基于卷积神经网络与随机森林分类的声音场景识别方法与流程
本发明涉及一种基于卷积神经网络与随机森林分类的声音场景识别方法。
背景技术:
声音场景识别,就是通过对音频信号进行分析,实现对声音场景的感知。作为分析环境信息的关键环节之一,它在场景识别,前景、背景声音识别和分离等方面有着广泛的应用。近年来,已经有相关研究将声音场景识别用来提升终端对情景的自主感知能力[1][2][3]。如手机检测场景声音,实现在会议情景下自动静音;在吵杂的室外环境加大通话和铃声音量;自动驾驶系统通过周围的环境声音来分析场景并实现安全驾驶等。
对于声音场景的识别,一般首先提取声谱特征或Mel频率倒谱系数(Mel-frequency cepstral coefficients,MFCC)等特征,然后利用支持向量机(SupportVectorMachine,SVM),高斯混合模型(GaussianMixture Model,GMM),深度神经网络(DeepNeuralNetworks,DNN)以及卷积神经网络(ConvolutionalNeuralNetworks,CNN)等分类器进行建模和分类[4]。近期典型的有:Kong等人[5]抽取场景声音的Mel声谱特征结合DNN实现对场景的分类。Benjamin等人[6]抽取场景声音的短时MFCC特征,通过GMM和最大后验估计学习特征分布将其转化为低维特征,使用SVM进行分类。Valenti等人[7]对IEEE DCASE2016所规定使用的声音场景数据库[8]中的场景声音进行不同长度的分割,然后提取了Mel能量谱,利用CNN进行声音场景识别。Bae等人[9]将CNN和长短时记忆(Long Short-TermMemory,LSTM)进行结构上的联合特征提取,再使用DNN进行进一步对声音场景分类。Lidy等人[10]使用Constant-Q transform(CQT)生成场景声音相应的声谱图,然后用双CNN并行的方式对声音场景进行建模和分类等。其中,Valenti[7]与Bae[9]等人结合CNN的方法取得了较高的识别率。
然而,基于CNN的相关方法中有以下缺点:1)识别效果依赖于设置分割的长度,长度不同引起的识别率变化将导致CNN模型不稳定,且在新数据集上需要多次调整分割参数,产生的效果带有一定偶然性。2)进行复杂结构的神经网络联合加剧模型的复杂度,使得模型难以训练。
针对这些缺点,本文根据IEEE DCASE2016中关于声音场景分类问题,提出卷积神经网络与随机森林结合的识别方法,使用随机森林对CNN中间特征进行识别。
技术实现要素:
本发明的目的在于提供一种基于卷积神经网络与随机森林分类的声音场景识别方法,该方法在IEEEDCASE2016声音场景评估数据集上的识别率既优于Mel频率倒谱系数特征结合高斯混合模型(MFCC-GMM)的基准方法,也优于现有的相关识别方法。
为实现上述目的,本发明的技术方案是:一种基于卷积神经网络与随机森林分类的声音场景识别方法,首先,声音场景通过Mel滤波器生成Mel能量谱及其片段样本集;然后,利用片段样本集对CNN进行两阶段训练,截断全连接层的特征输出,得到片段样本集的CNN特征;最后,用随机森林对片段样本集的CNN特征进行分类,得到最终识别结果。
在本发明一实施例中,所述声音场景通过Mel滤波器生成Mel能量谱及其片段样本集,即通过对各种不同长度的场景声音样本提取Mel能量谱,通过分片采样,得到大小一致的Mel能量谱片段作为CNN模型的训练样本。
在本发明一实施例中,所述声音场景通过Mel滤波器生成Mel能量谱及其片段样本集的具体实现方式如下,
步骤S1、场景声音信号s(n)经过短时傅里叶变换得到短时幅度谱|S(t,f)|
其中,t为帧索引,f为频率,w(n)为分析窗函数;
步骤S2、由短时幅度谱|S(t,f)|得到信号s(n)的能量密度函数P(t,f)
P(t,f)=S(t,f)×conj(S(t,f))=|S(t,f)|2 (2)
其中,conj为求共轭复数函数;
步骤S3、使用Mel滤波器组对能量密度函数P(t,f)进行滤波得到Mel滤波后的能量密度函数
其中,N表示Mel滤波器组由N个三角带通滤波器构成,Bm[k]表示中心频率为fm且响应频率范围为(fm-1,fm+1)的三角带通滤波器的频率响应函数;Bm[k]可以由下式表示:
