一种基于VAD算法打断智能语音机器人对话的方法与流程
本发明涉及智能语音对话领域,尤其涉及一种基于vad算法打断智能语音机器人对话的方法。
背景技术:
随着计算机和人工智能技术的飞速发展,智能语音对话被广泛的开发和应用,智能机器人已经越来越多地走进了人们的生活和工作中,生活和工作中的机器人应用领域越来越广,智能机器人时代即将到来,并且大量在社会中广泛使用。
目前,可以通过asr(实时语音识别)与nlp(自然语言理解),实现机器实时理解人类声音语言,在客服、销售等场景进行ai智能沟通,对人类声音语言进行大规模语料训练,在指定场景下,可以得到识别质量较好的识别模型,机器人将人类的声音实时发送到asr中进行识别,得到文本形式的识别结果,用于关键字匹配,或者语义处理,得到预设的问题与答案,在以音频形式播放出来,以匹配人与机器的语音沟通。
虽然现有方案能支持机器人与人类的语言沟通,但是基本以人与机器人之间一问一答的形式为主,很难做到人类水平的插话交流,比较死板且不自然。针对访客的突然插话接入,机器人若无动于衷,显得不礼貌,交流不友好,用户必须听完完整的机器人预设话术,且在机器人话术输出的时段内无法打断或提出疑问,在沟通上难以实现及时、快捷;另一方面,访客的插话打断,可能有更迫切的问题询问,若不及时切换到相关问题节点上,会浪费客户时间。综上所述,现有智能语音机器人与人的语音交流方案在交互体验、沟通效率上仍有待提高。
技术实现要素:
为了提高智能语音机器人的话术水平,实现用户随时打断智能语音机器人语音输出、智能语音机器人在沟通中切换话术的功能,本发明提出了一种基于vad算法打断智能语音机器人对话的方法。
本发明采用如下技术方案:
一种基于vad算法打断智能语音机器人对话的方法,所述方法包括:
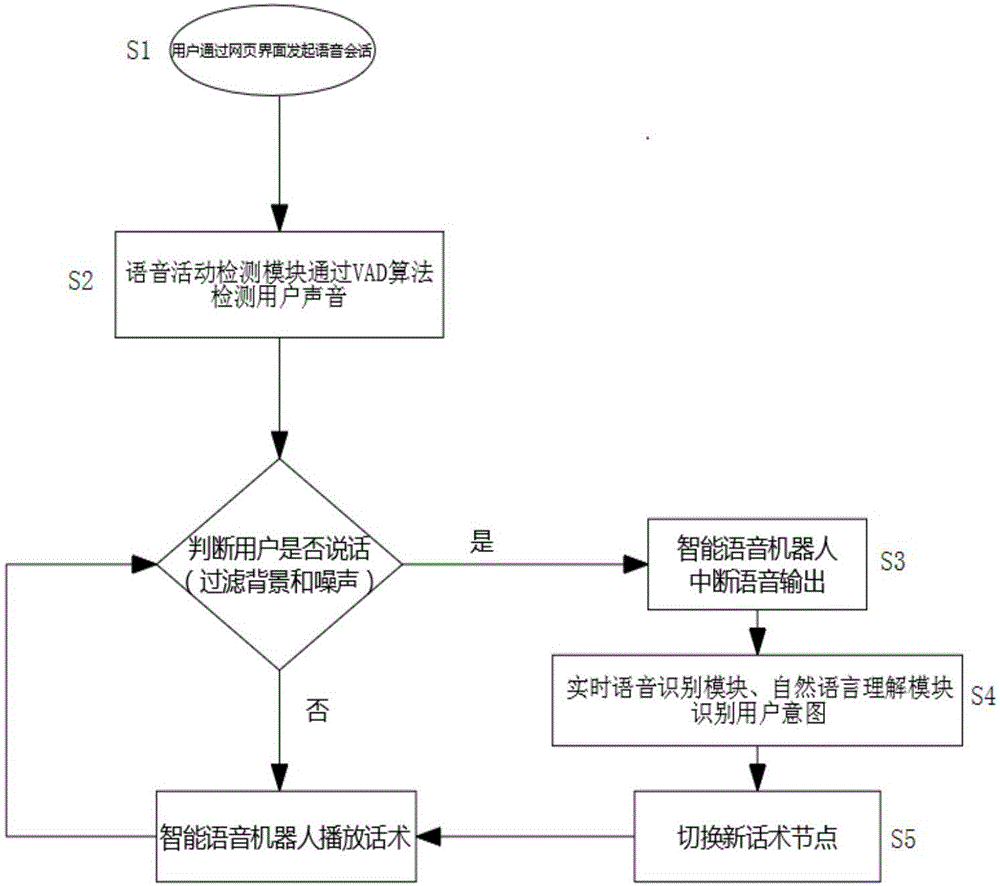
s1、用户在网页界面通过网页即时通信模块发起语音交流,智能语音机器人按照预
设话术进行语音播放;
s2、智能语音机器人内的语音活动检测模块通过vad算法实时检测判断用户是否发
出声音,并过滤背景声音与噪音;
s3、若语音活动检测模块识别用户发出声音,中断智能语音机器人的语音输出,等
待用户发言结束;
s4、智能语音机器人实时将用户发言音频数据发送至实时语音识别模块识别用户发
言内容,并通过自然语言理解模块识别用户意图;
s5、语音活动检测模块识别用户发言结束,智能语音机器人根据识别用户意图改变,
选择切换新话术节点;识别用户意图未改变,继续当前话术节点。
作为优选,所述智能语音机器人还包括第一sip客户端,所述网页界面还包括第二
sip客户端,所述第一sip客户端通过会话发起协议、实时传输协议向第二sip客户端播放话术内容,所述网页即时通信模块通过会话发起协议、实时传输协议向智能语音机器人传输用户的实时音频数据。
作为优选,所述通过vad算法判断用户是否发出声音的步骤如下:
(1)所述语音活动检测模块基于用户发言的音频数据计算最近1秒内复数个采样节
点的声音频率;
(2)设置阈值
音频;
(3)连续n个的采样节点均为有效音频时,计为一次有声片段;
(4)一段时间内的有声片段超过m个时,则判断当前用户处于发言状态。
本发明的有益效果是:1、针对现有方案的不足,本发明提供了基于vad算法的打断智能语音机器人对话方案,以提升交互体验、提高沟通效率;2、本发明包括且不限于通过各类vad智能声音检测技术检查智能语音机器人与用户实时交流过程中,对用户意图的识别、切换,智能语音机器人及时响应访客问题与意图,做到更接近人类日常沟通的体验;3、用户或智能语音机器人发起语音交流后,一直实时检查用户是否发声,识别并做语音分析,检查当前对话用户更明确的问题与意图,并在预设的话术中寻找相关回复;4、对话过程中,智能语音机器人在进行当前节点的语音交流时,也一直通过自然语言理解模块识别用户最新意图,且在识别到最新意图时,及时响应,将进行的对话保留现场,切换到新的对话节点上;5、新的对话节点完成后,智能语音机器人会自动切回之前通话节点,继续交流,也包括用户持续打断对话,并不断切换至新的节点;6、在机器人与访客实时语音交流的过程中实时检测客户声音,并识别意图,及时响应最新的访客问题。能带来更友好、更近乎人类交流的服务体验,大大提升沟通效率与交互体验。
