语音识别系统及其方法与词汇建立方法与流程
本发明是有关于一种可以根据非母语的语音词汇产生语音单元并且使用此语音单元进行识别的语音识别系统及其方法与词汇建立方法。
背景技术:
现有的语音识别系统多以识别单一语言为主。在多语言或混合语言的语音识别中,通常需要建立第一语言(例如,中文)以外的第二语言(例如,英文)的语音识别模型,或者建立第一语言的语音单元与第二语言的语音单元之间的对应关系。之后,才可以使用单一语言的语音识别模型进行多语言或混合语言的语音识别。然而,上述情况往往会造成许多问题。
以母语为中文(第一语言)、第二语言为英文的中英双语混合语音识别为例,上述的做法往往需要取得大量的英文语料以进行语音识别模型的训练。由于英文语料通常较容易通过以英文为母语的人所录制而得到,但因为腔调的差异,英文的语料与中文的语料两者在腔调上是不匹配的。当个别训练两者的语音识别模型时,会造成此两个语音识别模型也不相匹配,使得中英双语混合语音识别的识别率不佳,而难以应用。再者,以中文为母语的人所录制的英文语料也不容易搜集与校对,且各个以中文为母语的人对同一英文词汇的发音歧异度也大,故通常也不容易训练出在效能可赶得上中文语音识别的中文腔英文语音识别模型(Chinese-accented-English acoustic-model)。因此,实施多语言或混合语言的语音识别,所付出的资源与努力将远远超出单一语言的识别。
须注意的是,在一个多以母语为沟通的应用环境下,相对于母语,其他语言的使用频率通常是较低的。唯一较广泛使用的是所谓的「非母语词汇」(non-native word)或「外来语」(foreign-word or loan-blends)。随着时间推进,上述的非母语词汇或外来语也会不断地更新。另外,可以注意到的是,这里的使用族群,通常是以母语口音为主。若以前述多语言或混合语言的实施做法,所需要取得的是这些以母语口音为主的其他语言的大量语料。例如,取得中文口音的英文语料。然而,这些语料并不易于取得。
因此,如何提供一个适切的作法,以在不付出大量的资源下,建构可识别非母语词汇的语音识别系统,甚至可提供母语、非母语夹杂的语音识别系统,以让语音识别系统可更为广泛的应用,是本领域技术人员所致力研究的议题之一。
技术实现要素:
本发明提供一种根据非母语的语音词汇产生语音单元并且使用此语音单元进行识别的语音识别系统及其方法与词汇建立方法。
本发明提出一种语音识别系统。此系统包括储存单元以及处理单元。储存单元用以储存语音识别模型。语音识别模型具有多个语音单元以及多个基本成分声学模型,其中每一所述语音单元具有至少一时态,每一所述时态对应到基本成分声学模型的至少其中之一。处理单元用以运行多个模块,此些模块包括:分析扩充模块、输入模块、母语/非母语识别词汇功能模块以及语音识别器。输入模块用以输入第一语音信号。母语/非母语识别词汇功能模块用以从分析扩充模块取得母语/非母语词汇的语音单元序列。语音识别器用以根据语音识别模型与母语/非母语词汇的语音单元序列,对第一语音信号进行识别并输出识别结果。分析扩充模块用以根据语音识别模型以及由输入模块所输入的第二语音信号从基本成分声学模型中选择最佳基本成分声学模型,并根据此最佳基本成分声学模型更新语音单元。
本发明提出一种语音识别方法,此方法包括:储存语音识别模型,此语音识别模型具有多个语音单元以及多个基本成分声学模型,其中每一所述语音单元具有至少一时态,每一所述时态对应到所述基本成分声学模型的至少其中之一;输入第一语音信号;从分析扩充模块取得母语/非母语词汇的语音单元序列;根据语音识别模型与母语/非母语词汇的语音单元序列,对第一语音信号进行识别并输出识别结果;根据语音识别模型以及第二语音信号从基本成分声学模型中选择最佳基本成分声学模型,并根据此最佳基本成分声学模型更新语音单元。
本发明提出一种词汇建立方法,此方法包括:储存语音识别模型,此语音识别模型具有多个语音单元以及多个基本成分声学模型,其中每一所述语音单元具有至少一时态,每一所述时态对应到所述基本成分声学模型的至少其中之一;输入语音信号;根据语音识别模型以及语音信号从基本成分声学模型中选择最佳基本成分声学模型,并根据此最佳基本成分声学模型更新语音单元。
基于上述,本发明的语音识别系统及其方法与词汇建立方法可以在不录制大量非母语语料以及不重新训练声学模型的情况下来识别非母语的词汇。特别是,在新增用于识别非母语的词汇的语音单元时,所新增的语音单元并不会影响原本母语的识别效能。
为让本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图式作详细说明如下。
附图说明
图1是依据一范例实施例所绘示的语音识别系统的示意图。
图2是依据一范例实施例所绘示的语音识别模型的示意图。
图3是依据一范例实施例所绘示的基本成分声学模型的示意图。
图4A是依据一范例实施例所绘示的语音识别系统中各个模块的运作方式的示意图。
图4B是依据另一范例实施例所绘示的语音识别系统中各个模块的运作方式的示意图。
图5A是依据一范例实施例所绘示的语音单元序列产生模块的取代转换功能的示意图。
图5B是依据一范例实施例所绘示的仅根据语音信号来产生语音单元序列的示意图。
图6是依据一范例实施例所绘示的对语音信号进行切割的示意图。
图7是依据一范例实施例所绘示的选择最佳基本成分声学模型的示意图。
图8A是依据一范例实施例所绘示的新增语音单元至语音识别模型的示意图。
图8B是依据一范例实施例所绘示的更新语音识别模型中的新语音单元的示意图。
图9是依据一范例实施例所绘示的质量检验模块的运作的示意图。
图10是依据一范例实施例所绘示的基本成分组成更新模块的运作的示意图。
图11是依据一范例实施例所绘示的基本成分组成记录表的运作的示意图。
图12是依据一范例实施例所绘示的语音识别模型更新模块的运作的示意图。
图13是依据一范例实施例所绘示的语音识别的运作的示意图。
图14是依据一范例实施例所绘示的语音识别方法的流程图。
图15是依据一范例实施例所绘示的应用于分析扩充模块的方法的流程图。
附图标记说明:
1000:语音识别系统
100:处理单元
120:输入单元
130:储存单元
132:输入模块
134:语音识别模型
136:分析扩充模块
136a:语音单元序列产生模块
136b:语音信号时态切割模块
136c:时态基本成分挑选模块
136d:语音单元扩充模块
136e:迭代处理控制模块
136f:质量检验模块
136g:基本成分组成更新模块
136h:词汇的语音单元序列记录更新模块
136i:词汇的语音单元序列记录表
138:母语/非母语识别词汇功能模块
140:语法/语言模型
142:语音识别器
200:基本成分声学模型
40:语音信号
41:词汇
