语音处理方法及装置与流程
本发明涉及到语音识别领域,特别是涉及到一种语音处理方法及装置。
背景技术:
近年来随着互联网技术、智能硬件的蓬勃发展,语音识别、声纹识别、声源检测等语音智能交互技术开始从实验室走向用户。由于语音识别技术是基于语音的人机交互系统最核心的技术。目前在限定条件下识别率已经达到可用的准确率。所谓限定调节通常是指用户距离麦克风较近,噪声干扰较小。而必须近距离发出语音指令这一条件限制了语音交互的便捷性。
在远讲情况下,由于语音能量会快速衰减,而噪音干扰能量大致不变,会使得识别率迅速下降。另外一个影响识别准确率的因素是,语音指令到达房间墙壁多次反射之后的混响,也会造成实际应用与语音识别训练数据集的不匹配,影响识别率。
噪音主要有两个来源:(1)麦克风信号采集系统自带的信道噪声,信道噪声因麦克风的敏感性而不同,麦克风敏感性越高,通常信道噪声越高;(2)不可忽略的环境噪声干扰,比如电视机、空调噪声等等。相比于噪声,混响由于产生条件更为复杂,更难抑制。并且,噪音和混响一般同时存在,使得混响抑制更加困难。
cn201010224307.1公开了一种语音增强的方法,该方法包括如下步骤:利用判断器判断当前帧是否为纯噪音,如果当前帧是纯噪音且该当前帧的前若干帧均为纯噪音,利用改进谱减法的语音增强算法改进频域信号,反之语音生成模型的增强算法改进频域信号;将处理后的频域信号变换到时间域,进行去加重处理并得到输出信号。该发明的语音增强的方法,大大提高了对残余噪声的衰减,保证了语音可懂度。
然而,该方法解决的是高噪音背景下的除噪问题,并不适用于室内环境远讲情形下的除噪问题。
技术实现要素:
本发明的主要目的为提供一种语音处理方法及装置,在远讲情况下,提高室内采集声音信号的质量。
本发明提出一种语音处理方法,包括以下步骤:
将声音信号从时域变换到频域,获得频域信号,计算所述频域信号的观测信号功率谱密度,并根据所述观测信号功率谱密度估算噪音功率谱密度;
在判断出所述声音信号存在语音活动时,使用自适应kalman滤波处理所述频域信号,获得混响功率谱密度;
根据所述噪音功率谱密度、混响功率谱密度、观测信号功率谱密度计算去除噪音和混响的频域信号,记为优化估算语音频谱;
使用逆傅里叶变换将所述优化估算语音频谱从频域恢复为时域,获得优化后的声音信号。
优选地,所述估算噪音功率谱密度的步骤,包括:
假定前li时间帧没有语音活动,初始化噪音功率谱密度、估算语音频谱、观测信号功率谱密度、先验信噪比、后验信噪比;
从第li+1时间帧开始做迭代计算,更新观测信号功率谱密度,具体为:
φy(k)=αφ′y(k)+(1-α)|y(l,k)|2
其中,α为第一平滑因子,φy(k)为观测信号功率谱密度,φ′y(k)为前一帧的观测信号功率谱密度,y(l,k)为所述频域信号;
计算先验信噪比和后验信噪比:
其中,β为第二平滑因子,γ(k)为先验信噪比,ε(k)为后验信噪比,φv(k)为噪音功率谱密度,
根据所述先验信噪比和后验信噪比,计算噪音功率谱的自适应更新步长:
根据所述自适应更新步长,更新噪音功率谱,具体为:
φv(k)=αv(k)φ′v(k)+(1-αv(k))|y(l,k)|2。
优选地,所述假定前li时间帧没有语音活动,初始化噪音功率谱密度、估算语音频谱、观测信号功率谱密度、先验信噪比、后验信噪比,具体为:
