在错误隐藏过程中在不同域中改善信号衰落的装置及方法与流程
技术领域
本发明涉及音频信号编码、处理及解码,特别地涉及,针对切换式音频编码系统在错误 隐藏过程中的改善信号衰落的装置及方法。
背景技术:
在下文中,描述关于封包丢失隐藏(PLC)过程中的语音及音频编码解码器衰落的现有 技术的状态。关于现有技术的状态的解释始于G系列(G.718、G.719、G.722、G.722.1、 G.729、G.729.1)的ITU-T编码解码器,接着为3GPP编码解码器(AMR、AMR-WB、AMR-WB+) 及IETF编码解码器(OPUS),且以两种MPEG编码解码器(E-AAC、HILN)结束(ITU=国际 电信协会;3GPP=第三代合作伙伴计划;AMR=适应性多速率;WB=宽带;IETF=因特网工程任 务小组)。随后,分析关于追踪背景噪声水平的现有技术的状态,接着为提供概述的总结。
首先,考虑G.718。G.718为支持DTX/CNG(DTX=数字影院系统;CNG=舒缓噪声产生) 的窄频及宽带语音编码解码器。作为尤其涉及低延迟码的实施例,此处,将更详细地描述 低延迟版本模式。
考虑ACELP(层1)(ACELP=代数码激发线性预测),ITU-T为G.718[ITU08a,章节7.11] 推荐了用以控制衰落速度的线性预测域中的适应性衰落。大体而言,隐藏遵循此原理:
根据G.718,在帧擦除的状况下,隐藏策略可总结为将信号能量及频谱包络收敛至背景 噪声的所估计参数。将信号的周期性收敛为零。收敛速度取决于最后正确地接收的帧的参 数及连续被擦除的帧的数目,并由衰减因子α控制。衰减因子α进一步取决于用于无声 帧的LP(LP=线性预测)滤波器的稳定性θ。大体而言,若接收到的最后良好帧处于稳定 分段中,则收敛是缓慢的,且若帧处于转变分段中,则收敛是快速的。
衰减因子α取决于[ITU08a,章节6.8.1.3.1及7.11.1.1]中所描述的信号分类得到 的语音信号类别。基于邻近ISF(导抗频谱频率)滤波器之间的距离度量计算稳定性因子 θ[ITU08a,章节7.1.2.4.2]。
表1展示α的计算方案:
表1:衰减因子α的值,值θ为自邻近LP滤波器之间的距离度量所计算的稳定性因 子[ITU08a,章节7.1.2.4.2]。
此外,G.718提供衰落方法以便修改的频谱包络。一般想法为使最后的ISF参数朝向适 应性ISF均值向量收敛。首先,从最后3个已知的ISF向量计算出平均ISF向量。接着, 将平均ISF向量与脱机训练的长期ISF向量(其为常数向量)再次平均[ITU08a,章节 7.11.1.2]。
此外,G.718提供衰落方法,以控制长期行为且因此控制与背景噪声的相互作用,其中 将音高激发能量(且因此激发周期性)收敛为0,而随机激发能量收敛为CNG激发能量 [ITU08a,章节7.11.1.6]。如下计算创新增益衰落:
其中为下一个帧的开始处的创新增益,为当前帧的开始处的创新增益,gn为舒缓噪 声产生过程中所使用的激发增益及衰减因子α。
类似于周期性激发衰落,从开始,并在下一个帧的开始处到达逐个样本地贯 穿帧以使增益线性衰减。
图2概述G.718的解码器结构。特别地,图2说明用于PLC的具有高通滤波器的高阶 G.718解码器结构。
通过G.718的上文所描述的方法,对于封包丢失的较长突发,创新增益gs收敛为舒缓 噪声产生过程中所使用的增益gn。如[ITU08a,章节6.12.3]中所描述,舒缓噪声增益gn给 定为能量的平方根。并不详细描述的更新条件。遵循参考实施(浮点C码, stat_noise_uv_mod.c),如下得到
其中unvoiced_vad包含语音活动检测,其中unv_cnt包含成列的无声帧的数目,其中 lp_gainc包含固定码簿的低通增益,且其中lp_ener包含初始化为0的低通CNG能量估计
此外,若最后的良好帧的信号分类为不同于无声的信号,则G.718提供引入至无声激 发的信号路径中的高通滤波器,参见图2,亦参见[ITU08a,章节7.11.1.6]。此滤波器具 有低搁板特性,其在DC处的频率响应比奈奎斯频率处的频率响应低大约5dB。
此外,G.718提出解耦式LTP反馈回路(LTP=长期预测):虽然在正常操作过程中,基 于完全激发逐子帧地更新用于适应性码簿的反馈回路([ITU08a,章节7.1.2.1.4])。在隐 藏过程中,仅基于有声激发,逐帧地更新此反馈回路(参见[ITU08a,章节7.11.1.4、7.11.2.4、 7.11.1.6、7.11.2.6;dec_GV_exc@dec_gen_voic.c及 syn_bfi_post@syn_bfi_pre_post.c])。借助于此方法,适应性码簿未被噪声「污染」,该噪 声的起源在于随机选择的创新激发。
关于G.718的变换编码增强层(3至5),在隐藏过程中,解码器的关于高层解码的行 为类似于正常操作,只是MDCT(改善型离散余弦转换)频谱被设定为零。在隐藏过程中并 未应用特定的衰落行为。
关于CNG,在G.718中,按以下次序完成CNG合成。首先,对舒缓噪声帧的参数进行解 码。接着,合成舒缓噪声帧。然后重置音高缓冲器。接着,储存用于FER(帧错误恢复)分 类的合成。然后,进行频谱去加重。接着进行低频后滤波。接着,更新CNG变量。
在隐藏的状况下,执行完全一样的步骤,除了从比特串流中解码CNG参数。这意味在 帧丢失的过程中不更新参数,而是使用来自最后良好SID(静默插入描述符)帧的解码参 数。
现在考虑G.719。基于Siren 22的G.719为基于变换的全频带音频编码解码器。ITU- T为G.719推荐了在频谱域中具有帧重复的衰落[ITU08b,章节8.6]。根据G.719,将帧擦 除隐藏机制并入到解码器中。当正确地接收到帧时,将重建变换系数储存于缓冲器中。若 通知解码器帧已丢失或帧被损毁,则在最近接收的帧中重建的变换系数以因子0.5按比例 递减,且接着被用作当前帧的重建变换系数。解码器通过将这些系数变换至时域及执行开 窗重迭相加操作而继续进行。
在下文中,描述了G.722。G.722为50至7000Hz编码系统,其使用在高达64kbit/s (千位/秒)的比特率内的子频带适应性差分脉码调制(SB-ADPCM)。使用QMF分析(QMF= 正交镜像滤波)将信号拆分成较高及较低子频带。两个所得频带为ADPCM编码的(ADPCM= 适应性差分脉码调制)。
对于G.722,在附录III[ITU06a]中指定用于封包丢失隐藏的高复杂性算法,及在附录 IV[ITU07]中指定用于封包丢失隐藏的低复杂性算法。G.722-附录III([ITU06a,章节 III.5])提出逐步执行的静音,其在帧丢失20ms之后开始,在帧丢失60ms之后完成。此 外,G.722-附录IV提出衰落技术,其「对每一个样本」应用「逐样本地计算及调适的增益 因子」[ITU07,章节IV.6.1.2.7]。
在G.722中,就在QMF合成之前,静音程序发生于子频带域中,且作为PLC模块的最 后步骤。使用来自信号分类器的类别信息执行静音因子的计算,该信号分类器亦为PLC模 块的部分。在类别TRANSIENT、UV_TRANSITION与其他类别之间进行区别。此外,在10ms 帧的单次丢失与其他状况(10ms帧的多次丢失及20ms帧的单次/多次丢失)之间进行区 别。
由图3说明此情形。特别地,图3描绘G.722的衰落因子取决于类别信息且其中80个 样本等效于10ms的情境。
根据G.722,PLC模块产生用于遗漏帧的信号及应该与下一良好帧交叉衰落的某一额外 信号(10ms)。针对此额外信号的静音遵循相同规则。在G.722的高频带隐藏中,交叉衰 落并未发生。
在下文中,考虑G.722.1。基于Siren 7的G.722.1为具有超宽带带扩展模式的基于变 换的宽带带音频编码解码器,其被称作G.722.1C。G.722.1C自身基于Siren 14。ITU T为 G.722.1推荐具有后续静音的帧重复[ITU05,章节4.7]。若借助于此推荐中未定义的外部 发信号机制来通知解码器帧已丢失或损毁,则解码器重复先前帧的解码MLT(调制重迭变 换)系数。该解码器通过将该系数变换至时域及执行与先前及下一帧的解码信息的重迭及 相加操作来继续进行。若先前帧亦丢失或损毁,则解码器将所有当前帧MLT系数设定为零。
现在考虑G.729。G.729为用于语音的音频数据压缩算法,其压缩10毫秒持续时间的 封包中的数字语音。其被正式地描述为使用码激发线性预测语音编码码(CS-ACELP)的在8 kbit/s下的语音编码[ITU12]。
如[CPK08]中所概述,G.729推荐LP域中的衰落。G.729标准中所使用的PLC算法基于 先前接收的语音信息来重建用于当前帧的语音信号。换言之,PLC算法用先前接收的帧的 等效特性来代替遗漏激发,但激发能量最终逐渐衰减,适应性及固定码簿的增益按常数因 子衰减。
通过以下等式来给出衰减的固定码簿增益:
其中m为子帧索引。
适应性码簿增益是基于先前适应性码簿增益的衰减版本:
限制為
Nam in Park等人针对G.729提议使用借助于线性回归的预测的信号振幅控制[CPK08, PKJ+11]。其用于突发封包丢失,且使用线性回归作为核心技术。线性回归是基于如下线性 模型:
g′i=a+bi (2)
其中,g′i为新预测的当前振幅,a及b为用于一阶线性函数的系数,且i为帧的索引。 为了找到优化系数a*及b*,使平方预测误差的总和最小化:
ε为平方误差,gj为原始的过去第j个振幅。为了使此误差最小化,简单地将关于a及 b的导数设定为零。通过使用优化参数a*及b*,每一个的估计由以下等式来表示:
图4展示通过使用线性回归的振幅预测,特别地,振幅的预测。
为了获得丢失封包i的振幅A′i,将比率σi
与比例因子Si相乘:
A′i=Si*σi (6)
其中比例因子Si取决于连续隐藏帧的数目l(i):
在[PKJ+11]中,提出了略有不同的按比例缩放。
根据G.729,然后A′i将被平滑化以防止帧边界处的离散衰减。将最终平滑化振幅Ai(n) 与自先前PLC组件获得的激发相乘。
在下文中,考虑G.729.1。G.729.1为基于G.729的嵌入式可变比特率编码器:可与 G.729互操作的8至32kbit/s可调式宽带编码器比特串流[ITU06b]。
根据G.729.1,如在G.718(参见上文)中,提出适应性衰落,其取决于信号特性的稳 定性([ITU06b,章节7.6.1])。在隐藏的过程中,信号通常是基于衰减因子α而衰减的, 衰减因子α取决于最后良好接收的帧类别的参数及连续被擦除帧的数目。衰减因子α进 一步取决于用于无声帧的LP滤波器的稳定性。大体而言,若最后良好接收帧处于稳定分段 中,则衰减是缓慢的,且若帧处于转变分段中,则衰减是快速的。
