一种情感识别方法和情感识别系统与流程
本发明实施例涉及通信技术领域,具体涉及一种情感识别方法和情感识别系统。
背景技术:
在人与人之间的交流中,语言是最自然和重要的手段之一。说话者的言语中夹带的情感会对周围人的情绪产生极大的影响,其中,情感包括:正面和负面,尤其是服务人员,例如,在公交车、敬老院或者医院等公共场合,若服务人员态度恶劣,语气傲慢,语言粗鄙,即情感为负面,就会对被服务人员造成不好的影响,不利于社会和谐和提高幸福指数。
经发明人研究发现,目前没有一种有效的技术手段能够通过服务人员的言语判断出其对应的情感,以对其监督提高服务水平。
技术实现要素:
为了解决上述技术问题,本发明实施例提供了一种情感识别方法和情感识别系统,能够通过语音信号识别出对应的情感。
在一个方面,本发明实施例提供了一种情感识别方法,包括:
获取当前语音信号;
提取当前语音信号的语音特征,所述语音特征包括:声学特征和文本特征;
根据所述语音特征和预设深度模型,识别所述当前语音信号对应的情感类型,所述情感类型包括:正面、中性和负面。
可选地,所述提取当前语音信号的语音特征之前,所述方法还包括:
对所述当前语音信号进行预处理。
可选地,所述识别所述当前语音信号对应的情感类型之后,所述方法还包括:
根据所述情感类型,激活对应的预设应对方案。
可选地,所述声学特征包括:基频、时长、能量和频谱。
可选地,所述根据所述语音特征和预设深度模型,识别所述当前语音信号对应的情感类型包括:
根据声学特征和文本特征,获得用于情感识别的声学特征信息和文本特征信息;
根据所述声学特征信息,获得k个声学特征向量;
根据k个声学特征向量和文本特征信息,获得k个文本特征向量;
根据k个声学特征向量、k个文本特征向量和预设深度模型,识别当前语音信号的情感类型。
可选地,所述根据声学特征和文本特征,获得用于情感识别的声学特征信息和文本特征信息包括:
将声学特征和文本特征分别转化为对应的向量;
将声学特征对应的向量和文本特征对应的向量分别输入卷积神经网络,获得用于情感识别的声学特征信息和文本特征信息。
可选地,所述根据所述声学特征信息,获得k个声学特征向量包括:
将所述声学特征信息池化,获得k个声学特征向量;
所述根据k个声学特征向量和文本特征信息,获得k个文本特征向量包括:
根据k个声学特征向量的均值对文本特征信息采用聚焦机制聚焦;
将聚焦后的文本特征信息池化,获得k个文本特征向量。
另一方面,本发明实施例还提供一种情感识别系统,包括:
语音获取模块,被配置为获取当前语音信号;
特征提取模块,被配置为提取当前语音信号的语音特征,所述语音特征包括:声学特征和文本特征;
情感识别模块,被配置为根据所述语音特征和预设深度模型,识别所述当前语音信号对应的情感类型,所述情感类型包括:正面、中性和负面。
可选地,所述系统还包括:信号预处理模块和激活模块;
所述信号预处理模块,被配置为对所述当前语音信号进行预处理;
所述激活模块,被配置为根据所述情感类型,激活对应的预设应对方案。
可选地,所述情感识别模块包括:
第一获得单元,被配置为根据声学特征和文本特征,获得用于情感识别的声学特征信息和文本特征信息,具体包括:将声学特征和文本特征分别转化为对应的向量;将声学特征对应的向量和文本特征对应的向量分别输入卷积神经网络,获得用于情感识别的声学特征信息和文本特征信息;所述声学特征包括:基频、时长、能量和频谱;