γ(k)=1,ε(k)=κ,k=1,2,…,k
其中,k代表频带整体的数量,κ为第一衰减因子。
优选地,所述α的取值范围为[0.95,0.98)、0.98或(0.98,0.995],所述β的取值范围为[0.6,0.75)、0.75或(0.75,0.9]。
优选地,所述判断出所述声音信号存在语音活动的步骤,包括:
构建多参量的听觉特征,所述参量与所述声音信号、先验信噪比、后验信噪比相关;
使用所述听觉特征中的参量分别与各自对应的听觉阈值比较;
若任一参量大于与其对应的听觉阈值,则判定所述声音信号存在语音活动。
优选地,所述自适应kalman滤波是指用一个前向预测滤波器,对纯净语音频谱进行预测。
优选地,所述使用自适应kalman滤波处理所述频域信号,获得混响功率谱密度的步骤,包括:
初始化预测误差向量,预测向量方差矩阵,预测频谱误差,具体为:
e(k)=0
其中,预测向量方差矩阵pk为维度lg×lg的0矩阵,为预测误差向量gk为维度lg×1的0向量,e(k)为采用当前预测向量获得的预测误差;
更新预测向量方差矩阵的中间量,预测频谱误差的中间量,具体为:
其中,
预测频谱误差平滑,具体为:
e(k)=η|epre|2-(1-η)|epre,o|2
其中,η为平滑系数;
计算kalman增益,并更新pk和gk,具体为:
gk=g′k+kgepre
计算混响功率谱密度,具体为:
其中,φr(k)为混响功率谱密度,φ′r(k)为前一帧的混响功率谱密度。
优选地,所述根据所述噪音功率谱密度、混响功率谱密度、观测信号功率谱密度计算去除噪音和混响的频域信号,记为优化估算语音频谱的步骤,包括:
根据维纳滤波构建衰减因子,输出估算语音频谱,计算如下:
其中,ζ(k)为第二衰减因子,φy(k)为观测信号功率谱密度,φv(k)为噪音功率谱密度,φr(k)为混响功率谱密度,y(l,k)为频域信号。
优选地,所述使用逆傅里叶变换将所述优化估算语音频谱从频域恢复为时域,获得优化后的声音信号,具体为:
本发明还提供了一种语音处理装置,包括:
第一变换模块,用于将声音信号从时域变换到频域,获得频域信号;
第一计算模块,用于计算所述频域信号的观测信号功率谱密度,并根据观测信号功率谱密度估算噪音功率谱密度;
第二计算模块,用于在判断出所述声音信号存在语音活动时,使用自适应kalman滤波处理所述频域信号,获得混响功率谱密度;
第三计算模块,用于根据所述噪音功率谱密度、混响功率谱密度、观测信号功率谱密度计算去除噪音和混响的频域信号,记为优化估算语音频谱;
第二变换模块,使用逆傅里叶变换将所述优化估算语音频谱从频域恢复为时域,获得优化后的声音信号。
本发明提出的一种语音处理方法及装置,其方法如下:首先将声音信号转化成频域信号,通过计算频域信号的信噪比获得噪音功率谱的自适应更新步长,根据步长更新噪音功率谱密度;然后检测声音信号中是否存在语音活动,在存在语音活动的情况下,使用自适应kalman滤波处理频域信号,获得混响功率谱密度;在确定噪音功率谱密度和混响功率谱密度之后,计算优化估算语音频谱,最后将优化估算语音频谱经傅里叶逆变换,还原出优化后的声音信号。本发明能有效地优化远讲情况下采集的声音信号质量,提高语音识别的识别率。
附图说明
图1为本发明语音处理方法一实施例的流程示意图;