42:音标
500:转换表
510:语音单元识别器
520:语音单元
530:语音单元序列
60:语音特征参数抽取模块
61:切割模块
601:切割结果
t、τ:时间
701:比对结果
90:大词汇语音识别器
92:语音单元序列分数估算模块
94:语音识别模型还原模块
1001:基本成分分数正规化模块
1003:基本成分正规化分数累积与更新模块
1005:语音识别模型更新模块
11111:记录表
1101、1102、1103、1104、1105、1106、1107:子表格
步骤S1401:储存语音识别模型,语音识别模型具有多个语音单元以及多个基本成分声学模型,其中每一语音单元具有至少一时态,每一时态对应到基本成分声学模型的至少其中之一的步骤
步骤S1403:输入第一语音信号的步骤
步骤S1405:取得母语/非母语词汇的语音单元序列的步骤
步骤S1407:根据语音识别模型与母语/非母语词汇的语音单元序列,对第一语音信号进行识别并输出识别结果的步骤
步骤S1409:根据语音识别模型以及一第二语音信号从基本成分声学模型中选择最佳基本成分声学模型,并根据此最佳基本成分声学模型更新语音单元的步骤
步骤S1501:根据语音单元产生对应于第二语音信号的第一语音单元序列,其中第一语音单元序列包括语音单元中的第一语音单元的步骤
步骤S1503:根据第二语音信号的特征与第一语音单元序列对第二语音信号进行切割以产生多个子语音信号,其中此些子语音信号中的第一子语音信号对应至第一语音单元的时态中的第一时态,且第一时态对应至基本成分声学模型中的第一基本成分声学模型的步骤
步骤S1505:将第一子语音信号与基本成分声学模型进行比对,当第一子语音信号与基本成分声学模型中的第二基本成分声学模型的匹配程度大于第一子语音信号与第一基本成分声学模型的匹配程度时,选择第二基本成分声学模型为最佳基本成分声学模型的步骤
步骤S1507:判断第一语音单元是母语语音单元或新语音单元的步骤
步骤S1509:当第一语音单元是母语语音单元时,新增第二语音单元至语音单元中,其中第二语音单元的时态包括第二时态以及第三时态,第二时态对应至最佳基本成分声学模型且第三时态对应至第一语音单元的时态中的第四时态所对应的第三基本成分声学模型的步骤
步骤S1511:当第一语音单元是新语音单元时,根据最佳基本成分声学模型更新语音单元中的第一语音单元使得第一语音单元的第一时态对应至最佳基本成分声学模型的步骤
步骤S1513:根据更新后的语音单元产生对应于第二语音信号的第二语音单元序列,根据第二语音单元序列进行迭代操作以更新语音单元,其中第二语音单元序列包括第二语音单元的步骤
步骤S1515:根据第二语音单元序列计算对应于第二语音信号的第一分数,并判断第一分数是否小于第二语音信号的最佳识别结果的第二分数的步骤
步骤S1517:删除语音单元中的第二语音单元的步骤
步骤S1519:保留语音单元中的第二语音单元,根据第二时态所对应的第一基本成分声学模型排序结果计算对应于第二时态的多个第一基本成分正规化分数,根据第三时态所对应的第二基本成分声学模型排序结果计算对应于第三时态的多个第二基本成分正规化分数,根据第一基本成分正规化分数更新第二时态与基本成分声学模型之间的对应关系,以及根据第二基本成分正规化分数更新第三时态与基本成分声学模型之间的对应关系的步骤
具体实施方式
图1是依据一范例实施例所绘示的语音识别系统的示意图。请参照图1,在本范例实施例中,语音识别系统1000包括处理单元100、输入单元120以及储存单元130。其中,输入单元120耦接至储存单元130。储存单元130耦接至处理单元100。语音识别系统1000例如是行动装置、个人数字助理(Personal Digital Assistant,PDA)、笔记本电脑、平板计算机、一般桌面计算机等,或是其他的电子装置,在此并不设限。
处理单元100例如可以是一般用途处理器、特殊用途处理器、传统的处理器、数字信号处理器、多个微处理器(microprocessor)、一个或多个结合数字信号处理器核心的微处理器、控制器、微控制器、特殊应用集成电路(Application Specific Integrated Circuit,ASIC)、场可程序门阵列电路(Field Programmable Gate Array,FPGA)、任何其他种类的集成电路、状态机、基于进阶精简指令集机器(Advanced RISC Machine,ARM)的处理器以及类似品。
输入单元120例如是用以接收语音信号以及语音信号的音标或词汇并且提供所接收的语音信号以及语音信号的音标或词汇给储存单元130的装置或元件。举例来说,输入单元120例如可以包括用以采集语音信号的麦克风以及用以输入语音信号的音标或词汇的装置。或者,输入单元120也可以是用以从其他来源(例如,其他装置或储存媒体)接收语音信号以及语音信号的音标或词汇的装置。
储存单元130例如可以是任意型式的固定式或可移动式随机存取存储器(Random Access Memory,RAM)、只读存储器(Read-Only Memory,ROM)、闪存(Flash memory)、硬盘或其他类似装置或这些装置的组合。
在本范例实施例中,储存单元130储存有输入模块132、语音识别模型134、分析扩充模块136、母语/非母语识别词汇功能模块138、语法/语言模型140以及语音识别器142。特别是,分析扩充模块136包括语音单元序列产生模块136a、语音信号时态切割模块136b、时态基本成分挑选模块136c、语音单元扩充模块136d、迭代处理控制模块136e、质量检验模块136f、基本成分组成更新模块136g、词汇的语音单元序列记录更新模块136h以及词汇的语音单元序列记录表136i。其中,上述各个模块分别具有一或多个代码段,在上述代码段被安装后,会由处理单元100来执行。例如,处理单元100会借由这些模块来分别执行本发明的语音识别方法的各个运作。
特别是,语音识别模型134具有多个语音单元以及多个基本成分声学模型。其中每一个语音单元具有至少一时态,且每一时态会对应到上述的多个基本成分声学模型的至少其中之一。
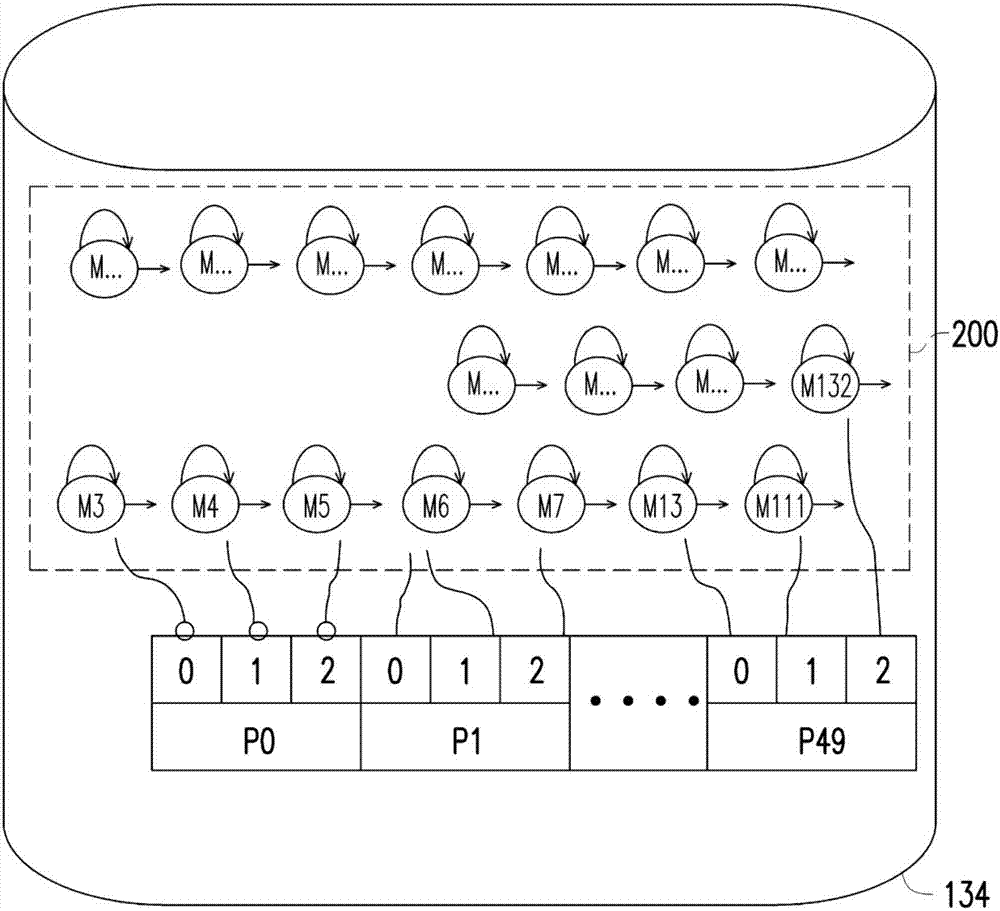
图2是依据一范例实施例所绘示的语音识别模型的示意图。
请参照图2,语音识别模型134包括多个语音单元。例如,语音单元P0至语音单元P49。特别是,在本范例实施例中,一个语音单元可以代表中文的一个单音段。例如,语音单元P0代表中文的空声母//(国际音标IPA标为),语音单元P1代表中文声母/ㄅ/也就是子音[p],语音单元P2代表中文声母/ㄆ/也就是子音[ph],语音单元P49代表中文双元音/ㄠ/中的第二元音,以此类推。
