一种语音识别系统的制作方法
本发明涉及语音识别技术领域,尤其涉及一种可以进行在线领域扩展的语音识别系统。
背景技术:
汉语不是拼读语言,如果没有上下文信息难以直接从音断定对应的汉字。传统的语音识别使用预先生成的静态解码网络进行解码,并且该解码网络通常是从音素直接映射为词语。该解码网络融合了要识别的音频内容的词语的概率分布信息。这样导致识别器从一个领域切换到另外一个领域时,性能会急剧下降,另外一些术语和新词可能总是无法正确识别。为了支持多个领域的识别,通常用一个模型来同时建模多个领域的词语的概率分布信息。这导致该模型概率分布比较平均(这意味着识别性能通常也比较平均),并且模型比较庞大。为了支持新词或者术语的识别,必须重新训练模型和构造识别器。这是非常耗费时间和资源的。
有鉴于上述的缺陷,本设计人,积极加以研究创新,以期创设一种可以进行在线领域扩展的语音识别系统,使其更具有产业上的利用价值。
技术实现要素:
为解决上述技术问题,本发明的目的是提供一种可以进行在线领域扩展,从而可快速提高特定领域的识别性能的语音识别系统。
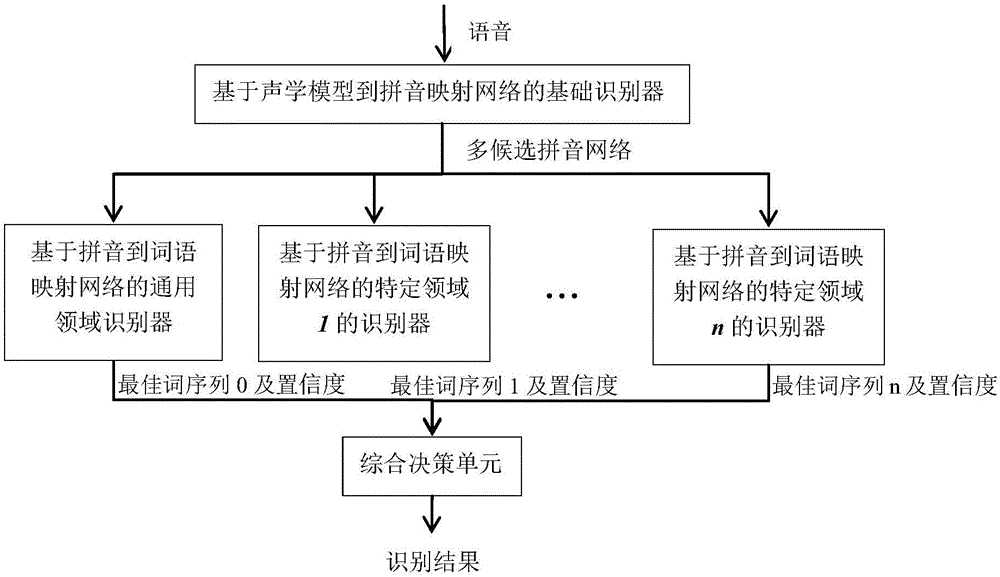
本发明的语音识别系统,包括
-基于声学模型到拼音映射网络的基础识别器,用于将语音映射为由多个候选拼音序列组织成的网络;
-多个并列的针对不同应用领域的基于拼音到词语映射网络的特定识别器,用于分别与由多个候选拼音序列组织成的网络进行组合,得到多个最佳词序列及置信度;
-综合决策单元,用于接收多个最佳词序列及置信度,然后根据置信度再加上预先给定的先验知识和规则以及附加知识,进行决策,选择最佳的词序列输出。
进一步的,通过调整拼音到词语映射网络,添加新的识别内容到已有领域的基于拼音到词语映射网络的特定识别器中,更新已有领域的识别内容;通过离线构造对应的基于拼音到词语映射网络的特定识别器,然后将扩展内容在线添加到基于拼音到词语映射网络的特定识别器中,创建新的应用领域的识别内容。
进一步的,所述基于声学模型到拼音映射网络的基础识别器根据输入的音频特征动态计算声学得分,并在其网络上保存有拼音序列的语言模型得分,采用动态规划算法结合声学得分和语言模型得分,搜索得分最高的若干拼音序列输出。
进一步的,所述拼音序列的语言模型采用基于长短时记忆单元的递归神经网络进行建模。
进一步的,所述综合决策单元通过融合识别置信度、先验知识和预设规则以及附加信息来选择最佳候选词序列。
进一步的,所述先验知识至少包括所述语音识别系统之外输入的关于领域的标识信息,或者根据识别结果历史信息得到的领域标识信息。
进一步的,所述领域标识信息为离散的0/1置,或连续的概率值。
进一步的,所述预设规则至少包括根据音频长度预估的词数范围。
进一步的,所述附加信息包括根据超级语言模型得到的关于识别结果词串符合语法规范的程度度量。
进一步的,所述综合决策单元将所述附加信息和预设规则通过分层加权的方式和置信度评分一起作为决策准则来选择候选词序列作为最终识别结果输出。
借由上述方案,本发明可以在线动态地将针对不同领域的基于拼音到词语映射网络的特定识别器添加到识别系统中去,可快速提高特定领域的识别性能;可快速定制扩展领域、添加热词/新词、定制领域识别内容;同时支持多个领域的识别,并保证其识别性能不下降。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
图1是本发明的语音识别系统框架图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