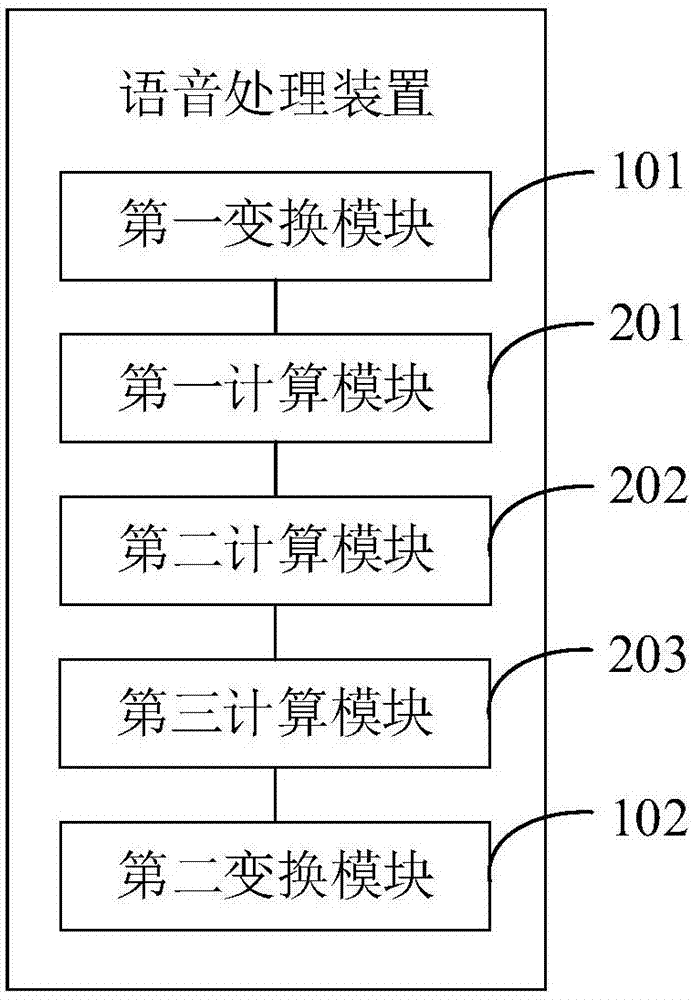
图2为本发明语音处理装置一实施例的结构示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明所指的声音信号,是指数字音频数据,即先通过声波转换电路将声波转换为模拟音频信号,再通过模拟数字转换器将上述模拟音频信号转换得到的数字音频数据。
参照图1,本发明提出一种语音处理方法,包括以下步骤:
s10、将声音信号从时域变换到频域,获得频域信号,计算所述频域信号的观测信号功率谱密度,并根据所述观测信号功率谱密度估算噪音功率谱密度;
s20、在判断出所述声音信号存在语音活动时,使用自适应kalman滤波处理所述频域信号,获得混响功率谱密度;
s30、根据所述噪音功率谱密度、混响功率谱密度、观测信号功率谱密度计算去除噪音和混响的频域信号,记为优化估算语音频谱;
s40、使用逆傅里叶变换将所述优化估算语音频谱从频域恢复为时域,获得优化后的声音信号。
在步骤s10中,对声音信号进行傅里叶变换后,估测声音信号中的噪音值,可用常规的技术手段计算声音信号的先验信噪比、后验信噪比,并根据上述先验信噪比、后验信噪比计算噪音功率谱密度的自适应更新步长。在获得步长后,更新噪音功率谱密度。可设定在起始阶段的声音信号不存在语音活动,因而获取到的观察信号功率谱密度等于噪音功率谱密度。
在步骤s20中,在经过语音检测处理,分检出需要处理的包含语音信息的声音信号后,采用自适应kalman滤波处理包含语音信息的声音信号。kalman自适应增强是假定用一个长为lg的前向预测滤波器,对纯净语音频谱进行预测。由于语音信号可以用一个自回归模型来很好的表达,因此计算出来的混响功率谱密度实际上也十分接近实际值。
在步骤s30中,在计算出噪音功率谱密度和混响功率谱密度后,可根据维纳滤波构建衰减因子,然后求解出优化估算语音频谱。
在步骤s40中,当求解出优化估算语音频谱后,将上述优化估算语音频谱经逆傅里叶变换,便可获得优化后的声音信号。经处理后的声音信号,再通过语音识别引擎对声音信号包含的内容进行识别,可大幅度地提高声音识别的准确性。
以下为本发明语音优化方法具体的计算过程。
首先是背景噪音的估计,噪声能量估计的准确程度直接影响后续语音检测的效果。本发明实施例采用固定噪声估计结合噪声自适应更新的方式来保证噪音估计的稳定性和精确性。初始化及具体计算流程如下所示:
取缓冲区数据,并加窗做fft变换,把时域信号变换到频谱域:
假设混合语音数据为y(t),其中x(t)为带混响语音信号,v(t)为背景噪声,h(τ)为混响冲击响应信号,s(t-τ)为无混响语音信号。fft变换(傅里叶变换)如下所示:
其中,w(t)为长度512的汉宁窗,l为时间帧坐标,k为频率坐标。
对前li时间帧假设没有语音活动,并做如下初始化:
γ(k)=1,ε(k)=κ,k=1,2,…,k
其中,k代表频带整体的数量,φv(k)代表噪音信号的功率谱密度,φy(k)代表观测信号的功率谱密度,γ(k)为先验信噪比,ε(k)为后验信噪比,
从第lt+1时间帧开始做迭代计算,计算流程如下所示:
更新观测信号功率谱密度估计值,即根据前一帧的结果,平滑得到下一帧的计算结果:
φ′y(k)=αφy(k)+(1-α)|y(l,k)|2