此外,每一个语音单元可以具有一到多个时态(state)。在本范例实施例中,每一个语音单元会具有三个时态。例如,语音单元P0包含了语音单元P0的第0个时态、第1个时态以及第2个时态;语音单元P1包含了语音单元P1的第0个时态、第1个时态以及第2个时态,以此类推。此外,语音识别模型134还包含了多个基本成分声学模型。为了简洁起见,图2绘示基本成分声学模型200来代表语音识别模型134所具有的多个基本成分声学模型。
特别是,一个语音单元的一个时态可以对应至一或多个基本成分声学模型。在本范例实施例中,一个时态是对应至一个基本成分声学模型。以语音单元P0为例,语音单元P0的第0个时态会对应至基本成分声学模型200中的基本成分声学模型M3,基本成分声学模型M3可以用来描述语音单元P0的第0个时态的信号的特征。语音单元P0的第1个时态会对应至基本成分声学模型200中的基本成分声学模型M4,基本成分声学模型M4可以用来描述语音单元P0的第1个时态的信号的特征。语音单元P0的第2个时态会对应至基本成分声学模型200中的基本成分声学模型M5,基本成分声学模型M5可以用来描述语音单元P0的第2个时态的信号的特征。
简单来说,在本范例实施例中,一个中文单音段可以被记录为一个语音单元,而语音单元可以包括第0个时态、第1个时态以及第2个时态。而每一个时态可以借由一个基本成分声学模型来做描述。
在本范例实施例中,语音识别模型134所具有的语音单元还可以再细分为母语语音单元以及新语音单元。在语音识别系统1000运作的初期,语音识别系统1000仅会包括用以描述母语的特性的母语语音单元(例如,中文的语音单元)。在经过本发明的语音识别方法的处理之后,语音识别模型134将增加出许多上述的新语音单元(例如,中文没有而英文才有的语音单元),此些新语音单元用以描述非母语的语音特性。
图3是依据一范例实施例所绘示的基本成分声学模型的示意图。
请参照图3,图3是用以描述图2中基本成分声学模型200的态样,它可以以高斯混合模型(Gaussian Mixture Model,GMM)组成或以类神经网络(Neural Networks,NN或Deep Neural Networks,DNN)输出层(output layer)中的某一个输出来代表。并且以自我转移(self-transition)与输出转移(transition-out)等两个转移机率(transition probability)来描述停留或离开该基本成分声学模型的机率。关于语音识别模型以GMM或NN/DNN的训练、实施等更细部的实作细节可以由现有技术所得知,在此便不再赘述。
图4A是依据一范例实施例所绘示的语音识别系统中各个模块的运作方式的示意图。图4B是依据另一范例实施例所绘示的语音识别系统中各个模块的运作方式的示意图。
请参照图4A,首先,输入模块132可以接收一个新的词汇41的语音信号40(亦称为,第二语音信号)与对应此语音信号的音标42。在本范例实施例中,所述新的词汇41是「today」。而对应此词汇41的音标42是//(注:为方便解说此处以一般人熟悉的KK音标表示,实作上可使用各种适当的音标符号或代号系统,只要能精确标记该发音即可)。之后,输入模块132会将「today」的语音信号40以及「today」这个词汇41与所对应的音标42输入至语音单元序列产生模块136a中。然而须注意的是,请参照图4B,在另一范例实施例中,当输入模块132仅接收到语音信号40时,输入模块132也可以仅将此语音信号40输入至语音单元序列产生模块136a中。此时,语音识别系统1000可以仅根据语音信号40来执行语音单元序列产生模块136a的运作,而不会使用词汇41的音标42来执行语音单元序列产生模块136a的运作。而仅根据语音信号40来执行语音单元序列产生模块136a的运作的详细流程请容后详述。
请再次参照图4A,语音单元序列产生模块136a会接收上述的语音信号40、语音信号40的词汇41与音标42。语音单元序列产生模块136a会先根据一已预先建立的词汇的语音单元序列记录表136i,寻找词汇41是否已有对应的语音单元序列,若词汇的语音单元序列记录表136i存在有词汇41「today」对应的语音单元序列,且是单一一个语音单元序列,则直接取用该语音单元序列,并进入语音信号时态切割模块136b进行处理。若词汇的语音单元序列记录表136i存在有多个语音单元序列与词汇41「today」对应,则将依照语音单元序列存放于语音单元序列记录表136i的顺序,循序取用,并进入语音信号时态切割模块136b进行处理。之后,语音信号时态切割模块136b会根据语音信号40进行切割以产生多个子语音信号。然而,倘若词汇的语音单元序列记录表136i不存在词汇41「today」对应的语音单元序列,语音单元序列产生模块136a将根据语音识别模型134中的语音单元P0~P49产生对应于语音信号40的语音单元序列。
举例来说,语音单元序列产生模块136a可以包括取代(substitution)转换功能、插入转换(Insertion)功能以及删除(Deletion)转换功能。
图5A是依据一范例实施例所绘示的语音单元序列产生模块的取代转换功能的示意图。
请参照图5A,语音单元序列产生模块136a可以接收「today」的语音信号40以及语音信号40所对应的音标42。语音单元序列产生模块136a可以根据转换表500来输出一或多个语音单元序列。其中,语音单元序列产生模块136a所输出的语音单元序列是使用中文的语音单元来描述(或近似)上述英文词汇「today」的发音。
例如,转换表500可以预先储存中文音标与英文KK音标的对应关系。语音单元序列产生模块136a可以根据音标//来输出以中文语音单元所表示的语音单元序列[P6 P31 P5 P32];或方便一般人阅读,可大略以中文注音/ㄊㄜㄉㄝ/表示。此外,语音单元序列产生模块136a也可以输出语音单元序列[P6 P31 P5 P35 P46],或以中文注音/ㄊㄜㄉㄟ/表示,其发音也是相近于KK音标中的//。须注意的是,不管是注音或KK音标符号,都只是为了方便一般人阅读的简略标示;真正精确的标示主要以国际音标IPA为准,或是以对应IPA的X-SAMPA符号标示。例如转换表500中P48与P49其实分别只代表双元音/ㄞ/与/ㄠ/的第二元音与(IPA国际音标)。因此,前述范例中的中文注音/ㄟ/的精确音标是对应至语音单元P35(双元音/ㄟ/的第一元音IPA[e])以及语音单元P46(双元音/ㄟ/的第二元音IPA)。
