基于卷积神经网络与随机森林分类的声音场景识别方法与流程
技术特征:
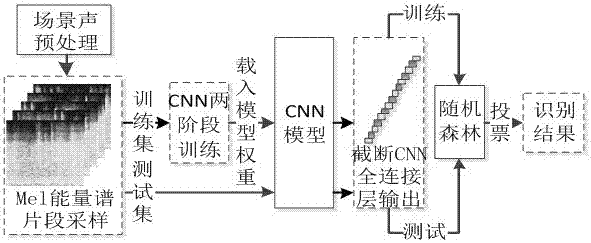
1.一种基于卷积神经网络与随机森林分类的声音场景识别方法,其特征在于:首先,声音场景通过Mel滤波器生成Mel能量谱及其片段样本集;然后,利用片段样本集对CNN进行两阶段训练,截断全连接层的特征输出,得到片段样本集的CNN特征;最后,用随机森林对片段样本集的CNN特征进行分类,得到最终识别结果。
2.根据权利要求1所述的基于卷积神经网络与随机森林分类的声音场景识别方法,其特征在于:所述声音场景通过Mel滤波器生成Mel能量谱及其片段样本集,即通过对各种不同长度的场景声音样本提取Mel能量谱,通过分片采样,得到大小一致的Mel能量谱片段作为CNN模型的训练样本。
3.根据权利要求1或2所述的基于卷积神经网络与随机森林分类的声音场景识别方法,其特征在于:所述声音场景通过Mel滤波器生成Mel能量谱及其片段样本集的具体实现方式如下,
步骤S1、场景声音信号s(n)经过短时傅里叶变换得到短时幅度谱|S(t,f)|
其中,t为帧索引,f为频率,w(n)为分析窗函数;
步骤S2、由短时幅度谱|S(t,f)|得到信号s(n)的能量密度函数P(t,f)
P(t,f)=S(t,f)×conj(S(t,f))=|S(t,f)|2 (2)
其中,conj为求共轭复数函数;
步骤S3、使用Mel滤波器组对能量密度函数P(t,f)进行滤波得到Mel滤波后的能量密度函数
其中,N表示Mel滤波器组由N个三角带通滤波器构成,Bm[k]表示中心频率为fm且响应频率范围为(fm-1,fm+1)的三角带通滤波器的频率响应函数;Bm[k]可以由下式表示:
其中,Mel滤波器的中心频率fm可通过对应的时域频率f得到;
步骤S4、Mel滤波后的能量密度函数通过规范化log尺度得到Mel能量谱Pmel(t,f)
步骤S5、对产生的Mel能量谱Pmel(t,f)进行分片采样,即采用滑动窗口取得Mel能量谱的片段;
通过上述的过程,将场景声音的时域信号转化为时频域的二维图谱,即Mel能量谱及能量谱片段。
4.根据权利要求3所述的基于卷积神经网络与随机森林分类的声音场景识别方法,其特征在于:所述CNN结构包括卷积层conv1、最大值池化层maxpool1、卷积层conv2、卷积层conv3、最大值池化层maxpool2、全连接层fc1、全连接层fc2和输出层。
5.根据权利要求4所述的基于卷积神经网络与随机森林分类的声音场景识别方法,其特征在于:所述卷积层conv1、卷积层conv2、卷积层conv3均采用无偏置和宽卷积运算,且卷积核大小均为3×3,卷积窗滑动步长为1,卷积核个数分别为32,64,64;所述最大值池化层maxpool1和最大值池化层maxpool2的池化窗大小为2×2,池化窗滑动步长为2;所述全连接层fc1和全连接层fc2神经元个数为512,输出层神经元个数为15;各层激活函数均采用修正线性单元;卷积层conv1在激活函数激活前,对该层的净激活值进行批标准化,卷积层conv2和卷积层conv3在激活函数激活前,加入l2正则化对卷积核参数本身进行惩罚;在全连接层fc1和全连接层fc2,采用0.5概率的Dropout训练策略,即在训练中随机让该层一定比例的神经元保留权重而不做输出;在输出层,全连接层产生的特征通过softmax激活得到分类的结果。
6.根据权利要求3至5任一所述的基于卷积神经网络与随机森林分类的声音场景识别方法,其特征在于:所述利用片段样本集对CNN进行两阶段训练,截断全连接层的特征输出,得到片段样本集的CNN特征的具体实现过程如下,
第一阶段:
将片段样本集划分成4种不同训练与测试子集的方案,即分别采用4种不同训练与测试子集的3/4做训练子集,1/4做验证子集;采用EarlyStopping策略,即每对CNN权重训练一次,就用验证子集进行一次验证,若识别率连续5次下滑则停止训练,并保存对验证子集识别率最高的权重,最后获得4组CNN的权重;选择4组中对验证子集识别率最高的权重作为第一阶段的训练结果;
第二阶段:
载入第一阶段的权重,然后对所有片段样本集进行训练;对整个片段样本集的损失值使用学习率调整与EarlyStopping相结合的策略,即,比较每次训练的损失值,并保存损失值最低时的CNN权重;若损失值未连续5次下降,则学习率减小一半;若损失值连续5次上升则停止训练;
根据第二阶段训练获得的CNN权重,构建CNN模型;其中,卷积层conv1到池化层maxpool2实现Mel能量谱的特征映射,全连接层fc1和fc2对特征映射进行降维;因此,通过截断全连接层的相关输出,获得CNN中间特征。
7.根据权利要求6所述的基于卷积神经网络与随机森林分类的声音场景识别方法,其特征在于:所述用随机森林对片段样本集的CNN特征进行分类,得到最终识别结果的具体实现方式如下,
首先,将场景声音训练样本的CNN中间特征集作为RF的训练样本,通过自助重采样作为构建决策树样本集;接着,在构建决策树阶段,通过每次组合的特征子集来构建分类回归树;经过N次的特征组合和自助重采样,生成N棵CART形成RF;在识别场景声音样本时,先抽取待测声音样本的CNN中间特征,统计每棵CART对该样本特征的预测结果并进行投票,得到最终的识别结果。
- 还没有人留言评论。精彩留言会获得点赞!