其中,Mel滤波器的中心频率fm可通过对应的时域频率f得到;
步骤S4、Mel滤波后的能量密度函数通过规范化log尺度得到Mel能量谱Pmel(t,f)
步骤S5、对产生的Mel能量谱Pmel(t,f)进行分片采样,即采用滑动窗口取得Mel能量谱的片段;
通过上述的过程,将场景声音的时域信号转化为时频域的二维图谱,即Mel能量谱及能量谱片段。
在本发明一实施例中,所述CNN结构包括卷积层conv1、最大值池化层maxpool1、卷积层conv2、卷积层conv3、最大值池化层maxpool2、全连接层fc1、全连接层fc2和输出层。
在本发明一实施例中,所述卷积层conv1、卷积层conv2、卷积层conv3均采用无偏置和宽卷积运算,且卷积核大小均为3×3,卷积窗滑动步长为1,卷积核个数分别为32,64,64;所述最大值池化层maxpool1和最大值池化层maxpool2的池化窗大小为2×2,池化窗滑动步长为2;所述全连接层fc1和全连接层fc2神经元个数为512,输出层神经元个数为15;各层激活函数均采用修正线性单元;卷积层conv1在激活函数激活前,对该层的净激活值进行批标准化,卷积层conv2和卷积层conv3在激活函数激活前,加入l2正则化对卷积核参数本身进行惩罚;在全连接层fc1和全连接层fc2,采用0.5概率的Dropout训练策略,即在训练中随机让该层一定比例的神经元保留权重而不做输出;在输出层,全连接层产生的特征通过softmax激活得到分类的结果。
在本发明一实施例中,所述利用片段样本集对CNN进行两阶段训练,截断全连接层的特征输出,得到片段样本集的CNN特征的具体实现过程如下,
第一阶段:
将片段样本集划分成4种不同训练与测试子集的方案,即分别采用4种不同训练与测试子集的3/4做训练子集,1/4做验证子集;采用EarlyStopping策略,即每对CNN权重训练一次,就用验证子集进行一次验证,若识别率连续5次下滑则停止训练,并保存对验证子集识别率最高的权重,最后获得4组CNN的权重;选择4组中对验证子集识别率最高的权重作为第一阶段的训练结果;
第二阶段:
载入第一阶段的权重,然后对所有片段样本集进行训练;对整个片段样本集的损失值使用学习率调整与EarlyStopping相结合的策略,即,比较每次训练的损失值,并保存损失值最低时的CNN权重;若损失值未连续5次下降,则学习率减小一半;若损失值连续5次上升则停止训练;
根据第二阶段训练获得的CNN权重,构建CNN模型;其中,卷积层conv1到池化层maxpool2实现Mel能量谱的特征映射,全连接层fc1和fc2对特征映射进行降维;因此,通过截断全连接层的相关输出,获得CNN中间特征。
在本发明一实施例中,所述用随机森林对片段样本集的CNN特征进行分类,得到最终识别结果的具体实现方式如下,
首先,将场景声音训练样本的CNN中间特征集作为RF的训练样本,通过自助重采样作为构建决策树样本集;接着,在构建决策树阶段,通过每次组合的特征子集来构建分类回归树;经过N次的特征组合和自助重采样,生成N棵CART形成RF;在识别场景声音样本时,先抽取待测声音样本的CNN中间特征,统计每棵CART对该样本特征的预测结果并进行投票,得到最终的识别结果。
相较于现有技术,本发明具有以下有益效果:
1)本发明方法相比IEEEDCASE2016的MFCC-GMM基准方法,本文方法识别率提高了9.2%;
2)本发明方法相比现有最新的Mel-DNN、CNN-LSTM和CQT-CNN方法,本文方法在CNN结构中加入l2正则化和训练时候采用EarlyStopping、Dropout策略,以此避免神经网络中经常出现的训练数据集表现良好而测试数据集性能不佳的过拟合现象;同时,也克服了CNN-LSTM和CQT-CNN方法进行结构联合、构建模型的参数空间较大、需要更多的计算资源和更长的训练时间的问题,使得模型可以适用于容量与计算能力相对较弱的终端设备;
3)本发明方法相比于Mel-CNN[7]方法在Evaluate数据集测试的识别率86.2%,与本文方法的86.4%接近。但Mel-CNN需要采用如表6所示的多次切割长度的尝试,且长度不同导致在Development数据集上进行4-fold交叉验证得到的平均识别率浮动较大。相对而言,本文所使用的CNN结构相对简洁;提取CNN中全连接层的低维输出作为特征,使用RF进行识别,使用了较少的计算资源和训练时间。
