基于生成对抗网络的深度特征的语音去混响方法与流程
本发明涉及语音信号处理领域,特别是针对远场语音识别中由于环境的混响所引起的识别性能下降的问题,提出一种基于生成对抗网络的深度特征的语音去混响方法。
背景技术:
近年来,智能家居、对话机器人、智能音响等新兴产业蓬勃发展,给人们的生活方式以及人和机器的交互方式产生了极大的变化,语音交互作为一个新的交互方式在这些新兴领域中得到了广泛的应用。随着深度学习应用在语音识别中,识别性能得到了很大的提高,识别率已经超过95%,识别效果基本上已经能达到了人的听觉水平。但是以上这些仅限于在近场的条件下,噪声和房间所产生的混响非常小,怎样在复杂场景下(噪声很多或者混响很大)达到一个很好的识别效果成为极为重要的用户体验。
语音的去混响是远场语音识别中的一个主要的研究方向。在一个房间内,混响语音可以表示为干净语音信号和房间冲击响应(rir)的卷积,所以含混响的语音会受到同一句话中的之前的语音信息的干扰。混响会包括早期混响和晚期混响,早期混响会对语音识别的效果带来一定的提升,但是晚期混响会使语音识别的识别效果下降。因此,如果能有效地抑制或减少晚期混响,将会得到一个良好的语音识别效果。
现有的研究分为两种:一种是使用信号处理的方法来进行语音去混响如加权预测误差(wpe)的方法;另一种是使用深度学习的方法来进行语音去混响如利用深度神经网络来进行语音的去混响。目前神经网络方法虽然能够建立一个良好的非线性映射,但是仅仅使用全连接的神经网络,效果很难达到我们所预期的效果,其次就是使用最基本的特征映射方法并不能很好的学习到语音的语义信息,构建一个好的网络结构以及研究语音的深层次的语义信息对于语音识别将产生一个好的识别性能的提升,对复杂场景下的语音识别有着现实意义。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出一种基于生成对抗网络的深度特征的语音去混响方法。
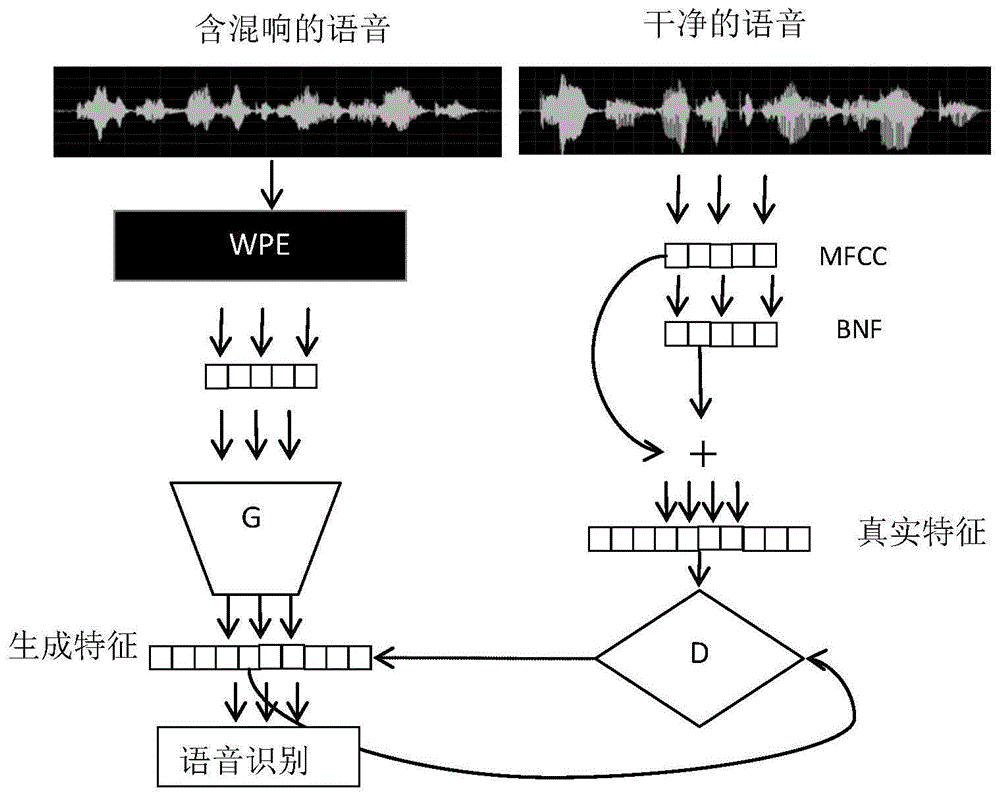
本发明提出一种结合信号处理和神经网络的深度特征映射的语音去混响方法。技术方案以reverbchallenge比赛的数据集作为实验对象。主要涉及四个方面:1)对语音进行加权预测误差(wpe)进行信号的预处理;2)对语音数据进行mfcc特征提取以及不含混响语音的针对音素的瓶颈特征(bnf)提取;3)构建生成对抗网络,另含混响语音(wpe处理后)的mfcc特征通过生成对抗网络映射到干净语音的深度特征;4)通过kaldi工具箱,使用传统的gmm-hmm进行强制对齐,然后利用深度神经网络(dnns)进行声学模型的训练以及解码。具体步骤如下:
1)加权预测误差(wpe)语音信号预处理
这部分,我们对wpe的方法在本发明中的实施方案进行了一个简要的介绍,wpe的方法用来估计和去除单通道语音中的晚期混响,混响语音信号y可以分解为安静语音成分d混响成分l,
y(t,f)=d(t,f)+l(t,f)(1)
l可以通过先前若干点的y加权确定,g表示权重系数;wpe算法的核心问题是确定g,然后估计出混响消除后的语音。
2)mfcc特征提取以及瓶颈特征(bnf)提取
mel频率倒谱系数(mfcc)是基于人耳听觉频域特性,将线性幅度谱映射到基于听觉感知的mel非线性幅度谱中,再转换到倒谱上。有以下步骤:
预加重:将一组语音信号s(n)通过高通滤波器。高通滤波器关系可以表示为:h(z)=1-az-1([a∈[0.9,1]),本实验中a值取0.95。
加窗:本文中取25ms为一帧,并使用了汉宁窗。
快速傅里叶变换(fft):对每一帧进行fft变换,从时域数据转变为频域数据,并计算其能量。
mel滤波:把求出的每帧谱线能量通过mel滤波器,并计算在mel滤波器中的能量。
计算dct倒谱:把mel滤波器的能量取对数后计算dct,就可以得到mel频率倒谱系数mfcc。