第二获得单元,被配置为根据所述声学特征信息,获得k个声学特征向量,具体包括:将所述声学特征信息池化,获得k个声学特征向量;还被配置为根据k个声学特征向量和文本特征信息,获得k个文本特征向量,具体包括:根据k个声学特征向量的均值对文本特征信息采用聚焦机制聚焦;将聚焦后的文本特征信息池化,获得k个文本特征向量;
情感识别单元,被配置为根据k个声学特征向量、k个文本特征向量和预设深度模型,识别当前语音信号的情感类型。
本发明实施例提供一种情感识别方法和情感识别系统,其中,该方法包括:获取当前语音信号;提取当前语音信号的语音特征,语音特征包括:声学特征和文本特征;根据所述语音特征和预设深度模型,识别所述当前语音信号对应的情感类型,所述情感类型包括:正面、中性和负面,本发明的技术方案能够通过语音信号识别出对应的情感类型,以对服务人员进行监督提高服务水平。
当然,实施本发明的任一产品或方法并不一定需要同时达到以上所述的所有优点。本发明的其它特征和优点将在随后的说明书实施例中阐述,并且,部分地从说明书实施例中变得显而易见,或者通过实施本发明而了解。本发明实施例的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
附图用来提供对本发明技术方案的进一步理解,并且构成说明书的一部分,与本申请的实施例一起用于解释本发明的技术方案,并不构成对本发明技术方案的限制。
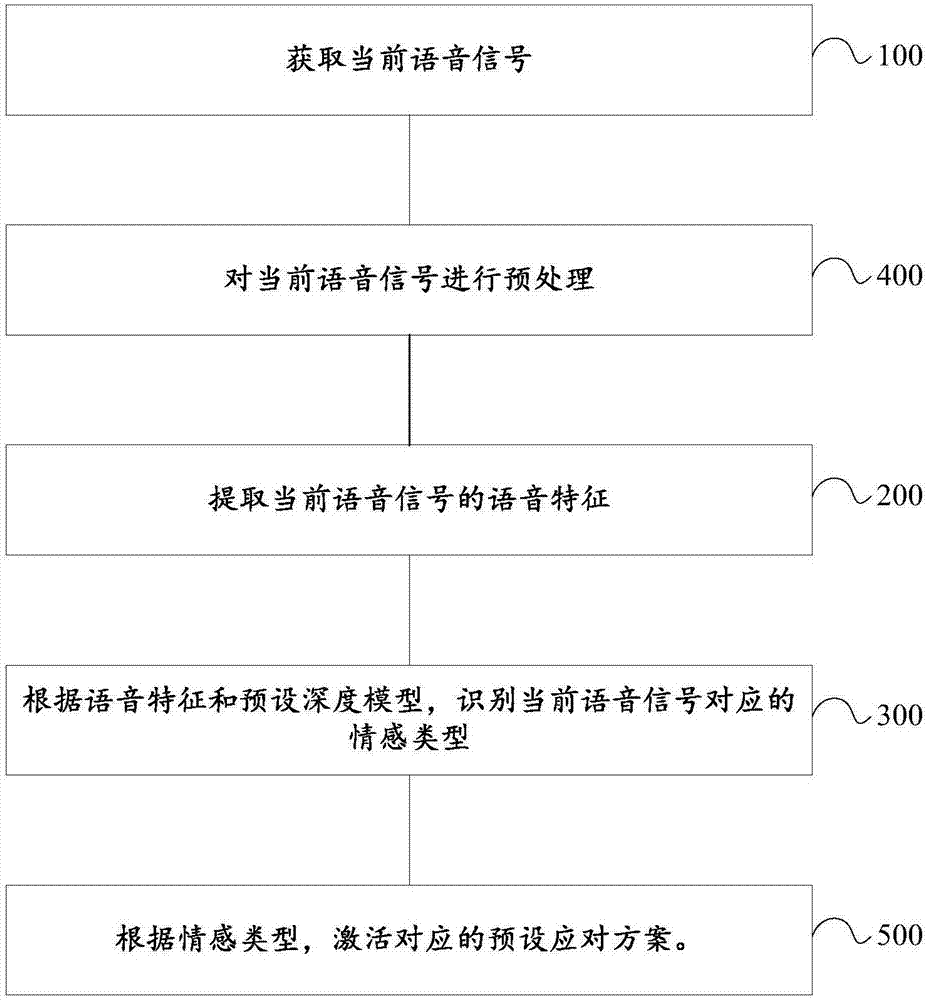
图1为本发明实施例提供的情感识别方法的一个流程图;
图2为本发明实施例提供的情感识别方法的另一流程图;
图3为本发明实施例提供的步骤300的流程图;
图4为本发明实施例提供的情感识别系统的一个结构框图;
图5为本发明实施例提供的情感识别系统的另一结构框图;
图6为本发明实施例提供的情感识别模块的结构框图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,下文中将结合附图对本发明的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
为了说明本发明实施例所述的技术方案,下面通过具体实施例来进行说明。
实施例一
图1为本发明实施例提供的情感识别方法的一个流程图,如图1所示,本发明实施例提供的情感识别方法具体包括以下步骤:
步骤100、获取当前语音信号。
具体的,步骤100通过麦克风或者麦克风阵列获取语音信号。
步骤200、提取当前语音信号的语音特征。
其中,语音特征包括:声学特征和文本特征。
可选地,声学特征包括:基频、时长、能量和频谱,其中,基频决定音调高低,通过自相关算法提取基频特征;时长与语速相关,当前语音信号中的无声信息对于情感识别也是有价值的,通过visualspeech工具提取时长特征;能量与振幅有关,可以通过现有的技术提取能量特征和频谱特征。
可选地,文本特征即为当前语音信号中的文本信息,通过语音识别技术例如科大讯飞的auto-speechrecognition提取文本特征。
