处理方法和装置、用于处理的装置与流程
本发明涉及处理
技术领域:
,特别是涉及一种处理方法和装置、一种用于处理的装置。
背景技术:
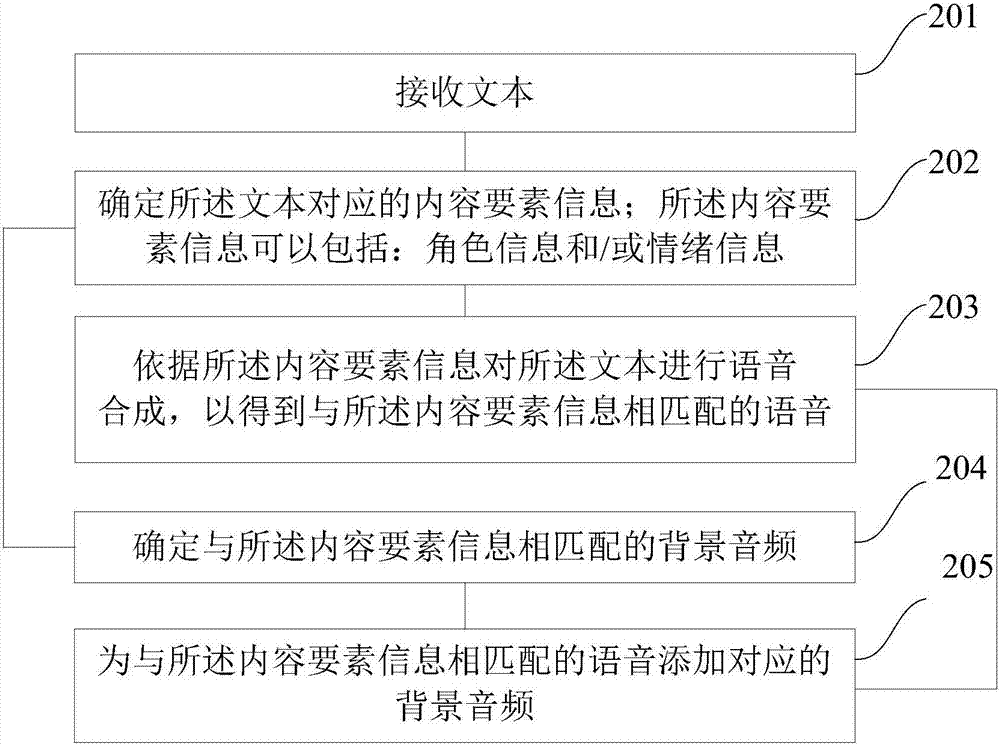
:讲故事是一种传统的教育方式,用于帮助儿童了解世界、传递价值观、知识和信仰;同时,讲故事是儿童社会和认知能力开发的重要环节,在儿童的成长中扮演着重要的角色。目前的讲故事技术可以包括:专人录制技术和语音合成技术。其中,专人录制技术可以通过专人讲述整篇故事,语音合成技术又称文语转换(TTS,Text-to-Speech)技术,其将故事文本转换为故事语音。然而,在实际应用中,专人录制技术的制作成本较高,并且,专人录制的故事语音通常由一个人来讲述,导致故事语音较为单一。而语音合成技术得到的故事语音往往缺乏情感表达,导致故事语音的表现力不够丰富。技术实现要素:鉴于上述问题,提出了本发明实施例以便提供一种克服上述问题或者至少部分地解决上述问题的处理方法、处理装置及用于处理的装置,本发明实施例可以将已有文本加工成为更生动、富有情感的语音表现形式,提高文本所对应语音的丰富度和表现力。为了解决上述问题,本发明实施例公开了一种处理方法,包括:接收文本;确定所述文本对应的内容要素信息;所述内容要素信息包括:角色信息和/或情绪信息;依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,所述角色信息包括:角色实体,所述确定所述文本对应的内容要素信息,包括:对所述文本进行命名实体识别,并从得到的识别结果中获取所述文本对应的角色实体。可选地,所述角色信息还包括:角色标签,所述角色标签用于表征所述角色实体对应的特征。可选地,所述角色标签包括:性别标签、年龄标签和性格标签中的至少一种。可选地,所述确定所述文本对应的内容要素信息,包括:将所述文本中的词汇与情绪词典进行匹配,并依据匹配结果确定所述文本对应的情绪信息;和/或采用情绪分类模型,确定所述文本对应的情绪信息;和/或对所述文本进行句法分析,并依据句法分析结果确定所述文本对应的情绪信息。可选地,所述依据所述内容要素信息对所述文本进行语音合成,包括:依据所述内容要素信息、以及内容要素信息与语音参数之间的映射关系,确定所述内容要素信息对应的目标语音参数;依据所述目标语音参数对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,所述方法还包括:确定与所述内容要素信息相匹配的背景音频;为与所述内容要素信息相匹配的语音添加对应的背景音频。可选地,所述内容要素信息还包括:场景信息。可选地,所述方法还包括:接收用户的问题信息;依据所述文本中包括的问答对,确定所述问题信息对应的答案信息。另一方面,本发明实施例公开了一种处理装置,包括:接收模块,用于接收文本;内容要素信息确定模块,用于确定所述文本对应的内容要素信息;所述内容要素信息包括:角色信息和/或情绪信息;以及语音合成模块,用于依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,所述角色信息包括:角色实体,所述内容要素信息确定模块包括:命名实体识别子模块,用于对所述文本进行命名实体识别,并从得到的识别结果中获取所述文本对应的角色实体。可选地,所述角色信息还包括:角色标签,所述角色标签用于表征所述角色实体对应的特征。可选地,所述角色标签包括:性别标签、年龄标签和性格标签中的至少一种。可选地,所述内容要素信息确定模块包括:第一情绪确定子模块,用于将所述文本中的词汇与情绪词典进行匹配,并依据匹配结果确定所述文本对应的情绪信息;和/或第二情绪确定子模块,用于采用情绪分类模型,确定所述文本对应的情绪信息;和/或第三情绪确定子模块,用于对所述文本进行句法分析,并依据句法分析结果确定所述文本对应的情绪信息。可选地,所述语音合成模块包括:目标语音参数确定子模块,用于依据所述内容要素信息、以及内容要素信息与语音参数之间的映射关系,确定所述内容要素信息对应的目标语音参数;语音合成子模块,用于依据所述目标语音参数对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,所述装置还包括:背景音频确定模块,用于确定与所述内容要素信息相匹配的背景音频;背景音频添加模块,用于为与所述内容要素信息相匹配的语音添加对应的背景音频。可选地,所述内容要素信息还包括:场景信息。可选地,所述装置还包括:问题接收模块,用于接收用户的问题信息;答案确定模块,用于依据所述文本中包括的问答对,确定所述问题信息对应的答案信息。再一方面,本发明实施例公开了一种用于处理的装置,包括有存储器,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于进行以下操作的指令:接收文本;确定所述文本对应的内容要素信息;所述内容要素信息包括:角色信息和/或情绪信息;依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。又一方面,本发明实施例公开了一种机器可读介质,其上存储有指令,当由一个或多个处理器执行时,使得装置执行前述一个或多个所述的处理方法。