成长型对话装置的制作方法
本发明涉及成长型对话装置,特别涉及适合获得用来自动进行声音对话的知识信息的成长型对话装置。
背景技术:
开发了在计算机或机器人与作为人的用户之间通过声音进行对话的系统(以下,称作对话系统)。搭载了该对话系统的机器人、或者智能电话、平板pc等设备(以下称作“对话设备”)使对话系统动作,对于对面的用户实施基于声音对话的服务。
在该对话系统中,首先,用麦克风收集用户讲话的声音,进行声音识别。接着,对于被写出的文本,通过被称作意图理解的处理,判别用户说了想要对话系统做什么。最后,基于判别结果,对话设备执行用户希望的动作,例如对于询问的回答的朗读或信息的显示等动作,如果是机器人则进行移动等动作。
在该对话系统中,在用户进行了系统不知道回答的询问的情况下,以往对话系统做出“不知道”等回答,但可以相反地从系统向用户寻求该询问的回答,以该结果来更新询问应答的知识。在专利文献1中公开了这样的对话系统的结构。在专利文献1的声音对话装置中,在从用户听到了不知道的内容的情况下向该用户反问其回答,将该询问内容和回答进行存储,用于以后的对话。因此,因不知道的对话内容而使对话中断、或变更用户提示的话题的必要性变小,并且能够通过学习,增加新的情景(scenario)及语汇来提高知识,并反映到从下次起的与用户的对话。
同样,对话系统中也存在如下系统结构:不是学习询问的回答内容本身,而是学习在用户使用的询问中所使用的表现,并更新知识以便能够应对变化更大的询问表现。
专利文献1:日本特开2004-109323号公报
在以往的对话系统中,如上述那样进行反问等而得到的知识通常被用在该系统在这以后进行声音对话的全部用户及全部上下文中。但是,新学习的回答知识可以分类为总是能使用的知识、仅特定的对话设备可以使用的知识、或能够在承担特定作用的对话设备间共用的知识等。同样,与询问表现的变化有关的知识也可以分类为总是能使用的知识、仅能对特定的用户使用的知识(或对特定的用户特别有效的知识)、在对话情景的特定的上下文中能使用的知识等。
在以往的对话系统中,并没有考虑到基于这样的知识的特性来切换将所得到的知识在怎样的情况下使用为好。因此,有将与某用户的个人信息有关的回答知识用于其他用户、或学习仅特定的用户使用的询问表现知识等,从而降低对话的精度等的问题。
技术实现要素:
本发明提供在利用声音进行学习的对话系统中、基于知识的特性将所得到的知识适当地分类而用于对话、从而能够提高对话的精度的成长型对话装置。
本发明的成长型对话装置的结构优选的是,与用户进行声音对话并将声音对话的结果作为知识进行储存的成长型对话装置,具有:声音识别部,根据所取得的用户的讲话声音进行声音识别,并转化为文本;意图理解部,参照根据意图理解学习数据进行学习而得到的意图理解模型数据,从由声音识别部进行声音识别而得到的文本,解析讲话意图;应答生成部,参照qadb,根据由意图理解部解析出的讲话意图生成应答文本;知识提取部,从由声音识别部进行声音识别而得到的文本、讲话意图、应答文本,提取知识;以及知识分类部,将由知识提取部提取出的知识根据特性进行分类。
发明效果
根据本发明,能够提供在利用声音进行学习的对话系统中、基于知识的特性将所得到的知识适当地分类而用于对话、从而能够提高对话的精度的成长型对话装置。
附图说明
图1是表示有关实施方式1的成长型对话装置的功能结构的图。
图2是表示意图理解用模型数据的一例的图。
图3是表示意图理解用学习数据的一例的图。
图4是表示qadb的一例的图。
