一种结合爬虫技术的轻量级实时语音识别及翻译装置的制作方法
本发明涉及一种语言识别及翻译装置。
背景技术
互联网快速发展带来的是以视频媒介传递的信息越来越多,很多人苦于无法在观看视频或者在现场听演讲时无法获取语音的文本内容。主流的方法是一边听,一边通过打字从而获取听到的内容,这种做法的效率非常低下。
现有的语音识别技术,能够实现语音听写、语音转写等语音技术,提供在线的语音识别服务,并具有高识别准确度。
但是上述语音识别技术,需要较好的硬件设备支持,也无法实时的实现文本的翻译,即使通过一些翻译网站,由于语言识别的断句导致文本出现的一些问题,在翻译之后会使文本更加混乱。
技术实现要素:
为解决上述问题,提供一种实时语音识别及翻译装置,本发明采用了如下技术方案:
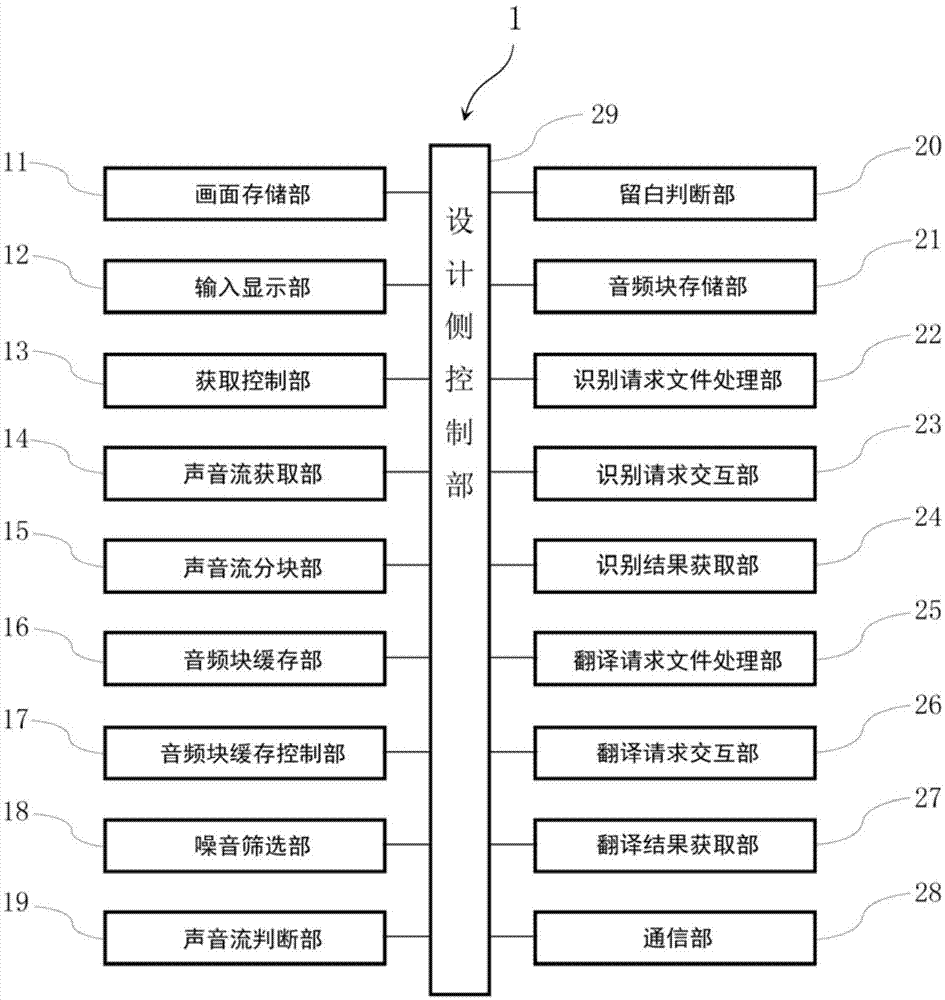
本发明提供了一种结合爬虫技术的轻量级实时语音识别及翻译装置,设置在连入互联网的终端中,通过与服务器交互进行语音识别及翻译,其特征在于,包括:画面存储部、输入显示部、获取控制部、声音流获取部、声音流分块部、音频块缓存部、噪音筛选部、声音流判断部、音频块存储部、识别请求文件处理部、识别请求交互部、识别结果获取部、翻译请求文件处理部、翻译请求交互部、翻译结果获取部以及通信部;画面存储部存储有用户输入操作画面、语音识别画面以及语音翻译画面,输入显示部显示用户输入操作画面让用户选择需要进行识别的待识别文件,获取控制部控制声音流获取部从待识别文件中获取待识别声音流,声音流分块部将待识别声音流切分成音频块,音频块缓存部对音频块进行暂存,噪音筛选部依次筛选音频块并丢弃属于噪音的音频块,声音流判断部依次判断噪音筛选部处理后的音频块是否具有声音流,音频块存储部将声音流判断部判断为具有声音流的音频块作为有效音频块进行存储,识别请求文件处理部将需要识别的有效音频块处理为可以发送给识别服务器的识别请求文件,识别请求交互部通过通信部与识别服务器交互并发送识别请求文件,识别结果获取部根据识别服务器返回的结果获取最终的识别结果文本,输入显示部在语音识别画面的文本区中显示识别结果文本,翻译请求文件处理部将需要翻译的识别结果文本处理为可以发送给翻译服务器的翻译请求文件,翻译请求交互部通过通信部与翻译服务器交互并发送翻译请求文件,翻译结果获取部根据翻译服务器返回的结果获取与识别结果文本对应的翻译结果,输入显示部在语音翻译画面的文本区显示翻译结果。
本发明提供的实时语音识别及翻译装置,还可以具有这样的技术特征,还包括:留白判断部,其中,留白判断部依次判断声音流判断部处理后的有效音频块,判断为留白过多时,获取控制部控制声音流获取部停止对待识别声音流的获取。
本发明提供的实时语音识别及翻译装置,还可以具有这样的技术特征,还包括:留白判断部;终端还具有麦克风;其中,输入操作画面还具有麦克风录音选择画面,用户选择通过麦克风录入待识别文件,获取控制部控制麦克风开始录音,进一步控制声音流获取部从麦克风的录音中获取待识别声音流,留白判断部依次判断声音流判断部处理后的音频块,判断为留白过多时,获取控制部控制声音流获取部停止获取识别声音流,并控制麦克风停止录音。
