一种新型语音除噪方法与流程
本发明涉及智能语音识别技术领域,特别是涉及到一种能够利用DNN算法来剔除突发噪音的新型语音除噪方法。
背景技术:
随着人们生活水平的提高以及对电器的需求量不断增大,家用电器经过不断地改革和创新,拥有了更多使用的功能,比如微波炉,以往仅单纯的用于加热,到如今,微波炉增加了蒸煮、烧烤、热奶等功能且变得更加智能,市面出现的各种品牌的智能微波炉,主要由控制面板、观察窗、炉门安全锁系统、电源线和插头这四大部分组成,控制面板主要有功能设定、时间设定、重量设定等功能,功能设定主要是通过功能菜单实现,比如直接按清蒸鱼、蒸排骨、煮米饭等按钮,自动实现不同的加热方式,各类不同品牌的智能微波炉使用步骤都大同小异。
语音交互作为最有效的沟通控制方式,可以帮助用户把家中的各种终端设备无缝连接起来,智能语音微波炉就是其中之一,用户通过简单的语音命令即可控制微波炉进行不同的工作,在语音识别方面,为了增强用户的体验感和语音识别的准确率,研发人员通过技术互相关时延等算法获取人说话的位置,然后将此位置锁定,抑制其他位置的声源,提高信噪比,为高语音识别率做保障,声源锁定虽然可提高信噪比,但当环境中突然出现大噪声时,会将声源焦点转移,导致大噪声后语音指令无法被电子设备识别到,这就降低了用户的智能体验感和语音识别的准确率。
技术实现要素:
为了解决上述突然出现的大噪声的语音识别问题,发明了一种能够有效剔除突发大噪声的新型语音除噪方法。
一种新型语音除噪方法,其包括以下步骤:
步骤一 语音采集模块采集外部语音数据并发送给语音识别模块;
步骤二 所述语音识别模块检测设备状态,判断所述设备是处于工作状态还是非工作状态;
步骤三 当检测到所述设备为非工作状态时,所述语音识别模块置于大噪音去噪模式对所述语音数据去噪,当检测到所述设备为工作状态时,所述语音识别模块置于常规去噪模式对所述语音数据去噪;
步骤四 将去噪后的所述语音数据经傅立叶变换输入语音识别引擎;
步骤五 所述语音识别引擎采用DNN(深度神经网络)算法在本地终端对所述语音数据进行识别;
步骤六 语音识别模块将步骤四的识别结果发送给设备控制电路;
步骤七 所述设备控制电路根据所述识别结果控制所述设备执行操作。
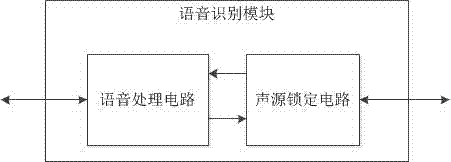
作为本发明的优选方案,所述语音识别模块由语音处理电路和声源锁定电路组成,所述语音处理电路处理所述语音采集模块采集到的所述语音数据,所述声源锁定电路根据所述语音分析电路的处理结果锁定声源的位置。
作为本发明的优选方案,所述语音识别模块包含有两种去噪模式,分别为所述大噪音去噪模式和常规去噪模式,所述大噪音去噪模式和常规去噪模式不能同时运行,是非此则彼的关系。
所述DNN算法包括有语音预处理、特征提取、形成发音字典及建立语音模型等四个过程,其中语音预处理过程包括对语音信号或语音数据的采样、反混叠滤波、语音增强和端点检测,特征提取过程的作用是从语音信号或语音数据的波形中提取一组能够描述语音信号或语音数据特征的参数,以便训练和识别,形成发音字典则是根据发音的音素,得到相应的文本集合即为发音字典,建立语音模型则是利用语法知识调整声学模型所识别出的不合逻辑的词语。
作为本发明的优选方案,所述语音采集模块包含有N个语音采集设备,所述N为大于等于2的正整数,N个所述语音采集设备根据客户需求进行排列,可以进行横排也可以进行竖排。
为了使音频数据容易被神经网络处理,需要把复杂的声波分解成一个个组成部分,为实现声波分解,需要利用到傅里叶变换,傅立叶变换将复杂的声波分解为简单的声波,然后将每一份频段所包含的能量加在一起,得到的结果便是从低音到高音的一个频谱,再将该频谱输入深度神经网络,对于每个小的音频切片,神经网络都将尝试找出当前正在说的声音所对应的声母或韵母,当通过神经网络跑完我们的整个音频剪辑之后,最终得到一份映射,其中标明了每个音频块和其最有可能对应的声母或韵母,然后将这些基于发音的预测与基于标注的文本数据库的可能性得分相结合,去掉最不可能的结果,留下最实际的结果。
与现有技术相比,本发明的有益效果:
1、由于采用了大噪声去噪电路,该去噪电路可以将突发的大噪声剔除,保证了声源识别的准确性。
附图说明
图1为本发明语音除噪方法的流程图;
图2为本发明语音识别模块的框图;
图3为本发明DNN算法框图。
具体实施方式
下面结合实施例及具体实施方式对本发明作进一步的详细描述,但不应将此理解为本发明上述主体的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
如图1所示,一种新型语音除噪方法,包含如下步骤:
步骤一 语音采集模块采集外部语音数据并发送给语音识别模块,本实施例中语音采集模块的语音采集设备使用麦克风,使用两个并排排列的麦克风进行语音数据的收集;
步骤二 语音识别模块检测设备状态,判断设备是处于工作状态还是非工作状态,本实施例中的设备是微波炉;
步骤三 当检测到微波炉为非工作状态时,语音识别模块置于大噪音去噪模式对语音数据去噪,当检测到微波炉为工作状态时,语音识别模块置于常规去噪模式对语音数据去噪;
步骤四 将去噪后的语音数据经傅立叶变换输入语音识别引擎;
步骤五 语音识别引擎采用DNN(深度神经网络)算法在本地终端对语音数据进行识别;
步骤六 语音识别模块将步骤四的识别结果发送给设备控制电路;
步骤七 设备控制电路根据识别结果控制微波炉执行各项操作。
如图2所示,语音识别模块由语音处理电路和电源锁定电路组成,语音处理电路处理由麦克风传输来的所采集的语音数据,并将处理结果传输给电源锁定电路,电源锁定电路根据处理结果锁定声源的位置并同时屏蔽掉声源之外的噪声。
如图3所示,DNN算法包括语音预处理、特征提取、形成发音字典及建立语音模型等四个过程,其中语音预处理过程包括对语音信号或语音数据的采样、反混叠滤波、语音增强和端点检测,特征提取过程的作用是从语音信号或语音数据的波形中提取一组能够描述语音信号或语音数据特征的参数,以便训练和识别,形成发音字典则是根据发音的音素,得到相应的文本集合即为发音字典,建立语音模型则是利用语法知识调整声学模型所识别出的不合逻辑的词语。
- 还没有人留言评论。精彩留言会获得点赞!