图5是表示有关实施方式1的成长型对话装置的处理的流程的图。
图6是表示有关实施方式1的知识分类处理的流程图。
图7是表示情景上下文依赖度及任务上下文依赖度的计算处理的流程图。
图8是表示个人性依赖度的计算处理的流程图。
图9是表示有关实施方式2的成长型对话装置的功能结构的图。
图10是表示有关实施方式2的成长型对话装置的处理的流程的图。
图11是表示有关实施方式2的知识分类处理的流程图。
标号说明
101用户讲话声音
102讲话区间检测处理
103声音识别处理
104意图理解处理
105应答生成处理
106声音合成处理
107应答声音
108声音识别用模型数据
109意图理解用模型数据
110意图理解模型学习处理
111qadb(通常)
113qadb(特定任务)
114qadb(特定设备)
117工作日志
118知识提取处理
120知识分类处理
121意图理解用学习数据(通常)
122意图理解用学习数据(特定用户)
123意图理解用学习数据(情景节点)
124知识保存处理
具体实施方式
以下,使用图1至图11说明有关本发明的各实施方式。
〔实施方式1〕
以下,使用图1至图8说明本发明的实施方式1。
首先,使用图1对有关实施方式1的成长型对话装置的结构进行说明。
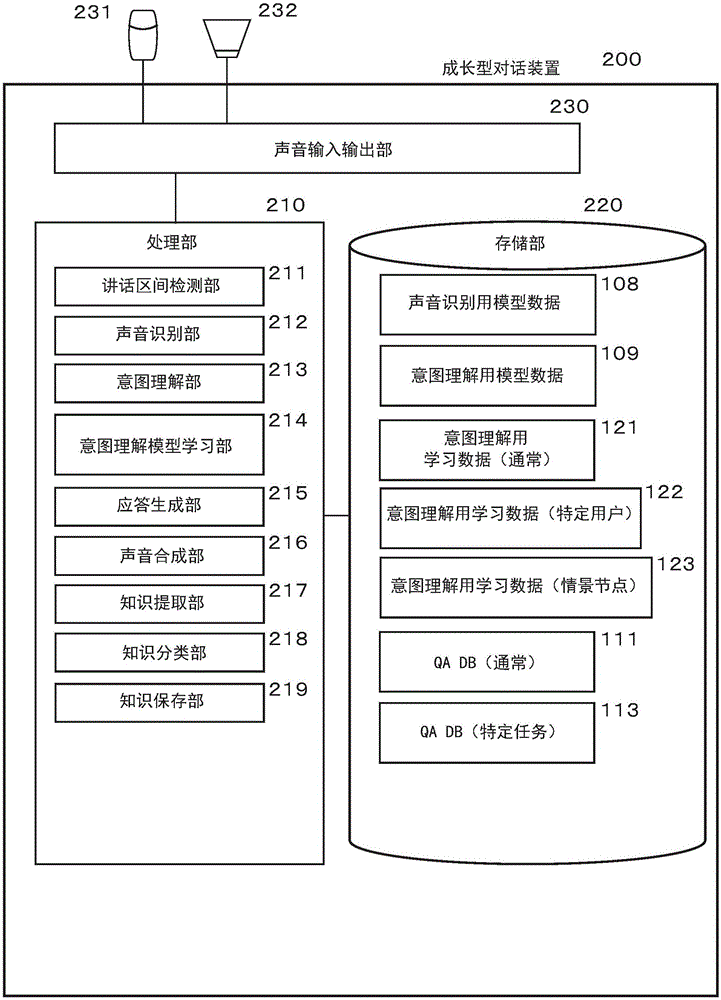
有关本实施方式的成长型对话装置200如图1所示,由处理部210、存储部220、声音输入输出部230构成。成长型对话装置200既可以是pc或智能电话等通常的信息处理装置,也可以是用来施行特定的业务的机器人。
在声音输入输出部230上,连接着麦克风231和扬声器232,从麦克风231输入用户的声音,从扬声器232向用户输出声音。
处理部210是执行成长型对话装置200的各处理的部分,由讲话区间检测部211、声音识别部212、意图理解部213、意图理解模型学习部214、应答生成部215、声音合成部216、知识提取部217、知识分类部218、知识保存部219的子组件构成。
处理部210的子组件的功能通过由作为硬件的中央处理装置(cpu)执行主存储装置上的程序而被执行。
讲话区间检测部211是从用户声音中检测无声部、检测讲话区间的功能部。声音识别部212是对用户声音进行声音识别而转化为文本的功能部。意图理解部213是根据进行声音识别而得到的文本,阐释用户的讲话意图的功能部。意图理解模型学习部214是根据意图理解学习数据(后述)生成意图理解模型数据(后述)的功能部。应答生成部215是基于意图理解部213的处理来生成用于成长型对话装置200的应答的数据的功能部。声音合成部216是成长型对话装置200生成用于向用户应答的声音数据的功能部。知识提取部217是基于应答生成部215的处理来获得知识信息的功能部。知识分类部218是判定由知识提取部217提取的知识信息的保存部位的功能部。知识保存部219是将知识信息向qadb(后述)和意图理解学习数据(后述)保存的功能部。
存储部220是保存用来执行成长型对话装置200的各处理的所需数据的部分,存储声音识别用模型数据108、意图理解用模型数据109、意图理解用学习数据(通常)121、意图理解用学习数据(特定用户)122、意图理解用学习数据(情景节点)123、qadb(通常)111、qadb(特定任务)113的各种数据。