此外,衰减因子α取决于每一子帧的平均音高增益([ITU06b,等式163,164]):
其中为子帧i中的音高增益。
表2展示α的计算方案,其中
在隐藏程序的过程中,α被用于以下隐藏工具中:
表2:衰减因子α的值,值θ为自邻近LP滤波器之间的距离度量所计算的稳定性因 子。[ITU06b,章节7.6.1]。
根据G.729.1,关于喉脉冲再同步,因为先前帧的激发的最后脉冲是用于建构周期性部 分,所以其增益在隐藏的帧的开始处大约是正确的,且可被设定为1。增益接着在整个帧中 逐样本地线性衰减,从而达成在帧的结束处的α的值。通过使用最后良好帧的每一子帧的 音高激发增益值来外插有声片段的能量演进。大体而言,若这些增益大于1,则信号能量正 在增加,若这些增益小于1,则能量正在减少。α因此被设定为如上文所描述, 参见[ITU06b,等式163,164]。β的值被限于0.98与0.85之间,从而避免强能量增加及 减少,参见[ITU06b,章节7.6.4]。
关于激发的随机部分的建构,根据G.729.1,在被擦除区块的开始处,通过使用最后良 好帧的每一子帧的创新激发增益来初始化创新增益gs:
gs=0.1g(0)+0.2g(1)+0.3g(2)+0.4g(3)
其中g(0)、g(1)、g(2)及g(3)为最后正确地接收的帧的四个子帧的固定码簿增 益或创新增益。如下进行创新增益衰减:
其中为在下一帧的开始处的创新增益,为在当前帧的开始处的创新增益,且α 是如上文表2中所定义。类似于周期性激发衰减,增益因此在整个帧中逐样本地线性衰减, 以开始,且直至会在下一帧的开始处达成的的值。
根据G.729.1,若最后良好帧为无声,则仅使用创新激发且其进一步按0.8的因子衰 减。在此状况下,用创新激发来更新过去激发缓冲器,因为激发的周期性部分是不可用的, 参见[ITU06b,章节7.6.6]。
在下文中,考虑AMR。3GPP AMR[3GP12b]为利用ACELP算法的语音编码解码器。AMR能 够编码具有8000个样本/s的采样率及4.75与12.2kbit/s之间的比特率的语音,且支持 静默描述符帧的发信号(DTX/CNG)。
在AMR中,在错误隐藏的过程中(参见[3GP12a]),区别了易于出错(位错误)的帧与 完全丢失(完全没有资料)的帧。
对于ACELP隐藏,AMR引入估计频道质量的状态机:状态计数器的值愈大,频道质量愈 差。系统在状态0开始。每次检测到不良帧,状态计数器便递增1,且在其达到6时饱和。 每次检测到良好语音帧,状态计数器便被重置为零,不过在状态为6时除外,此时状态计 数器被设定为5。状态机的控制流程可由以下C程序代码描述(BFI为不良帧指示符,State 为状态变量):
除了此状态机之外,在AMR中,检查来自当前及先前帧的不良帧旗标(prevBFI)。
三个不同组合为可能的:
三个组合中的第一个为BFI=0,prevBFI=0,State=0:在所接收的语音帧或在先前接收 的语音帧中并未检测到错误。所接收的语音参数以正常方式用于语音合成中。储存语音参 数的当前帧。
三个组合中的第二者为BFI=0,prevBFI=1,State=0或5:在所接收的语音帧中并未检 测到错误,但先前接收的语音帧是不良的。限制LTP增益及固定码簿增益使其低于用于最 后接收的良好子帧的值:
其中gp=当前解码LTP增益,gp(-1)=用于最后良好子帧的LTP增益(BFI=0),且
其中gc=当前解码固定码簿增益,且gc(-1)=用于最后良好子帧的固定码簿增益(BFI=0)。
所接收的语音参数的剩余部分被正常地用于语音合成中。储存语音参数的当前帧。
三个组合中的第三者为BFI=1,prevBFI=0或1,State=1……6:在所接收的语音帧中 检测到错误,且开始替换及静音程序。LTP增益及固定码簿增益由来自先前子帧的衰减值代 替:
其中gp指示当前解码LTP增益,且gp(-1),……,gp(-n)指示用于最后n个子帧的LTP 增益,且median5()指示5点中值运算,且
P(state)=衰减因子,
其中(P(1)=0.98,P(2)=0.98,P(3)=0.8,P(4)=0.3,P(5)=0.2, P(6)=0.2)且state=状态号,且
其中gc指示当前解码固定码簿增益,且gc(-1),……,gc(-n)指示用于最后n个子帧 的固定码簿增益,且median5()指示5点中值运算,且C(state)=衰减因子,其中(C (1)=0.98,C(2)=0.98,C(3)=0.98,C(4)=0.98,C(5)=0.98,C(6) =0.7)且state=状态号。
在AMR中,LTP滞后值(LTP=长期预测)由来自先前帧的第4个子帧的过去值(12.2模 式)或基于最后正确接收的值略作修改的值(所有其他模式)代替。
根据AMR,在接收到损毁资料时按接收到固定码簿创新脉冲时的状态使用来自错误帧 的所接收脉冲。在并未接收到数据的状况下,应使用随机固定码簿索引。
关于AMR中的CNG,根据[3GP12a,章节6.4],通过使用来自较早接收的有效SID帧的 SID信息来替换每一个第一丢失的SID帧,且应用用于有效SID帧的程序。对于后续丢失 的SID帧,将衰减技术应用于舒缓噪声,该舒缓噪声将逐渐减少输出水平。因此,检查最 后SID更新是否是在超过50个帧(=1s)以前,若是如此,则将使输出静音(每一帧水平 衰减-6/8dB[3GP12d,dtx_dec{}@sp_dec.c],其每秒产生37.5dB)。应注意在LP域中执 行应用于CNG的衰落。
在下文中,考虑AMR-WB。适应性多速率WB[ITU03,3GP09c]为基于AMR的语音编码解 码器,ACELP(参见章节1.8)。其使用参数带宽扩展且亦支持DTX/CNG。在标准[3GP12g]的 描述中,给出了隐藏实例解决方案,其与AMR[3GP12a]下的状况相同,具有微小的偏差。因 此,此处仅描述与AMR的不同之处。针对标准描述,参见上文的描述。
关于ACELP,在AMR-WB中,基于参考源代码,通过修改音高增益gp(针对上文的AMR, 被称作LTP增益)及通过修改码增益gc执行ACELP衰落[3GP12c]。
在丢失帧的状况下,用于第一子帧的音高增益gp与最后良好帧中的音高增益相同,不 过其被限于0.95与0.5之间。对于第二、第三及以后的子帧,音高增益gp以0.95的因子 减小,且再次受限制。
AMR-WB提出:在隐藏的帧中,gc是基于最后gc:
gc,current=gc,past*(1.4-gp,past) (14)
为了隐藏LTP滞后,在AMR-WB中,将五个最后良好LTP滞后及LTP增益的历史用于寻 找在帧丢失的状况下进行更新的最佳方法。在接收到具有位错误的帧的情况下,不论所接 收的LTP滞后是否可使用,皆执行预测[3GP12g]。
关于CNG,在AMR-WB中,若最后正确地接收的帧为SID帧,且帧分类为丢失,则其应 由最后有效的SID帧信息来替换,且应该应用用于有效SID帧的程序。
对于后续丢失SID帧,AMR-WB提出将衰减技术应用于舒缓噪声,该舒缓噪声将逐渐减 少输出水平。因此,检查最后SID更新是否是在超过50个帧(=1s)以前,若是如此,则 将输出静音(每一帧水平衰减-3/8dB[3GP12f,dtx_dec{}@dtx.c],其每秒产生18.75 dB)。应注意在LP域中执行应用于CNG的衰落。
现在考虑AMR-WB+。适应性多速率WB+[3GP09a]为使用ACELP及TCX(TCX=9变换编码 激发)作为核心编码解码器的切换式编码解码器。其使用参数带宽扩展且亦支持DTX/CNG。
在AMR-WB+中,应用模式外插逻辑以在失真超帧内外插丢失帧的模式。此模式外插是基 于在模式指示符的定义中存在冗余的事实。由AMR-WB+提出的决策逻辑(参见[3GP09a]的图 18)如下:
-定义向量模式(m-1,m0,m1,m2,m3),其中m-1指示先前超帧的最后帧的模式,且 m0、m1、m2、m3指示当前超帧(自比特串流解码)中的帧的模式,其中mk=-1、0、1、2或 3(-1:丢失,0:ACELP,1:TCX20,2:TCX40,3:TCX80),且其中丢失帧的数目nloss 可在0与4之间。
-若m-1=3,且帧0至3的模式指示符中的两者等于三,则所有指示符将被设定为 三,因为接着可肯定在超帧内指示了一个TCX80帧。
-若帧0至3中的仅一个指示符为三(且丢失帧的数目nloss为三),则模式将被设 定为(1,1,1,1),因为接着TCX80目标频谱的3/4丢失且极有可能全局TCX增益丢失。
-若模式指示(x,2,-1,x,x)或(x,-1,2,x,x),则其将被外插为(x,2,2, x,x),从而指示TCX40帧。若模式指示(x,x,x,2,-1)或(x,x,-1,2),则其将被外 插为(x,x,x,2,2),亦指示TCX40帧。应注意(x,[0,1],2,2,[0,1])为无效配 置。
-之后,对于丢失的每一帧(模式=-1),若前一帧为ACELP,将模式设定为ACELP(模 式=0),且针对所有其他状况,将模式设定为TCX20(模式=1)。
关于ACELP,根据AMR-WB+,若丢失帧模式导致在模式外插之后mk=0,则针对此帧应 用与[3GP12g]中相同的方法(参见上文)。
在AMR-WB+中,取决于丢失帧的数目及外插之模式,区别进行以下TCX相关隐藏方法 (TCX=经变换编码激发):
-若整个帧丢失,则应用类似ACELP的隐藏:重复最后激发,且使用隐藏的ISF系数 (朝向其适应性均值稍微移位)以合成时域信号。另外,就在LPC(线性预测编码)合成之 前,在线性预测域中乘以每一帧(20ms)0.7的衰落因子[3GP09b,dec_tcx.c]。
-若最后模式为TCX80,以及(部分丢失)超帧的外插模式为TCX80(nloss=[1,2], 模式=(3,3,3,3,3)),则考虑到最后正确地接收的帧,利用相位及振幅外插在FFT 域中执行隐藏。此处,相位信息的外插方法并不被关注(与衰落策略无关),且因此未进行 描述。对于进一步细节,参见[3GP09a,章节6.5.1.2.4]。关于AMR-WB+的振幅修改,针对 TCX隐藏所执行的方法由以下步骤构成[3GP09a,章节6.5.1.2.3]:
-计算先前帧量级频谱:
-计算当前帧量级频谱:
-计算先前与当前帧之间的非丢失频谱系数的能量的增益差:
-使用如下等式来外插遗漏频谱系数的振幅:
若(lost[k]) A[k]=gain·oldA[k]
-在mk=[2,3]的丢失帧的每一其他状况中,使用所有可用的信息(包括全局TCX 增益)来合成TCX目标(解码频谱加噪声填充(使用自比特串流解码的噪声水平)的反FFT)。 在此状况下并不应用衰落。
关于AMR-WB+中的CNG,使用与AMR-WB中相同的方法(参见上文)。