附图说明
图1为本发明声音场景识别架构。
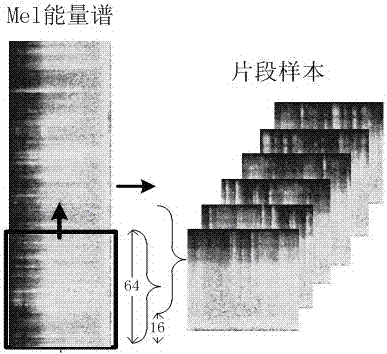
图2为分片采样过程。
图3为CNN结构。
图4为两阶段训练过程。
图5为RF构建过程。
图6为对Evaluate数据集的识别及错误情况。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
本发明的一种基于卷积神经网络与随机森林分类的声音场景识别方法,首先,声音场景通过Mel滤波器生成Mel能量谱及其片段样本集;然后,利用片段样本集对CNN进行两阶段训练,截断全连接层的特征输出,得到片段样本集的CNN特征;最后,用随机森林对片段样本集的CNN特征进行分类,得到最终识别结果。
所述声音场景通过Mel滤波器生成Mel能量谱及其片段样本集,即通过对各种不同长度的场景声音样本提取Mel能量谱,通过分片采样,得到大小一致的Mel能量谱片段作为CNN模型的训练样本;具体实现方式如下,
步骤S1、场景声音信号s(n)经过短时傅里叶变换得到短时幅度谱|S(t,f)|
其中,t为帧索引,f为频率,w(n)为分析窗函数;
步骤S2、由短时幅度谱|S(t,f)|得到信号s(n)的能量密度函数P(t,f)
P(t,f)=S(t,f)×conj(S(t,f))=|S(t,f)|2 (2)
其中,conj为求共轭复数函数;
步骤S3、使用Mel滤波器组对能量密度函数P(t,f)进行滤波得到Mel滤波后的能量密度函数
其中,N表示Mel滤波器组由N个三角带通滤波器构成,Bm[k]表示中心频率为fm且响应频率范围为(fm-1,fm+1)的三角带通滤波器的频率响应函数;Bm[k]可以由下式表示:
其中,Mel滤波器的中心频率fm可通过对应的时域频率f得到;
步骤S4、Mel滤波后的能量密度函数通过规范化log尺度得到Mel能量谱Pmel(t,f)
步骤S5、对产生的Mel能量谱Pmel(t,f)进行分片采样,即采用滑动窗口取得Mel能量谱的片段;
通过上述的过程,将场景声音的时域信号转化为时频域的二维图谱,即Mel能量谱及能量谱片段。
所述CNN结构包括卷积层conv1、最大值池化层maxpool1、卷积层conv2、卷积层conv3、最大值池化层maxpool2、全连接层fc1、全连接层fc2和输出层。所述卷积层conv1、卷积层conv2、卷积层conv3均采用无偏置和宽卷积运算,且卷积核大小均为3×3,卷积窗滑动步长为1,卷积核个数分别为32,64,64;所述最大值池化层maxpool1和最大值池化层maxpool2的池化窗大小为2×2,池化窗滑动步长为2;所述全连接层fc1和全连接层fc2神经元个数为512,输出层神经元个数为15;各层激活函数均采用修正线性单元;卷积层conv1在激活函数激活前,对该层的净激活值进行批标准化,卷积层conv2和卷积层conv3在激活函数激活前,加入l2正则化对卷积核参数本身进行惩罚;在全连接层fc1和全连接层fc2,采用0.5概率的Dropout训练策略,即在训练中随机让该层一定比例的神经元保留权重而不做输出;在输出层,全连接层产生的特征通过softmax激活得到分类的结果。
所述利用片段样本集对CNN进行两阶段训练,截断全连接层的特征输出,得到片段样本集的CNN特征的具体实现过程如下,
第一阶段:
将片段样本集划分成4种不同训练与测试子集的方案,即分别采用4种不同训练与测试子集的3/4做训练子集,1/4做验证子集;采用EarlyStopping策略,即每对CNN权重训练一次,就用验证子集进行一次验证,若识别率连续5次下滑则停止训练,并保存对验证子集识别率最高的权重,最后获得4组CNN的权重;选择4组中对验证子集识别率最高的权重作为第一阶段的训练结果;
第二阶段:
载入第一阶段的权重,然后对所有片段样本集进行训练;对整个片段样本集的损失值使用学习率调整与EarlyStopping相结合的策略,即,比较每次训练的损失值,并保存损失值最低时的CNN权重;若损失值未连续5次下降,则学习率减小一半;若损失值连续5次上升则停止训练;