干净语音的bnf特征我们使用kaldi工具进行提取。这一步我们首先使用gmm-hmm模型进行语音的强制对齐,然后进行三音素训练,随后采用一个含有三个隐层的全连接神经网络进行音素的bnf的提取,其中我们使用的隐层神经元的个数为512,提取的bnf的维数设置为15。
3)构建生成对抗网络,进行含混响语音的mfcc特征到干净语音特征的bnf的非线性函数的学习
本发明中生成对抗网络的生成器和判别器中的结构如图2所示,生成器中,我们将所提取的mfcc特征作为神经网络的输入,通过一个全连接的输入层,将语音特征映射到一个多维的线性空间,然后我们设置了三层全连接隐层,每个隐层的神经元的个数为1024,最后通过一个输出层输出一个28维的bnf和mfcc的融合特征。对于判别器,本发明同样使用含有相同结构的神经网络作为神经网络框架,在此部分中,我们将生成器所生成的特征和干净语音的特征均输入到判别器当中,输出为一个一维的在0到1之间的数,以此来判断是输入的特征是生成器所生成的还是干净的语音数据。我们在此生成对抗网络结构中所使用的目标函数如下所示:
其中x为干净的语音,xc为含有混响的语音,g(xc)为生成器所生成的特征,d(g(xc))为生成器所生成的特征然后输入到判别器所产生的0到1之间的数值,d(x)为干净的语音数据输入到判别器所产生的0到1之间的数,
4)通过kaldi工具箱进行语音识别
我们进行增强后的特征最终会应用于语音识别系统中,kaldi在做语音识别方面是一个不错的工具,所以本发明中我们使用kaldi中的nnet2中的声学模型进行最终的语音识别。在此过程中,我们使用干净语音的bnf和干净语音的mfcc的融合特征进行归一化然后求其一阶差分和二阶差分,将进行差分后的特征来进行单因素以及三音素训练,本发明中也用了一个lda算法和mllr算法来进行模型的优化。然后,我们使用reverbchallenge数据集中多场景下进行语音去混响之后的bnf和mfcc特征进行声学模型的训练。最后,我们将去混响之后的测试集数据进行解码。在语音识别的这部分,我们使用的语言模型为tri-gram语言模型。
有益效果
本发明主要针对远场,重点以构建生成对抗网络,从带混响语音的mfcc特征映射到干净语音的瓶颈特征学习其非线性函数,并且使用加权预测误差(wpe)的方法进行混响语音的信号处理,具体优点有:
1)通过结合信号处理的方法以及基于生成对抗网络的深度学习框架,使得该系统得以结合两者各自的优势产生一个更好的语音去混响效果;
2)通过提取干净语音的深层次的瓶颈特征,从含混响语音的mfcc特征直接学习一个干净语音的瓶颈特征,减少了一步从混响语音中提取深度瓶颈特征,使得计算量大大减少,而且可以产生一个良好的语音识别效果;
3)针对所提出的模型找到一种减小在真实环境下识别效果并不能达到预期的问题,提出了一种特征融合的方法,使得该系统在真实环境下也可以产生一个比较好的识别效果。
附图说明
图1是基于生成对抗网络的深度特征映射语音去混响方法的系统框图。
图2是生成对抗网络的生成器和判别器的结构:
(a)生成器网络结构;
(b)判别器网络结构。
具体实施方式
下面结合附图和附表对本发明中的作用和效果进行详细说明。
本实施例以基于reverbchallenge数据集为例来给出发明的实施方式,整个系统算法流程如图1所示,包括数据的特征提取、wpe的语音信号预处理、生成对抗网络的构建、特征融合来处理真实世界下语音的过拟合问题以及语音识别模型的训练方式这几个步骤。具体步骤如下:
本发明以2014年reverbchallenge比赛的数据集作为处理对象,提出了一种远场语音识别系统,具体内容包括:
1)针对既要进行远场语音识别中既要进行语音的去混响又要更好的学习深层次的语音信息的问题,本发明中提出一种新的深度特征映射的方法。
2)怎样更好的结合信号处理的方法和深度学习的方法,本发明中提出了一种好的方法来结合两者的优势。