在下文中,考虑OPUS。OPUS[IET12]并有来自两种编码解码器的技术:语音导向式SILK
(其被称为Skype编码解码器)及低潜时CELT(CELT=受约束的能量重迭变换)。可在高及 低比特率之间顺畅地调整Opus,且在内部,Opus在处于较低比特率下的线性预测编码解 码器(SILK)与处于较高比特率下的变换编码解码器(CELT)以及用于短重迭的混合体之 间切换。
关于SILK音讯数据压缩及解压缩,在OPUS中,若干参数在SILK解码器例程中的隐藏 的过程中受到衰减。在使用来自先前帧的激发的最后音高循环积累起激发的情况下,取决 于连续丢失帧的数目,通过对于每一帧将所有LPC系数与0.99、0.95抑或0.90相乘使LTP 增益参数衰减。音高滞后参数在连续丢失的过程中极缓慢地增大。对于单次丢失,与最后 帧相比较,音高滞后参数保持恒定。此外,激发增益参数按每一帧指数地衰减, 使得对于第一激发增益参数,激发增益参数为0.99,使得对于第二激发增益参数,激发增 益参数为0.992等等。使用随机数产生器产生激发,该随机数产生器通过变量溢出产生白 噪声。此外,基于最后正确地接收的系数集合外插LPC系数/对LPC系数求平均值。在产生 衰减的激发向量之后,在OPUS中使用隐藏的LPC系数以合成时域输出信号。
现在,在OPUS的上下文中,考虑CELT。CELT为基于变换的编码解码器。CELT的隐藏 以基于音高的PLC方法为特征,该方法应用于多达五个连续丢失帧。从帧6开始,应用类 似噪声的隐藏方法,该方法产生背景噪声,该背景噪声的特性应该听起来好像先前背景噪 声。
图5说明CELT的突发丢失行为。特别地,图5描绘CELT隐藏语音分段的频谱图(x 轴:时间;y轴:频率)。浅灰色方框指示前5个连续丢失帧,其中应用基于音高的PLC方 法。除此之外,展示了类似噪声的隐藏。应注意的是即刻执行切换,该切换并非平滑地转 变。
关于基于音高的隐藏,在OPUS中,基于音高的隐藏由通过自相关发现解码信号中的周 期性及使用音高偏移(音高滞后)重复窗化波形(在使用LPC分析及合成的激发域中)构 成。窗化波形以保留时域混迭消除的方式与先前帧及下一帧重迭[IET12]。另外,通过以下 程序代码得到及应用衰落因子:
在此程序代码中,exc含有激发信号,该激发信号多达在丢失之前的MAX_PERIOD个样 本。
激发信号稍后与衰减相乘,接着经由LPC合成而被合成及输出。
用于时域方法的衰落算法可概述如下:
-找到在丢失之前的最后音高循环的音高同步能量。
-找到在丢失之前的倒数第二音高循环的音高同步能量。
-若能量增大,则对其进行限制以保持恒定:衰减=1
-若能量减少,则在隐藏的过程中继续相同的衰减。
关于类似噪声的隐藏,根据OPUS,对于第六个及以后的连续丢失帧,执行MDCT域中的 噪声替换方法,以便对舒缓背景噪声进行仿真。
关于背景噪声水平及形状的追踪,在OPUS中,背景噪声估计执行如下:在MDCT分析 之后,计算每一频带的MDCT频带能量的平方根,其中根据[IET12,表55],MDCT频率仓 (bin)的分组遵循巴克尺度(bark scale)。接着通过以下等式将能量的平方根变换至log2域:
bandLogE[i]=log2(e)·loge(bandE[i]-eMeans[i])其中i=0...21 (18)
其中e为欧拉数,bandE为MDCT频带的平方根,且eMeans为常数向量(其为得到导致 增强的编码增益的结果零均值所必要的)。
在OPUS中,如下在解码器侧上对背景噪声求对数[IET12,amp2Log2及log2Amp@ quant_bands.c]:
backgroundLogE[i]=min(backgroundLogE[i]+8·0.001,bandLogE[i]) 其中i=0…21(19)
所追踪的最小能量基本上是由当前帧的频带的能量的平方根来判定的,但自一个帧至 下一帧的增加限于0.05dB。
关于背景噪声水平及形状的应用,根据OPUS,若应用类似PLC的噪声,则使用如在最 后良好帧中得到的backgroundLogE,且将其反向转换至线性域:
其中e为欧拉数,且eMeans为与用于“线性至对数”变换的常数向量相同的常数向量。
当前隐藏程序将用由随机数产生器产生的白噪声填充MDCT帧,且以该白噪声逐频带地 匹配bandE的能量的方式按比例调整此白噪声。随后,应用产生时域信号的反MDCT。在重 迭相加及去加重(如在常规解码中)之后,放出时域信号。
在下文中,考虑MPEG-4HE-AAC(MPEG=动画专业团体;HE-AAC=高效率进阶音讯编码)。 高效率进阶音讯编码由补充了参数带宽扩展(SBR)的基于变换的音频编码解码器(AAC) 构成。
关于AAC(AAC=进阶音讯编码),DAB联盟针对DAB+中的AAC指定了在频域中至零的衰 落[EBU10,章节A1.2](DAB=数位音频传输)。例如衰减斜坡的衰落行为可能为固定的或可 由使用者调整。来自最后AU(AU=存取单元)的频谱系数按对应于衰落特性的因子衰减,且 接着被传递至频率至时间映像。取决于衰减斜坡,隐藏在数个连续无效AU之后切换至静音, 其意味完整频谱将被设定为0。
DRM(DRM=数字版权管理)联盟针对DRM中的AAC指定了在频域中的衰落[EBU12,章节 5.3.3]。隐藏刚好在最终的频率至时间转换之前对频谱数据起作用。若多个帧被损毁,隐 藏首先基于来自最后有效帧的略作修改的频谱值实施衰落。此外,类似于DAB+,例如衰减 斜坡的衰落行为可能为固定的或可由使用者调整。来自最后帧的频谱系数按对应于衰落特 性的因子衰减,且接着被传递至频率至时间映像。取决于衰减斜坡,隐藏在数个连续无效 帧之后切换至静音,其意味完整频谱将被设定为0。
3GPP为增强型aacPlus中的AAC引入了类似于DRM的在频域中的衰落[3GP12e,章节 5.1]。隐藏刚好在最终的频率至时间转换之前对频谱数据起作用。若多个帧被损毁,隐藏 首先基于来自最后良好帧的略作修改的频谱值实施衰落。完整衰落历时5个帧。复制来自 最后良好帧的频谱系数,且其按如下因子衰减:
衰落因子=2-(nFadeOutFrame/2)
其中nFadeOutFrame作为自最后良好帧以来的帧计数器。在历时五个帧的衰落之后,隐藏 切换至静音,此意味完整频谱将被设定为0。
Lauber及Sperschneider为AAC引入了基于能量外插的MDCT频谱的逐帧衰落[LS01, 章节4.4]。前一频谱的能量形状可能被用以外插所估计频谱的形状。可独立于隐藏技术, 作为一种后隐藏来执行能量外插。
关于AAC,在比例因子频带的基础上执行能量计算以便接近人类听觉系统的关键频带。 个别能量值被逐帧地减小以便平滑地降低音量,例如使信号衰落。由于所估计值表示当前 信号随时间流逝而快速降低,所以此情形变得有必要。
为了产生待馈出的频谱,Lauber及Sperschneider提议帧重复或噪声替换[LS01,章节 3.2及3.3]。
Quackenbusch及Driesen针对AAC提议至零的指数逐帧衰落[QD03]。提出了时间/频 率系数的邻近集合的重复,其中每一重复具有指数地增加的衰减,因此在延长的中断的状 况下逐渐衰落至静音。
关于MPEG-4 HE-AAC中的SBR(SBR=频谱带复制),3GPP针对增强型aacPlus中的SBR 提议了对解码包络数据进行缓冲,且在帧丢失的状况下,再次使用所传输的包络数据的缓 冲能量,且针对每一隐藏的帧使能量按3dB的恒定比率减少。将结果反馈至正常解码程序 中,其中包络调整器用其计算增益,这些增益用于调整由HF产生器产生的修补高频带。SBR 解码接着照常发生。此外,增量(δ)编码的噪声底限及正弦水平值被删除。因为与先前信 息的差别不再可用,所以解码噪声底限及正弦水平保持与HF产生的信号的能量成正比 [3GP12e,章节5.2]。
DRM联盟针对结合AAC的SBR指定与3GPP相同的技术[EBU12,章节5.6.3.1]。此外, DAB联盟针对DAB+中的SBR指定与3GPP相同的技术[EBU10,章节A2]。
在下文中,考虑MPEG-4 CELP及MPEG-4 HVXC(HVXC=谐波向量激发编码)。DRM联盟 针对结合CELP及HVXC的SBR[EBU12,章节5.6.3.2]指定不管何时检测到损毁的SBR帧, 用于语音编码解码器的SBR的最低要求隐藏应用于数据值的预定集合。那些值产生在低相 对播放水平处的静态高频带频谱包络,从而展现出朝向较高频率的滚降。目标仅为借助于 插入“舒缓噪声”(与严格的静音相对照)而确保没有不良的、潜在大声的音讯突发到达听 者的耳朵。此实际上并非真正的衰落,而是跳转至某一能量水平以便插入某一种类的舒缓 噪声。
随后,提到替代例[EBU12,章节5.6.3.2],其再次使用最后正确地解码数据且使水平 (L)朝向0缓慢地衰落,这类似于AAC+SBR状况。
现在,考虑MPEG-4 HILN(HILN=谐波及个别线加噪声)。Meine等人引入了在参数域中 用于参数MPEG-4HILN编码解码器[ISO09]的衰落[MEP01]。对于持续谐波分量,用于代替 损毁的差分编码参数的良好默认行为是保持频率恒定,使振幅按衰减因子(例如,-6dB) 减少,及令频谱包络朝向具有平均化的低通特性的频谱包络收敛。用于频谱包络的替代例 将为使其保持不变。关于振幅及频谱包络,可以与对待谐波分量相同的方式来对待噪声分 量。
在下文中,考虑现有技术中的背景噪声水平的追踪。Rangachari及Loizou[RL06]提 供对若干方法的良好概述且论述其中一些的限制。用于追踪背景噪声水平的方法为(例如) 最小值跟踪程序[RL06] [Coh03] [SFB00] [Dob95],基于VAD(VAD=语音活动检测);卡尔 曼滤波[Gan05] [BJH06],子空间分解[BP06] [HJH08];软决策[SS98] [MPC89] [HE95]及 最小值统计。
最小值统计方法被选择用于USAC-2(USAC=统一语音及音讯编码)的范畴内,且随后更 详细概述。
基于最佳平滑及最小值统计的噪声功率谱密度估计[Mar01]引入噪声估计式,该噪声估 计式能够独立于信号为作用中语音或背景噪声的情况而工作。与其他方法相对比,最小值 统计算法并不使用任何显式临限值在语音活动与语音暂停之间进行区分,且因此相较于与 传统的语音活动检测方法相关的程度,与软决策方法相关的程度更高。类似于软决策方法, 其亦可在语音活动的过程中更新所估计噪声PSD(功率谱密度)。
最小值统计方法根据两个观测,亦即语音及噪声通常在统计上独立且有噪声语音信号 的功率频繁衰减至噪声的功率水平。因此有可能通过跟踪有噪声信号PSD的最小值而得到 准确的噪声PSD(PSD=功率谱密度)估计。因为最小值小于(或在其他状况下等于)平均值, 所以最小值跟踪方法需要偏差补偿。