步骤300、根据语音特征和预设深度模型,识别当前语音信号对应的情感类型。
其中,情感类型包括:正面、中性和负面,需要说明的是,正面的情感类型可以使被服务人员愉悦,中性的情感类型不会对被服务人员的情绪产生影响,而负面的情感类型就会使被服务人员觉得不舒服。对于同一句话,如“你是傻瓜”,可能是一个人在调侃朋友,也有可能是嘲笑敌手,情感可能正面也可能负面。
需要说明的是,预设深度模型经过样本数据库进行大量训练,使得识别出来的情感类型的准确率较高。
可选地,本发明实施例提供的情感识别方法可以应用于公交车、敬老院、医院等公共场合。
本发明实施例提供的情感识别方法,包括:获取当前语音信号;提取当前语音信号的语音特征,语音特征包括:声学特征和文本特征;根据语音特征和预设深度模型,识别当前语音信号对应的情感类型,情感类型包括:正面、中性和负面,本发明的技术方案能够通过语音信号识别出对应的情感类型,以对服务人员进行监督提高服务水平。
可选地,图2为本发明实施例提供的情感识别方法的另一流程图,如图2所示,步骤200之前,本发明实施例提供的情感识别方法还包括:
步骤400、对当前语音信号进行预处理。
具体的,步骤400中的预处理包括:消除环境噪声、加强有用信号或者分割当前语音信号等,需要说明的是,分割当前语音信号可以通过对信号加窗分帧,比如用窗长25ms、窗移10ms的汉明窗(即每一帧语音时长25ms,窗格移动步长10ms)来实现。
可选地,步骤300之后,本发明实施例提供的情感识别方法还包括:
步骤500、根据情感类型,激活对应的预设应对方案。
具体的,步骤500包括:在情感类型为正面或中性的状态下,鼓励服务人员继续保持,在情感类型为负面的状态下,激活预设的应对方案,其中,应对方案包括但不限于以下几种:(1)及时报警,提醒提醒服务人员注意服务态度,可选地,报警包括文字显示、蜂鸣、语音播报等;(2)将负面情感对应的当前语音信号收集存在云端,供服务机构做服务质量评估和改进;(3)定时消息推送,每天下班后将服务人员的服务质量信息推送到他的手机上,让他综合了解自已当天服务情况,以便进一步提高服务水平。
可选地,图3为本发明实施例提供的步骤300的流程图,如图3所示,步骤300包括:
步骤301、根据声学特征和文本特征,获得用于情感识别的声学特征信息和文本特征信息。
具体的,步骤301包括:将声学特征和文本特征分别转化为对应的向量;将声学特征对应的向量和文本特征对应的向量分别输入卷积神经网络,获得用于情感识别的声学特征信息和文本特征信息。
步骤302、根据声学特征信息,获得k个声学特征向量。
具体的,步骤302包括:将声学特征信息池化,获得k个声学特征向量。
步骤303、根据k个声学特征向量和文本特征信息,获得k个文本特征向量。
具体的,步骤303包括:根据k个声学特征向量的均值对文本特征信息采用聚焦机制聚焦;将聚焦后的文本特征信息池化,获得k个文本特征向量。
需要说明的是,采用聚焦机制为不同的文本分配不同权重,例如给不文明的字词分配更高的权重,影响情感的判断,通俗的说,例如比如卷积神经输出的特征表示当前说话者的态度很蛮横,卷积神经网络的聚焦机制会给“不文明的字词”(如混蛋、傻子等)分配更高的权重,比如卷积神经输出的特征表示当前说话者的态度很平和,卷积神经网络的聚焦机制就不会给“不文明的字词”(如混蛋、傻子等)分配更高的权重。