本发明实施例包括以下优点:本发明实施例依据文本对应的内容要素信息,对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音;其中,在上述内容要素信息包括角色信息的情况下,可以实现分角色的语音的输出,进而可以提高语音的丰富度;在上述内容要素信息包括情绪信息的情况下,可以实现分情绪的语音的输出,进而可以提高语音的表现力。本发明实施例可以将已有文本加工成为更生动、富有情感的语音表现形式,并通过例如故事机的多媒体终端加以播放。附图说明图1是本发明的一种处理方法实施例一的步骤流程图;图2是本发明的一种处理方法实施例二的步骤流程图;图3是本发明的一种处理方法实施例三的步骤流程图;图4是本发明的一种处理装置实施例的结构框图;图5是本发明的一种用于处理的装置900作为终端时的结构框图;及图6是本发明的一些实施例中服务器的结构示意图。具体实施方式为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。本发明实施例提供了一种处理方案,该方案可以接收文本,确定所述文本对应的内容要素信息,并依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。本发明实施例中,文本可以指需要转换为语言的文本。可选地,该文本可以为具有一定情节内容的文本,该文本可以包括:作品文本或者普通文本等,该文本的例子可以包括:故事文本、评书文本、诗歌文本、小品文本等,本发明实施例主要以故事文本为例进行说明,其他类型的文本相互参照即可。本发明实施例中,内容要素信息可用于表征构成文本内容的因素,本发明实施例的内容要素信息可以包括:角色信息和/或情绪信息。其中,角色信息可用于表征文本对应的发声实体。上述发声实体可以包括:文本中的角色实体、或者文本的叙述实体。根据一种实施例,文本中的角色实体可以包括主角信息、配角信息等,根据另一种实施例,文本中的角色实体可以包括实体的标识信息,例如,故事《小红帽》中的角色信息可以包括:“小红帽”、“大灰狼”、“妈妈”、“猎人”等。文本的叙述实体可以指情节的叙述者,该叙述实体通常为情节外的叙述者,该叙述实体通常不同于文本中的角色实体,也可称为第三方实体。情绪信息可用于表征发声实体对应的情绪。该情绪可以指实体有喜、怒、哀、乐、惧等心理体验,这种体验是人对客观事物的态度的一种反映。情绪具有肯定和否定的性质:能满足人的需要的事物会引起人的肯定性质的体验,如快乐、满意等;不能满足人需要的事物会引起人的否定性质的体验,如愤怒、憎恨、哀怨等。根据一种实施例,情绪信息可以包括:肯定、否定和中性;根据另一种实施例,情绪信息可以包括:喜、怒、忧、思、悲、恐、惊等,可以理解,本发明实施例对于具体的情绪信息不加以限制。本发明实施例中,实体是一个具体事物或概念,实体一般会划分类型,例如实体类实体、电影类实体等;同一个实体可以对应多个实体实例,实体实例是在网络(或其它媒介)中对一个实体的描述性页面(内容),例如各种百科的页面中即包含实体对应的实体实例。实体词的例子可以包括但不限于:人名、地名、机构名、书名、歌名、影视剧名、产品名、品牌名等专有名词。在实际应用中,可以从互联网抓取实体相关数据,并对实体相关数据进行分析,以得到对应的实体词,并将该实体词存储至实体库,本发明实施例对于具体的实体词及其获取方式不加以限制。本发明实施例中,可以以文本中的语言单元为单位进行处理,具体地,确定所述文本中语言单元对应的内容要素信息,并依据所述内容要素信息对所述文本中语言单元进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,上述语言单元可以包括:段落、句子、或者分句等。其中,句子是语言运用的基本单位,它由词、词组(短语)构成,能表达一个完整的意思;由两个或两个以上结构上相对独立的单句形式构成的句子就是复句,复句中相对独立的单句形式被称为分句。当然,本发明实施例对于具体的语言单元不加以限制。在本发明实施例的一种应用示例中,假设故事文本1为《井底之蛙》对应的文本,对应的文本内容如下:“有一只青蛙长年住在一口枯井里。它对自己生活的小天地满意极了,一有机会就要当众吹嘘一番。有一天,它吃饱了饭,蹲在井栏上正闲得无聊,忽然看见不远处有一只大海鳖在散步。青蛙赶紧扯开嗓门喊了起来:“喂,海鳖兄,请过来,快请过来!”……海鳖慢慢地退了回来,问青蛙:“你听说过大海没有?”青蛙摇摆头。海鳖说:“大海水天茫茫,无边无际。……你看,比起你这一眼枯井、一坑浅水来,哪个天地更开阔,哪个乐趣更大呢?”青蛙听傻了,鼓着眼睛,半天合不拢嘴”。本发明实施例在以语言单元为单位对上述故事文本1进行处理的过程中,上述故事文本1中的不同语言单元可以对应不同的角色信息。例如,对于句子1“有一只青蛙长年住在一口枯井里。”、句子2“青蛙赶紧扯开嗓门喊了起来:“喂,海鳖兄,请过来,快请过来!””和句子3“海鳖慢慢地退了回来,问青蛙:“你听说过大海没有?””,可以确定句子1对应的角色信息为“叙述实体”,句子2中前一分句对应的角色信息为“叙述实体”、而后一分句对应的角色信息为“青蛙”,句子3中前一分句对应的角色信息为“叙述实体”、而后一分句对应的角色信息为“海鳖”。