其中,α为平滑因子,取值范围为推荐为0.95~0.995,本实施例优选0.98作为平滑阈值。
计算先验信噪比和后验信噪比
其中,β为平滑因子,β为取值范围为0.6~0.9,本实施例优选取值为0.75。max函数表示选择两个变量中的最大值。
以上只是先验信噪比和后验信噪比的一种优选的计算方式,任何按照上述方法进行适当的变形分解,再进行求解的方式,也应属于本发明的保护范围之内。
根据先验后验信噪比计算噪音功率谱自适应更新步长:
即采用固定步长加上自适应步长的方式,实现整体更新。
根据步长,更新噪音功率谱,基本原则是,如果语音越少,则噪音功率谱更新的步长越大,保证噪音估计的准确性;反之,则采用较慢的步长,以避免语音信号参与噪音功率谱的迭代更新:
φv(k)=αv(k)φ′v(k)+(1-αv(k))|y(l,k)|2。
上式输出即为噪音功率谱更新结果,用以下一帧的噪音更新和作为参数参与语音检测过程。
以下为语音检测的具体过程。
在准确估算出背景噪音参数之后,便可根据背景噪音参数构建听觉特征的。在获得听觉特征之后,将当前帧的听觉特征与设定的听觉阈值比较,便可判断当前帧是否出现语音活动。
语音活动检测主要是为了检测出语音活动的区域,在非语音活动区域,停止对语音的优化处理,减少功耗;在语音活动区域,则可减少噪音干扰,提高语音优化的效果。
在提取当前帧的听觉特征之前,有一初始化过程,具体如下:
对特征缓冲矩阵,特征阈值,语音检测结果缓冲区进行初始化,特征缓冲区矩阵由li个3维度列向量构成,以公式表示如下:
q(1:li)=0
θt(1)=fb(1,1)
θt(2)=fb(2,1)
θt(3)=fb(3,1)
其中,fb为听觉特征缓冲区,q为语音活动检测结果缓冲区,θt为听觉特征阈值缓冲区,即分别用先验信噪比、后验信噪比和时域信号用以最终的语音活动检测。在听觉特征计算中,lw代表窗长,lt代表起始样本点,起始样本点取值范围通常在5~20之间,本实施例设定为10。
从第lt+1时间帧开始,计算当前帧听觉特征如下所示:
根据当前帧听觉特征计算结果,更新特征缓冲区和特征阈值,即把缓冲区内时间最久的数据踢出缓冲区,把当前帧数据放入缓冲区:
并求取各维度参数对应的听觉阈值:
当前听觉特征与听觉阈值进行对比,根据对比结果确定语音检测的结果,具体计算如下所示:
q(i)为所述听觉特征的维度参数的得分,qframe为语音检查的判断结果,结果为1贝4表明当前帧存在语音,结果为0则表明当前帧不存在语音。
更新语音检测结果缓冲区,同样把缓冲区内时间最久的数据踢出缓冲区,加入当前帧判断结果,并计算缓冲区内平均的语音检测结果:
q=[q′(:,2:lb);qframe]
然后,计算语音检测结果缓冲区内检测结果的统计值,在此处采用的是计算检测结果的总和,具体计算如下:
由于语音通常是连续出现的,对比qm与固定阈值δli,如果小于阈值,表明当前缓冲区内语音存在帧为误检,当前缓冲区内没有语音,更新特征阈值并把语音频谱估计结果设为一个极小值,计算如下所示:
同时,更新估算语音频谱
δ取值范围为0.1~0.3,本项发明取值为0.15。若无误检,表明当前缓冲区内有语音出现,可对该声音信号继续优化处理。