根据第二阶段训练获得的CNN权重,构建CNN模型;其中,卷积层conv1到池化层maxpool2实现Mel能量谱的特征映射,全连接层fc1和fc2对特征映射进行降维;因此,通过截断全连接层的相关输出,获得CNN中间特征。
所述用随机森林对片段样本集的CNN特征进行分类,得到最终识别结果的具体实现方式如下,
首先,将场景声音训练样本的CNN中间特征集作为RF的训练样本,通过自助重采样作为构建决策树样本集;接着,在构建决策树阶段,通过每次组合的特征子集来构建分类回归树;经过N次的特征组合和自助重采样,生成N棵CART形成RF;在识别场景声音样本时,先抽取待测声音样本的CNN中间特征,统计每棵CART对该样本特征的预测结果并进行投票,得到最终的识别结果。
以下为本发明的具体实现过程。
1、卷积神经网络与随机森林结合架构
本发明识别架构如图1所示。其中,实线框,场景声音预处理、CNN模型和随机森林,是本发明方法的三个主要过程。虚线框,Mel能量谱片段采样、CNN两阶段训练、截断CNN全连接层输出和识别结果,是本发明方法的四个具体技术细节。
场景声预处理,通过对场景声音分帧、傅里叶变换、Mel滤波器组滤波、log尺度变换等步骤,生成Mel能量谱。Mel能量谱片段采样,对Mel能量谱进行分片采样,生成Mel能量谱的片段样本集,作为CNN两阶段训练的训练集和CNN模型的测试集。CNN两阶段训练,通过两阶段训练,确定CNN模型的权值。CNN模型,用于片段样本的CNN中间特征的生成,作为截断CNN全连接层的输入。截断CNN全连接层输出,提取训练集和测试集的CNN中间特征,用于随机森林的训练与决策。随机森林,通过训练集的中间特征训练得到,并用于测试集的中间特征的投票。识别结果,根据测试集的中间特征的投票情况,确定场景声音的识别结果。
2、卷积神经网络的特征提取及识别
2.1场景声音预处理与Mel能量谱分片采样
这部分对各种不同长度的场景声音样本提取Mel能量谱,通过分片采样,得到大小一致的Mel能量谱片段作为CNN模型的训练样本。其相关过程如下:
1)场景声音信号s(n)经过短时傅里叶变换(Short Time Fourier Transform,STFT)得到短时幅度谱|S(t,f)|。
其中,t为帧索引,f为频率,w(n)为分析窗函数。w(n),本发明实施例中选汉明窗。
2)由短时幅度谱|S(t,f)|得到信号s(n)的能量密度函数P(t,f)。
P(t,f)=S(t,f)×conj(S(t,f))=|S(t,f)|2 (2)
其中conj为求共轭复数函数。
3)使用Mel滤波器组对能量密度函数P(t,f)进行滤波得到Mel滤波后的能量密度函数
其中,N表示Mel滤波器组由N个三角带通滤波器构成,Bm[k]表示中心频率为fm且响应频率范围为(fm-1,fm+1)的三角带通滤波器的频率响应函数。Bm[k]可以由下式表示:
其中,Mel滤波器的中心频率fm可通过对应的时域频率f得到。
4)Mel滤波后的能量密度函数通过规范化log尺度得到Mel能量谱Pmel(t,f)。
5)如图2所示,对产生的Mel能量谱Pmel(t,f)进行分片采样,即采用滑动窗口取得Mel能量谱的片段。本发明实施例中中,窗口的宽度为64像素,滑动距离16像素。
通过上述的过程,将场景声音的时域信号转化为时频域的二维图谱,即Mel能量谱及能量谱片段。
2.2卷积神经网络结构
本发明的CNN结构如图3所示,由卷积层conv1、最大值池化层maxpool1、卷积层conv2、卷积层conv3、最大值池化层maxpool2、全连接层fc1、全连接层fc2和输出层等构成。
网络输入的Mel能量谱大小为64×64,训练时的批尺寸(Batch size)为512。即训练中,每输入512张64×64的能量谱片段,CNN就进行一次参数的更新。conv1,conv2,conv3都采用无偏置(Nobias)和宽卷积运算(卷积运算前对边缘进行补0)。卷积核大小都为3×3,卷积窗滑动步长(stride)为1。卷积核个数分别为32,64,64。池化层maxpool1和maxpool2的池化窗大小为2×2,池化窗滑动步长(stride)为2。全连接层fc1和fc2神经元个数为512,输出层神经元个数为15。各层激活函数采用修正线性单元(Rectified Linear Unit,ReLU)。conv1层在激活函数激活前,对该层的净激活值进行批标准化(Batch normalize,BN)[11]。conv2和conv3层在激活函数激活前,加入l2(0.001)正则化对卷积核参数本身进行惩罚。在全连接层fc1和fc2,采用0.5概率的Dropout训练策略[12],即在训练中随机让该层一定比例的神经元保留权重而不做输出。在输出层,全连接层产生的特征通过softmax激活得到分类的结果。