在本发明实施例的另一种应用示例中,假设故事文本2为《小蝌蚪找妈妈》对应的文本,对应的文本内容如下:“暖和的春天来了。池塘里的冰融化了。……他们一起游到鸭妈妈身边,问鸭妈妈:“鸭妈妈,鸭妈妈,您看见过我们的妈妈吗?请您告诉我们,我们的妈妈是什么样的呀?”……小蝌蚪听了,高兴得在水里翻起跟头来:“啊!我们找到妈妈了!我们找到妈妈了!好妈妈,好妈妈,您快到我们这儿来吧!您快到我们这儿来吧!”青蛙妈妈扑通一声跳进水里,和她的孩子蝌蚪一块儿游玩去了。”本发明实施例在以语言单元为单位对上述故事文本2进行处理的过程中,上述故事文本2中的不同语言单元可以对应不同的情绪信息。例如,对于分句““鸭妈妈,鸭妈妈,您看见过我们的妈妈吗?请您告诉我们,我们的妈妈是什么样的呀?””,其对应的情绪信息可以包括:“问”;而对于分句““啊!我们找到妈妈了!我们找到妈妈了!好妈妈,好妈妈,您快到我们这儿来吧!您快到我们这儿来吧!””,其对应的情绪信息可以包括:“喜”等。本发明实施例中,语音与内容要素信息相匹配可以包括:语音的语音参数与内容要素信息相匹配等,语音参数的例子可以包括:语速、音量和音色中的至少一种。根据一种实施例,语音的音色可以与角色信息相匹配,这样可以使得不同的角色信息对应不同的音色,例如,在故事《小红帽》中“小红帽”、“大灰狼”、“妈妈”、“猎人”、“叙述实体”等不同角色信息发声的情况下,至少两种角色信息所对应语音的音色可以相互不同(例如,“小红帽”、“大灰狼”所对应语音的音色不同等),由此可以实现分角色的语音的输出。根据另一种实施例,语音的语速和/或音量可以与情绪信息相匹配,这样可以使得不同的情绪信息对应不同的语速和/或音量。例如,“喜”、“怒”、“忧”、“思”、“悲”、“恐”、“惊”中的至少两种情绪信息所对应语音的语速和/或音量可以相互不同,由此可以实现分情绪的语音的输出。综上,本发明实施例依据文本对应的内容要素信息,对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音;其中,在上述内容要素信息包括角色信息的情况下,可以实现分角色的语音的输出,进而可以提高语音的丰富度;在上述内容要素信息包括情绪信息的情况下,可以实现分情绪的语音的输出,进而可以提高语音的表现力。本发明实施例提供的处理方案可以针对任意的文本进行处理,本发明实施例提供的处理方案可以应用于任意的处理平台,处理平台的例子可以包括:故事网站和/或故事APP(应用程序,Application)等。在本发明的一种实施例中,本发明实施例输出的语音可以应用于多媒体终端,由此可以向用户输出丰富度更佳及表现力更丰富的语音。多媒体终端的例子可以包括:故事机、智能手机、平板电脑、电子书阅读器、MP3(动态影像专家压缩标准音频层面3,MovingPictureExpertsGroupAudioLayerIII)播放器、MP4(动态影像专家压缩标准音频层面4,MovingPictureExpertsGroupAudioLayerIV)播放器、膝上型便携计算机、车载电脑、台式计算机、机顶盒、智能电视机、可穿戴设备等等。在本发明的另一种实施例中,处理平台可以提供SDK(软件开发工具包,softwaredevelopmentkit),该SDK可以为第三方平台(如第三方APP)提供一个与处理平台进行语音交换的通道,通过SDK的使用,第三方平台可以将更多生动的语音集成到自身的产品上,例如,第三方平台可以将通过SDK得到的语音集成到终端或者终端上运行的APP上。方法实施例一参照图1,示出了本发明的一种处理方法实施例一的步骤流程图,具体可以包括如下步骤:步骤101、接收文本;步骤102、确定所述文本对应的内容要素信息;所述内容要素信息可以包括:角色信息和/或情绪信息;步骤103、依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。本发明实施例对于步骤101中文本的来源不加以限制。例如,该文本可以源自互联网,也可以源自用户,或者可以源自第三方平台。其中,在该文本源自互联网的情况下,可以通过网页爬取的方式,从相关的网页(例如艺术相关的垂直网站中网页、或者儿童故事相关的垂直网站中网页等)中爬取文本。在该文本源自用户的情况下,例如,可以通过网站或者APP的形式向用户提供上传接口,并将用户通过该上传接口上传的文本作为步骤101中文本。步骤102中,角色信息可用于表征文本对应的发声实体。上述发声实体可以包括:文本中的角色实体、或者文本的叙述实体。根据一种实施例,文本中的角色实体可以包括主角信息、配角信息等,根据另一种实施例,文本中的角色实体可以包括角色实体的标识信息,例如,故事《小红帽》中的角色信息可以包括:“小红帽”、“大灰狼”、“妈妈”、“猎人”等。文本的叙述实体可以指情节的叙述者,该叙述实体通常为情节外的叙述者,该叙述实体通常不同于文本中的角色实体,也可称为第三方实体。在本发明的一种实施例中,步骤102确定所述文本对应的内容要素信息的过程,可以包括:利用角色词典,确定所述文本对应的内容要素信息。其中,角色词典可用于存储针对预置故事或者预置作品挖掘得到的角色。