附图说明
图1是本发明的流程示意图;
图2是本发明中通过vad算法判断用户是否发出声音流程示意图;
图3是本发明中智能语音机器人与网页界面的结构示意图。
图1-3中:1、智能语音机器人,2、第一sip客户端,3、实时语音识别模块,4、自然语言理解模块,5、语音活动检测模块,6、网页界面,7、网页即时通信模块,8、第二sip客户端。
具体实施方式
下面通过具体实施例,并结合附图,对本发明的技术方案作进一步的具体描述:
实施例:如附图1-3所示的一种基于vad算法打断智能语音机器人对话的方法,所
述方法包括:
s1、用户在网页界面6通过网页即时通信模块7发起语音交流,智能语音机器人1
按照预设话术进行语音播放;
s2、智能语音机器人1内的语音活动检测模块5通过vad算法实时检测判断用户是
否发出声音,并过滤背景声音与噪音;
s3、若语音活动检测模块5识别用户发出声音,中断智能语音机器人1的语音输出,
等待用户发言结束;
s4、智能语音机器人1实时将用户发言音频数据发送至实时语音识别模块3识别用
户发言内容,并通过自然语言理解模块4识别用户意图;
s5、语音活动检测模块5识别用户发言结束,智能语音机器人1根据识别用户意图
改变,选择切换新话术节点;识别用户意图未改变,继续当前话术节点。
当用户或智能语音机器人1发起语音交流时,智能语音机器人1会实时将访客声音送入实时语音识别模块3和自然语言理解模块4中进行语音识别与语音处理,分析语音内容与用户意图;在智能语音机器人1播放语音时,同时实时检测用户是否发声,并过滤背景声与噪音,当语音活动检测模块5中的vad算法识别到用户说话时,中断智能语音机器人1语音输出,等待用户说话结束;同时将用户的音频数据输送到实时语音识别模块3和自然语言理解模块4中识别用户说话内容与意图,匹配相关问题和回复话术;当用户说话结束时,语音活动检测模块5识别出用户发言结束,智能语音机器人1根据最新匹配的话术内容,进行语音回复。
所述智能语音机器人1还包括第一sip客户端2,所述网页界面6还包括第二sip
客户端8,所述第一sip客户端2通过会话发起协议、实时传输协议向第二sip客户端8播放话术内容,所述网页即时通信模块7通过会话发起协议、实时传输协议向智能语音机器人1传输用户的实时音频数据,通过智能语音机器人1内的第一sip客户端2和网页界面6内的第二sip客户端8、网页即时通信模块7实现用户、智能语音机器人1之间的全双工实时语音通话,智能语音机器人1通过会话发起协议、实时传输协议由第一sip客户端2向第二sip客户端8发送回复的话术内容,用户在网页界面6通过会话发起协议、实时传输协议由网页即时通信模块7向智能语音机器人1传输用户的实时音频数据。
所述通过vad算法判断用户是否发出声音的步骤如下:
(1)所述语音活动检测模块5基于用户发言的音频数据计算最近1秒内复数个采样
节点的声音频率;
(2)设置阈值
音频;
(3)连续n个的采样节点均为有效音频时,计为一次有声片段;
(4)一段时间内的有声片段超过m个时,则判断当前用户处于发言状态。
以每1秒作为一个基础计算单位,根据实际需求调整每1秒的采样节点数量,对不同年龄、不同性别的用户设置不同的阈值
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
- 还没有人留言评论。精彩留言会获得点赞!