偏差为平滑化信号PSD的方差的函数,且因而取决于PSD估计式的平滑参数。与对最 小值跟踪的较早期研究(其利用恒定平滑参数及恒定最小偏差校正)相对比,使用基于时 间及频率的PSD平滑,其亦需要基于时间及频率的偏差补偿。
使用最小值跟踪提供对噪声功率的粗略估计。然而,存在一些缺点。具有固定平滑参数 的平滑化加宽了平滑化PSD估计的语音活动的峰值。此将产生不准确的噪声估计,因为用 于最小值搜寻的滑动窗可能滑到宽峰值中。因此,无法使用接近于一的平滑参数,且因此, 噪声估计将具有相对较大的方差。此外,使噪声估计偏向较低值。此外,在增加噪声功率 的状况下,最小值跟踪落在后面。
具有低复杂性的基于MMSE的噪声PSD跟踪[HHJ10]引入了背景噪声PSD方法,该方法 利用了用于DFT(离散傅立叶变换)频谱上的MMSE搜寻。该算法由这些处理步骤构成:
-基于先前帧的噪声PSD计算最大可能性估计式。
-计算最小均方估计式。
-使用决策导向方法[EM84]来估计最大可能性估计式。
-在假定语音及噪声DFT系数为高斯分布的情况下计算反偏差因子。
-所估计噪声功率谱密度为平滑的。
亦应用安全网方法以便避免算法的完全死锁。
基于数据驱动的递归噪声功率估计来跟踪非稳定噪声[EH08]引入了用于根据由极不稳 定噪声源污染的语音信号估计噪声频谱方差的方法。此方法亦使用在时间/频率方向上的平 滑。
基于噪声功率估计的平滑及估计偏差校正的低复杂性噪声估计算法[Yu09]增强了 [EH08]中所引入的方法。主要的差别在于,用于噪声功率估计的频谱增益函数是由迭代数 据驱动方法发现的。
用于噪声语音增强的统计方法[Mar03]组合[Mar01]中给出的最小值统计方法、软决策 增益修改[MCA99]、先验SNR的估计[MCA99]、适应性增益限制[MC99]以及MMSE对数频谱振 幅估计式[EM85]。
对于多个语音及音频编码解码器而言,衰落是备受关注的,这些编码解码器特别地为 AMR(参见[3GP12b])(包括ACELP及CNG)、AMR-WB(参见[3GP09c])(包括ACELP及CNG)、 AMR-WB+(参见[3GP09a])(包括ACELP、TCX及CNG)、G.718(参见[ITU08a])、G.719(参 见[ITU08b])、G.722(参见[ITU07])、G.722.1(参见[ITU05])、G.729(参见[ITU12、CPK08、 PKJ+11])、MPEG-4HE-AAC/增强型aacPlus(参见[EBU10、EBU12、3GP12e、LS01、QD03]) (包括AAC及SBR)、MPEG-4HILN(参见[ISO09、MEP01])及OPUS(参见[IET12])(包括 SILK及CELT)。
取决于编码解码器,在不同域中执行衰落:
对于利用LPC的编码解码器,在线性预测域(亦称为激发域)中执行衰落。对于基于 ACELP的编码解码器(例如,AMR、AMR-WB、AMR-WB+的ACELP核心、G.718、G.729、G.729.1、 OPUS中的SILK核心);使用时间-频率变换进一步处理激发信号的编码解码器(例如AMR- WB+的TCX核心、OPUS中的CELT核心)及在线性预测域中操作的舒缓噪声产生(CNG)方案 (例如,AMR中的CNG、AMR-WB中的CNG、AMR-WB+中的CNG)而言,此情形同样适用。
对于将时间信号直接变换至频域的编码解码器,在频谱/子频带域中执行衰落。对于基 于MDCT或类似变换的编码解码器(诸如,MPEG-4HE-AAC中的AAC、G.719、G.722(子频 带域)及G.722.1)而言,此情形同样适用。
对于参数编码解码器,在参数域中应用衰落。对于MPEG-4HILN而言,此情形同样适 用。
关于衰落速度及衰落曲线,衰落通常是通过应用衰减因子而实现,该衰减因子被应用 于适当域中的信号表示。衰减因子的大小控制着衰落速度及衰落曲线。在大多数状况下, 逐帧地应用衰减因子,但亦利用逐样本应用,参见例如G.718及G.722。
可能以两个方式(绝对及相对)提供用于某一信号分段的衰减因子。
在绝对地提供衰减因子的状况下,参考水平总是为最后接收的帧的水平。绝对衰减因 子通常以用于紧接在最后良好帧之后的信号分段的接近1的值开始,且接着朝向0较快地 或较慢地降级。衰落曲线直接取决于这些因子。此为例如G.722的附录IV中所描述的隐藏 的状况(特别地参见[ITU07,图IV.7]),其中可能的衰落曲线为线性或逐渐线性的。考虑 增益因子g(n)(而g(0)表示最后良好帧的增益因子)、绝对衰减因子αabs(n),任何后 续丢失帧的增益因子可得到为:
g(n)=αabs(n)·g(0) (21)
在相对地提供衰减因子的状况下,参考水平为来自先前帧的水平。此情形在递归隐藏 程序的状况下(例如,在已经衰减的信号被进一步处理及再次衰减的情况下)具有优点。
若递归地应用衰减因子,则此因子可能为独立于连续丢失帧的数目的固定值,例如针 对G.719的0.5(参见上文);与连续丢失帧的数目有关的固定值,例如,如在[CPK08]中针 对G.729所提出的:针对前两个帧的1.0、针对接下来两个帧的0.9、针对帧5及6的0.8 及针对所有后续帧的0(参见上文);或与连续丢失帧的数目有关且取决于信号特性的值, 例如用于不稳定的信号的较快衰落及用于稳定信号的较慢衰落,例如G.718(参见上文的章 节及[ITU08a,表44]);
假设相对衰落因子0≤αrel(n)≤1,而n为丢失帧的数目(n≥1);任何后续帧 的增益因子可被得到为:
g(n)=αrel(n)·g(n-1) (22)
从而导致指数衰落。
关于衰落程序,通常指定衰减因子,但在一些应用标准(DRM、DAB+)中,衰减因子的 指定被留给制造者完成。
若不同信号部分被单独地衰落,则可能应用不同衰减因子例如以用某一速度衰减音调 分量及用另一速度衰减类似噪声的分量(例如,AMR、SILK)。
通常,将某一增益应用于整个帧。当在频谱域中执行衰落时,此情形是仅有的可能方 式。然而,若在时域或线性预测域中进行衰落,则可能进行更细致化的衰落。此更细致化 的衰落应用于G.718中,其中通过最后帧的增益因子与当前帧的增益因子之间的线性内插 针对每一样本得到个体增益因子。
对于具有可变帧持续时间的编码解码器,恒定的相对衰减因子导致取决于帧持续时间 的不同衰落速度。例如对于AAC就是此状况,其中帧持续时间取决于采样率。
为了对最后接收的信号的时间形状采用所应用的衰落曲线,可能进一步调整(静态)衰 落因子。例如针对AMR应用此进一步动态调整,其中考虑先前五个增益因子的中值(参见 [3GP12b]及章节1.8.1)。在执行任何衰减之前,若中值小于最后增益,则将当前增益设定 为中值,否则使用最后增益。此外,例如针对G729应用此进一步动态调整,其中使用先前 增益因子的线性回归来预测振幅(参见[CPK08、PKJ+11]及章节1.6)。在此状况下,用于第 一隐藏帧的所得增益因子可能超出最后接收的帧的增益因子。
关于衰落的目标水平,对于所有所分析的编码解码器(包括那些编码解码器的舒缓噪 声产生(CNG)),目标水平为0(G.718及CELT例外)。
在G.718中,单独地执行音高激发(表示音调分量)的衰落及随机激发(表示类似噪 声的分量)的衰落。在音高增益因子衰落至零的同时,创新增益因子衰落至CNG激发能量。
假设给出相对衰减因子,此基于公式(23)而导致以下绝对衰减因子:
g(n)=αrel(n)·g(n-1)+(1-αrel(n))·gn (25)
其中gn为在舒缓噪声产生的过程中使用的激发的增益。当gn=0时,此公式对应于公式(23)。
G.718在DTX/CNG的状况下不执行衰落。
在CELT中,不存在朝向目标水平的衰落,但在历时5个帧的音调隐藏(包括衰落)之 后,水平在第6个连续丢失帧处即刻切换至目标水平。使用公式(19)逐频带地得到水平。
关于衰落的目标频谱形状,所有所分析的纯粹基于变换的编码解码器(AAC、G.719、 G.722、G.722.1)以及SBR仅仅在衰落的过程中延长最后良好帧的频谱形状。
各种语音编码解码器使用LPC合成将频谱形状衰落至均值。均值可能为静态(AMR)或 适应性的(AMR-WB、AMR-WB+、G.718),而适应性均值系自静态均值及短期均值得到(通过 求最后n个LP系数集合的平均值来得到)(LP=线性预测)。
所论述的编码解码器AMR、AMR-WB、AMR-WB+、G.718中的所有CNG模块皆在衰落的过 程中延长最后良好帧的频谱形状。
关于背景噪声水平追踪,自文献中已知五个不同方法:
-基于语音活动检测器:基于SNR/VAD,但极难以调谐,且难以用于低SNR语音。
-软决策方案:软决策方法考虑到语音存在的机率[SS98] [MPC89] [HE95]。
-最小值统计:跟踪PSD的最小值,在缓冲器中随时间的流逝保持一定量的值,因此 使得能够从过去样本中找到最小噪声[Mar01] [HHJ10] [EH08] [Yu09]。
-卡尔曼滤波:算法使用随时间的流逝观测到的含有噪声(随机变化)的一系列量测, 且产生倾向于比单独基于单一量测的估计更精确的噪声PSD的估计。卡尔曼滤波器对有噪 声输入数据的串流进行递归操作,以产生系统状态的统计学上的最佳估计[Gan05] [BJH06]。
-子空间分解:此方法试图利用例如KLT(卡忽南-拉维(Karhunen-Loève)变换,其 亦称为主分量分析)及/或DFT(离散时间傅立叶变换)将类似噪声的信号分解成干净的语 音信号及噪声部分。接着可使用任意平滑算法追踪本征向量/本征值[BP06] [HJH08]。
技术实现要素:
本发明的目的在于提供用于音频编码系统的改善概念。本发明的目的是由一种用于解 码音频信号的装置、由一种用于解码音频信号的方法及由用于执行用于解码音频信号的方 法的计算机程序实现。
提供用于解码音频信号的装置。装置包括接收接口,其中接收接口用于接收包括音频 信号的第一音频信号部分的第一帧,且其中接收接口用于接收包括音频信号的第二音频信 号部分的第二帧。
此外,装置包括噪声水平追踪单元,其中噪声水平追踪单元用于根据第一音频信号部 分及第二音频信号部分中的至少一个(这意味:根据第一音频信号部分及/或第二音频信号 部分)判定噪声水平信息,其中噪声水平信息被表示于追踪域中。
进一步地,装置包括第一重建单元,该第一重建单元用于在多个帧中的第三帧不由接 收接口接收的情况下或在第三帧由接收接口接收但被损毁的情况下,根据噪声水平信息而 在第一重建域中重建音频信号的第三音频信号部分,其中第一重建域不同于或等于追踪域。