此外,本发明并不用于限定中文音标与英文音标的人工对应方式。两者之间的对应方式可以使用多种方法来实现。在一范例实施例中,可以预先储存中文音标所对应的语音单元以及英文音标所对应的语音单元。中文音标所对应的语音单元以及英文音标所对应的语音单元可以分别用区辨特征(Distinctive Features)向量表示。中文音标所对应的语音单元以及英文音标所对应的语音单元之间的近似程度可计算向量距离而得知。在另一实施例中,还可通过中文跟英文两套语料库,来计算两语言各别的语音单元之间的混淆矩阵(confusion matrix),并借以得到两语言语音单元间的距离。在另一实施例中,还可以通过中文跟英文两套语音识别器的声学模型,通过计算模型间的距离来得到两语言的语音单元间的距离。借由上述方式,可以得出与所输入的词汇的发音相接近的语音单元序列。
此外,在经由上述的取代转换功能产生语音单元序列后,语音单元序列产生模块136a还可以使用插入转换功能或删除转换功能来对所产生的语音单元序列进行修正。
例如,语音单元序列产生模块136a可以使用插入转换功能在所产生的语音单元序列中特定类型的连续语音单元之间,插入一特定类型的语音单元。举例来说,在一范例实施例中,语音单元序列产生模块136a可以根据母语的语音组合法(Phonotactics)来决定转换规则。以中文为例,中文的音节结构为「IGVC」。其中,「I」为「Initial」的缩写,代表声母子音。「G」为「Glide」的缩写,代表介音子音。例如中文音标中的/一/、/ㄨ/或/ㄩ/。「V」为「Vowel」的缩写,代表元音。「C」为「Coda」的缩写,代表音节尾子音。例如:[n]或。
以英文词汇「yesterday」为例,其可以经由上述的取代转换功能来产生语音单元序列[P41 P38 P21 P6 P33 P5 P35 P46],以注音简略表示为/一ㄝㄙㄊㄦㄉㄟ/。之后,可以再经由插入转换以产生新的语音单元序列[P41 P38 P21 P40 P6 P33 P5 P35 P46],以注音简略表示为/一ㄝㄙ帀ㄊㄦㄉㄟ/。由于中文的音节结构中,连续的子音只能有声母子音以及介音子音,因此在此范例中,连续子音/ㄙ/跟/ㄊ/之间需插入一个元音/帀/。换句话说,基于中文的自然发音习惯,子音/ㄙ/(语音单元P21)跟/ㄊ/(语音单元P6)之间可能会多一个元音/帀/(语音单元P40)(注:注音符号/帀/是/ㄓ/的颠倒符号,是/ㄙ/后面没有接其他韵母符号时的韵母,在习惯写法里面都被省略。正如「桑」的注音是/ㄙㄤ/,而「斯」的注音原本应该是/ㄙ帀/,但习惯上省略其韵母符号/帀/而简写为/ㄙ/)。
此外,语音单元序列产生模块136a也可以使用删除转换功能在所产生的语音单元序列中特定类型的连续语音单元之间,删除一特定类型的语音单元。其中,删除转换功能的实作方法相类似于上述的插入转换功能。举例来说,由于中文的音节结构中,音节尾子音的种类有限,只有[n]、[叼]六种;但是英文音节尾子音的种类比较多,因此不属中文音节尾子音可能在发音中被忽略,故可以删除对应的语音单元。
以英文词汇「word」为例,可以经由上述的取代转换功能来产生语音单元序列[P42 P33 P5],注音简略表示为/ㄨㄦㄉ/。之后可再经由删除转换功能产生新的语音单元序列[P42 P33],注音简略表示为/ㄨㄦ/。因为在中文音节中,子音/ㄉ/不会出现在音节尾,故许多以中文为母语的人在发音上自然会忽略上述/ㄉ/的音,故在此范例中,音节尾子音/ㄉ/可以删除。也就是原始语音单元序列[P42 P33 P5]中的语音单元P5会被删除。
值得一提的是,在图4B的范例实施例中,语音单元序列产生模块136a是不使用音标来进行识别。也就是说,输入模块132可以不用输入对应于语音信号40的音标42,语音单元序列产生模块136a可以直接根据所输入的语音信号40来进行语音识别以产生对应于语音信号40的语音单元序列。
例如,图5B是依据一范例实施例所绘示的仅根据语音信号来产生语音单元序列的示意图。
请参照图5B,在本范例实施例中,语音单元序列产生模块136a会包括语音单元识别器510。当语音单元序列产生模块136a仅接收到来自输入模块的语音信号40时,语音单元识别器510会分析语音信号40以判断组成词汇41的语音单元序列。举例来说,在一范例实施例中,由于语音识别模型134中会储存多个语音单元(例如,语音单元P0至语音单元P49以及语音单元sil,图5B以语音单元520表示),语音单元识别器510会将语音信号40与所述多个语音单元重复地比对以找出语音信号40中多个子语音信号所对应的语音单元,借以将所找出的语音单元组成一个语音单元序列。或者,在另一范例实施例中,语音识别系统1000可以预先储存多个不同词汇所对应的语音单元序列(例如,图5B中的多个语音单元序列530,亦称为默认语音单元序列)。语音单元识别器510可以从此些默认语音单元序列中挑选出最近似于语音信号40的语音单元序列。
特别是,由于以中文音标来描述(或近似)一个英文词汇的发音时可能有多种的描述方式,故语音单元序列产生模块136a(或语音单元识别器510)所产生的语音单元序列可以有一或多个。例如,图5B中经由语音单元识别器510所取得的语音单元序列[P6 P31 P5 P32]与语音单元序列[P6 P31 P5 P35 P46]。当语音单元序列产生模块136a产生对应于语音信号40的多个语音单元序列时,语音识别系统1000可以从所产生的多个语音单元序列中择一来进行后续的流程。此外,语音识别系统1000也可以重复地从所产生的多个语音单元序列中选择一个不同的语音单元序列来重复地执行图4B中各个模块的运作。
请再次参照图4A与图4B,假设语音单元序列产生模块136a产生对应于「today」的语音单元序列[P6 P31 P5 P32](亦称为,第一语音单元序列)。之后,语音信号时态切割模块136b会根据语音信号40进行切割以产生多个子语音信号。
图6是依据一范例实施例所绘示的对语音信号进行切割的示意图。
请参照图6,语音信号时态切割模块136b可以包括语音特征参数抽取模块60和切割模块61。语音特征参数抽取模块60可以抽取语音信号40以得到多个的语音特征参数。之后,切割模块61会根据语音单元序列产生模块136a所产生的语音单元序列[P6 P31 P5 P32],来对语音信号40进行比对切割。一般来说,对语音信号40进行比对切割又称为强制校准(force alignment),也就是找出语音信号40与所给定的语音单元序列所对应的各个基本成分声学模型之间最佳的对应位置。