声音识别用模型数据108是用来将声响数据变换为音素或识别词语的连接的由概率值构成的声音识别用的基准数据。意图理解用模型数据109是用来从识别出的文本提取意图的基准数据。意图理解用学习数据是用来将识别出的文本与用户的讲话意图联系起来的学习数据。对于本实施方式的意图理解用学习数据,设想意图理解用学习数据(通常)121、意图理解用学习数据(特定用户)122、意图理解用学习数据(情景节点)123这三个种类的学习数据。关于意图理解用学习数据的详细情况,在后面说明。
qadb(questionandanswerdatabase:问答数据库)是将用户的讲话意图与用来应答的回答联系起来的数据。对于本实施方式的qadb,设想qadb(通常)111、qadb(特定任务)113这两个种类的db。
接着,使用图2至图4,对在本实施方式的成长型对话装置中使用的数据构造的主要部分进行说明。
意图理解用模型数据109是用来从识别出的文本提取意图的基准数据,如图2所示,由文本109a、命令109b、置信度109c的字段构成。
文本109a是保存从意图理解用学习用数据得到的文本的单词序列的字段。命令109b是保存用于成长型对话装置动作的命令的字段。置信度109c是保存将在与用户的对话中出现了文本109a的单词时、成长型对话装置用记述在命令109b中的命令进行应对时的或然性在0~1之间进行数值化的概率的字段。
例如,在图2的第三记录所示的例子中,表示了当在与用户的对话中出现了“高尾山”、“高度”、“几米”或“高”这样的单词时,作为询问的应答而回答高尾山的高度的置信度是0.9。
意图理解用学习数据(通常)121是用来根据被识别出的文本学习意图并制作意图理解用模型数据109的元数据,如图3所示,由文本121a、命令121b的字段构成。
文本121a是保存将用户的对话进行声音识别而写出的文本的字段。命令121b是保存与文本121a对应的用于成长型对话装置进行动作的命令的字段。在图3所示的例子中,表示了与命令121b作为询问应答而回答“高尾山的高度”的情况对应的文本是“高尾山的高度是”、“高尾山的高度是多少”、“高尾山与富士山的高度相差多少”等。
此外,虽然作为图没有表示,但意图理解用学习数据(特定用户)122是按每个特定的用户分别存在的学习数据,在没有进行对于该用户的知识获得的情况下内容物为空。
进而,虽然作为图没有表示,但意图理解用学习数据(情景节点)123是按每个特定的情景树(scenariotree)而存在的学习数据。这里,情景树是表示成长型对话装置的对话中的对应的树,情景节点是表示对话装置的对应的有限状态的节点。成长型对话装置按照情景树被设计成,通过来自用户的对话的输入而变迁节点,进行向用户的对话的应答。
qadb(通常)111是对应于询问回答的内容而保存其回答的数据,如图4所示,由i字段111a、a字段111b构成。
i字段111a是保存表示询问的意图标签的字段。这里,意图标签如“高尾山的高度”、“高尾山的位置”等那样,是表示询问的意图的识别码。a字段111b是保存与i字段111a的询问的意图对应的回答的字段。在图4所示的例子中,表示了作为对于询问意图“高尾山的高度”的回答而保存“599米”、作为对于询问意图“高尾山的位置”的回答而保存“东京都八王子市”。
此外,qadb(特定任务)113是按每个特定的任务而制作、根据关于该特定的任务的询问回答的内容而保存其回答的数据。特定的任务是指成长型对话装置针对关于对话应答而接受的命令进行动作。
接着,使用图5至图8对成长型对话装置的处理进行说明。
首先,使用图5对经由成长型对话装置(对话设备)的声音对话处理的流程、特别是成长型对话装置对于用户讲话的询问声音讲出回答声音为止的一系列的处理的流程进行说明。