2.3CNN训练过程及其特征提取
如图4所示,本发明方法中训练分为两个阶段。在第一阶段,把训练集划分成4种不同训练与测试子集的方案。即图4所示的4-Fold,分别采用4种不同的3/4做训练子集,1/4做验证子集。采用EarlyStopping策略,即每对CNN权重训练一次,就用验证子集进行一次验证,如果识别率连续5次下滑则停止训练,并保存对验证子集识别率最高的权重。这样,图4中的4个不同的训练子集,将获得4组CNN的权重。选择4组中对验证子集识别率最高的权重作,为第一阶段的训练结果。
在第二阶段,载入第一阶段的权重,然后对所有训练集样本进行训练。对整个训练集的损失值使用学习率调整与EarlyStopping相结合的策略。即,比较每次训练的损失值,并保存损失值最低时的CNN权重;若损失值未连续5次下降,则学习率减小一半;若损失值连续5次上升则停止训练。
根据第二阶段训练获得的CNN权重,构建如图3所示的CNN模型。其中,卷积层conv1到池化层maxpool2实现Mel能量谱的特征映射,全连接层fc1和fc2对特征映射进行降维。因此,通过截断全连接层的相关输出,获得CNN中间特征。
2.4随机森林
随机森林(Random Forests,RF)[13]是一种通过构建多棵决策树进行投票的集成分类器。如图5,本发明方法利用随机森林的识别过程如下:首先,将场景声音训练样本的CNN中间特征集作为RF的训练样本,通过自助重采样(Bootstrapping)作为构建决策树样本集。接着,在构建决策树阶段,通过每次组合的特征子集来构建分类回归树(Classification And Regression Tree,CART)。经过N次的特征组合和自助重采样,生成N棵CART形成RF。在识别场景声音样本时,先抽取待测声音样本的CNN中间特征,统计每棵CART对该样本特征的预测结果并进行投票,得到最终的识别结果。
3实验及结果分析
本发明采用的场景声音来自IEEE DCASE2016所规定使用的声音数据库中的声音场景数据集[8]。如表1所示,该数据集包含15类场景声音。数据集分为Development和Evaluate两个部分。其中,Development部分包含1170样本,Evaluate部分包含390个样本。在Development部分设置了4-Fold,作为模型的训练与验证。而Evaluate部分为测试集,仅用于评估模型。15类场景声音的样本数量相等。声音样本都为双声道“.wav”数据格式,采样率为44.1kHz,声音长度为30s,采样精度为24bits。下面,以Development和Evaluate数据集为基础,进行相关实验。
表1声音场景样本类别
3.1不同CNN参数设置的比较
在这部分比较3种不同CNN参数设置的识别效果。实验在Development数据集上进行4个fold的交叉验证。训练过程使用cudnn加速库加速计算[14]。
如表2所示,3种CNN参数的设置:CNN-1为本发明方法采用的设置,卷积层无偏置(Nobias),conv1层BN,conv2和conv3层加入l2正则化;CNN-2卷积层均有偏置项,相关层也采用了BN和l2正则化;CNN-3卷积层均无偏置项,但没有采用BN和l2正则化。3种设置的部分参数说明如下。
表2不同结构的CNN
1)Conv1-32-Nobias-BN,表示卷积层1,该层有32个卷积核,无偏置项,使用了BN;
2)Conv2-64-Nobias-l2(0.001),表示卷积层2,l2(0.001)表示该层采用l2正则化,惩罚系数为0.001;
3)2×2MaxPool1,表示池化层1,采用了2×2区域的最大值池化;
4)FC1-512+Dropout(0.5),表示全连接层1,该层有512神经元,采用0.5系数的Dropout的训练策略。