由于在实际的语音信号中,可能存在静音(silence,图6以sil表示)于语音单元序列的之前与之后,因此在现有技术中,常加入一个可有可无的语音单元sil(optional silence),于语音单元序列的前、后以吸收可能出现的静音段落。也就是说,切割模块61将会根据语音单元序列[P6 P31 P5 P32]、语音单元序列[sil P6 P31 P5 P32]、语音单元序列[P6 P31 P5 P32 sil]、语音单元序列[sil P6 P31 P5 P32 sil]等这几组可能出现的语音单元序列,对语音信号40进行切割(或称强制校准),以取得其中优选的一组为结果输出。详细来说,以语音单元序列[sil P6 P31 P5 P32 sil]这组语音单元序列为例,切割模块61将会对语音单元sil的第0个时态、第1个时态以及第2个时态所对应的基本成分声学模型M0、基本成分声学模型M1以及基本成分声学模型M2、语音单元P6的第0个时态、第1个时态以及第2个时态所对应的基本成分声学模型M10、基本成分声学模型M11以及基本成分声学模型M12、语音单元P31的第0个时态、第1个时态以及第2个时态所对应的基本成分声学模型M91、基本成分声学模型M92以及基本成分声学模型M93、以及其他语音单元每个时态所对应的基本成分声学模型与语音信号40进行强制校准,以得到每个基本成分声学模型与语音信号40最佳的对应位置,从而可得到每个基本成分声学模型对应于语音信号40的子语音信号的切割结果601。其中,每一个子语音信号会对应至一个语音单元的时态所对应的基本成分声学模型。
接着,请再次参考图4A与图4B,在语音信号时态切割模块136b产生切割结果601之后,时态基本成分挑选模块136c,会将切割结果601中的每一个子语音信号与语音识别模型134中的基本成分声学模型200进行比对。
图7是依据一范例实施例所绘示的选择最佳基本成分声学模型的示意图。
请参照图7,接续图6的范例,以切割结果601中时间间隔介于时间t与时间τ的子语音信号(亦称为,第一子语音信号)为例,第一子语音信号对应至语音单元P31(亦称为,第一语音单元)的第1个时态(亦称为,第一时态),且语音单元P31的第1个时态对应至基本成分声学模型M92(亦称为,第一基本成分声学模型)。时态基本成分挑选模块136c会根据第一子语音信号的特征以及语音识别模型134来进行比对,以从语音识别模型134中寻找是否有匹配度比基本成分声学模型M92更佳的基本成分声学模型,并且从语音识别模型134中选择最佳基本成分声学模型。
特别是,时态基本成分挑选模块136c可以根据下述方程式(1)来找出第一子语音信号所对应的最佳基本成分声学模型m*。
其中,o为观测序列,即前述的语音特征参数。λ为语音识别模型134。mi为语音识别模型134的基本成分声学模型。N为语音识别模型134中所有基本成分声学模型个数。由于本方法是在既有的语音识别模型134的基本成分声学模型中,选取最佳的基本成分声学模型,故在此阶段,语音识别模型134的基本成分声学模型是不改变的。也就是说,在此阶段中方程式(1)中的N是不变的。
在图7的范例实施例中,时态基本成分挑选模块136c可以根据切割结果601中所切割出的子语音信号来与语音识别模型134的基本成分声学模型进行比对。以语音单元P31为例,在切割结果601中,语音单元P31的第1时态是对应至基本成分声学模型M92。语音单元P31的第1个时态所对应的子语音信号(即,第一子语音信号)的时间起点为时间t,而语音单元P31的第1个时态所对应的子语音信号的时间终点为时间τ。通过上述方程式(1),时态基本成分挑选模块136c会将第一子语音信号与语音识别模型134中的基本成分声学模型进行比对。时态基本成分挑选模块136c会从语音识别模型134寻找与第一子语音信号具有最大相似度或匹配度的最佳基本成分声学模型。在本范例实施例中,假设第一子语音信号与基本成分声学模型M115(亦称为,第二基本成分声学模型)的匹配程度大于第一子语音信号与基本成分声学模型M92的匹配程度。此时,时态基本成分挑选模块136c会选择基本成分声学模型M115为第一子语音信号的最佳基本成分声学模型,如图7中的比对结果701所示。
请再次参照图4A与图4B,当时态基本成分挑选模块136c执行完上述的比对操作时,语音单元扩充模块136d会判断语音单元是母语语音单元或新语音单元,并且根据判断的结果执行不同的运作。
图8A是依据一范例实施例所绘示的新增语音单元至语音识别模型的示意图。
请参照图8A,接续图7,当时态基本成分挑选模块136c选择基本成分声学模型M115为第一子语音信号的最佳基本成分声学模型时,语音单元扩充模块136d会判断第一子语音信号所对应的语音单元P31是母语语音单元或是新语音单元。
当语音单元P31原本就是一母语语音单元时,语音单元扩充模块136d会新增一个语音单元P50(亦称为,第二语音单元)至语音识别模型134的语音单元中。其中,语音单元P50的第0个时态以及第2个时态会分别对应至语音单元P31的第0时态与第2时态所对应的基本成分声学模型M91与基本成分声学模型M93。而语音单元P50的第1个时态会对应至上述所选出的最佳基本成分声学模型(也就是,基本成分声学模型M115)。特别是,上述语音单元P50的第1个时态可以称为「第二时态」,语音单元P50的第0个时态以及第2个时态可以称为「第三时态」。语音单元P31的第0个时态与第2个时态可以称为「第四时态」。基本成分声学模型M91与基本成分声学模型M93可以称为「第三基本成分声学模型」。此外,所新增的语音单元P50是被归类为新语音单元。
然而,假设语音单元P31是之前新增的一新语音单元时,语音单元扩充模块136d会根据所选出的最佳基本成分声学模型更新语音单元P31使得该语音单元P31的一时态被更新以对应至所选择的最佳基本成分声学模型。根据最佳基本成分声学模型来更新新语音单元的实施例请容后详述。
之后,请再次参照图4A与图4B,语音识别系统1000在经语音单元扩充模块136d新增语音单元P50至语音识别模型134之后,迭代处理控制模块136e可以根据更新后的语音识别模型134的语音单元对语音信号40产生新的语音单元序列[P6 P50 P5 P32]。须注意的是,不同于原先语音单元序列产生模块136a所产生的语音单元序列[P6 P31 P5 P32],语音单元P31已被取代为语音单元P50。之后,语音信号时态切割模块136b、时态基本成分挑选模块136c以及语音单元扩充模块136d会根据新产生的语音单元序列[P6 P50 P5 P32]进行迭代操作。其中迭代操作例如是语音信号时态切割模块136b、时态基本成分挑选模块136c以及语音单元扩充模块136d重复地执行上述语音信号时态切割模块136b、时态基本成分挑选模块136c以及语音单元扩充模块136d的各个运作,以再次新增语音单元至语音识别模型134或更新语音识别模型134中的语音单元,借以得到最佳的结果。