此外,装置包含变换单元,该变换单元用于在多个帧中的第四帧不由接收接口接收的 情况下或在第四帧由接收接口接收但被损毁的情况下,将噪声水平信息自追踪域变换至第 二重建域,其中第二重建域不同于追踪域,且其中第二重建域不同于第一重建域,及
进一步地,装置包含第二重建单元,该第二重建单元用于在多个帧中的第四帧不由接 收接口接收的情况下或在第四帧由接收接口接收但被损毁的情况下,根据在第二重建域中 表示的噪声水平信息而在第二重建域中重建音频信号的第四音频信号部分。
根据一些实施例,追踪域可例如其中追踪域为时域、频谱域、FFT域、MDCT域或激发 域。第一重建域可例如为时域、频谱域、FFT域、MDCT域或激发域。第二重建域可例如为 时域、频谱域、FFT域、MDCT域或激发域。
在实施例中,追踪域可例如为FFT域,第一重建域可例如为时域,及第二重建域可例 如为激发域。
在另一实施例中,追踪域可例如为时域,第一重建域可例如为时域,及第二重建域可例 如为激发域。
根据实施例,该第一音频信号部分可例如被表示于第一输入域中,及该第二音频信号 部分可例如被表示于第二输入域中。变换单元可例如为第二变换单元。装置可例如进一步 包含第一变换单元,第一变换单元用于将第二音频信号部分或自第二音频信号部分得到的 值或信号自第二输入域变换至追踪域以获得第二信号部分信息。噪声水平追踪单元可以例 如用于接收在追踪域中表示的第一信号部分信息,其中第一信号部分信息根据第一音频信 号部分,其中噪声水平追踪单元用于接收在追踪域中表示的第二信号部分,且其中噪声水 平追踪单元用于根据在追踪域中表示的第一信号部分信息及根据在追踪域中表示的第二信 号部分信息判定噪声水平信息。
根据实施例,第一输入域可例如为激发域,及第二输入域可例如为MDCT域。
在另一实施例中,第一输入域可例如为MDCT域,且其中第二输入域可例如为MDCT域。
根据实施例,第一重建单元可例如用于通过进行至类似噪声的频谱的第一衰落来重建 第三音频信号部分。第二重建单元可例如用于通过进行至类似噪声的频谱的第二衰落及/或 LTP增益的第二衰落来重建第四音频信号部分。此外,第一重建单元及第二重建单元可例如 用于在相同衰落速度的情况下,进行至类似噪声的频谱的第一衰落及第二衰落及/或LTP增 益的第二衰落。
在实施例中,装置可例如进一步包括用于根据第一音频信号部分而判定第一聚合值的 第一聚合单元。此外,装置可例如进一步包括用于根据第二音频信号部分而将第二聚合值 判定为自第二音频信号部分得到的值的第二聚合单元。噪声水平追踪单元可例如用于接收 第一聚合值作为在追踪域中表示的第一信号部分信息,其中噪声水平追踪单元用于接收第 二聚合值作为在追踪域中表示的第二信号部分信息,且其中噪声水平追踪单元用于根据在 追踪域中表示的第一聚合值及根据在追踪域中表示的第二聚合值而判定噪声水平信息。
根据实施例,第一聚合单元可例如用于判定第一聚合值以使得第一聚合值指示第一音 频信号部分或自第一音频信号部分得到的信号的均方根。第二聚合单元用于判定第二聚合 值以使得第二聚合值指示第二音频信号部分或自第二音频信号部分得到的信号的均方根
在实施例中,第一变换单元可例如用于通过对自第二音频信号部分得到的值应用增益 值而将自第二音频信号部分得到的值自所述第二输入域变换至追踪域。
根据实施例,增益值可例如指示由线性预测编码合成引入的增益,或其中增益值指示 由线性预测编码合成及去加重引入的增益。
在实施例中,噪声水平追踪单元可例如用于通过应用最小值统计方法来判定噪声水平 信息。
根据实施例,噪声水平追踪单元可例如用于将舒缓噪声水平判定为噪声水平信息。重 建单元可例如用于在多个帧中的第三帧不由接收接口接收的情况下或在第三帧由接收接口 接收但被损毁的情况下,根据噪声水平信息而重建第三音频信号部分。
在实施例中,噪声水平追踪单元可例如用于将舒缓噪声水平判定为自噪声水平频谱得 到的噪声水平信息,其中该噪声水平频谱是通过应用最小值统计方法而获得。重建单元可 例如用于在多个帧中的第三帧不由接收接口接收的情况下或在第三帧由接收接口接收但被 损毁的情况下,根据多个线性预测系数而重建第三音频信号部分。
根据实施例,第一重建单元可例如用于在多个帧中的第三帧不由接收接口接收的情况 下或在第三帧由接收接口接收但被损毁的情况下,根据噪声水平信息及根据第一音频信号 部分而重建第三音频信号部分。
在实施例中,第一重建单元可例如用于通过减小或放大第一音频信号部分来重建第三 音频信号部分。
根据实施例,第二重建单元可例如用于根据噪声水平信息和根据第二音频信号部分来 重建第四音频信号部分。
在实施例中,第二重建单元可例如用于通过减小或放大第二音频信号部分来重建第四 音频信号部分。
根据实施例,装置可例如进一步包含长期预测单元,该长期预测单元包含延迟缓冲器, 其中长期预测单元可例如用于根据第一音频信号部分或第二音频信号部分、根据储存于延 迟缓冲器中的延迟缓冲器输入及根据长期预测增益而产生处理信号,且其中长期预测单元 用于在多个帧中的第三帧不由接收接口接收的情况下或在第三帧由接收接口接收但被损毁 的情况下,使长期预测增益朝向零衰落。
在实施例中,长期预测单元可例如用于使长期预测增益朝向零淡化,其中长期预测增 益朝向零衰落的速度取决于衰落因子。
在实施例中,长期预测单元可例如用于在多个帧中的第三帧不由接收接口接收的情况 下或在第三帧由接收接口接收但被损毁的情况下,通过将所产生的处理信号储存于延迟缓 冲器中来更新延迟缓冲器输入。
此外,提供用于解码音频信号的方法。该方法包括:
-接收包括音频信号的第一音频信号部分的第一帧,及接收包括音频信号的第二音频 信号部分的第二帧。
-根据第一音频信号部分及第二音频信号部分中的至少一个判定噪声水平信息,其中 噪声水平信息被表示于追踪域中。
-在多个帧中的第三帧未被接收的情况下或在第三帧被接收但被损毁的情况下,根据 噪声水平信息而在第一重建域中重建音频信号的第三音频信号部分,其中第一重建域不同 于或等于追踪域。
-在多个帧中的第四帧未被接收的情况下或在第四帧被接收但被损毁的情况下,将噪 声水平信息自追踪域变换至第二重建域,其中第二重建域不同于追踪域,且其中第二重建 域不同于所述第一重建域。及:
-在多个帧中的第四帧未被接收的情况下或在第四帧被接收但被损毁的情况下,根据 在第二重建域中表示的噪声水平信息而在第二重建域中重建音频信号的第四音频信号部分。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程 序。
此外,提供用于解码音频信号的装置。
装置包含接收接口。接收接口用于接收多个帧,其中该接收接口用于接收多个帧中的 第一帧,该第一帧包含音频信号的第一音频信号部分,该第一音频信号部分被表示于第一 域中,且其中接收接口用于接收多个帧中的第二帧,该第二帧包含音频信号的第二音频信 号部分。
此外,装置包含变换单元,该变换单元用于将第二音频信号部分或自第二音频信号部 分得到的值或信号自第二域变换至追踪域,以获得第二信号部分信息,其中第二域不同于 第一域,其中追踪域不同于第二域,且其中追踪域等于或不同于第一域。
此外,装置包含噪声水平追踪单元,其中噪声水平追踪单元用于接收在追踪域中表示 的第一信号部分信息,其中第一信号部分信息取决于第一音频信号部分。噪声水平追踪单 元用于接收在追踪域中表示的第二信号部分,且其中噪声水平追踪单元用于取决于在追踪 域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号部分信息而判定噪声水 平信息。
此外,装置包含重建单元,该重建单元用于在多个帧中的第三帧不由接收接口接收而 是被损毁的情况下,取决于噪声水平信息而重建音频信号的第三音频信号部分。
音频信号可例如为语音信号或音乐信号,或包含语音及音乐的信号等。
第一信号部分信息取决于第一音频信号部分的陈述意味:第一信号部分信息为第一音 频信号部分或已取决于第一音频信号部分而获得/产生第一信号部分信息抑或第一信号部 分信息以某一其他方式取决于第一音频信号部分。举例而言,第一音频信号部分可能已自 一个域变换至另一域以获得第一信号部分信息。
同样,第二信号部分信息取决于第二音频信号部分的陈述意味:第二信号部分信息为 第二音频信号部分抑或已取决于第二音频信号部分而获得/产生第二信号部分信息抑或第 二信号部分信息以某一其他方式取决于第二音频信号部分。举例而言,第二音频信号部分 可能已自一个域变换至另一域以获得第二信号部分信息。
在实施例中,第一音频信号部分可例如表示于作为第一域的时域中。此外,变换单元可 例如用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的激发域变换至 为追踪域的时域。此外,噪声水平追踪单元可例如用于接收在作为追踪域的时域中表示的 第一信号部分信息。此外,噪声水平追踪单元可例如用于接收在作为追踪域的时域中表示 的第二信号部分。
根据实施例,第一音频信号部分可例如表示于作为第一域的激发域中。此外,变换单元 可例如用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的时域变换至 为追踪域的激发域。此外,噪声水平追踪单元可例如用于接收在作为追踪域的激发域中表 示的第一信号部分信息。此外,噪声水平追踪单元可例如用于接收在作为追踪域的激发域 中表示的第二信号部分。
在实施例中,第一音频信号部分可例如表示于作为第一域的激发域中,其中噪声水平 追踪单元可例如用于接收第一信号部分信息,其中该第一信号部分信息被表示于为追踪域 的FFT域中,且其中该第一信号部分信息取决于在激发域中表示的该第一音频信号部分, 其中变换单元可例如用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域 的时域变换至为追踪域的FFT域,且其中噪声水平追踪单元可例如用于接收在FFT域中表 示的第二音频信号部分。
在实施例中,装置可例如进一步包含用于取决于第一音频信号部分而判定第一聚合值 的第一聚合单元。此外,装置可例如进一步包含用于取决于第二音频信号部分而将第二聚 合值判定为自第二音频信号部分得到的值的第二聚合单元。此外,噪声水平追踪单元可例 如用于接收第一聚合值作为在追踪域中表示的第一信号部分信息,其中噪声水平追踪单元 可例如用于接收第二聚合值作为在追踪域中表示的第二信号部分信息,且其中噪声水平追 踪单元可例如用于取决于在追踪域中表示的第一聚合值及取决于在追踪域中表示的第二聚 合值而判定噪声水平信息。
根据实施例,第一聚合单元可例如用于判定第一聚合值以使得第一聚合值指示第一音 频信号部分或自第一音频信号部分得到的信号的均方根。此外,第二聚合单元可例如用于 判定第二聚合值以使得第二聚合值指示第二音频信号部分或自第二音频信号部分得到的信 号的均方根。
