进一步投影到低维的PCA子空间,这里设经过PCA降维后的特征向量的维度是J。在进行随机采样之前,为了保证各个基础子空间分类器的性能,首先将含有较多信息量的前E1个主元分量固定下来,随机采样算法仅应用于剩下的J-E1个主元分量,从中随机选取E2个主元分量构成维度为E1+E2的随机子空间。
在第二层采样空间实验中,J的值固定为1200或者1300,该值是通过交叉验证确定的较优值。E1+E2的值固定为800。对于每个组合(E1,E2),我们随机创建了10个子空间,即10个基础分类器。
第一组实验考察了动态自适应融合算法的性能随着聚类数目K而变化的情况。由于聚类方法采用的是GMM算法,且训练数据有限,故K的取值分别设置为8、16、及32。实验结果列出与表1中。
表1动态自适应融合方法实验结果
表1中,当K为8,16,32时,动态自适应融合结果对E1和E2所有组合条件下的EER与minDCF的均值分别为:4.02,2.20;3.89,2.14;4.02,2.20。由此可见当K的取值为12时,融合后的系统性能最佳。原因在于,当聚类数目K的值较小时,不能有效地将相似说话人的特征向量聚集在一起,基础分类器的局部分类能力不能被有效地反映出来,造成其局部分类置信度的估计不够准确;反之,当K的值相对于训练数据的规模来说较大时,用于聚类的GMM模型的复杂度增加,模型参数在估计过程中容易出现过拟合现象,造成基础分类器的局部分类置信度不能被有效估计。第一组实验结果充分表明当K的值为16时,可以使得基础分类器的局部分类置信度的估计更为准确。
第二组实验则对比分析了本发明所提出的动态自适应融合方法(DY)与线性融合算法(LR),以及经典的应用于说话人确认领域中基于Logistic回归算法(LG)的融合效果,其中动态自适应融合方法中聚类数目K=16。
表2不同融合方法的比较
表2中列出了E1和E2在不同组合情况下的三种融合算法的结果,对于每种组合构建出10个基础分类器。从中可以看出,对于每组实验,本发明所提出的动态自适应融合方法均能获得最低的EER值,其次是基于Logistic回归的融合算法,线性融合系统具有最高的EER,性能最差。在minDCF方面,动态自适应融合算法在除第三组实验以外的每组实验中基本都能获得最低的检测代价。特别是在第五组实验中,动态自适应融合的EER为3.76,minDCF为2.08,系统性能达到最好,比基于Logistic回归融合算法的最小EER值相对降低了3.7%,比线性融合相应的最小EER值相对降低了6.6%。这充分表明本文提出的基于随机子空间采样的动态多分类器融合算法的有效性,而且该融合算法适用于任何子空间分类器,具有很好的推广性。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!