kalman自适应增强是假定用一个长为lg的前向预测滤波器,对纯净语音频谱进行预测,通常lg<li。在本项发明中,这两个参数分别设置为lg=15,li=25。由于语音信号可以用一个自回归模型来很好的表达,预测的误差可以理解为混响分量。基于最小均方误差准则,滤波器更新的自适应过程如下所示:
在前li帧进行预测误差向量,预测向量方差矩阵,预测误差进行初始化,初始化过程如下所示:
e(k)=0
其中,预测向量方差矩阵pk为维度lg×lg的0矩阵,为预测误差向量gk为维度lg×1的0向量,e(k)为采用当前预测向量获得的预测误差。
从li+1帧开始,如果语音检测结果表明存在语音活动执行如下自适应更新过程:
(1.1)更新预测误差,包括预测误差向量和预测频谱误差,更新过程如下所示:
其中,
(1.2)预测频谱误差平滑,使得误差估计更加平滑,具体流程如下所示:
e(k)=η|epre|2-(1-η)|epre,o|2
其中,η为平滑系数取值范围在0.6~0.9之间,本项发明取值为0.75。
(1.3)kalman增益计算,更新预测向量,更新过程如下所示:
gk=g′k+kgepre
(1.4)混响功率谱密度更新,更新过程如下所示:
该混响功率谱密度与观测信号功率谱密度采用同一个平滑系数α。φ′r(k)为前一帧的混响功率谱密度。混响功率谱密度的初始设置值为0。
(1.5)根据维纳滤波构建衰减因子,输出估算语音频谱,计算如下:
该频谱估计值既用来在下一步恢复时域信号,又用于第一步参与后验信噪比的计算。
(1.6)循环执行1.1-1.5至所有频带更新完毕,采用逆傅里叶变换恢复时域信号,计算流程如下所示:
恢复出时域信号之后,发送到后续应用终端,比如通讯设备或者语音识别引擎,实现噪声、混响联合抑制。
参照图2,本发明还提出了一种语音处理装置,包括:
第一变换模块101,用于将声音信号从时域变换到频域,获得频域信号;
第一计算模块201,用于计算所述频域信号的观测信号功率谱密度,并根据所述观测信号功率谱密度估算噪音功率谱密度;
第二计算模块202,用于在判断出所述声音信号存在语音活动时,使用自适应kalman滤波处理所述频域信号,获得混响功率谱密度;
第三计算模块203,用于根据所述噪音功率谱密度、混响功率谱密度、观测信号功率谱密度计算去除噪音和混响的频域信号,记为优化估算语音频谱;
第二变换模块102,使用逆傅里叶变换将所述优化估算语音频谱从频域恢复为时域,获得优化后的声音信号。
优选地,所述第一计算模块201包括估算噪音功率谱密度单元,用于估算噪音功率谱密度。所述估算噪音功率谱密度单元执行以下流程:
假定前li时间帧没有语音活动,初始化噪音功率谱密度、估算语音频谱、观测信号功率谱密度、先验信噪比、后验信噪比;
从第li+1时间帧开始做迭代计算,更新观测信号功率谱密度,具体为:
φy(k)=αφ′y(k)+(1-α)|y(l,k)|2
其中,α为第一平滑因子,φy(k)为观测信号功率谱密度,φ′y(k)为前一帧的观测信号功率谱密度,y(l,k)为所述频域信号;
计算先验信噪比和后验信噪比:
其中,β为第二平滑因子,γ(k)为先验信噪比,ε(k)为后验信噪比,φv(k)为噪音功率谱密度,
根据所述先验信噪比和后验信噪比,计算噪音功率谱的自适应更新步长:
根据所述自适应更新步长,更新噪音功率谱,具体为:
φv(k)=αv(k)φ′v(k)+(1-αv(k))|y(l,k)|2。