成长型对话装置总是用图1所示的麦克风231将声音持续集音。在该状况下,用户发出的用户讲话声音101在由麦克风变换为数字信号后,由讲话区间检测处理102仅切离出用户的声音部分。接着,通过声音识别处理103进行声音识别处理,被写出为与声音对应的文本。这里,声音识别处理103使用声音识别用模型数据108。接着,在意图理解处理104中,基于文本中包含的单词信息,决定用户询问的意图标签。这里,意图标签如已经说明那样,如“高尾山的高度”、“高尾山的位置”等那样,是表示询问的意图的识别码。为了根据单词信息决定该意图信息,使用意图理解用模型数据109。接着,在应答生成处理105中,在两种qadb内检索由意图理解处理104决定的i字段的意图标签,将与保存在对应的a字段中的回答文本输出。最后,在声音合成处理106中将回答文本变换为合成声音,经由扬声器232从对话设备作为应答声音107发出。
意图理解用模型数据109是通过意图理解模型学习处理110,根据将意图理解用学习数据(通常)121和意图理解用学习数据(特定用户)122结合的学习数据进行了机械学习的模型数据。这里,意图理解用学习数据(特定用户)122是按每个用户分别存在的数据,在没有进行对该用户的知识获得的情况下内容为空。当对话设备检测到新的用户而开始声音对话服务时,使用脸识别或生物体信息认证技术等识别该用户,如果是已知的用户,则在选择该用户用的意图理解用学习数据(特定用户)122后,进行上述的机械学习处理。当为未知的用户的情况下,准备空的数据,作为该用户用的意图理解用学习数据(特定用户)122新追加到系统。这样,在对话设备服务于某用户的状况下,意图理解用模型数据109进行对于该用户特殊化的意图理解模型学习。
此外,意图理解用学习数据(特定情景)123是按每个情景树分别存在的数据,在没有进行对于该情景的知识获得的情况下内容为空。
在qadb中,如上述那样,有qadb(通常)111、qadb(特定任务)113这两种。qadb(通常)111是保存有不管是哪个用户、哪个任务、哪个对话设备都能够利用的回答信息的db,qadb(特定任务)113是保存有只有执行某特定的任务的对话设备才能够回答的回答信息的db。
这些qadb如上述那样,基本上是拥有i字段和a字段这二个字段的表,在i字段中保存有预先定义的意图标签,在a字段中保存有对于该意图标签所表示的询问的回答文本。此外,qadb(特定任务)113、qadb(特定设备)114也是对于多个任务或多个对话设备分别存在的db,与用户同样,每当任务或对话设备变化时进行切换。
如上述那样,在本实施方式的成长型对话装置中,采用称作任务的概念。任务是指表示对话设备实施的服务的内容的信息,例如可以考虑“顾客引导任务”“商品说明任务”等。在一个个成长型对话装置中,在一时期中被分配某一个任务,以与该任务对应的内容(content)实施服务。当然,在切换了任务时,三种意图理解用学习数据、两种qadb可以通过一齐切换为该任务用的数据而使对话的精度提高。
基于从应答生成处理105输出的回答文本、声音识别处理103的写出文本、意图理解处理104的意图标签和其置信度、应答生成处理105中的qadb的检索结果(成功/失败)等信息,由知识提取处理118提取新的知识信息。这里输出的知识信息是写出文本q、意图标签i、回答文本a这三个信息。
知识提取处理118例如可以取以下这样的次序。
(意图标签的置信度低的情况)
