智能化听力锻炼方法及装置与流程
本发明涉及语音识别技术领域,特别涉及一种智能化听力锻炼方法及装置。
背景技术:
目前,锻炼听力的方式,主要还是靠跟读,对记忆性及听力帮助不大;并且无法对各个年龄段的人进行针对性的训练。
技术实现要素:
本发明提供一种智能化听力锻炼方法及装置,能智能分析用户的年龄段,并根据该年龄段应该掌握的词汇,模拟真实听力考试,并引导用户作答。通过这种方式,强化用户的听力能力。
本发明实施例提供的一种智能化听力锻炼方法,包括:
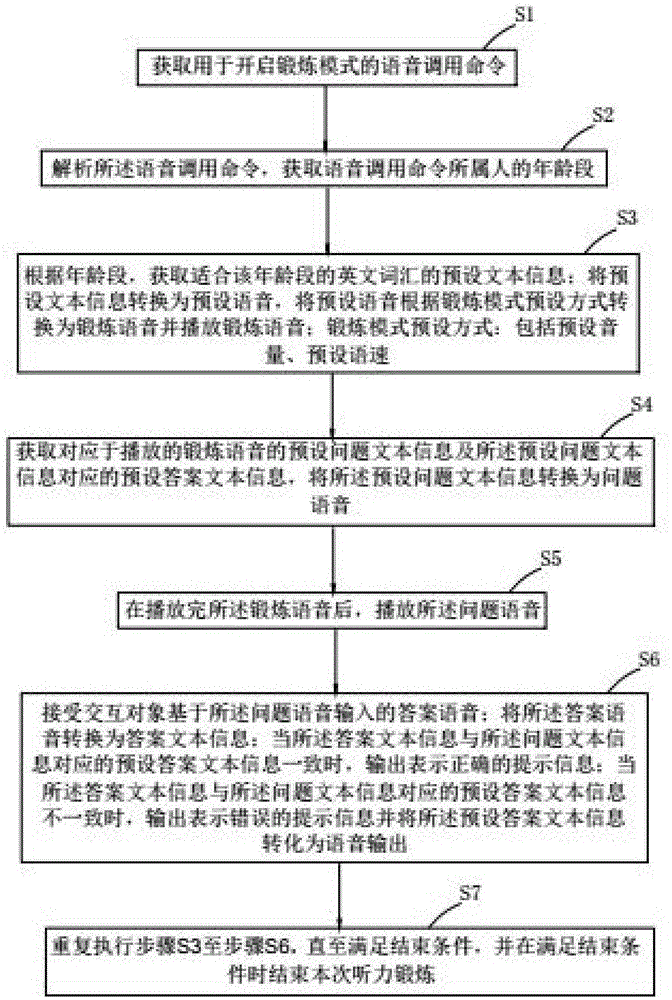
s1、获取用于开启锻炼模式的语音调用命令;
s2、解析所述语音调用命令,获取语音调用命令所属人的年龄段;
s3、根据所述年龄段,获取适合该年龄段的英文词汇的预设文本信息;将所述预设文本信息转换为预设语音,将所述预设语音根据锻炼模式预设方式转换为锻炼语音并播放所述锻炼语音;所述锻炼模式预设方式包括:预设语速和/或预设音量;
s4、获取对应于播放的锻炼语音的预设问题文本信息及所述预设问题文本信息对应的预设答案文本信息,将所述预设问题文本信息转换为问题语音;
s5、在播放完所述锻炼语音后,播放所述问题语音;
s6、接收交互对象基于所述问题语音输入的答案语音;将所述答案语音转换为答案文本信息;当所述答案文本信息与所述预设答案文本信息一致时,输出表示正确的提示信息;当所述答案文本信息与所述预设答案文本信息不一致时,输出表示错误的提示信息并将所述预设答案文本信息转化为语音输出;
s7、重复执行步骤s3至步骤s6,直至满足结束条件,并在满足结束条件时结束本次听力锻炼。
在一个实施例中,所述将所述预设语音根据锻炼模式预设方式转换为锻炼语音;
其中,根据所述听力锻炼模式,将所述预设语音转换为锻炼语音:
确定当前轮数,
根据所述当前轮数确定相对应的当前语速,所述当前轮数与所述当前语速为正相关关系;和/或,根据所述当前轮数确定相对应的当前音量,所述当前轮数与所述当前音量为负相关关系;
将所述预设语音按照当前语速和/或当前音量生成锻炼语音。
在一个实施例中,将所述预设语音根据锻炼模式预设方式转换为锻炼语音包括:
在上一轮输出的提示信息是表示正确时,确定上一轮中播放上一轮锻炼语音的上一轮播放参数,所述上一轮播放参数包括上一轮语速和/或上一轮音量;
根据所述上一轮播放参数确定本轮播放参数,并根据所述本轮播放参数生成本轮的锻炼语音;所述本轮播放参数包括本轮语速和/或本轮音量,且所述本轮语速大于所述上一轮语速、所述本轮音量小于所述上一轮音量。
在一个实施例中,锻炼预设方式还包括:添加干扰语音;将所述预设语音根据锻炼模式预设方式转换为锻炼语音包括:
获取干扰语音,
使用所述干扰语音与所述预设语音生成锻炼语音。
本发明还提供一种智能化听力锻炼装置,包括:
启动模块,用于获取用于开启锻炼模式的语音调用命令;
用户年龄段确定模块,用于解析所述语音调用命令,获取语音调用命令所属人的年龄段;
锻炼语音生成模块,用于根据所述年龄段,获取适合该年龄段的英文词汇的预设文本信息;将所述预设文本信息转换为预设语音,将所述预设语音根据锻炼模式预设方式转换为锻炼语音并播放所述锻炼语音;
问题语音生成模块,用于获取对应于播放的锻炼语音的预设问题文本信息及所述预设问题文本信息对应的预设答案文本信息,将所述预设问题文本信息转换为问题语音;
播放执行模块,用于在播放完所述锻炼语音后,播放所述问题语音;