详细来说,在迭代操作中,语音识别系统1000会通过语音信号时态切割模块136b来根据语音单元序列[P6 P50 P5 P32]的各个时态对语音信号40切割以产生多个子语音信号。之后,再通过时态基本成分挑选模块136c再次对切割结果中的每个子语音信号进行最佳基本成分声学模型的挑选。此时,可能还会改变语音单元序列[P6 P50 P5 P32]中的语音单元的基本成分声学模型。
图8B是依据一范例实施例所绘示的更新语音识别模型中的新语音单元的示意图。
请参照图8B,以语音单元P50为例,语音单元P50的第0个时态是对应至基本成分声学模型M91。假设在执行上述的迭代操作中,当经由时态基本成分挑选模块136c执行完上述的比对操作时,语音单元P50的第0个时态所对应的最佳基本成分声学模型是基本成分声学模型M101。此时,由于语音单元P50是新语音单元,故语音单元扩充模块136d会根据所选出的最佳基本成分声学模型更新语音单元P50使得语音单元P50的第0个时态对应至所选出的最佳基本成分声学模型(即,基本成分声学模型M101)。
此外,假设此时语音单元序列[P6 P50 P5 P32]中的语音单元P6、语音单元P5以及语音单元P32的其中之一的基本成分声学模型改变时,由于语音单元P6、语音单元P5以及语音单元P32皆为母语语音单元,故此时语音单元扩充模块136d将需再次新增新语音单元至语音识别模型134中。
之后,请再次参照图4A与图4B,假设在经由上述的迭代操作后,语音单元序列[P6 P50 P5 P32]中的语音单元的基本成分声学模型已不会再改变时,则语音识别系统1000会执行质量检验模块136f。
图9是依据一范例实施例所绘示的质量检验模块的运作的示意图。
请参照图9,质量检验模块136f包括大词汇语音识别器90、语音单元序列分数估算模块92以及语音识别模型还原模块94。
大词汇语音识别器90具有大量的词汇,例如20万个词汇。而当语音信号40的「today」输入至大词汇语音识别器90时,大词汇语音识别器90可以输出对应于语音信号40的最佳识别结果的词汇(假定为中文的「土地」)、对应的语音单元序列(亦称为,第三语音单元序列,假定为[P6 P27 P5 P26])、与对应的分数(亦称为,第二分数),此第二分数代表从大词汇语音识别器90所具有的词汇中识别出语音信号40所得的最佳分数。语音单元序列分数估算模块92用以根据语音单元序列[P6 P50 P5 P32]以及语音信号40计算对应于语音信号40的分数(亦称为,第一分数)。此第一分数代表使用语音单元序列[P6 P50 P5 P32]来识别出语音信号40所获得的分数。当上述的第一分数小于第二分数时,代表使用语音单元序列[P6 P50 P5 P32]来表示语音信号40是不合适的,也表示新产生的语音单元P50有可能有质量不佳的问题,质量检验模块136f的语音识别模型还原模块94会删除语音识别模型134中的语音单元P50。此时,会返回执行语音单元序列产生模块136a。语音单元序列产生模块136a会先确认词汇的语音单元序列记录表136i中是否有与词汇41对应的其他语音单元序列可用。倘若词汇的语音单元序列记录表136i中没有与词汇41对应的其他语音单元序列可用,则取用根据音标42转换所产生的其他语音单元序列中(或借由语音识别对语音信号40进行识别所产生的其他语音单元序列中),未曾被使用过的语音单元序列的其中之一。之后,再度执行前述语音信号时态切割模块136b、时态基本成分挑选模块136c、语音单元扩充模块136d、迭代处理控制模块136e、质量检验模块136f等模块的运作。
倘若语音单元序列产生模块136a已无任何其他语音单元序列可取用,或其所产生的其他语音单元序列皆已被使用过,则表示大词汇语音识别器90所输出对应于语音信号40的最佳识别结果的第三语音单元序列[P6 P27 P5 P26],为语音信号40最佳的表示。换句话说,可使用此第三语音单元序列[P6 P27 P5 P26]来做为语音信号40的标示。之后,词汇的语音单元序列记录更新模块136h会将词汇41「today」与所对应的第三语音单元序列[P6 P27 P5 P26]储存至词汇的语音单元序列记录表136i中并且结束图4A与图4B的运作。
然而,当上述的第一分数大于第二分数时,代表语音单元序列[P6 P50 P5 P32]对于语音信号40来说,可以得到较大词汇语音识别器90所识别出的结果更佳的分数,也表示「today」以语音单元序列[P6 P50 P5 P32]表示不会与大词汇语音识别器90所具有的多个词汇混淆,因此则可以结束质量检验模块136f的运作。
在执行完上述质量检验模块136f的运作后,请再次参照图4A与图4B,若第一分数大于第二分数时,语音识别系统1000才会执行基本成分组成更新模块136g。详细来说,上述分析程序会根据语音信号40产生新的语音单元P50。然而,语音识别系统1000还可以搜集多个由同一人或不同人所录制的关于词汇41「today」的语音信号以进行上述的分析。因此,在识别由同一人或不同人所录制的关于词汇41「today」的语音信号后,可能会分别地新增一个语音单元P50至语音识别模型134。此时,可以借由基本成分组成更新模块136g来对多个语音单元P50来进行正规化以产生一个正规化后的语音单元P50。
图10是依据一范例实施例所绘示的基本成分组成更新模块的运作的示意图。
请参照图10,基本成分组成更新模块136g包括基本成分分数正规化模块1001、基本成分正规化分数累积与更新模块1003以及语音识别模型更新模块1005。
详细来说,对于每一个语音单元P50,基本成分组成更新模块136g的基本成分分数正规化模块1001会根据语音单元P50中各个时态所对应的基本成分声学模型来计算对应于语音单元P50中各个时态的基本成分正规化分数。
例如,以图8A中右侧的语音单元P50为例,基本成分分数正规化模块1001会根据语音单元P50的第1个时态所对应的基本成分声学模型排序结果(亦称为,第一基本成分声学模型排序结果)计算对应于语音单元P50的第1个时态的多个第一基本成分正规化分数。其中,「基本成分声学模型排序结果」代表在时态基本成分挑选模块136b的比对过程中,语音识别模型134中的多个基本成分声学模型与语音单元P50的第1个时态的子语音信号的匹配程度的排序。例如,与语音单元P50的第1个时态的子语音信号的匹配程度最高的基本成分声学模型会被排列在基本成分声学模型排序结果的第一个。与语音单元P50的第1个时态的子语音信号的匹配程度次高的基本成分声学模型被排列在基本成分声学模型排序结果的第二个。与语音单元P50的第1个时态的子语音信号的匹配程度为第三高的基本成分声学模型被排列在基本成分声学模型排序结果的第三个,以此类推。
特别是,被排列在基本成分声学模型排序结果的第一个的基本成分声学模型会被给予一个基本成分正规化分数「N/N」。N代表语音识别模型134中基本成分声学模型的个数。也就是说,被排列在基本成分声学模型排序结果的第一个的基本成分声学模型的基本成分正规化分数的数值是等于「1」。