预置故事可以为常见的故事、或者为通过网页爬取得到的故事等,例如,可以针对预置故事《小红帽》挖掘得到“小红帽”、“大灰狼”、“妈妈”、“猎人”等故事角色,并存储至角色词典;这样,利用角色词典,确定所述文本对应的内容要素信息的过程可以包括:依据文本查找角色词典,并将命中该角色词典的文本内容作为所述文本对应的角色信息。在本发明的另一种实施例中,所述角色信息可以包括:角色实体,相应地,步骤102确定所述文本对应的内容要素信息的过程,可以包括:对所述文本进行命名实体识别,并从得到的识别结果中获取所述文本对应的角色实体。命名实体识别(NER,NamedEntityRecognition),是指识别文本中具有特定意义的实体。命名实体识别的方法具体包括但不限于:基于规则和词典的方法、基于统计的方法、二者混合的方法等。其中,基于统计的方法利用人工标注的语料进行训练,基于统计的方法可以包括但不限于:隐马尔可夫模型(HMM,HiddenMarkovMode)、最大熵(ME,MaxmiumEntropy)、支持向量机(SVM,SupportVectorMachine)、条件随机场(CRF,ConditionalRandomFields)。可以理解,本发明实施例对于命名实体识别的具体方法不加以限制。在本发明的一种可选实施例中,在从得到的识别结果中获取所述文本对应的角色实体后,可以判断该角色实体是否为文本对应的发声实体,若是,则将该角色实体作为所述文本对应的角色信息,否则,可以根据所述文本的句法分析结果和/或语义分析结果,确定所述文本对应的发声实体。例如,对于句子1“有一只青蛙长年住在一口枯井里。”,虽然可以从句子1中获取角色实体“青蛙”,但由于角色实体“青蛙”并非句子1的发声实体,故可以根据句子1的句法分析结果和/或语义分析结果,将叙述角色作为句子1对应的发声实体。又如,对于句子2“青蛙赶紧扯开嗓门喊了起来:“喂,海鳖兄,请过来,快请过来!””,虽然可以分别从句子2中的前一分句和后一分句中获取角色实体“青蛙”和“海鳖”,但由于角色实体“青蛙”并非前一分句“青蛙赶紧扯开嗓门喊了起来:”的发声实体、以及角色实体“海鳖”并非后一分句“喂,海鳖兄,请过来,快请过来!”的发声实体,故可以根据句子2的句法分析结果和/或语义分析结果,将叙述角色作为前一分句对应的发声实体、以及将“青蛙”作为后一分句对应的发声实体。需要说明的是,可以通过句法分析和/或语义分析方式,判断该角色实体是否为文本对应的发声实体,本发明实施例对于判断该角色实体是否为文本对应的发声实体的具体过程不加以限制。句法分析和/或语义分析为本领域中的自然语言处理方式。句法分析是指对句子中的词语语法功能进行分析,依存句法分析是一种常见的句法分析方式,在实际应用中,依存句法分析结果可以包括:依存树,该依存树可用于表征问题包括的各词汇之间的依存关系,对该依存树进行分析,并根据分析结果确定所述文本对应的发声实体。语义分析可用于分析一段文本所表达的含义。本发明实施例对于具体的句法分析和/或语义分析方法不加以限制。在本发明的一种实施例中,所述角色信息还可以包括:角色标签,所述角色标签用于表征所述角色实体对应的特征。可选地,所述角色标签可以包括:性别标签、年龄标签和性格标签中的至少一种。其中,性别标签、年龄标签可以适用于人物角色实体,如“小红帽”等。性格标签可以适用于人物角色实体和动物角色实体,如“小红帽”、“大灰狼”、“青蛙”、“海鳖”等。性格标签的例子可以包括:柔美、严肃等。当然,上述性别标签、年龄标签和性格标签只是作为角色标签的一种示例,实际上,本领域技术人员可以根据实际应用需求,采用任意的角色标签,如形象标签等,可以理解,本发明实施例对于具体的角色标签不加以限制。步骤102中,情绪信息可用于表征发声实体对应的情绪。该情绪可以指实体有喜、怒、哀、乐、惧等心理体验,这种体验是人对客观事物的态度的一种反映。情绪具有肯定和否定的性质:能满足人的需要的事物会引起人的肯定性质的体验,如快乐、满意等;不能满足人需要的事物会引起人的否定性质的体验,如愤怒、憎恨、哀怨等。根据一种实施例,情绪信息可以包括:肯定、否定和中性;根据另一种实施例,情绪信息可以包括:喜、怒、忧、思、悲、恐、惊等,可以理解,本发明实施例对于具体的情绪信息不加以限制。本发明实施例可以提供确定所述文本对应的内容要素信息的如下确定方式:确定方式1、将所述文本中的词汇与情绪词典进行匹配,并依据匹配结果确定所述文本对应的情绪信息;和/或确定方式2、采用情绪分类模型,确定所述文本对应的情绪信息;和/或确定方式3、对所述文本进行句法分析,并依据句法分析结果确定所述文本对应的情绪信息。对于确定方式1,情绪词典可用于记录情绪词汇,该情绪词汇可以包括:直接描述情绪的词汇、和/或、能引发情绪的词汇。参照表1,示出了本发明实施例的一种情绪词典的示例,其中记录有直接描述情绪的词汇。表1情绪词汇情绪悲伤悲伤心悲忧愁忧忧虑忧高兴喜参照表2,示出了本发明实施例的一种情绪词典的示例,其中记录有能引发情绪的词汇。表2情绪词汇情绪夭折悲壮志未酬悲困境忧渺茫忧吹嘘喜对于确定方式2,情绪分类模型可以为对情绪语料进行训练得到,其中,情绪语料可以为经过情绪类别标注的文本,通过训练可以使得情绪分类模型具备对于文本到情绪类别的分类能力。