结果输出模块,用于接受交互对象基于所述问题语音输入的答案语音;将所述答案语音转换为答案文本信息;当所述答案文本信息与所述问题文本信息对应的预设答案文本信息一致时,输出表示正确的提示信息;当所述答案文本信息与所述问题文本信息对应的预设答案文本信息不一致时,输出表示错误的提示信息并将所述预设答案文本信息转化为语音输出;
循环模块,用于锻炼语音生成模块、问题语音生成模块、播放执行模块、结果输出模块的循环执行;
结束模块,用于获取输出表示错误的提示信息的次数,当所述次数超过预设阈值时,结束本次听力锻炼;
和/或,
获取关闭听力锻炼的语音命令,结束本次听力锻炼;
和/或,
从播放完问题语音后开始计时,当超过预设的时间值还未接受到交互对象基于所述问题语音输入的答案语音,结束本次听力锻炼。
在一个实施例中,锻炼语音生成模块包括:
轮数确定子模块,用于确定当前轮数,
第一语速和/或音量确定子模块,用于根据所述当前轮数确定相对应的当前语速,所述当前轮数与所述当前语速为正相关关系;和/或,根据所述当前轮数确定相对应的当前音量,所述当前轮数与所述当前音量为负相关关系;
第一锻炼语音生成子模块,将所述预设语音按照当前语速和音量生成锻炼语音。
在一个实施例中,锻炼语音生成模块包括:
第二语速和/或音量确定子模块,用于在上一轮输出的提示信息是表示正确时,确定上一轮中播放上一轮锻炼语音的上一轮播放参数,所述上一轮播放参数包括上一轮语速和/或上一轮音量;
根据所述上一轮播放参数确定本轮播放参数,并根据所述本轮播放参数生成本轮的锻炼语音;所述本轮播放参数包括本轮语速和/或本轮音量,且所述本轮语速大于所述上一轮语速、所述本轮音量小于所述上一轮音量。
在一个实施例中,锻炼语音生成模块包括:
干扰语音获取子模块,用于获取干扰语音,
第二锻炼语音生成子模块,使用所述干扰语音与所述预设语音生成锻炼语音。
在一个实施例中,智能化听力锻炼装置还包括:评价模块,用于根据交互对象每一轮输入的答案语音确定所述交互对象的答案信息,并根据所述答案信息确定所述交互对象的评价系数,所述答案信息包括获取当前答案语音的时长、最大轮数、最大播放语速、最小播放音量中的一项或多项。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种智能化听力锻炼方法的示意图;
图2为本发明实施例中一种智能化听力锻炼装置的示意图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
本发明实施例提供了一种智能化听力锻炼方法,如图1所示,包括:
s1、获取用于开启锻炼模式的语音调用命令;
s2、解析语音调用命令,获取语音调用命令所属人的年龄段;
s3、根据年龄段,获取适合该年龄段的英文词汇的预设文本信息;将预设文本信息转换为预设语音,将预设语音根据锻炼模式预设方式转换为锻炼语音并播放锻炼语音;锻炼模式预设方式:包括预设音量、预设语速;
s4、获取对应于播放的锻炼语音的预设问题文本信息及预设问题文本信息对应的预设答案文本信息,将预设问题文本信息转换为问题语音;
s5、在播放完锻炼语音后,播放问题语音;
s6、接收交互对象基于问题语音输入的答案语音;将答案语音转换为答案文本信息;当答案文本信息与预设答案文本信息一致时,输出表示正确的提示信息;当答案文本信息与预设答案文本信息不一致时,输出表示错误的提示信息并将预设答案文本信息转化为语音输出;