在意图标签的置信度是某阈值t1以下的情况下,在应答生成处理105中能够检索回答文本,但不实施该回答文本的朗读。并且,在知识提取处理118中,通过向用户进行反问,取得回答文本。这里,设想用户和进行了询问的用户是不同的用户,是能够从其获得知识的主体。例如,假设写出文本是“告诉我高尾山的高度”,则对话系统通过对该文本进行定型的句子开头(日语中句子结尾)表现变换处理,向用户进行“请告诉我高尾山的高度”的询问。对此,如果用户回答“是599米”,则在声音识别处理后,通过进行将定型的句子开头表现删除等的文本处理,得到“599米”的文本。进而,通过由对话系统追加自身固有的句子开头表现,得到“是599米”的回答文本。结果,能够输出写出文本q“告诉我高尾山的高度”、新制作出的意图标签i“告诉我高尾山的高度”、对应的回答文本a“是599米”这样的提取知识。新制作的意图标签必须是与已经存在的标签不一致的唯一的标签。在上述例子中将写出文本q原样作为标签,但如果存在相同的意图标签,则对于末尾赋予识别号码等而使其成为唯一是容易的。
(意图标签不包含在qa数据库中的情况)
当应答生成处理105中检索qa数据库时在i字段中不存在被指定的意图标签的情况下,与上述同样,对话系统进行反问而取得回答文本。结果,能够输出写出文本q、意图标签i、回答文本a这三个信息。
(意图标签的置信度高、也包含在qadb中的情况)
在意图标签的置信度比阈值t1高、也包含在qadb中的情况下,不实施知识提取处理118,而仅实施由应答生成处理105检索出的回答文本的朗读。
在执行了知识提取处理118、输出了上述三个知识信息的情况下,将它们作为向下个知识分类处理120的输入。在知识分类处理120中,决定将这些知识信息保存到哪个意图理解用学习数据、哪个qa数据库中。
最后,基于知识分类处理120的判定结果,将由知识保存处理124提取出的知识信息(q,i,a)保存到适当的地方。即,以规定的形式,将写出文本q向意图理解学习用数据的文本字段保存,将意图标签i向意图理解学习用数据的命令字段和qadb的i字段保存,将回答文本a向qadb的i字段的a字段保存。
接着,使用图6对知识分类处理120的详细情况进行说明。
首先,基于被输入的知识信息,检索其意图标签i和回答文本a的组是否被保存在某个qadb的i字段及a字段中(s201)。在检索到这样的记录的情况下(s201:是),判断该知识信息不是新的回答知识的提取,而是新的表现知识的提取结果。在此情况下,接着计算写出文本q即该文本的询问表现的情景上下文依赖度c(s202)(详细情况后述)。进而,计算q的个人依赖度u(s203)(详细情况后述)。并且,通过将情景上下文依赖度c和个人依赖度u的大小与某个阈值c0、u0比较(s204、s205),决定应作为该知识信息(表现信息)的保存目的地的意图理解用学习数据的地方。即,当情景上下文依赖度c比阈值c0大时(s204:是),保存到意图理解用学习数据(情景节点)123中,当情景上下文依赖度c不比阈值c0大时(s204:否),向s205前进。当个人依赖度u比阈值u0大时(s205:是),保存到意图理解用学习数据(特定用户)122,当不大时(s205:否),保存到意图理解用学习数据(通常)121。
另一方面,在处理s201中没有检索到记录的情况下(s201:否),将提取出的知识信息判断为回答知识。在此情况下,计算回答文本a的任务上下文依赖度t(s207)(详细情况后述),通过与某阈值t0的比较,将保存部位分类为qadb(通常)111或qadb(特定任务)113。即,当任务上下文依赖度t比阈值t0大时(s208:是),将所获得的回答知识(i,a)保存到qadb(特定任务)113,当任务上下文依赖度t不比阈值t0大时(s208:否),将所获得的回答知识(i,a)保存到qadb(通常)111。