确定方式3的例子可以包括:获取上述所述文本中包括的动词、以及该动词对应的修饰词,根据该修饰词确定所述文本对应的情绪信息。例如,对于文本“高兴得在水里翻起跟头来”,可以确定动词“翻起跟头”及修饰词“高兴”,由此可以确定情绪信息“高兴”。可以理解,本领域技术人员可以根据实际应用需求,采用上述确定方式1至确定方式3中的任一或者组合,本发明实施例对于确定所述文本对应的内容要素信息的具体过程不加以限制。本发明实施例中,语音与内容要素信息相匹配可以包括:语音的语音参数与内容要素信息相匹配等,语音参数的例子可以包括:语速、音量和音色中的至少一种。根据一种实施例,语音的音色可以与角色信息相匹配,这样可以使得不同的角色信息对应不同的音色,例如,在《小红帽》中“小红帽”、“大灰狼”、“妈妈”、“猎人”、“叙述实体”等不同角色信息发声的情况下,至少两种角色信息所对应语音的音色可以相互不同(例如,“小红帽”、“大灰狼”所对应语音的音色不同等),由此可以实现分角色的语音的输出。根据另一种实施例,语音的语速和/或音量可以与情绪信息相匹配,这样可以使得不同的情绪信息对应不同的语速和/或音量。例如,“喜”、“怒”、“忧”、“思”、“悲”、“恐”、“惊”中的至少两种情绪信息所对应语音的语速和/或音量可以相互不同,由此可以实现分情绪的语音的输出。在本发明的一种可选实施例中,上述依据所述内容要素信息对所述文本进行语音合成的过程,可以包括:依据所述内容要素信息、以及内容要素信息与语音参数之间的映射关系,确定所述内容要素信息对应的目标语音参数;依据所述目标语音参数对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。本发明实施例可以预先建立内容要素信息与语音参数之间的映射关系,例如可以依据语料集合(包括内容要素信息对应的语音样本集合)得到内容要素信息与语音参数之间的初始映射关系,然后依据测试语音对初始映射关系进行调整,以得到内容要素信息与语音参数之间的当前映射关系,可以理解,可以根据测试语音对当前映射关系进行不断地调整和更新。TTS技术即将文字转换为语音的技术。语音合成技术的例子可以包括:基于隐马尔可夫模型(HMM,HiddenMarkovModel)的语音合成(HTS,HMM-basedSpeechSynthesisSystem),HTS的基本思路是:对语音信号进行参数化分解,并建立各声学参数对应的HMM模型,合成时利用训练得到的HMM模型对文本和目标语音参数对应的声学参数进行预测,这些声学参数被输入至参数合成器,最终得到合成语音。上述声学参数可以包括:频谱参数和基频参数中的至少一种。本发明实施例中,HMM模型的输入可以包括:文本和目标语音参数,由此可以得到文本和目标语音参数共同对应的声学参数,由于上述目标语音参数与上述内容要素信息相匹配,故可以得到与所述内容要素信息相匹配的语音。在实际应用中,可以对步骤103中得到的与所述内容要素信息相匹配的语音进行保存,或者,将步骤103中得到的与所述内容要素信息相匹配的语音输出给其他设备,或者,可以将步骤103中得到的与所述内容要素信息相匹配的语音发布到信息平台以供下载等,本发明实施例对于步骤103中得到的与所述内容要素信息相匹配的语音的后续处理方式不加以限制。综上,本发明实施例的处理方法,依据文本对应的内容要素信息,对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音;其中,在上述内容要素信息包括角色信息的情况下,可以实现分角色的语音的输出,进而可以提高语音的丰富度;在上述内容要素信息包括情绪信息的情况下,可以实现分情绪的语音的输出,进而可以提高语音的表现力。方法实施例二参照图2,示出了本发明的一种处理方法实施例二的步骤流程图,具体可以包括如下步骤:步骤201、接收文本;步骤202、确定所述文本对应的内容要素信息;所述内容要素信息可以包括:角色信息和/或情绪信息;步骤203、依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音;相对于图1所示方法实施例一,本实施例的方法还可以包括:步骤204、确定与所述内容要素信息相匹配的背景音频;步骤205、为与所述内容要素信息相匹配的语音添加对应的背景音频。本发明实施例可以将背景音频添加于与所述内容要素信息相匹配的语音对应的预设位置,上述背景音频与上述语音相结合,可以增强情感的表达,达到一种让用户身临其境的感受。本发明实施例中的背景音频可以与角色信息相匹配,例如,角色信息为例如“青蛙”的动物,则背景音频可以包括:例如“青蛙”的动物叫声。本发明实施例中的背景音频可以与情绪信息相匹配,例如,情绪信息为“喜”,则背景音频可以为“欢快”的音乐,又如,情绪信息为“悲”,则背景音频可以为“悲伤凄凉”的音乐。在本发明的一种可选实施例中,所述内容要素信息还可以包括:场景信息。场景信息可用于表征所处的场景,如自然场景(如海边、山脉、打雷、下雨等)、城市场景(如街道喧哗、室内桌子移动等)。本发明实施例中的背景音频可以与场景信息相匹配。例如,场景信息包括“打雷”和/或“下雨”,则背景音频可以为“打雷”和/或“下雨”对应的音频。