s7、重复执行步骤s3至步骤s6直至满足结束条件,并在满足结束条件时结束本次听力锻炼。
上述智能化听力锻炼方法能智能分析用户的年龄段,并根据该年龄段应该掌握的词汇,模拟真实听力考试,并引导用户作答,通过这种方式,强化用户的听力能力。
本发明实施例中,可以预设多种听力锻炼模式,听力锻炼模式可以包括:简单模式、困难模式、由容易到困难的进阶模式等。
下面以由容易到困难的进阶模式进行举例说明
用户通过语音开启听力锻炼模式。其中,将用户开启模式的语音送入声纹识别引擎。声纹识别引擎通过声纹识别技术识别用户开启模式的语音,进而可识别出用户年龄段。根据用户年龄段从词汇内容库中选择适合该用户年龄段的词汇,随机抽取一条词汇;该词汇通过tts(texttospeech,从文本到语音)语音合成引擎,进行预设语音的合成。再经过调整预设语音的音量和/或语速合成锻炼语音;最后播放合成好的锻炼语音。当合成语音播放后通过预设的问题语音提问用户;例如“这个词汇是什么?”。用户通过语音输入答案,asr(automaticspeechrecognition,自动语音识别)语音识别引擎识别答案;若答案正确,则提示用户正确,并逐渐增加难度,继续出题;若答案错误,则提示用户错误,播报正确答案,继续出题。增加难度的方法包括:降低音量或提高语速。具体实施为:音量越低,难度越高;语速越快,难度越高。
其中,结束条件用于结束本次听力锻炼,结束条件具体可以根据实际情况而定。具体的,上述s7中“在满足结束条件时结束本次听力锻炼”包括:
统计输出表示错误的提示信息的次数,当所述次数超过预设阈值时,结束本次听力锻炼;
和/或,
获取关闭听力锻炼的语音命令,结束本次听力锻炼;
和/或,
从播放完问题语音后开始计时,当超过预设的时间值还未接收到交互对象基于所述问题语音输入的答案语音,结束本次听力锻炼。
通过统计输出表示错误的提示信息的次数,当次数超过预设阈值时、获取关闭听力锻炼的语音命令、从播放完问题语音后开始计时,当超过预设的时间值还未接受到交互对象基于问题语音输入的答案语音中至少一个条件成立时,结束本次听力锻炼。
为了使听力锻炼的难度随着轮数的增加而逐渐增加,在一个实施例中,s4根据年龄段,获取适合用户年龄段的英文词汇的预设文本信息;将预设文本信息转换为预设语音,根据听力锻炼模式,将预设语音转换为锻炼语音;
其中,根据听力锻炼模式,将预设语音转换为锻炼语音:
确定当前轮数,当前轮数即为当前听力锻炼模式下已播放锻炼语音次数加一;
根据当前轮数确定相对应的当前语速,当前轮数与当前语速为正相关关系;和/或,根据当前轮数确定相对应的当前音量,当前轮数与当前音量为负相关关系;
将预设语音按照当前语速和/或音量生成锻炼语音。
使锻炼语音随着锻炼的轮数的增加而逐渐地加快播放语速和/或降低播放音量,使得语速越来越快,音量越来越低,从而使听力锻炼的难度随着锻炼轮数的增加而逐渐增加,通过这种由容易到困难逐渐递进的方式,强化用户的听力能力。
为使用户可以循序渐进地锻炼听力,在一个实施例中,将预设语音根据锻炼模式预设方式转换为锻炼语音包括:
在上一轮输出的提示信息是表示正确时,确定上一轮中播放上一轮锻炼语音的上一轮播放参数,上一轮播放参数包括上一轮语速和/或上一轮音量;
根据上一轮播放参数确定本轮播放参数,并根据本轮播放参数生成本轮的锻炼语音;本轮播放参数包括本轮语速和/或本轮音量,且本轮语速大于上一轮语速、本轮音量小于上一轮音量。
通过加快语音的语速和/或音量使用户更好地锻炼听力。