实验结果如表3所示,为3种不同参数设置的CNN在Development部分4个Fold交叉验证中的识别率。对于3种不同的CNN,本发明方法所用的CNN-1,比CNN-2识别率有所提升,也优于CNN-3。表明本发明方法采用的加入BN,l2正则化和去掉偏置项在一定程度上提高了识别率。因此,本发明方法采用CNN-1的设置进行CNN的两阶段训练。由于CNN-1交叉验证中Fold-1在4个Fold验证中的识别率最高,所以选用了Fold-1训练的权重作为第二阶段训练的载入权重,进行第二阶段训练。最后,根据第二阶段训练获得的CNN权重,可以构建CNN-1模型,作为进一步实验的CNN模型。
表3不同结构的CNN的识别率%
3.2CNN中间特征与各种分类器
根据两阶段训练构建的CNN模型,我们可以提取CNN的全连接层FC1和FC2在ReLU激活前后的输出作为CNN中间特征。这部分,测试各种分类器对这些CNN中间特征的分类性能。
用Development数据集提取的CNN中间特征对各种分类器进行训练。使用Evaluate数据集提取的CNN中间特征作为测试集,评估这些分类器的识别性能。同时,把这些分类器与CNN-1本身的softmax分类器的识别效果进行比较。
由于每个声音样本产生的Mel能量谱都被分成若干个片段,所以使用分类器对片段进行投票的结果作为该样本的预测结果。使用5种不同的分类器分别验证CNN中间特征的识别情况。
分类器1,线性判别式分析(Linear DiscriminantAnalysis,LDA)。
分类器2,二次判别式分析(Quadratic DiscriminantAnalysis,QDA)。
分类器3,支持向量机(SupportVector Machine,SVM)。
分类器4,随机森林(Random Forest,RF)。
分类器5,k最近邻(k-Nearest Neighbor,kNN)。
表4不同分类器的识别效果%
实验结果如表4所示,为各个分类器使用不同的CNN中间特征训练后进行测试得到的识别率。在FC1、FC2层及激活前后输出的特征,对分类器的识别性能产生不同影响。多数分类器对全连接层FC2激活后的特征识别性能高于其他位置输出。而从平均的识别率上看,RF表现出更高的识别性能。说明RF较其他分类器对CNN全连接层特征的识别有着较高的识别性能。其次,RF的识别率高于CNN本身结构中采用softmax分类器的识别率。尤其,当RF分类器结合CNN的FC2激活后特征时,获得86.4%的识别率,高于CNN的softmax分类器的83.9%。因此,进一步说明RF分类器结合CNN中间特征的对场景声音识别的有效性。
3.3与现有方法的比较
在这部分,把RF分类器结合CNN的FC2激活后特征的识别方法,与最新方法进行比较。这些方法包括:IEEE DCASE2016的MFCC结合GMM的基准方法[8]、Kong提出的Mel能量谱结合DNN的深度学习基准方法[5]、Valenti等提出的分割场景声音提取Mel频谱图使用CNN分类的方法[7]、Bae等提出由CNN和LSTM构建联合网络的方法[9]和Lidy提出的CQT结合双CNN的方法[10]。
6种识别方法在Development数据集上的识别率和Evaluate数据集测试的识别率,如表5所示。实验结果表明,本发明RF结合CNN中间特征的方法具有如下优点。
表5不同识别方法对比结果%
1)相比IEEEDCASE2016的MFCC-GMM基准方法,本发明方法识别率提高了9.2%。
2)相比现有最新的Mel-DNN、CNN-LSTM和CQT-CNN方法,本发明方法在CNN结构中加入l2正则化和训练时候采用EarlyStopping、Dropout策略,以此避免神经网络中经常出现的训练数据集表现良好而测试数据集性能不佳的过拟合现象;同时,也克服了CNN-LSTM和CQT-CNN方法进行结构联合、构建模型的参数空间较大、需要更多的计算资源和更长的训练时间的问题,使得模型可以适用于容量与计算能力相对较弱的终端设备。
表6Valenti[7]等提出识别方法的分割长度及其交叉验证识别率%