又如,场景信息包括“桌子移动”,则背景音频可以为“桌子移动”对应的音频等。在实际应用中,可以预先建立背景标签与背景音频之间的映射关系,这样,可以将所述内容要素信息对应的关键词(如角色标签、角色标识、场景信息的关键词等),与背景标签与背景音频之间的映射关系中的背景标签进行匹配,以得到与所述内容要素信息相匹配的背景音频,可以理解,本发明实施例对于与所述内容要素信息相匹配的背景音频的具体获取方式不加以限制。步骤205中,可以将背景音频添加于与所述内容要素信息相匹配的语音对应的预设位置。可选地,该预设位置可以与语音同步,例如,在语音播放到“打雷”或者“下雨”时,可以同步播放“打雷”和/或“下雨”对应的音频;或者,在语音对于“打雷”的播放完毕后,再播放“打雷”对应的音频。在实际应用中,可以针对一个完整文本,确定其对应的语音时间轴,并将背景音频添加于该语音时间轴中的预设位置,例如,可以依据该背景音频对应的目标文本,将该背景音频与语音时间轴中目标文本对应的语音片段进行对齐,以使该预设位置与该语音片段同步,或者,可以使该预设位置滞后于该语音片段等,目标文本的例子可以参见前述的“打雷”或者“下雨”等,本发明实施例对于具体的预设位置不加以限制。方法实施例三参照图3,示出了本发明的一种处理方法实施例三的步骤流程图,具体可以包括如下步骤:步骤301、接收文本;步骤302、确定所述文本对应的内容要素信息;所述内容要素信息可以包括:角色信息和/或情绪信息;步骤303、依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音;相对于图1所示方法实施例一,本实施例的方法还可以包括:步骤304、接收用户的问题信息;步骤305、依据所述文本中包括的问答对,确定所述问题信息对应的答案信息。本发明实施例可以针对内容进行自动问答,具体地,可以针对用户的问题信息,依据所述文本中包括的问答对,确定所述问题信息对应的答案信息。其中,问答对可以指文本中包括:问题及其答复,可以预先从文本中抽取上述问答对并保存。以儿童故事对应的故事文本为例,由于其中的内容相对简单,结构清晰,故可以从中抽取得到准确率较高的问答对。预先从故事文本中抽取上述问答对的过程可以包括:从故事文本中获取具有问答关系的上下文,并对上下文进行语义分析,以得到该上下文中包括的问答对。以故事《小蝌蚪找妈妈》中“他们一起游到鸭妈妈身边,问鸭妈妈:“鸭妈妈,鸭妈妈,您看见过我们的妈妈吗?请您告诉我们,我们的妈妈是什么样的呀?”鸭妈妈回答说:“看见过。你们的妈妈头顶上有两只大眼睛,嘴巴又阔又大。你们自己去找吧。””、以及“大鱼笑着说:“我不是你们的妈妈。我是小鱼的妈妈。你们的妈妈有四条腿,到前面去找吧。””等故事文本为例,可以得到如下问答对:问题“小蝌蚪的妈妈长什么样”,答复“头顶上有两只大眼睛,嘴巴又阔又大,有四条腿…”,并对上述问答对进行保存。以故事《小马过河》中“小马赶紧跑过去问到:“牛伯伯,您知道那河里的水深不深呀?”牛伯伯挺起他那高大的身体笑着说:“不深,不深。才到我的小腿。””为例,可以得到如下问答对:问题“谁说河水浅”,答复“牛伯伯”。以故事《小马过河》中“小马高兴地跑回河边准备淌过河去。他刚一迈腿,忽然听见一个声音说:“小马,小马别下去,这河可深啦。”小马低头一看,原来是小松鼠。”为例,可以得到如下问答对:问题“谁说河水深”,答复“小松鼠”。在接收到用户的问题信息的情况下,预先保存的问答对可以作为问题信息对应的答案信息的获取依据。可选地,可以直接依据该问题信息在上述问答对中进行查询,以得到上述问题信息对应的答案信息。例如,若问题信息为“小蝌蚪的妈妈长什么样”,则可以通过查询得到对应的答案信息“头顶上有两只大眼睛,嘴巴又阔又大,有四条腿…”。又如,若问题信息为“谁说河水浅、谁说河水深”,可以通过查询上述问答对,并对得到的多条查询结果进行合并得到答案信息“牛伯伯说河水浅,小松鼠说河水深”。需要说明的是,对于方法实施例,为了简单描述,故将其都表述为一系列的运动动作组合,但是本领域技术人员应该知悉,本发明实施例并不受所描述的运动动作顺序的限制,因为依据本发明实施例,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的运动动作并不一定是本发明实施例所必须的。装置实施例参照图4,示出了本发明的一种处理装置实施例的结构框图,具体可以包括:接收模块401,用于接收文本;内容要素信息确定模块402,用于确定所述文本对应的内容要素信息;所述内容要素信息可以包括:角色信息和/或情绪信息;以及语音合成模块403,用于依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,所述角色信息可以包括:角色实体,所述内容要素信息确定模块可以包括:命名实体识别子模块,用于对所述文本进行命名实体识别,并从得到的识别结果中获取所述文本对应的角色实体。可选地,所述角色信息还可以包括:角色标签,所述角色标签用于表征所述角色实体对应的特征。可选地,所述角色标签可以包括:性别标签、年龄标签和性格标签中的至少一种。