并且,在保存到某个中之后,向s202前进,将知识信息保存到意图理解用学习数据中的某个。
这里,关于情景上下文依赖度c和个人依赖度u,将写出文本q进行解析来计算其值,关于任务上下文依赖度t,将回答文本a进行解析来计算其值。这是因为,可以推测询问的措词或表现多数情况下依赖于成长型对话装置中的情景和个人的讲话方式,但推测对询问的回答依赖于对成长型对话装置赋予的任务(例如,在商品说明任务中,商品名及商品的特性等成为回答的情况可能较多),不怎么依赖于情景或个人的特性。
接着,使用图7对情景上下文依赖度c计算处理、个人依赖度u计算处理的详细情况进行说明。
写出文本q的情景上下文依赖度c如以下这样计算。首先,将写出文本q利用语态素解析程序等分割为单词(s301)。接着,参照辞典,将助词等特定的词类的单词删除,由此能够提取出拥有意义的内容语wi(s302)。同样,根据情景数据中包含的文本进行单词分割(s303),提取内容语的序列ck(s304)。接着,根据辞典,生成与单词序列ck相同长度的单词序列rk(s306)。并且,参照单词共现概率数据库307,从这些单词wi、单词序列ck、rk,取得单词序列ck和rk中被赋予了条件的单词wi中包含的全部单词间的共现概率pr(wi,wj|ck)和pr(wi,wj|rk)(s305)。所谓共现概率pr(wi,wj|ck),是在包含单词序列ck的文章中,单词wi和单词wj都出现的统计学概率,所谓共现概率pr(wi,wj|rk),是在包含单词列rk的文章中,单词wi和单词wj都出现的统计学概率,最后,例如通过以下的(式1)计算情景上下文依赖度c。其中,对数取自然对数。
[数式1]
这里,当情景上下文依赖度c大时,意味着写出文本q依赖于情景的程度大(即,与随机的单词序列相比背离大)。
任务上下文依赖度t也能够以同样的处理来实现。在此情况下,以回答文本a和任务数据为输入,将最终计算出的值作为任务上下文依赖度t。这里,任务数据是指在包含于某任务中的服务情景整体中包含的文本。在此情况下,设内容语提取s304的输出为tk,任务上下文依赖度t的值通过以下的(式2)来计算。
[数式2]
接着,使用图8对个人依赖度u计算处理进行说明。
首先,将写出文本q与图7所示的处理同样地进行单词分割(s401),提取内容语(s402),向单词wi变换。接着,在处理s403中,通过参照单词共现概率数据库405,取得单词wi中包含的全部的单词间的共现概率pr(wi,wj)(s403)。最后,通过以下的(式3)计算个人依赖度u。
[数式3]
这里,当个人依赖度u大时,意味着写出文本q依赖于特定用户的程度大。即,意味着当采取通常不被使用的讲话方式(概率小的单词的组合表现)时,看作依赖于特定的用户。
另外,在本实施方式中,作为意图理解用学习用数据,通过将通常、特定用户、情景节点这三种保存到不同的地方进行了区别,但也可以对数据赋予标签,通过读取该标签来判定意图理解用学习用数据的种类。此外,作为qadb,通过将通常、特定任务这两种保存到不同的地方进行了区别,但也可以对数据赋予标签,通过读取该标签来判定qadb的种类。
此外,在知识保存判定处理中,对于所获得的知识,基于情景上下文依赖度、个人依赖度、任务上下文依赖度这样的各种指标,判定了意图理解用学习数据、qadb的放入地方,但也可以在成长型对话装置中设置显示装置和输入装置,显示所获得的知识信息(q,i,a)和基于指标的判断,管理者检查放入哪个意图理解用学习数据、qadb。