具体的,文本特征信息的聚焦机制如下:为文本特征信息分配权重,其中,权重是根据k个声学特征向量决定的。
特别地,假如在t时刻,文本特征信息为ha(t),声学特征信息为oq,每个文本特征信息经聚焦机制的聚焦的作用后变为
ma,q(t)=tanh(wamha(t)+wqmoq)
其中,wam,wqm,wms是聚焦参数,sa,q(t)是权重,
步骤304、根据k个声学特征向量、k个文本特征向量和预设深度模型,识别当前语音信号的情感类型。
具体的,步骤304具体包括:对k个语音特征向量和k个文本特征向量进行逻辑回归,根据逻辑回归后的k个语音特征向量和k个文本特征向量以及深度模型,识别当前语音信号的情感类型。
下面通过具体说明本发明实施例的工作原理:通过麦克风或者麦克风阵列获得当前语音信号;对当前语音信息进行预处理;提取当前语音信号的声学特征并通过语音识别技术提取当前语音信号的文本特征,将声学特征和文本特征分别转化为对应的向量;将声学特征对应的向量和文本特征对应的向量分别输入卷积神经网络,获得用于情感识别的声学特征信息和文本特征信息;将声学特征信息池化,获得k个声学特征向量;根据k个声学特征向量的均值对文本特征信息采用聚焦机制聚焦;将聚焦后的文本特征信息池化,获得k个文本特征向量;对k个语音特征向量和k个文本特征向量进行逻辑回归,根据逻辑回归后的k个语音特征向量和k个文本特征向量以及深度模型,识别当前语音信号的情感类型;根据情感类型,激活对应的预设应对方案。
实施例二
基于上述实施例的发明构思,图4为本发明实施例提供的情感识别系统的一个结构示意图,如图4所示,本发明实施例提供的情感识别系统包括:语音获取模块10、特征提取模块20和情感识别模块30。
在本实施例中,语音获取模块10,被配置为获取当前语音信号;特征提取模块20,被配置为提取当前语音信号的语音特征;情感识别模块30,被配置为根据语音特征和预设深度模型,识别当前语音信号对应的情感类型。
可选地,声学特征包括:基频、时长、能量和频谱,其中,基频决定音调高低,通过自相关算法提取基频特征;时长与语速相关,当前语音信号中的无声信息对于情感识别也是有价值的,通过visualspeech工具提取时长特征;能量与振幅有关,可以通过现有的技术提取能量特征和频谱特征。
可选地,文本特征即为当前语音信号中的文本信息,通过语音识别技术例如科大讯飞的auto-speechrecognition提取文本特征。
其中,情感类型包括:正面、中性和负面,需要说明的是,正面的情感类型可以使被服务人员愉悦,中性的情感类型不会对被服务人员的情绪产生影响,而负面的情感类型就会使被服务人员觉得不舒服。对于同一句话,如“你是傻瓜”,可能是一个人在调侃朋友,也有可能是嘲笑敌手,情感可能正面也可能负面。
可选地,本发明实施例提供的情感识别系统可以应用于公交车、敬老院、医院等公共场合。
本发明实施例提供的情感识别系统,包括:语音获取模块,被配置为获取当前语音信号;特征提取模块被配置为提取当前语音信号的语音特征,语音特征包括:声学特征和文本特征;情感识别模块被配置为根据语音特征和预设深度模型,识别当前语音信号对应的情感类型,情感类型包括:正面、中性和负面,本发明的技术方案能够通过语音信号识别出对应的情感类型,以对服务人员进行监督提高服务水平。