在实施例中,变换单元可例如用于通过对自第二音频信号部分得到的值应用增益值而 将自第二音频信号部分得到的值自第二域变换至追踪域。
根据实施例,增益值可例如指示由线性预测编码合成引入的增益,或增益值可例如指 示由线性预测编码合成及去加重引入的增益。
在实施例中,噪声水平追踪单元可例如用于通过应用最小值统计方法判定噪声水平信 息。
根据实施例,噪声水平追踪单元可例如用于将舒缓噪声水平判定为噪声水平信息。重 建单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收 接口接收但被损毁的情况下,取决于噪声水平信息而重建第三音频信号部分。
在实施例中,噪声水平追踪单元可例如用于将舒缓噪声水平判定为自噪声水平频谱得 到的噪声水平信息,其中该噪声水平频谱是通过应用最小值统计方法而获得。重建单元可 例如用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收接口接收 但被损毁的情况下,取决于多个线性预测系数而重建第三音频信号部分。
根据另一实施例,噪声水平追踪单元可例如用于将指示舒缓噪声水平的多个线性预测 系数判定作为噪声水平信息,且重建单元可例如用于取决于多个线性预测系数而重建第三 音频信号部分。
在实施例中,噪声水平追踪单元用于将指示舒缓噪声水平的多个FFT系数判定作为噪 声水平信息,且第一重建单元用于在多个帧中的该第三帧不由接收接口接收的情况下或在 该第三帧由接收接口接收但被损毁的情况下,取决于自这些FFT系数得到的舒缓噪声水平 而重建第三音频信号部分。
在实施例中,重建单元可例如用于在多个帧中的该第三帧不由接收接口接收的情况下 或在该第三帧由接收接口接收但被损毁的情况下,取决于噪声水平信息及取决于第一音频 信号部分而重建第三音频信号部分。
根据实施例,重建单元可例如用于通过减小或放大自第一或第二音频信号部分得到的 信号来重建第三音频信号部分。
在实施例中,装置可例如进一步包含长期预测单元,该长期预测单元包含延迟缓冲器。 此外,长期预测单元可例如用于取决于第一或第二音频信号部分、取决于储存于延迟缓冲 器中的延迟缓冲器输入及取决于长期预测增益而产生被处理信号。此外,长期预测单元可 例如用于在多个帧中的该第三帧不由接收接口接收的情况下或在该第三帧由接收接口接收 但被损毁的情况下,使长期预测增益朝向零衰落。
根据实施例,长期预测单元可例如用于使长期预测增益朝向零衰落,其中长期预测增 益衰落至零的速度取决于衰落因子。
在实施例中,长期预测单元可例如用于在多个帧中的该第三帧不由接收接口接收的情 况下或在该第三帧由接收接口接收但被损毁的情况下,通过将产生的被处理信号储存于延 迟缓冲器中来更新延迟缓冲器输入。
根据实施例,变换单元可例如为第一变换单元,及重建单元为第一重建单元。装置进一 步包含第二变换单元及第二重建单元。第二变换单元可例如用于在多个帧中的第四帧不由 接收接口接收的情况下或在该第四帧由接收接口接收但被损毁的情况下,将噪声水平信息 自追踪域变换至第二域。此外,第二重建单元可例如用于在多个帧中的该第四帧不由接收 接口接收的情况下或在该第四帧由接收接口接收但被损毁的情况下,取决于在第二域中表 示的噪声水平信息而重建音频信号的第四音频信号部分。
在实施例中,第二重建单元可例如用于取决于噪声水平信息及取决于第二音频信号部 分重建第四音频信号部分。
根据实施例,第二重建单元可例如用于通过减小或放大自第一或第二音频信号部分得 到的信号来重建第四音频信号部分。
此外,提供用于解码音频信号的方法。
该方法包括:
-接收多个帧中的第一帧,该第一帧包含音频信号的第一音频信号部分,该第一音频 信号部分被表示于第一域中。
-接收多个帧中的第二帧,该第二帧包含音频信号的第二音频信号部分。
-将第二音频信号部分或自第二音频信号部分得到的值或信号自第二域变换至追踪 域以获得第二信号部分信息,其中第二域不同于第一域,其中追踪域不同于第二域,且其 中追踪域等于或不同于第一域。
-取决于在追踪域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号 部分信息而判定噪声水平信息,其中第一信号部分信息取决于第一音频信号部分。及:
-在多个帧中的第三帧不被接收的情况下或在该第三帧被接收但被损毁的情况下,取 决于在追踪域中表示的噪声水平信息而重建音频信号的第三音频信号部分。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程 序。
本发明的实施例中的一些提供时间变化平滑参数,以使得经平滑化周期图的跟踪能力 及其方差受到较好地平衡,以开发用于偏差补偿的算法及大体上加速噪声跟踪。
本发明的实施例是基于如下发现,关于衰落,关注以下参数:衰落域;衰落速度,或更 一般地,衰落曲线;衰落的目标水平;衰落的目标频谱形状;及/或背景噪声水平追踪。在 此上下文中,实施例是基于现有技术具有显著缺点的发现。
提供针对切换式音频编码系统的在错误隐藏过程中的改善信号衰落的装置及方法。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程 序。
实施例实现衰落至舒缓噪声水平。根据实施例,实现在激发域中的共同舒缓噪声水平 追踪。不管所使用的核心编码器(ACELP/TCX)如何,在突发封包丢失的过程中被设定为目 标的舒缓噪声水平将是相同的,且该舒缓噪声水平将总是最新的。共同噪声水平追踪是必 要的,还不存在该现有技术。实施例提供切换式编码解码器在突发封包丢失的过程中至类 似舒缓噪声的信号的衰落。
此外,实施例实现了总复杂性与具有两个独立噪声水平追踪模块的情况相比将较低, 因为可共享功能(PROM)及内存。
在实施例中,在语音起作用的过程中,激发域中的水平得到(与时域中的水平得到相比 较)提供更多的最小值,因为语音信息的部分由LP系数涵盖。
在ACELP的状况下,根据实施例,水平得到发生于激发域中。在TCX的状况下,在实 施例中,在时域中得到水平,且作为校正因子应用LPC合成及去加重的增益,以便模型化 激发域中的能量水平。追踪激发域中的水平(例如在FDNS之前)理论上亦将为可能的,但 TCX激发域与ACELP激发域之间的水平补偿被认为是相当复杂的。
现有技术并未并有在不同域中的这种共同背景水平追踪。现有技术并不具有在切换式 编码解码器系统中的例如在激发域中的这种共同舒缓噪声水平追踪。因此,实施例相比于 现有技术是有利的,因为对于现有技术,在突发封包丢失的过程中被设定为目标的舒缓噪 声水平可取决于水平受到追踪的先前编码模式(ACELP/TCX)而不同;因为在现有技术中, 针对每一编码模式为单独的追踪将导致不必要的附加项及额外计算复杂性;及因为在现有 技术中,最新舒缓噪声水平在任一核心中归因于最近切换至此核心可能并不可用。
根据一些实施例,在激发域中进行水平追踪,但在时域中进行TCX衰落。通过时域中 的衰落,避免TDAC的失效,这些失效将导致频迭。当隐藏音调信号分量时,此情形变得备 受关注。此外,避免ACELP激发域与MDCT频谱域之间的水平转换,且因此例如节省了计算 资源。由于激发域与时域之间的切换,在激发域与时域之间需要水平调整。通过得到将由 LPC合成及预强调引入的增益及使用此增益作为校正因子来使水平在两个域之间转换来解 决此情形。
相比之下,现有技术并不进行在激发域中的水平追踪及在时域中的TCX衰落。关于目 前先进技术的基于变换的编码解码器,在激发域(针对时域/类似ACELP隐藏方法,参见 [3GP09a])中抑或在频域(针对如帧重复或噪声替换的频域方法,参见[LS01])中应用衰减 因子。在频域中应用衰减因子的现有技术的方法的缺点为在时域中的重迭相加区中将导致 频迭。对于被应用不同衰减因子的邻近帧将出现此状况,因为衰落程序使TDAC(时域频迭 消除)失效。此在隐藏音调信号分量时尤其相关。上文所提及的实施例因此相比于现有技 术是有利的。
实施例补偿高通滤波器对LPC合成增益的影响。根据实施例,为了补偿由经高通滤波 无声激发引起的LPC分析及强调的非吾人所乐见的增益改变,得到校正因子。此校正因子 考虑此非吾人所乐见的增益改变,且修改激发域中的目标舒缓噪声水平以使得在时域中达 到正确目标水平。
相比之下,若未将最后良好帧的信号分类为无声,则例如G.718[ITU08a]的现有技术将 高通滤波器引入至无声激发的信号路径中,如图2中所描绘。由此,现有技术导致非吾人 所乐见的副效应,因为后续LPC合成的增益取决于由该高通滤波器更改的信号特性。因为 在激发域中追踪及应用背景水平,所以算法依赖于LPC合成增益,LPC合成增益又再次取 决于激发信号的特性。换言之,如由现有技术所进行的,归因于高通滤波的激发的信号特 性的修改可产生LPC合成的修改(通常减少的)增益。此情形导致错误的输出水平,即使 激发水平是正确的。
实施例克服现有技术的这些缺点。
特别地,实施例实现舒缓噪声的适应性频谱形状。与G.718相对比,通过追踪背景噪 声的频谱形状及通过在突发封包丢失的过程中应用(衰落至)此形状,先前背景噪声的噪 声特性将为匹配的,导致舒缓噪声的合意的噪声特性。此情形避免可通过使用频谱包络引 入的频谱形状的突兀的错配,该频谱包络是由脱机训练及/或最后接收的帧的频谱形状得到。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的装置。装置包括用于 接收一个或多个帧的接收接口、系数产生器及信号重建器。系数产生器用于在一个或多个 帧中的当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下, 判定由当前帧包含的一个或多个第一音频信号系数,其中该一个或多个第一音频信号系数 指示编码音频信号的特性,及判定指示编码音频信号的背景噪声的一个或多个噪声系数。 此外,系数产生器用于在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧 被损毁的情况下,取决于一个或多个第一音频信号系数及取决于一个或多个噪声系数而产 生一个或多个第二音频信号系数。音频信号重建器用于在当前帧由接收接口接收的情况下 及在由接收接口接收的当前帧未被损毁的情况下取决于一个或多个第一音频信号系数而重 建重建音频信号的第一部分。此外,音频信号重建器用于在当前帧不由接收接口接收的情 况下或在由接收接口接收的当前帧被损毁的情况下,取决于一个或多个第二音频信号系数 而重建重建音频信号的第二部分。
在一些实施例中,一个或多个第一音频信号系数可例如为编码音频信号的一个或多个 线性预测滤波器系数。在一些实施例中,一个或多个第一音频信号系数可例如为编码音频 信号的一个或多个线性预测滤波器系数。