参见图1,本发明一较佳实施例所述的一种语音识别系统,由基本的基于声学模型到拼音映射网络的基础识别器和任意多个针对不同应用领域的基于拼音到词语映射网络的特定识别器以及一个综合决策单元共同组成,其中基于声学模型到拼音映射网络的基础识别器用于将语音映射为由多个候选拼音序列组织成的网络;各基于拼音到词语映射网络的特定识别器用于分别与由多个候选拼音序列组织成的网络进行组合,得到多个最佳词序列及置信度;综合决策单元用于接收多个最佳词序列及置信度,然后根据置信度再加上预先给定的先验知识和规则以及附加知识,进行决策,选择最佳的词序列输出。
本发明的针对不同领域的基于拼音到词语映射网络的特定识别器可以在线动态添加到识别系统中去,从而可快速提高特定领域的识别性能。本发明中,各基于拼音到词语映射网络的特定识别器是并列的,可以快速扩展。具体的,通过调整拼音到词语映射网络,添加新的识别内容到已有领域的基于拼音到词语映射网络的特定识别器中,更新已有领域的识别内容;通过离线构造对应的基于拼音到词语映射网络的特定识别器,然后将扩展内容在线添加到基于拼音到词语映射网络的特定识别器中,创建新的应用领域的识别内容。具体应用时,对已有领域的识别内容进行更新,比如新词/热词的添加,只需要调整拼音到词语映射网络,无需涉及声学模型和基本识别器的调整;新的应用领域识别内容的添加,比如:家居控制,车载导航等,只需要离线构造对应的拼音到词语映射网络,然后可以在线添加到识别系统中,从而不影响已有领域的识别进程。
本发明中基于声学模型到拼音映射网络的基础识别器根据输入的音频特征动态计算声学得分,并在其网络上保存有拼音序列的语言模型得分,采用动态规划算法结合声学得分和语言模型得分,搜索得分最高的若干拼音序列输出,且拼音序列的语言模型采用基于长短时记忆单元的递归神经网络进行建模。
本发明中的上述各网络在系统中具体表现为一个加权有限状态自动机(WFST,Weighted Finite State Transducers)。通过该自动机可以把输入的序列映射为另外的序列。在基于声学模型到拼音映射网络的基础识别器中,该网络上保存了拼音序列的语言模型得分,在解码过程中,根据输入的音频特征动态计算声学得分,采用动态规划算法在该WFST网络中结合声学得分和语言模型得分,搜索得分最高的若干拼音序列作为多候选结果输出。
具体实施时,拼音语言模型可以采用基于长短时记忆(LSTM,Long-short Term Memory)单元的递归神经网络(RNN,Recurrent Neural Network)进行建模,这样加强了拼音上下文的关联,提高了拼音多候选识别结果的准确性。
本发明中,基于拼音到词语映射网络的特定识别器其输入是表示多候选拼音序列的网络和拼音到词语的映射网络,输出是最佳词序列及其之置信度指标。多候选拼音序列网络可以表示为一个拼音到拼音映射的WFST,而拼音到词语的映射网络也表示成一个WFST,其路径权重为拼音序列到词序列的映射代价。识别过程首先是对两个WFST进行组合生成一个新的WFST,然后从该WFST中搜索得分最高的序列,输出其词序列和得分。
在本发明中,综合决策单元接收来自多个基于拼音到词语映射网络的特定识别器的输出,即词序列及其置信度,然后根据其置信度再加上预先给定的先验知识和规则以及附加知识,进行决策,选择最佳的词序列输出。特定的,所谓的先验知识至少包括:识别系统之外输入的关于领域的标识信息,或者根据识别结果历史信息得到的领域标识信息。所谓领域标识信息可以是离散的0/1置,也可以是连续的概率值。特定的,所谓的规则至少包括:根据音频长度预估的词数范围。根据词数范围,可以排除那些超长或者超短的识别结果。特定的,所谓附加信息可以包括根据超级语言模型得到的关于识别结果词串符合语法规范的程度度量。上述信息和规则通过分层加权的方式和置信度评分一起作为决策准则来选择候选词串作为最终识别结果输出。
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!