可选地,图5为本发明实施例提供的情感识别系统的另一结构示意图,如图5所示,本发明实施例提供的系统还包括:信号预处理模块40和激活模块50。
信号预处理模块40,被配置为对当前语音信号进行预处理。
具体的,预处理包括:消除环境噪声、加强有用信号或者分割当前语音信号等,需要说明的是,分割当前语音信号可以通过对信号加窗分帧,比如用窗长25ms、窗移10ms的汉明窗(即每一帧语音时长25ms,窗格移动步长10ms)来实现。
激活模块50,被配置为根据情感类型,激活对应的预设应对方案。
具体的,激活模块50在情感类型为正面或中性的状态下,鼓励服务人员继续保持,在情感类型为负面的状态下,激活预设的应对方案,其中,应对方案包括但不限于以下几种:(1)及时报警,提醒提醒服务人员注意服务态度,可选地,报警包括文字显示、蜂鸣、语音播报等;(2)将负面情感对应的当前语音信号收集存在云端,供服务机构做服务质量评估和改进;(3)定时消息推送,每天下班后将服务人员的服务质量信息推送到他的手机上,让他综合了解自已当天服务情况,以便进一步提高服务水平。
可选地,图6为本发明实施例提供的情感识别模块的结构示意图,如图6所示,情感识别模块包括:第一获得单元31、第二获得单元32和情感识别单元33。
第一获得单元31,被配置为根据声学特征和文本特征,获得用于情感识别的声学特征信息和文本特征信息,具体包括:将声学特征和文本特征分别转化为对应的向量;将声学特征对应的向量和文本特征对应的向量分别输入卷积神经网络,获得用于情感识别的声学特征信息和文本特征信息;声学特征包括:;
第二获得单元31,被配置为根据声学特征信息,获得k个声学特征向量,具体包括:将声学特征信息池化,获得k个声学特征向量;还被配置为根据k个声学特征向量和文本特征信息,获得k个文本特征向量,具体包括:根据k个声学特征向量的均值对文本特征信息采用聚焦机制聚焦;将聚焦后的文本特征信息池化,获得k个文本特征向量;
情感识别单元33,被配置为根据k个声学特征向量、k个文本特征向量和预设深度模型,识别当前语音信号的情感类型。
本领域技术人员可以理解为上述实施例二包括的各个模块或单元只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。
本领域普通技术人员还可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序来执行相关的硬件来完成,所述的程序可以在存储于一计算机可读取存储介质中,所述的存储介质,包括:rom/ram、磁盘、光盘等。
虽然本发明所揭露的实施方式如上,但所述的内容仅为便于理解本发明而采用的实施方式,并非用以限定本发明。任何本发明所属领域内的技术人员,在不脱离本发明所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本发明的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!