根据实施例,一个或多个噪声系数可例如为指示编码音频信号的背景噪声的一个或多 个线性预测滤波器系数。在实施例中,一个或多个线性预测滤波器系数可例如表示背景噪 声的频谱形状。
在实施例中,系数产生器可例如用于判定一个或多个第二音频信号部分以使得一个或 多个第二音频信号部分为重建音频信号的一个或多个线性预测滤波器系数,或使得一个或 多个第一音频信号系数为重建音频信号的一个或多个导抗频谱对。
根据实施例,系数产生器可例如用于通过应用如下公式而产生一个或多个第二音频信 号系数:
fcurrent[i]=α·flast[i]+(1-α)·ptmean[i]
其中fcurrent[i]指示-个或多个第二音频信号系数中的一个,其中flast[i]指示一个或多个第一 音频信号系数中的一个,其中ptmean[i]为一个或多个噪声系数中的一个,其中α为实数,其 中0≤α≤1,且其中i为索引。在实施例中,0<α<1。
根据实施例,flast[i]指示编码音频信号的线性预测滤波器系数,且其中fcurrent[i]指示重建 音频信号的线性预测滤波器系数。
在实施例中,ptmean[i]可例如指示编码音频信号的背景噪声。
在实施例中,系数产生器可例如用于在一个或多个帧中的当前帧由接收接口接收的情 况下及在由接收接口接收的当前帧未被损毁的情况下,通过判定编码音频信号的噪声频谱 来判定一个或多个噪声系数。
根据实施例,系数产生器可例如用于通过对信号频谱使用最小值统计方法来判定背景 噪声频谱及通过自背景噪声频谱计算表示背景噪声形状的LPC系数来判定表示背景噪声的 LPC系数。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的方法。该方法包括:
-接收一个或多个帧。
-在一个或多个帧中的当前帧被接收的情况下及在所接收的当前帧未被损毁的情况 下,判定由当前帧所包含一个或多个第一音频信号系数,其中该一个或多个第一音频信号 系数指示编码音频信号的特性,及判定指示编码音频信号的背景噪声的一个或多个噪声系 数。
-在当前帧未被接收的情况下或在所接收的当前帧被损毁的情况下,取决于一个或多 个第一音频信号系数及取决于一个或多个噪声系数而产生一个或多个第二音频信号系数。
-在当前帧被接收的情况下及在所接收的当前帧未被损毁的情况下,取决于一个或多 个第一音频信号系数而重建重建音频信号的第一部分。及:
-在当前帧未被接收的情况下或在所接收的当前帧被损毁的情况,取决于一个或多个 第二音频信号系数重建重建音频信号的第二部分。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程 序。
具有在衰落的过程中追踪及应用舒缓噪声的频谱形状的共同手段具有若干优点。通过 追踪及应用频谱形状以使得频谱形状对于两个核心编码解码器而言可类似地实现,允许了 简单的共同方法。CELT仅教示频谱域中的能量的逐频带追踪及频谱域中的频谱形状的逐频 带形成,此对于CELP核心而言是不可能的。
相比之下,在现有技术中,在突发丢失的过程中引入的舒缓噪声的频谱形状是完全静 态的抑或部分静态的且部分适应于频谱形状的短期均值(如G.718中所实现[ITU08a]),且 通常将与在封包丢失之前在信号中的背景噪声不匹配。舒缓噪声特性的此错配可能造成麻 烦。根据现有技术,可使用经脱机训练的(静态)背景噪声形状,其针对特定信号而言可听 起来是合意的,但针对其他信号而言不太合意,例如,汽车噪声听起来与办公室噪声完全 不同。
此外,在现有技术中,可使用对先前接收的帧的频谱形状的短期均值的调适,其可能使 信号特性更接近于之前接收的信号,但不一定更接近于背景噪声特性。在现有技术中,在 频谱域中逐频带地追踪频谱形状(如CELT[IET12]中所实现)并不适用于不仅使用基于MDCT 域的核心(TCX)而且使用基于ACELP的核心的切换式编码解码器。上文所提及的实施例因 此相比于现有技术是有利的。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的装置。装置包含用于 接收包含关于编码音频信号的音频信号频谱的多个音频信号样本的信息的一个或多个帧的 接收接口,及用于产生重建音频信号的处理器。处理器用于,在当前帧不由接收接口接收 的情况下或在当前帧由接收接口接收但被损毁的情况下,通过将修改的频谱衰落至目标频 谱来产生重建音频信号,其中修改的频谱包含多个修改的信号样本,其中对于修改的频谱 的每个修改的信号样本,该修改的信号样本的绝对值等于音频信号频谱的音频信号样本中 一个的绝对值。此外,处理器用于,在一个或多个帧中的当前帧由接收接口接收的情况下 以及由接收接口接收的当前帧未被损毁的情况下,不将修改的频谱衰减至目标频谱。
根据实施例,目标频谱可例如为类似噪声的频谱。
在实施例中,类似噪声的频谱可例如表示白噪声。
根据实施例,类似噪声的频谱可例如被成形。
在实施例中,类似噪声的频谱的形状可例如取决于先前接收的信号的音频信号频谱。
根据实施例,类似噪声的频谱可例如取决于音频信号频谱的形状而成形。
在实施例中,处理器可例如使用倾斜因子来使类似噪声的频谱成形。
根据实施例,处理器可例如使用如下公式:
shaped_noise[i]=noise*power(tilt_factor,i/N)
其中N指示样本的数目,其中i为索引,其中0<=i<N,其中tilt_factor>0,且 其中power为功率函数。
power(x,y)指示xy
power(tilt_factor,i/N)指示
若tilt_factor小于1,则此情形意味在i增加的情况下的衰减。若tilt_factor大于 1,则意味在i增加的情况下的放大。
根据另一实施例,处理器可例如使用如下公式:
shaped_noise[i]=noise*(1+i/(N-1)*(tilt_factor-1))
其中N指示样本的数目,其中i为索引,其中0<=i<N,其中tilt_factor>0。
若tilt_factor小于1,则此情形意味在i增加的情况下的衰减。若tilt_factor大于 1,则意味在i增加的情况下的放大。
根据实施例,处理器可例如用于,在当前帧不由接收接口接收的情况下或在由接收接 口接收的当前帧被损毁的情况下,通过改变音频信号频谱的音频信号样本中的一个或多个 的符号来产生修改的频谱。
在实施例中,音频信号频谱的音频信号样本中的每一个可例如由实数表示,但不由虚 数表示。
根据实施例,音频信号频谱的音频信号样本可例如被表示在修改的离散余弦变换域中。
在另一实施例中,音频信号频谱的音频信号样本可例如被表示在修改的离散正弦变换 域中。
根据实施例,处理器可例如用于通过使用随机或伪随机输出第一值或第二值的随机符 号函数产生修改的频谱。
在实施例中,处理器可例如用于通过随后减小衰减因子而将修改的频谱衰落至目标频 谱。
根据实施例,处理器可例如用于通过随后增加衰减因子而将修改的频谱衰落至目标频 谱。
在实施例中,在当前帧不由接收接口接收的情况下或在由接收接口接收的当前帧被损 毁的情况下,处理器可例如用于通过使用如下公式产生重建音频信号:
x[i]=(1-cum_damping)*noise[i]+cum_damping*random_sign()*x_old[i] 其中i为索引,其中x[i]指示重建音频信号的样本,其中cum_damping为衰减因子,其中x_old[i]指示编码音频信号的音频信号频谱的音频信号样本中的一个,其中random_sign ()返回1或-1,且其中noise为指示目标频谱的随机向量。
在实施例中,该随机向量noise可例如被按比例调整以使得其二次均值类似于由接收 接口最后所接收的帧中的一个帧所包含的编码音频信号的频谱的二次均值。
根据一般实施例,处理器可例如用于通过使用随机向量产生重建音频信号,该随机向 量被按比例调整以使得其二次均值类似于由接收接口最后所接收的帧中的一个帧所包含的 编码音频信号的频谱的二次均值。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的方法。该方法包括:
-接收包括关于编码音频信号的音频信号频谱的多个音频信号样本的信息的一个或 多个帧。及:
-产生重建音频信号。
在当前帧未被接收的情况下或在当前帧被接收但被损毁的情况下,通过将修改的频谱 衰落至目标频谱进行产生重建音频信号,其中修改的频谱包含多个修改的信号样本,其中 对于修改的频谱的每个修改的信号样本,该修改的信号样本的绝对值等于音频信号频谱的 音频信号样本中的一个的绝对值。在一个或多个帧中的当前帧被接收的情况下及在所接收 的当前帧未被损毁的情况下,不将修改的频谱衰落至白噪声频谱。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程 序。
实施例实现在FDNS应用(FDNS=频域噪声替换)之前使MDCT频谱衰落至白噪声。
根据现有技术,在基于ACELP的编码解码器中,用随机向量(例如,用噪声)来代替创 新码簿。在实施例中,对TCX解码器结构采用由用随机向量(例如,用噪声)代替创新码 簿构成的ACELP方法。此处,创新码簿的等效物为通常在比特串流内被接收且被反馈至FDNS 中的MDCT频谱。
经典MDCT隐藏方法将为简单地照原样重复此频谱或应用某一随机化程序,该随机化程 序基本上延长最后接收的帧的频谱形状[LS01]。此情形的缺点是延长了短期的频谱形状, 从而频繁地导致反复的金属声音,该声音并不类似背景噪声,且因此无法被用作舒缓噪声。
使用所提出的方法,通过FDNS及TCX LTP执行短期频谱成形,仅通过FDNS执行长期 频谱成形。由FDNS进行的成形自短期频谱形状衰落至背景噪声的追踪的长期频谱形状,且 将TCX LTP衰落至零。
将FDNS系数衰落至追踪的背景噪声系数,导致在最后良好频谱包络与长远来看应被设 定为目标的频谱背景包络之间具有平滑转变,以便在长突发帧丢失的状况下达成合意的背 景噪声。
相比之下,根据现有技术的状态,对于基于变换的编码解码器,通过频域中的帧重复或 噪声替换来进行类似噪声的隐藏[LS01]。在现有技术中,噪声替换通常由频谱仓的符号加 扰来执行。若在隐藏的过程中使用现有技术TCX(频域)符号加扰,则再次使用最后接收的 MDCT系数,且在频谱被反向变换至时域之前使每一符号随机化。现有技术的此程序的缺点 为对于连续丢失的帧,一次又一次地使用相同频谱,其仅仅是具有不同的符号随机化及全 局衰减。当在粗时间网格上查看随时间的流逝的频谱包络时,可以看见包络在连续帧丢失 的过程中大约为恒定的,因为频带能量在帧内相对于彼此保持恒定,且仅全局地衰减。在 所使用的编码系统中,根据现有技术,使用FDNS来处理频谱值,以便恢复原始频谱。此意 味在想要将MDCT频谱衰落至某一频谱包络(使用例如描述当前背景噪声的FDNS系数)的 情况下,结果不仅取决于FDNS系数,而且取决于被符号加扰的先前解码的频谱。上文所提 及的实施例克服现有技术的这些缺点。