3)相比于Mel-CNN[7]方法在Evaluate数据集测试的识别率86.2%,与本发明方法的86.4%接近。但Mel-CNN需要采用如表6所示的多次切割长度的尝试,且长度不同导致在Development数据集上进行4-fold交叉验证得到的平均识别率浮动较大。相对而言,本发明所使用的CNN结构相对简洁;提取CNN中全连接层的低维输出作为特征,使用RF进行识别,使用了较少的计算资源和训练时间。
4讨论
在这部分,主要通过统计错分的情况,以分析各种声音场景的识别效果,讨论本发明方法的实际应用意义。
图6是本发明方法在Evaluate数据集验证,产生的识别结果及错误分布情况。其中,每类的预测样本总数是26,横坐标代表的是声音场景的预测标签,纵坐标代表的是声音场景的实际标签。从图6可以看出对各种声音场景的识别情况。
1)对湖边沙滩和住宅区的声音场景,则具有理想的识别率,即测试中没有出现错误;
2)对公交车上、地铁站、火车和市中心的声音场景,识别率为96.2%;
3)对办公室、有轨电车和普通汽车的声音场景,识别率为92.3%;
4)对森林中的道路、咖啡厅/餐馆和图书馆等3类声音场景,识别率在80.8%至84.6%之间;
5)对公园、超市和家里等声音场景的识别率较低,识别率分别为50%、57%和73.1%。
因此,整体而言,本文方法对各种声音场景的识别是有效的。
对于识别率较低的5),其中,对于26个公园声音场景的识别,正确识别13个;被错误地识别为住宅区的声音场景和火车声音场景的各有3个;其它7个分别被误识别为:地铁站和图书馆各2个,超市、公交车和有轨电车各1个。其原因源于公园的声音场景受不同时间段及不同人流量的影响,场景声音刚好与这7种场景声音相近。如某些时段,公园里的场景声音与住宅区的场景声音很相近,而在另一些时段,与火车里的场景声音相近等。同样,对于超市声音场景误识别为地铁站;家庭场景声音误识别为公交车的声音场景也属于这种情况。
事实上,对于这种场景声音相近的情况,如果仅有场景声音,我们人类的听觉系统难以区别相应的声音场景。然而,本文采取的卷积层无偏设置,l2、Dropout和EarlyStopping的训练策略,具有提升这些场景声音的CNN中间特征的泛化特性。同时,本文也针对过拟合问题,采用RF分类器进行的投票决策。因此,采用本文方法,在两阶段训练CNN模型参数中,进一步结合这些场景声音的前后声音数据,有针对性地增加这些多变声音场景的声音分布比例,泛化声音场景的特征表征,将进一步改善这类场景的识别率。
5结论
本发明方法针对声音场景分类问题,提出一种利用卷积神经网络中间特征结合随机森林分类器对声音场景进行分类的方法。实验结果表明,CNN结构中采用BN和l2正则化等技术,使用RF对CNN中间特征进行分类识别,可以有效地提高场景声音的识别效果。总体而言,本发明方法工作有三个方面的意义:1)通过对Mel能量谱的分片采样,对声音场景的识别效果不依赖于场景声音分割的长度;2)设计相对简捷的CNN模型与随机森林分类器,使得模型可以适用于容量与计算能力相对较弱的终端设备;3)对声音场景的识别性能优于现有相关的识别方法。
参考文献:
[1]BATTAGLINO D,LEPAULOUX L,PILATI L,et al.Acoustic context recognition using local binarypattern codebooks[C]//Processings ofIEEE WASPAA’15.NewYork,USA:2015:1-5.
[2]ERONEN A J,PELTONEN V T,TUOMI J T,et al.Audio-based context recognition[J].IEEE Transactions onAudio,Speech,and Language Processing,2006,14(1):321-329.
[3]JONATHAN SL,SUKJAE C,OHBYUNG K.Identifying multiuser activity with overlapping acoustic data for mobile decision making in smart home environments[J].Expert Systems With Applications,81(2017)299–308.