可选地,所述内容要素信息确定模块可以包括:第一情绪确定子模块,用于将所述文本中的词汇与情绪词典进行匹配,并依据匹配结果确定所述文本对应的情绪信息;和/或第二情绪确定子模块,用于采用情绪分类模型,确定所述文本对应的情绪信息;和/或第三情绪确定子模块,用于对所述文本进行句法分析,并依据句法分析结果确定所述文本对应的情绪信息。可选地,所述语音合成模块可以包括:目标语音参数确定子模块,用于依据所述内容要素信息、以及内容要素信息与语音参数之间的映射关系,确定所述内容要素信息对应的目标语音参数;语音合成子模块,用于依据所述目标语音参数对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,所述装置还可以包括:背景音频确定模块,用于确定与所述内容要素信息相匹配的背景音频;背景音频添加模块,用于为与所述内容要素信息相匹配的语音添加对应的背景音频。可选地,所述内容要素信息还可以包括:场景信息。可选地,所述装置还可以包括:问题接收模块,用于接收用户的问题信息;答案确定模块,用于依据所述文本中可以包括的问答对,确定所述问题信息对应的答案信息。对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。本发明实施例提供了一种用于处理的装置,该装置可以包括有存储器,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于进行以下操作的指令:接收文本;确定所述文本对应的内容要素信息;所述内容要素信息包括:角色信息和/或情绪信息;依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,所述角色信息包括:角色实体,所述确定所述文本对应的内容要素信息,包括:对所述文本进行命名实体识别,并从得到的识别结果中获取所述文本对应的角色实体。可选地,所述角色信息还包括:角色标签,所述角色标签用于表征所述角色实体对应的特征。可选地,所述角色标签包括:性别标签、年龄标签和性格标签中的至少一种。可选地,所述确定所述文本对应的内容要素信息,包括:将所述文本中的词汇与情绪词典进行匹配,并依据匹配结果确定所述文本对应的情绪信息;和/或采用情绪分类模型,确定所述文本对应的情绪信息;和/或对所述文本进行句法分析,并依据句法分析结果确定所述文本对应的情绪信息。可选地,所述依据所述内容要素信息对所述文本进行语音合成,包括:依据所述内容要素信息、以及内容要素信息与语音参数之间的映射关系,确定所述内容要素信息对应的目标语音参数;依据所述目标语音参数对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。可选地,所述装置还经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于进行以下操作的指令:确定与所述内容要素信息相匹配的背景音频;为与所述内容要素信息相匹配的语音添加对应的背景音频。可选地,所述内容要素信息还包括:场景信息。可选地,所述装置还经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于进行以下操作的指令:接收用户的问题信息;依据所述文本中包括的问答对,确定所述问题信息对应的答案信息。图5是根据一示例性实施例示出的一种用于处理的装置900作为终端时的框图。例如,装置900可以是移动电话,计算机,数字广播终端,消息收发设备,游戏控制台,平板设备,医疗设备,健身设备,个人数字助理等。参照图4,装置900可以包括以下一个或多个组件:处理组件902,存储器904,电源组件906,多媒体组件908,音频组件910,输入/输出(I/O)的接口912,传感器组件914,以及通信组件916。处理组件902通常控制装置900的整体操作,诸如与显示,电话呼叫,数据通信,相机操作和记录操作相关联的操作。处理元件902可以包括一个或多个处理器920来执行指令,以完成上述的方法的全部或部分步骤。此外,处理组件902可以包括一个或多个模块,便于处理组件902和其他组件之间的交互。例如,处理组件902可以包括多媒体模块,以方便多媒体组件908和处理组件902之间的交互。存储器904被配置为存储各种类型的数据以支持在设备900的操作。这些数据的示例包括用于在装置900上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。存储器904可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(SRAM),电可擦除可编程只读存储器(EEPROM),可擦除可编程只读存储器(EPROM),可编程只读存储器(PROM),只读存储器(ROM),磁存储器,快闪存储器,磁盘或光盘。电源组件906为装置900的各种组件提供电力。电源组件906可以包括电源管理系统,一个或多个电源,及其他与为装置900生成、管理和分配电力相关联的组件。多媒体组件908包括在所述装置900和用户之间的提供一个输出接口的屏幕。