此外,被排列在基本成分声学模型排序结果的第二个的基本成分声学模型会被给予一个基本成分正规化分数「(N-1)/N」。被排列在基本成分声学模型排序结果的第三个的基本成分声学模型会被给予一个基本成分正规化分数「(N-2)/N」,以此类推。而被排列在基本成分声学模型排序结果的最后一个的基本成分声学模型会被给予一个基本成分正规化分数「1/N」。
类似地,基本成分分数正规化模块1001会根据语音单元P50的第0个时态的基本成分声学模型排序结果计算对应于语音单元P50的第0个时态的多个基本成分正规化分数,且基本成分分数正规化模块1001也会根据语音单元P50的第2个时态的基本成分声学模型排序结果计算对应于语音单元P50的第2个时态的多个基本成分正规化分数。而根据基本成分声学模型排序结果计算对应于语音单元P50的第0个时态与第2个时态的多个基本成分正规化分数的方式可以相同于前述计算语音单元P50的第1个时态的多个第一基本成分正规化分数的方法,故在此并不再赘述。特别是,对应于语音单元P50的第0个时态的多个基本成分正规化分数以及对应于语音单元P50的第2个时态的多个基本成分正规化分数可以统称为「第二基本成分正规化分数」。
之后,基本成分组成更新模块136g更用以根据上述的第一基本成分正规化分数更新所述第二时态与基本成分声学模型之间的对应关系,以及根据第二基本成分正规化分数更新第三时态与基本成分声学模型之间的对应关系。
具体来说,在基本成分分数正规化模块1001的运作之后,基本成分正规化分数累积与更新模块1003会产生一个基本成分组成记录表。
图11是依据一范例实施例所绘示的基本成分组成记录表的运作的示意图。
请参照图11,假设基本成分组成记录表11111中的子表格1101是记录根据语音信号Utt-1所产生的语音单元P50的第0个时态的基本成分声学模型排序结果(由大到小)以及基本成分声学模型排序结果中各个基本成分声学模型所对应的基本成分正规化分数。例如,子表格1101记录根据语音信号Utt-1所产生的语音单元P50的第0个时态中,与该时态的匹配度最高的基本成分声学模型是基本成分声学模型M101,而基本成分声学模型M101的正规化分数的数值为「1」。此外,子表格1101还记录根据语音信号Utt-1所产生的语音单元P50的第0个时态中,与该时态的匹配度是次高的基本成分声学模型是基本成分声学模型M90,而基本成分声学模型M90的正规化分数的数值为「0.9935」。以此类推。
类似地,子表格1103中是记录语音信号Utt-1所产生的语音单元P50的第1个时态的基本成分声学模型排序结果以及基本成分声学模型排序结果中各个基本成分声学模型所对应的基本成分正规化分数。子表格1104中是记录语音信号Utt-1所产生的语音单元P50的第2个时态的基本成分声学模型排序结果以及基本成分声学模型排序结果中各个基本成分声学模型所对应的基本成分正规化分数。
此外,基本成分分数正规化模块1001也会根据语音信号Utt-2产生语音单元P50的第0个时态的基本成分声学模型排序结果以及各个基本成分声学模型所对应的基本成分正规化分数。此时,基本成分正规化分数累积与更新模块1003会为每一个基本成分声学模型计算一个新的正规化分数,并根据新的正规化分数来来重新排序以产生一个新的基本成分声学模型排序结果。其中,所述新的正规化分数是将一个基本成分声学模型根据语音信号Utt-1所产生的基本成分正规化分数加上此基本成分声学模型根据语音信号Utt-2所产生的基本成分正规化分数。
举例来说,假设在语音信号Utt-1的第0个时态中,基本成分声学模型M101的正规化分数的数值为「1」,而在语音信号Utt-2的第0个时态中,基本成分声学模型M101的正规化分数的数值为「0.9804」。此时,基本成分声学模型M101的新的正规化分数的数值会被记录为「1.9804」。类似地,假设在语音信号Utt-1的第0个时态中,基本成分声学模型M90的正规化分数的数值为「0.9935」,而在语音信号Utt-2的第0个时态中,基本成分声学模型M90的正规化分数的数值为「1」。此时,基本成分声学模型M90的新的正规化分数的数值会被记录为「1.9935」。以此类推。
当经由上述方式计算完各个基本成分声学模型的新的正规化分数后,基本成分正规化分数累积与更新模块1003会根据此些新的正规化分数进行排序并将排序后的结果纪录于子表格1102中。可以看到的是,子表格1102中的基本成分声学模型M90是语音单元P50的第0个时态在正规化后匹配度最高的基本成分声学模型。
此外,基本成分正规化分数累积与更新模块1003可以根据语音信号Utt-3、语音信号Utt-4以及语音信号Utt-5重复的进行上述的运算。在完成上述的运算后,最后可以看到的是,在子表格1105中,语音单元P50的第0个时态在正规化后匹配度最高的基本成分声学模型是基本成分声学模型M101。
此外,语音单元P50的第1个时态以及语音单元P50的第2个时态也可以根据语音信号Utt-2、语音信号Utt-3、语音信号Utt-4以及语音信号Utt-5重复的进行上述的运算。在完成上述的运算后,最后可以看到的是,在子表格1106中,语音单元P50的第1个时态在正规化后匹配度最高的基本成分声学模型是基本成分声学模型M41。在子表格1107中,语音单元P50的第2个时态在正规化后匹配度最高的基本成分声学模型是基本成分声学模型M93。
图12是依据一范例实施例所绘示的语音识别模型更新模块的运作的示意图。
请参照图12,语音识别模型更新模块1005会根据上述基本成分正规化分数累积与更新模块1003的正规化的结果,将语音单元P50的第0个时态对应至基本成分声学模型M101,将语音单元P50的第1个时态对应至基本成分声学模型M41以及将语音单元P50的第2个时态对应至基本成分声学模型M93。之后,语音识别模型更新模块1005会将语音单元P50正规化后的各个时态的对应关系储存至语音识别模型134中。接着,词汇的语音单元序列记录更新模块136h会将词汇41「today」与所对应的语音单元序列储存至词汇的语音单元序列记录表136i中。之后结束图4A与图4B中各个模块的运作。
详细来说,通过上述运作,由于借由同一人或不同人所录制的关于词汇41「today」的语音信号40可能有腔调与发音的差异,亦可能产生不相同的语音单元序列,因此,词汇的语音单元序列记录更新模块136h还可以储存这些相异的语音单元序列至词汇的语音单元序列记录表136i的中。换句话说,同一词汇可以对应到多个不同的语音单元序列,即所谓的多重发音(multi-pronunciation)。