本发明提供的实时语音识别及翻译装置,还可以具有这样的技术特征,还包括:音频块缓存控制部,其中,音频块以14秒为一段,在音频块缓存部中的缓存数量在20个以下,当音频块的数量超出20个时,音频块缓存控制部控制音频块缓存部将新的音频块覆盖当前最早生成的音频块。
本发明提供的实时语音识别及翻译装置,还可以具有这样的技术特征,其中,识别请求文件处理部、识别请求交互部以及识别结果获取部的语音识别过程运行基于如下步骤:步骤a1,通过预先设定的api参数拼接识别服务器的url地址;步骤a2,向识别服务器发送request请求;步骤a3,对识别服务器返回的参数筛选获得token参数;步骤a4,依次读取需要识别的音频块,并由token参数监听读取的过程;步骤a5,将音频块转化为字节类型的多个参数;步骤a6,将多个参数打包为字典参数;步骤a7,将字典参数与token参数作为识别请求文件发送给识别服务器;步骤a8,获取识别服务器返回的结果并筛选出识别内容;步骤a9,将识别结构内容转化为文本并输出。
本发明提供的实时语音识别及翻译装置,还可以具有这样的技术特征,其中,翻译请求文件处理部、翻译请求交互部以及翻译结果获取部的语音翻译过程运行基于如下步骤:步骤b1,获取预先设定的翻译网站地址;步骤b2,向翻译网站地址的翻译服务器发送预设单词,请求响应,查看其产生的动态参数;步骤b3,将动态参数打包为参数字典;步骤b4,将需要翻译的识别结果文本根据参数字典打包为翻译请求文件;步骤b5,将参数字典发送给翻译服务器;步骤b6,以post的方式模拟浏览器请求发起过程,将翻译请求发送给翻译服务器;步骤b7,获取翻译服务器返回的响应字典;步骤b8,将响应字典转化为响应字符串;步骤b9,解析响应字符串,获取对应翻译内容的译文字符串;步骤b10,将译文字符串转化为译文字典;步骤b11,将译文字典转化为与识别结果文本对应的翻译结果。
发明作用与效果
根据本发明的实时语音识别及翻译装置,提供了对视频或是现场演讲的实时翻译,可以自动、实时地提取视频或是现场演讲的语音文本内容,通过根据语音中的断句将声音流分块,同时滤去其中噪音的音频块,能够使语音识别更好地处理断句;该装置还可以实现多语言的识别或翻译,并支持在识别过程中将语言直接翻译输出;由于大部分的识别以及运算都交由服务器执行,因此该装置具有轻量化的特征,不需要很好的硬件、软件支持,可以被安装在普通的电脑或者小设备中,节约经济成本。
附图说明
图1是本发明实施例的装置的结构框图;
图2是本发明实施例的装置的语音识别过程的流程图;以及
图3是本发明实施例的装置的语音翻译过程的流程图。
具体实施方式
以下结合附图来说明本发明的具体实施方式。
<实施例>
图1是本发明实施例的装置的结构框图。
如图1所示,本实施例提供的结合爬虫技术的轻量级实时语音识别及翻译装置100包括:
画面存储部11、输入显示部12、获取控制部13、声音流获取部14、声音流分块部15、音频块缓存部16、音频块缓存控制部17、噪音筛选部18、声音流判断部19、留白判断部20、音频块存储部21、识别请求文件处理部22、识别请求交互部23、识别结果获取部24、翻译请求文件处理部25、翻译请求交互部26、翻译结果获取部27、通信部28以及控制上述各部运行的系统控制部29。