为使用户可以循序渐进地锻炼听力,在一个实施例中,将预设语音根据锻炼模式预设方式转换为锻炼语音包括:
在上一轮输出的提示信息是表示错误时,确定上一轮中播放上一轮锻炼语音的上一轮播放参数,上一轮播放参数包括上一轮语速和/或上一轮音量;
根据上一轮播放参数确定本轮播放参数,并根据本轮播放参数生成本轮的锻炼语音;本轮播放参数包括本轮语速和/或本轮音量,且本轮语速等于上一轮语速、本轮音量等于上一轮音量。
当用户遇到无法跟上语速的和/或音量,通过维持一定的语速和/或音量,使用户可以适应于当前播放的语速和/或音量。
为了使听力锻炼更接近于现实,在一个实施例中,锻炼预设方式还包括:添加干扰语音;将预设语音根据锻炼模式预设方式转换为锻炼语音;包括:
获取干扰语音,
使用干扰语音与预设语音生成锻炼语音。
在现实生活中,人与人交谈时往往周围环境会有各种各样的背景音存在,所以需要在各种各样的背景音存在的情况下锻炼听力,另外在背景音(即干扰语音)的存在下锻炼更能提高用户的听力水平。
本发明还提供一种智能化听力锻炼装置,如图2所示,包括:
启动模块10,用于获取用于开启锻炼模式的语音调用命令;
用户年龄段确定模块20,用于解析语音调用命令,获取语音调用命令所属人的年龄段;
锻炼语音生成模块30,用于根据年龄段,获取适合该年龄段的英文词汇的预设文本信息;将预设文本信息转换为预设语音,将预设语音根据锻炼模式预设方式转换为锻炼语音并播放锻炼语音;
问题语音生成模块40,用于获取对应于播放的锻炼语音的预设问题文本信息及预设问题文本信息对应的预设答案文本信息,将预设问题文本信息转换为问题语音;
问题播放模块50,用于在播放完锻炼语音后,播放问题语音;
结果输出模块60,用于接受交互对象基于问题语音输入的答案语音;将答案语音转换为答案文本信息;当答案文本信息与问题文本信息对应的预设答案文本信息一致时,输出表示正确的提示信息;当答案文本信息与问题文本信息对应的预设答案文本信息不一致时,输出表示错误的提示信息并将预设答案文本信息转化为语音输出;
循环模块70,用于锻炼语音生成模块30、问题语音生成模块40、播放执行模块50、结果输出模块60的循环执行;
结束模块80,用于获取输出表示错误的提示信息的次数,当次数超过预设阈值时,结束本次听力锻炼;
和/或,
获取关闭听力锻炼的语音命令,结束本次听力锻炼;
和/或,
从播放完问题语音后开始计时,当超过预设的时间值还未接受到交互对象基于问题语音输入的答案语音,结束本次听力锻炼。
上述智能化听力锻炼装置能智能分析用户的年龄段,并根据该年龄段应该掌握的词汇。模拟真实听力考试,并引导用户作答,通过这种方式,强化用户的听力能力。
听力锻炼模式可以包括:简单、困难、由容易到困难的进阶模式等。
下面以由容易到困难的进阶模式进行举例说明
启动模块10获取用户语音开启听力锻炼模式。其中,用户开启模式的语音送入用户年龄段确定模块20,例如:声纹识别引擎。声纹识别引擎通过声纹识别技术识别用户开启模式的语音识别出用户年龄段。锻炼语音生成模块30根据用户年龄段从词汇内容库中选择适合该用户年龄段的词汇。随机抽取一条词汇;该词汇通过tts(texttospeech,从文本到语音)语音合成引擎,进行预设语音的合成。再经过调整预设语音的音量和/或语速合成锻炼语音;播放锻炼语音。当锻炼语音播放后通过预设的问题语音提问用户。例如“这个词汇是什么?”。用户通过语音输入答案。结果输出模块60包括:asr(automaticspeechrecognition,自动语音识别)语音识别引擎,结果输出模块60识别答案;若答案正确,则提示用户正确,并逐渐增加难度,继续出题;若答案错误,则提示用户错误,播报正确答案,继续出题。增加难度的方法包括:降低音量或提高语速。具体实施为:音量越低,难度越高;语速越快,难度越高。