[4]CAKIRE,PARASCANDOLO G,HEITTOLA T,et al.Convolutional recurrent neural networks for polyphonic sound event detection[J],IEEE Transactions onAudio,Speech,and Language Processing,2017,25(6):1292-1303.
[5]KONG Q,SOBIERAJ I,WANG W,et al.Deep neural network baseline for dcase challenge2016[C]//Processing ofDCASE’16.Budapest,Hungary:2016:50-54.
[6]ELIZALDE B,KUMAR A,SHAH A,et al.Experiments on the DCASE Challenge 2016:Acoustic scene classification and sound event detection in real life recording[EB/OL].(2016-08-25).https://arxiv.org/pdf/1607.06706.pdf.
[7]VALENTI M,DIMENT A,PARASCANDOLO G,et al.DCASE 2016acoustic scene classification using convolutional neural networks[C]//Processing ofDCASE’16.Budapest,Hungary:2016:95-99.
[8]MESAROS A,HEITTOLA T,VIRTANEN T.TUT database for acoustic scene classification and sound event detection[C]//Processing ofIEEE EUSIPCO’16.Budapest,Hungary:2016:1128-1132.
[9]BAE S H,CHOI I,KIM N S.Acoustic scene classification using parallel combination of LSTM and CNN[C]//Processing ofDCASE’16.Budapest,Hungary:2016:11-15.
[10]LIDY T,SCHINDLER A.CQT-based convolutional neural networks for audio scene classification[C]//Processing ofDCASE’16:Budapest,Hungary:2016:60-64.
[11]IOFFE S,SZEGEDY C.Batch normalization:Accelerating deep network training by reducing internal covariateshift[EB/OL].(2015-03-02).https://arxiv.org/pdf/1502.03167.pdf.
[12]SRIVASTAVA N,HINTON G E,KRIZHEVSKY A,et al.Dropout:a simple way to prevent neural networks from overfitting[J].Journal ofMachine Learning Research,2014,15(1):1929-1958.
[13]BREIMAN L.Random forests[J].Machine learning,2001,45(1):5-32.
[14]CHETLUR S,WOOLLEY C,VANDERMERSCH P,et al.cudnn:Efficient primitives for deeplearning[EB/OL].(2014-12-18).https://arxiv.org/pdf/1410.0759.pdf.。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!