画面存储部11存储有用户输入操作画面、语音识别画面以及语音翻译画面。用户输入操作画面包括有待识别文件选择画面以及麦克风录音选择画面。
输入显示部12显示所述用户输入操作画面让用户选择需要进行识别的待识别文件或是选择使用麦克风录入待识别文件。
用户直接选择待识别文件时,获取控制部13控制声音流获取部14从所述待识别文件中获取待识别声音流;
用户选择使用麦克风录入待识别文件时,获取控制部13控制麦克风开始录音,进一步控制声音流获取部14从麦克风的录音中获取待识别声音流。
声音流分块部15将所述待识别声音流切分成音频块。音频块每块的时长为14秒。
音频块缓存部16对音频块进行暂存。
音频块缓存控制部17控制音频块缓存部16中的音频块数量在20个以下。当音频块数量超出时,音频块缓存控制部17控制音频块缓存部16将新生成的音频块覆盖当前最早生成的音频块。
噪音筛选部17依次筛选音频块并丢弃属于噪音的音频块。
声音流判断部19依次判断噪音筛选部17处理后的音频块是否具有声音流。
音频块存储部21将声音流判断部19判断为具有声音流的音频块作为有效音频块进行存储。
留白判断部20依次判断声音流判断部19处理后的音频块。
判断为留白过多且用户直接选择待识别文件时,获取控制部13控制声音流获取部14停止对待识别声音流的获取;
判断为留白过多且用户选择使用麦克风录入待识别文件时,获取控制部13控制声音流获取部14停止获取识别声音流,并控制麦克风停止录音。
识别请求文件处理部22将需要识别的有效音频块处理为可以发送给识别服务器的识别请求文件。
识别请求交互部23通过通信部28与识别服务器交互并发送识别请求文件。
识别结果获取部24根据所述识别服务器返回的结果获取最终的识别结果文本。
输入显示部12在语音识别画面的文本区中显示识别结果文本。
翻译请求文件处理部25将需要翻译的识别结果文本处理为可以发送给与翻译网站地址对应的翻译服务器的翻译请求文件。
翻译请求交互部26通过通信部28与翻译服务器交互并发送翻译请求文件。
翻译结果获取部27根据翻译服务器返回的结果获取与识别结果文本对应的翻译结果。
输入显示部12在语音翻译画面的文本区显示翻译结果。
通信部28用于完成本实施例的装置与服务器之间的通信。
图2是本发明实施例的装置的语音识别过程的流程图。
本实施例的装置的识别请求文件处理部22、识别请求交互部23以及识别结果获取部24的语音识别过程运行基于如下步骤,如图2所示:
其中,获取token的步骤由步骤a1、步骤a1以及步骤a3组成;
步骤a0,在用户输入待识别文件后,就开始语音识别过程;
步骤a1,通过预先设定的api参数拼接识别服务器的url地址;
步骤a2,向识别服务器发送request请求;
步骤a3,对识别服务器返回的参数筛选获得token参数;
步骤a4,依次读取从音频块存储部中获得的需要识别的音频块并由token参数监听读取的过程,;
步骤a5,将音频块转化为字节类型的多个参数;
步骤a6,将多个参数打包为字典参数;
步骤a7,将字典参数与token参数作为识别请求文件发送给识别服务器;
步骤a8,获取识别服务器返回的结果并筛选出识别内容;