结束模块80通过统计输出表示错误的提示信息的次数,当次数超过预设阈值时、获取关闭听力锻炼的语音命令、从播放完问题语音后开始计时,当超过预设的时间值还未接受到交互对象基于问题语音输入的答案语音中至少一个条件成立时,结束本次听力锻炼。
为了使听力锻炼的难度随着锻炼轮数的增加而逐渐增加,在一个实施例中,锻炼语音生成模块包括:
轮数确定子模块,用于确定当前轮数,
第一语速和/或音量确定子模块,用于根据当前轮数确定相对应的当前语速,当前轮数与当前语速为正相关关系;和/或,根据当前轮数确定相对应的当前音量,当前轮数与当前音量为负相关关系;
第一锻炼语音生成子模块,将预设语音按照当前语速和/或音量生成锻炼语音。
使锻炼语音随着轮数的增加而逐渐的语速越来越快,音量越来越低,从而使听力锻炼的难度随着锻炼轮数的增加而逐渐增加,通过这种由容易到困难逐渐递进的方式,强化用户的听力能力。
为使用户可以循序渐进地锻炼听力,在一个实施例中,锻炼语音生成模块包括:
第二语速和/或音量确定子模块,用于在上一轮输出的提示信息是表示正确时,确定上一轮中播放上一轮锻炼语音的上一轮播放参数,上一轮播放参数包括上一轮语速和/或上一轮音量;
根据上一轮播放参数确定本轮播放参数,并根据本轮播放参数生成本轮的锻炼语音;本轮播放参数包括本轮语速和/或本轮音量,且本轮语速大于上一轮语速、本轮音量小于上一轮音量。
通过加快语音的语速和/或音量使用户更好地锻炼听力。
为使用户可以循序渐进地锻炼听力,在一个实施例中,锻炼语音生成模块包括:
第三语速和/或音量确定子模块,用于在上一轮输出的提示信息是表示错误时,确定上一轮中播放上一轮锻炼语音的上一轮播放参数,上一轮播放参数包括上一轮语速和/或上一轮音量;
根据上一轮播放参数确定本轮播放参数,并根据本轮播放参数生成本轮的锻炼语音;本轮播放参数包括本轮语速和/或本轮音量,且本轮语速等于上一轮语速、本轮音量等于上一轮音量。
当用户遇到无法跟上语速的和/或音量,通过维持一定的语速和/或音量,使用户可以适应于当前播放的语速和/或音量。
为了使听力锻炼更接近于现实,在一个实施例中,锻炼语音生成模块包括:
干扰语音获取子模块,用于获取干扰语音,
第二锻炼语音生成子模块,使用干扰语音与预设语音生成锻炼语音。在现实生活中,人与人交谈时往往周围环境会有各种各样的背景音存在,所以需要在各种各样的背景音存在的情况下锻炼听力。另外在背景音的存在下锻炼更能提高用户的听力水平。
为了使交互对象了解自己听力锻炼的结果,在一个实施例中,还包括:评价模块,用于根据交互对象每一轮输入的答案语音确定交互对象的答案信息,并根据答案信息确定交互对象的评价系数,答案信息包括获取当前答案语音的时长、最大循环轮数、最大播放语速、最小播放音量中的一项或多项。在本次听力锻炼结束后,对交互对象的本次听力锻炼进行评价,使交互对象对自身听力水平有比较直观的印象,了解自身的听力水平,并在下次听力锻炼时更努力获取更高的评价。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!