在一些实施例中,屏幕可以包括液晶显示器(LCD)和触摸面板(TP)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动运动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。在一些实施例中,多媒体组件908包括一个前置摄像头和/或后置摄像头。当设备900处于操作模式,如拍摄模式或视频模式时,前置摄像头和/或后置摄像头可以接收外部的多媒体数据。每个前置摄像头和后置摄像头可以是一个固定的光学透镜系统或具有焦距和光学变焦能力。音频组件910被配置为输出和/或输入音频信号。例如,音频组件910包括一个麦克风(MIC),当装置900处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器904或经由通信组件916发送。在一些实施例中,音频组件910还包括一个扬声器,用于输出音频信号。I/O接口912为处理组件902和外围接口模块之间提供接口,上述外围接口模块可以是键盘,点击轮,按钮等。这些按钮可包括但不限于:主页按钮、音量按钮、启动按钮和锁定按钮。传感器组件914包括一个或多个传感器,用于为装置900提供各个方面的状态评估。例如,传感器组件914可以检测到设备900的打开/关闭状态,组件的相对定位,例如所述组件为装置900的显示器和小键盘,传感器组件914还可以检测装置900或装置900一个组件的位置改变,用户与装置900接触的存在或不存在,装置900方位或加速/减速和装置900的温度变化。传感器组件914可以包括接近传感器,被配置用来在没有任何的物理接触时检测附近物品的存在。传感器组件914还可以包括光传感器,如CMOS或CCD图像传感器,用于在成像应用中使用。在一些实施例中,该传感器组件914还可以包括加速度传感器,陀螺仪传感器,磁传感器,压力传感器或温度传感器。通信组件916被配置为便于装置900和其他设备之间有线或无线方式的通信。装置900可以接入基于通信标准的无线网络,如WiFi,2G或3G,或它们的组合。在一个示例性实施例中,通信部件916经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信部件916还包括近场通信(NFC)模块,以促进短程通信。例如,在NFC模块可基于射频识别(RFID)技术,红外数据协会(IrDA)技术,超宽带(UWB)技术,蓝牙(BT)技术和其他技术来实现。在示例性实施例中,装置900可以被一个或多个应用专用集成电路(ASIC)、数字信号处理器(DSP)、数字信号处理设备(DSPD)、可编程逻辑器件(PLD)、现场可编程门阵列(FPGA)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述方法。在示例性实施例中,还提供了一种包括指令的非临时性计算机可读存储介质,例如包括指令的存储器904,上述指令可由装置900的处理器920执行以完成上述方法。例如,所述非临时性计算机可读存储介质可以是ROM、随机存取存储器(RAM)、CD-ROM、磁带、软盘和光数据存储设备等。图6是本发明的一些实施例中服务器的结构示意图。该服务器1900可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(centralprocessingunits,CPU)1922(例如,一个或一个以上处理器)和存储器1932,一个或一个以上存储应用程序1942或数据1944的存储介质1930(例如一个或一个以上海量存储设备)。其中,存储器1932和存储介质1930可以是短暂存储或持久存储。存储在存储介质1930的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器1922可以设置为与存储介质1930通信,在服务器1900上执行存储介质1930中的一系列指令操作。服务器1900还可以包括一个或一个以上电源1926,一个或一个以上有线或无线网络接口1950,一个或一个以上输入输出接口1958,一个或一个以上键盘1956,和/或,一个或一个以上操作系统1941,例如WindowsServerTM,MacOSXTM,UnixTM,LinuxTM,FreeBSDTM等等。一种非临时性计算机可读存储介质,当所述存储介质中的指令由装置(终端或者服务器)的处理器执行时,使得装置能够执行图1至图3所示的一种处理方法,所述方法包括:接收文本;确定所述文本对应的内容要素信息;所述内容要素信息包括:角色信息和/或情绪信息;依据所述内容要素信息对所述文本进行语音合成,以得到与所述内容要素信息相匹配的语音。本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本发明旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本
技术领域:
中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。以上对本发明所提供的一种处理方法、一种处理装置和一种用于处理的装置,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1