3)使用了一种生成对抗网络的框架来进行语音特征的学习以及映射。
4)利用kaldi工具进行语音识别。
本发明的方法具体步骤如下:
1)实验数据集
为了公平有效的评估我们的方法,我们使用reverb挑战赛官方数据集中的单通道数据集进行实验。我们使用了一种多环境的训练集,该训练集由干净的训练数据通过卷积干净的话语与测量的房间冲击响应所得到,这其中我们也加入了一些加性噪声总的来说信噪比为20db。实验中的测试数据包括模拟数据(simdata)和真实环境下的数据(realdata)。simudata由基于wsjcam0语料库生成的混响语音组成,这些语音采用与多条件训练集相同的人工失真方式。simudata模拟了六种混响情况:三个不同大小的房间(小、中、大)和一个扬声器和麦克风之间的距离(near=50cm和far=200cm)。realdata发音来自mc-wsj-av语料库。在实际情况下,由于扬声器会跟随头部的运动,声源不能被认为是完全空间固定的,因此realdata与模拟数据是两种不同状态下的数据。用于realdata录音的房间不同于用于simudata和训练集的房间,其房间的混响时间约为0.7s,还包含一些固定的环境噪声。realdata中根据扬声器和麦克风之间的两个距离(近=100cm和远=250cm)的不同也分为两种不同的条件。但是由于在realdata和simudata中使用的句子的文本相同。因此,对于simudata和realdata,我们可以使用相同的语言模型以及声学模型。
2)语音识别
kaldi在做语音识别方面是一个不错的工具,所以本发明中我们使用kaldi中的nnet2中的声学模型进行的语音识别。在此过程中,我们使用干净语音的mfcc特征进行归一化然后求其一阶差分和二阶差分,将进行差分后的特征来进行单音素以及三音素训练,本发明中也用了一个lda算法和mllr算法来进行模型的优化。然后,我们使用reverbchallenge数据集中多场景下训练集的mfcc特征进行声学模型的训练。最后,我们将该数据集的测试集数据进行解码。在语音识别的这部分,我们使用的语言模型为tri-gram语言模型。在不进行去混响的情况下,该数据集的结果如表1中:mfcc行。
表1为语音识别的词错率结果
3)使用wpe进行混响的预处理
我们使用wpe中单通道的语音去混响作为本数据集的信号处理部分的混响处理,使用步骤2)中我们提到的语音识别系统,最终的语音识别的词错率如表1中:wpe+mfcc行,可以看出,语音识别的准确率有了一个明显的提升。
4)生成对抗网络的构建
我们使用tensorflow进行了如图2所示的生成对抗网络框架的构建,将生成器和判别器的隐层的个数均设置成3,每个隐层的神经元的个数设置成1024,生成器的输出维度设置成相应的映射干净语音的声学特征,最终我们得到的结果如表1中:mfcc-mfcc行。
5)特征融合
本发明中我们通过拼接mfcc和bnf使其作为干净的特征,将其当做含混响语音的mfcc特征的学习目标,相当于一个多任务学习,我们不仅仅进行声学特征mfcc的学习,而且学习一个mfcc到音素特征的bnf,两者将会产生一定的互补信息,使得在真实场景下能够达到一个更好的识别性能。进行特征融合之后的语音识别的词错率如表1中:mfcc-bnf+mfcc行。
6)wpe和深度特征映射的方法
我们最终的结果先通过一个wpe进行含混响语音的预处理,然后进行含混响语音的mfcc特征提取和对干净语音的mfcc特征提取和利用kaldi工具进行音素bnf的提取,最后拼接两个特征作为生成对抗网络的学习目标。
最终得到的语音识别的词错率如表1:wpe+mfcc-bnf+mfcc行,我们可以看到,使用我们的方法最终的语音识别的词错率对比不处理进行语音识别的词错率降低了6.48%,相对于只使用wpe的词错率降低了3.17%,整个系统将会产生一个相当不错的识别性能。
- 还没有人留言评论。精彩留言会获得点赞!