步骤a9,将识别结构内容转化为文本并输出;
步骤a10,结束此次过程。
图3是本发明的装置的语音翻译过程的流程图。
本实施例的装置的翻译请求文件处理部、翻译请求交互部以及翻译结果获取部的语音翻译过程运行基于如下步骤,如图3所示:
其中,打包数据的步骤包括步骤b1、步骤b2、步骤b3以及步骤b4,发起请求的步骤包括步骤b5以及步骤b6,获取响应内容的步骤包括步骤b7以及步骤b8,解析内容的步骤包括步骤b9以及步骤b10;
步骤b0,从语音识别结果部获取到需要翻译的识别结果文本,开始语音翻译过程;
步骤b1,获取预先设定的翻译网站地址;
步骤b2,向所述翻译网站地址的翻译服务器发送预设单词,请求响应,查看其产生的动态参数;
步骤b3,将所述动态参数打包为参数字典;
步骤b4,将需要翻译的所述识别结果文本根据所述参数字典打包为翻译请求文件;
步骤b5,将所述参数字典发送给所述翻译服务器;
步骤b6,以post的方式模拟浏览器请求发起过程,将所述翻译请求发送给所述翻译服务器;
步骤b7,获取所述翻译服务器返回的响应字典;
步骤b8,将所述响应字典转化为响应字符串;
步骤b9,解析所述响应字符串,获取对应翻译内容的译文字符串;
步骤b10,将所述译文字符串转化为译文字典;
步骤b11,将所述译文字典转化为与所述识别结果文本对应的翻译结果;
步骤b12,将翻译结果输出并结束此次过程。
实施例作用与效果
根据本实施例提供的实时语音识别及翻译装置,提供了对视频或是现场演讲的实时翻译,可以自动、实时地提取视频或是现场演讲的语音文本内容,该装置还可以实现多语言的识别及翻译,在识别过程中将语言翻译并直接输出,提高工作效率;由于大部分的识别以及运算都交由服务器执行,因此该装置具有轻量化的特征,不需要很好的硬件、软件支持,可以被安装在普通的电脑或者小设备中,节约经济成本。
实施例中,设置有留白判断部,通过判断读取的音频块中是否存在大量留白,进一步判断音频中是否已经结束说话,从而结束对待识别文件的读取,避免了本实施例的装置长时间的占用终端设备。
实施例中,终端设备还具有麦克风,本实施例的装置能通过获取控制部控制麦克风进行录音,以此实现在现场演讲中实时的对语音进行翻译,同时,设置的留白判断部,可以通过判断读取的音频块中是否存在大量留白,进一步判断现场演讲是否已经结束发言,从而结束对待识别文件的读取并停止麦克风。
实施例中,设置有音频块缓存控制部,可以控制音频块缓存部中的音频块数量,避免本实施例的装置对终端设备的内存的占用。
实施例中,识别请求文件处理部、识别请求交互部以及识别结果获取部的语音识别各部基于语音识别过程方法运行,通过与服务器的交互,将占用大量终端设备运行资源的语音识别交由服务器运行,从而保证了本实施例的装置的轻量化。
实施例中,翻译请求文件处理部、翻译请求交互部以及翻译结果获取部的语音翻译各部基于语音翻译过程方法运行,通过与服务器的交互,将占用大量终端设备运行资源的语音翻译交由服务器运行,从而保证了本实施例的装置的轻量化。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
- 还没有人留言评论。精彩留言会获得点赞!