优选地,所述估算噪音功率谱密度单元包括初始化子单元,用于初始化噪音功率谱密度、估算语音频谱、观测信号功率谱密度、先验信噪比、后验信噪比。所述初始化子单元执行以下流程:
γ(k)=1,ε(k)=κ,k=1,2,…,k
其中,k代表频带整体的数量,κ为第一衰减因子。
优选地,所述α的取值范围为[0.95,0.98)、0.98或(0.98,0.995],所述β的取值范围为[0.6,0.75)、0.75或(0.75,0.9]。
优选地,还包括语音判断模块,用于判断所述声音信号是否存在语音活动,语音判断模块执行以下流程:
构建多参量的听觉特征,所述参量与所述声音信号、先验信噪比、后验信噪比相关;
使用所述听觉特征中的参量分别与各自对应的听觉阈值比较;
若任一参量大于与其对应的听觉阈值,则判定所述声音信号存在语音活动。
优选地,所述自适应kalman滤波是指用一个长为lg的前向预测滤波器,对纯净语音频谱进行预测。
优选地,所述第二计算模块202执行以下流程:
初始化预测误差向量,预测向量方差矩阵,预测频谱误差,具体为:
e(k)=0
其中,预测向量方差矩阵pk为维度lg×lg的0矩阵,为预测误差向量gk为维度lg×1的0向量,e(k)为采用当前预测向量获得的预测误差;
更新预测向量方差矩阵的中间量,预测频谱误差的中间量,具体为:
其中,
预测频谱误差平滑,具体为:
e(k)=η|epre|2一(1-η)|epre,o|2
其中,η为平滑系数;
计算kalman增益,并更新pk和gk,具体为:
gk=g′k+kgepre
计算混响功率谱密度,具体为:
其中,φr(k)为混响功率谱密度,φ′r(k)为前一帧的混响功率谱密度。
优选地,所述第三计算模块203执行以下流程:
根据维纳滤波构建衰减因子,输出估算语音频谱,计算如下:
其中,ζ(k)为第二衰减因子,φy(k)为观测信号功率谱密度,φv(k)为噪音功率谱密度,φr(k)为混响功率谱密度,y(l,k)为频域信号。
优选地,所述第二变换模块102,用于使用逆傅里叶变换将所述优化估算语音频谱从频域恢复为时域,获得优化后的声音信号。所述优化后的声音信号可通过以下公式求得:
本发明可以用于辅助应用于家居环境下的语音指令识别。在家居环境下,用户距离麦克风大约为1米至3米,会受到家庭噪声和墙壁混响的影响,识别率会迅速下降。本发明提出的语音处理方法与装置,可以优化语音质量。经实验证明,在距离麦克风2米左右,输入信噪比10db左右,识别率可以从30%提高到65%,当增加噪声至20db,识别率从10%提高至50%左右。
本发明提出的一种语音处理方法及装置,其方法如下:首先将声音信号转化成频域信号,通过计算频域信号的信噪比获得噪音功率谱的自适应更新步长,根据步长更新噪音功率谱密度;然后检测声音信号中是否存在语音活动,在存在语音活动的情况下,使用自适应kalman滤波处理频域信号,获得混响功率谱密度;在确定噪音功率谱密度和混响功率谱密度之后,计算优化估算语音频谱,最后将优化估算语音频谱经傅里叶逆变换,还原出优化后的声音信号。本发明能有效地优化远讲情况下采集的声音信号质量,提高语音识别的识别率。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!