在经过前述非母语的词汇的新增之后,即可定义外来语的语音单元序列,并建构其所需的新语音单元,因此,除了可识别母语词汇,图1的语音识别系统1000也可以应用于识别新增的外来语的词汇。
图13是依据一范例实施例所绘示的语音识别的运作的示意图。
请参照图13,在图13中,语音识别系统1000中的分析扩充模块136可以执行上述图4A与图4B中各个模块的运作。在经由前述图4A与图4B中各个模块的运作之后,可在语音识别系统1000的语音识别模型134中新增可描述外来语词汇或非母语词汇所需的新语音单元,并可由新增的过程中,将非母语词汇加入至分析扩充模块136中的词汇的语音单元序列记录表136i。因此,可由非母语的语音单元序列来识别非母语词汇。
特别是,母语/非母语识别词汇功能模块138可由词汇的语音单元序列记录表136i中抽取(或取得)母语或非母语词汇的语音单元序列来识别母语或非母语的词汇。此外,语音识别系统1000中的语音识别器142可以借由母语/非母语识别词汇功能模块138以及语音识别模型134来执行语音识别的功能。也就是说,语音识别系统1000可以接收语音信号(亦称为,第一语音信号)来进行语音识别。例如,语音识别器142会通过母语/非母语识别词汇功能模块138从词汇的语音单元序列记录表136i取得母语/非母语词汇的语音单元序列。之后,语音识别器142会结合语音识别模型134与从语音单元序列记录表136i中所取得的母语/非母语词汇的语音单元序列,建构语音识别器142所需要的「识别搜寻网络(search-networks)」。之后,再进行语音识别并且输出对应的识别结果。在另一实施例中,语音识别器142可进一步结合语法/语言模型140、语音识别模型134与从语音单元序列记录表136i中所取得的母语/非母语词汇的语音单元序列,建构语音识别器142所需要的「识别搜寻网络(search-networks)」。至于如何通过母语/非母语识别词汇功能模块138、语法/语言模型140与语音识别模型134来执行语音识别功能的实作细节可以由现有技术所得知,在此便不再赘述。
图14是依据一范例实施例所绘示的语音识别方法的流程图。
请参照图14,在步骤S1401中,储存单元130会储存语音识别模型,此语音识别模型具有多个语音单元以及多个基本成分声学模型,其中每一语音单元具有至少一时态,每一时态对应到所述基本成分声学模型的至少其中之一。在步骤S1403中,输入模块132输入第一语音信号。在步骤S1405中,母语/非母语识别词汇功能模块138从分析扩充模块136取得母语/非母语词汇的语音单元序列。在步骤S1407中,语音识别器142根据语音识别模型134与母语/非母语词汇的语音单元序列,对第一语音信号进行识别并输出识别结果。在步骤S1409中,分析扩充模块136根据语音识别模型134以及由输入模块132所输入的一第二语音信号从基本成分声学模型中选择最佳基本成分声学模型,并根据此最佳基本成分声学模型更新语音单元。在此须说明的是,图14中并不用于限定步骤S1403、步骤S1405、步骤S1407以及步骤S1409之间的执行顺序。在一范例实施例中,也可以先执行步骤S1409,之后再执行步骤S1403、步骤S1405以及步骤S1407。
图15是依据一范例实施例所绘示的应用于分析扩充模块的方法的流程图。其中,图14的步骤S1409的实施细节可以由图15来进行说明。
请参照图15,首先在步骤S1501中,语音单元序列产生模块136a会根据语音识别模型的语音单元产生对应于所输入的第二语音信号的第一语音单元序列,其中此第一语音单元序列包括上述语音单元中的第一语音单元。接着,在步骤S1503中,语音信号时态切割模块136b会根据上述第二语音信号的多个特征与第一语音单元序列对第二语音信号进行切割以产生多个子语音信号,其中此些子语音信号中的第一子语音信号对应至第一语音单元的时态中的第一时态,且第一时态对应至基本成分声学模型中的第一基本成分声学模型。之后,在步骤S1505中,时态基本成分挑选模块136c用以将第一子语音信号与基本成分声学模型进行比对,当第一子语音信号与基本成分声学模型中的第二基本成分声学模型的匹配程度大于第一子语音信号与第一基本成分声学模型的匹配程度时,选择第二基本成分声学模型为最佳基本成分声学模型。在步骤S1507中,语音单元扩充模块136d判断第一语音单元是母语语音单元或新语音单元。
当第一语音单元是母语语音单元时,在步骤S1509中,语音单元扩充模块136d会新增第二语音单元至上述的语音单元中,其中此第二语音单元的时态包括第二时态以及第三时态,第二时态对应至最佳基本成分声学模型且第三时态对应至第一语音单元的时态中的第四时态所对应的第三基本成分声学模型。
当第一语音单元是新语音单元时,在步骤S1511中,语音单元扩充模块136d更用以根据最佳基本成分声学模型更新上述语音单元中的第一语音单元使得第一语音单元的第一时态对应至最佳基本成分声学模型。
之后,在步骤S1513中,迭代处理控制模块136e根据更新后的语音单元产生对应于第二语音信号的第二语音单元序列,其中此第二语音单元序列包括第二语音单元,其中语音信号时态切割模块136b、时态基本成分挑选模块136c以及语音单元扩充模块136d会根据此第二语音单元序列进行迭代操作以更新语音单元。
之后,在步骤S1515中,质量检验模块136f根据第二语音单元序列计算对应于第二语音信号的第一分数,并判断第一分数是否小于第二语音信号的最佳识别结果的第二分数。
当第一分数小于第二分数时,在步骤S1517中,质量检验模块136f会删除语音单元中的第二语音单元。
当第一分数非小于第二分数时,在步骤S1519中,质量检验模块136f会保留语音单元中的第二语音单元,且基本成分组成更新模块136g会根据第二语音单元的第二时态所对应的第一基本成分声学模型排序结果计算对应于第二时态的多个第一基本成分正规化分数以及根据第二语音单元的第三时态所对应的第二基本成分声学模型排序结果计算对应于第三时态的多个第二基本成分正规化分数。基本成分组成更新模块136g根据第一基本成分正规化分数更新第二语音单元的第二时态与基本成分声学模型之间的对应关系,以及根据第二基本成分正规化分数更新第二语音单元的第三时态与基本成分声学模型之间的对应关系。
综上所述,本发明的语音识别系统与语音识别方法可以在不录制大量非母语语料以及不重新训练声学模型的情况下来识别非母语的词汇。特别是,在新增用于识别非母语的词汇的语音单元时,所新增的语音单元并不会影响原本母语的识别效能。
虽然本发明已以实施例揭露如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,故本发明的保护范围当视权利要求书的界定为准。
- 还没有人留言评论。精彩留言会获得点赞!