以上,通过本实施方式的结构,成长型对话装置能够将新得到的关于询问回答的知识或关于询问表现的知识按照其特性而保存到适当地分类的意图理解用模型数据或qadb中。结果,不再将仅对特定的用户可以回答的知识向其他用户回答,此外,解决了将对于特定的用户有效的询问表现知识也用于其他用户而降低对话精度的问题。
关于特定任务也是同样的。此外,通过将与遵循成长型对话装置的情景的询问表现有关的知识作为意图理解用模型数据保存,能够使学习的精度提高。
〔实施方式2〕
以下,使用图9至图11说明本发明的实施方式2。
在实施方式1中,对通过声音识别与用户对话的成长型对话装置的知识获得进行了说明。在本实施方式中,说明除此以外还能够对人进行图像识别、储存工作日志、关于特定任务储存经验知识的情况下的知识获得。
在本实施方式中,重点说明与实施方式1不同之处。
首先,使用图9对有关实施方式2的成长型对话装置的结构进行说明。
本实施方式的成长型对话装置与实施方式1的成长型对话装置不同的是,具有图像输入部240,在其上连接着相机(摄像装置)242,将从那里拍摄的运动图像、静止图像取入。
在处理部210中,在实施方式1的基础上,还附加了图像识别部250和经验知识生成部252的子组件。
图像识别部250是将所拍摄的运动图像、静止图像进行图案识别而读取特征的功能部。经验知识生成部252根据图像识别部250的图像识别结果和工作日志而生成关于该成长型对话装置的经验知识的功能部。关于成长型对话装置的经验知识,是通过使该成长型对话装置工作而得到的知识。
此外,存储部220除了实施方式1的数据以外,还加上了qadb(特定设备)114和工作日志117。
qadb(特定设备)114是按每个特定的设备制作、根据与该特定的设备有关的询问回答的内容来保存其回答的数据。这里,特定的设备是指成长型对话装置的硬件,一台台成长型对话装置视为特定的设备。工作日志117是成长型对话装置的工作记录。在工作日志117中,例如写入由成长型对话装置进行图像识别而得到的特定的用户在哪年的哪月哪日与该设备关于某话题进行了对话等的记录。
接着,使用图10及图11对本实施方式的成长型对话装置的处理进行说明。
在本实施方式的成长型对话装置中,在实施方式1的图5中表示的成长型对话装置的处理中加上了图像识别处理116和经验知识生成处理119,作为数据而加上了工作日志117、qadb(特定设备)。在本实施方式的成长型对话装置的处理中,根据图像识别的结果和成长型对话装置的工作日志117,通过经验知识生成处理119生成关于该成长型对话装置的经验知识。
所生成的经验知识用于知识分类处理120的判断。
接着,使用图11对有关实施方式2的知识分类处理120的详细情况进行说明。
在有关实施方式2的知识分类处理120中,作为s201:否时的判定处理,判定回答文本a是否是经验知识(s206)。当回答文本a是经验知识时(s206:是),将所获得的回答知识(i,a)向qadb(特定设备)114保存。当回答文本a不是经验知识时(s206:否),向s207前进。
此外,在向各qadb保存后前进到s202的判定处理,这与图6所示的实施方式1的知识分类处理120是同样的。
在本实施方式中,除了实施方式1的成长型对话装置的功能以外,还能够进行对特定设备特殊化的知识的获得。
- 还没有人留言评论。精彩留言会获得点赞!