实施例是基于有必要在将频谱反馈至FDNS处理之前将用于符号加扰的频谱衰落至白 噪声的发现。否则,输出的频谱将决不匹配用于FDNS处理的目标包络。
在实施例中,对于LTP增益衰落使用与白噪声衰落相同的衰落速度。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的装置。装置包括用于 接收多个帧的接收接口、用于储存解码音频信号的音频信号样本的延迟缓冲器、用于自储 存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本的样本选择器,及用于处理 选定音频信号样本以获得重建音频信号的重建音频信号样本的样本处理器。样本选择器用 于在当前帧由接收接口接收的情况下及在由接收接口接收的当前帧未被损毁的情况下,取 决于由当前帧所包含的音高滞后信息自储存于延迟缓冲器中的音频信号样本选择多个选定 音频信号样本。此外,样本选择器用于在当前帧不由接收接口接收的情况下或在由接收接 口接收的当前帧被损毁的情况下,取决于由先前由接收接口所接收的另一帧所包含的音高 滞后信息自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本。
根据实施例,样本处理器可例如用于在当前帧由接收接口接收的情况下及在由接收接 口接收的当前帧未被损毁的情况下,通过取决于由当前帧所包含的增益信息重新按比例调 整选定音频信号样本而获得重建音频信号样本。此外,样本选择器可例如用于在当前帧不 由接收接口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,通过取决于由先 前由接收接口所接收的该另一帧所包含的增益信息重新按比例调整选定音频信号样本而获 得重建音频信号样本。
在实施例中,样本处理器可例如用于在当前帧由接收接口接收的情况下及在由接收接 口接收的当前帧未被损毁的情况下,通过将选定音频信号样本与取决于由当前帧所包含的 增益信息的值相乘而获得重建音频信号样本。此外,样本选择器用于在当前帧不由接收接 口接收的情况下或在由接收接口接收的当前帧被损毁的情况下,通过将选定音频信号样本 与取决于由先前由接收接口所接收的该另一帧所包含的增益信息的值相乘而获得重建音频 信号样本。
根据实施例,样本处理器可例如用于将重建音频信号样本储存于延迟缓冲器中。
在实施例中,样本处理器可例如用于在由接收接口接收另一帧之前将重建音频信号样 本储存于延迟缓冲器中。
根据实施例,样本处理器可例如用于在由接收接口接收另一帧之后将重建音频信号样 本储存于延迟缓冲器中。
在实施例中,样本处理器可例如用于取决于增益信息重新按比例调整选定音频信号样 本以获得重新按比例调整的音频信号样本及通过组合重新按比例调整的音频信号样本与输 入音频信号样本以获得处理音频信号样本。
根据实施例,样本处理器可例如用于在当前帧由接收接口接收的情况下及在由接收接 口接收的当前帧未被损毁的情况下,将指示重新按比例调整的音频信号样本与输入音频信 号样本的组合的处理音频信号样本储存于延迟缓冲器中,且不将重新按比例调整的音频信 号样本储存于延迟缓冲器中。此外,样本处理器用于在当前帧不由接收接口接收的情况下 或在由接收接口接收的当前帧被损毁的情况下,将重新按比例调整的音频信号样本储存于 延迟缓冲器中且不将处理音频信号样本储存于延迟缓冲器中。
根据另一实施例,样本处理器可例如用于在当前帧不由接收接口接收的情况下或在由 接收接口接收的当前帧被损毁的情况下,将处理音频信号样本储存于延迟缓冲器中。
在实施例中,样本选择器可例如用于通过取决于修改的增益重新按比例调整选定音频 信号样本而获得重建音频信号样本,其中修改的增益系根据如下公式来定义的:
gain=gain_past*damping;
其中gain为修改的增益,其中样本选择器可例如用于在gain已被计算之后将gain_past 设定为gain,且其中damping为实值。
根据实施例,样本选择器可例如用于计算修改的增益。
在实施例中,damping可例如根据下式来定义:0≤damping≤1。
根据实施例,在自上一次帧由接收接口接收以来至少预定义数目的帧尚未由接收接口 接收的情况下,修改的增益gain可例如被设定为零。
此外,提供用于对编码音频信号进行解码以获得重建音频信号的方法。该方法包括:
-接收多个帧。
-储存解码音频信号的音频信号样本。
-自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号样本。及:
-处理选定音频信号样本以获得重建音频信号的重建音频信号样本。
在当前帧被接收的情况下及在所接收的当前帧未被损毁的情况下,取决于由当前帧所 包含的音高滞后信息而进行自储存于延迟缓冲器中的音频信号样本选择多个选定音频信号 样本的步骤。此外,在当前帧未被接收的情况下或在所接收的当前帧被损毁的情况下,取 决于由先前由接收接口所接收的另一帧所包含的音高滞后信息而进行自储存于延迟缓冲器 中的音频信号样本选择多个选定音频信号样本的步骤。
此外,提供用于在执行于计算机或信号处理器上时实施上文所描述的方法的计算机程 序。
实施例使用TCX LTP(TXC LTP=经变换编码激发长期预测)。在正常操作的过程中,用 合成的信号更新TCX LTP内存,该合成的信号含有噪声及重建音调分量。
代替在隐藏的过程中停用TCX LTP,可在隐藏的过程中以在最后良好帧中接收的参数 继续其正常操作。此保留信号的频谱形状,特别地,由LTP滤波器模型化的那些音调分量。
此外,实施例解耦TCX LTP反馈回路。正常TCX LTP操作的简单继续会引入额外噪声, 因为随着每一更新步骤都会引入来自LTP激发的其他随机产生的噪声。音调分量因此随时 间的流逝因添加的噪声而愈来愈失真。
为了克服此情形,可仅反馈更新的TCX LTP缓冲器(在不添加噪声的情况下),以便不 会以不合需要的随机噪声污染音调信息。
此外,根据实施例,将TCX LTP增益衰落至零。
这些实施例是基于如下发现:继续TCX LTP有助于短期地保留信号特性,但就长期而 言具有以下缺点:在隐藏的过程中播出的信号将包括在丢失之前存在的发声/音调信息。尤 其对于干净的语音或有背景噪声的语音,音调或谐波极不可能在极长的时间内极慢地衰减。 通过在隐藏的过程中继续TCX LTP操作,特别地在解耦LTP内存更新(仅反馈音调分量而 不反馈符号加扰部分)的情况下,发声/音调信息将在整个丢失之内保持存在于隐藏的信号 中,仅通过整体衰落至舒缓噪声水平而衰减。此外,在突发丢失的过程中应用TCX LTP而 不随时间的流逝衰减的情况下,不可能在突发封包丢失的过程中达到舒缓噪声包络,因为 信号将接着总是并有LTP的发声信息。
因此,使TCX LTP增益朝向零衰落,以使得由LTP表示的音调分量将衰落至零,同时 信号衰落至背景信号水平及形状,且使得衰落达到所要的频谱背景包络(舒缓噪声)而不 并有不合需要的音调分量。
在实施例中,对于LTP增益衰落使用与白噪声衰落相同的衰落速度。
相比之下,在现有技术中,不存在在隐藏的过程中使用LTP的已知的变换编码解码器。 对于MPEG-4LTP[ISO09],现有技术中并不存在隐藏方法。利用LTP的现有技术的另一基 于MDCT的编码解码器为CELT,但此编码解码器针对前五个帧使用类似ACELP的隐藏,且 针对所有后续帧产生背景噪声,此举并不利用LTP。不使用TCX LTP的现有技术的缺点为 用LTP模型化的所有音调分量会突然消失。此外,在现有技术的基于ACELP的编码解码器 中,在隐藏的过程中延长LTP操作,且使适应性码簿的增益朝向零衰落。关于反馈回路操 作,现有技术使用两个方法:反馈整个激发,例如创新及适应性激发的总和(AMR-WB);抑 或仅反馈经更新的适应性激发,例如音调信号部分(G.718)。上文所提及的实施例克服现 有技术的缺点。
附图说明
在下文中,参考附图更详细地描述本发明的实施例,其中:
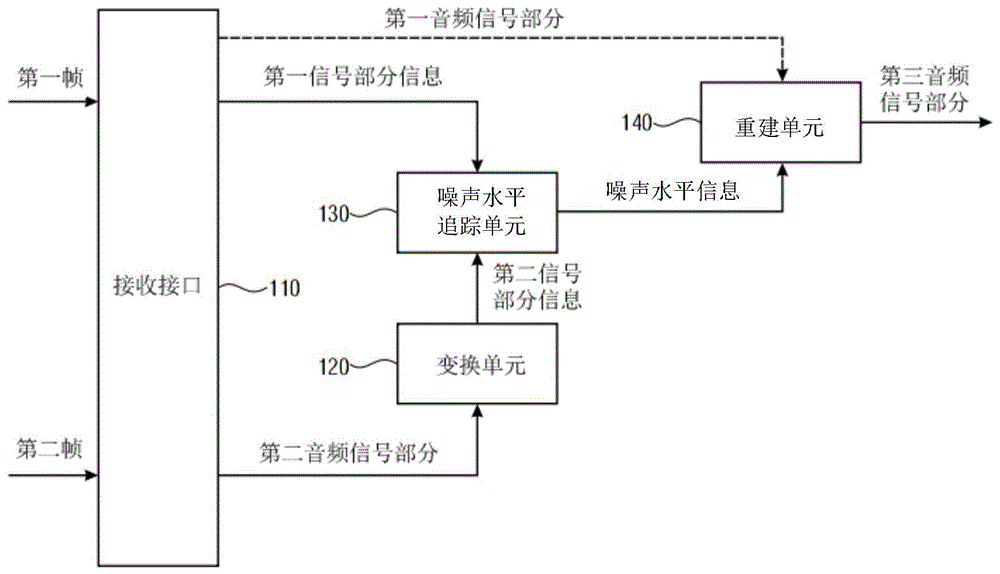
图1a说明根据实施例的用于对音频信号进行解码的装置;
图1b说明根据另一实施例的用于对音频信号进行解码的装置;
图1c说明根据另一实施例的用于对音频信号进行解码的装置,其中装置进一步包含第 一聚合单元及第二聚合单元;
图1d说明根据另一实施例的用于对音频信号进行解码的装置,其中装置更包含长期预 测单元,该长期预测单元包含延迟缓冲器;
图2说明G.718的解码器结构;
图3描绘G.722的衰落因子取决于类别信息的情境;
图4展示用于使用线性回归进行振幅预测的方法;
图5说明受约束的能量重迭变换(CELT)的突发丢失行为;
图6展示在无错误操作模式的过程中在解码器中的根据实施例的背景噪声水平追踪;
图7说明根据实施例的LPC合成及去加重的增益推导;
图8描绘根据实施例的在封包丢失的过程中的舒缓噪声水平应用;
图9说明根据实施例的在ACELP隐藏的过程中的进阶高通增益补偿;
图10描绘根据实施例的在隐藏的过程中的LTP反馈回路的解耦;
图11说明根据实施例的于对编码音频信号进行解码以获得重建音频信号的装置;
图12展示根据另一实施例的用于对编码音频信号进行解码以获得重建音频信号的装 置;及
图13说明另一实施例的用于对编码音频信号进行解码以获得重建音频信号的装置;及
图14说明另一实施例的用于对编码音频信号进行解码以获得重建音频信号的装置。
具体实施方式
图1a说明根据实施例的用于对音频信号进行解码的装置。
装置包含接收接口110。接收接口用于接收多个帧,其中接收接口110用于接收多个帧 中的第一帧,该第一帧包含音频信号的第一音频信号部分,该第一音频信号部分被表示于 第一域中。此外,接收接口110用于接收多个帧中的第二帧,该第二帧包含音频信号的第 二音频信号部分。
此外,装置包含变换单元120,该变换单元用于将第二音频信号部分或自第二音频信号 部分得到的值或信号自第二域变换至追踪域,以获得第二信号部分信息,其中第二域不同 于第一域,其中追踪域不同于第二域,且其中追踪域等于或不同于第一域。
此外,装置包含噪声水平追踪单元130,其中噪声水平追踪单元用于接收在追踪域中表 示的第一信号部分信息,其中第一信号部分信息取决于第一音频信号部分,其中噪声水平 追踪单元用于接收在追踪域中表示的第二信号部分,且其中噪声水平追踪单元用于取决于 在追踪域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号部分信息而判定 噪声水平信息。
此外,装置包含重建单元,该重建单元用于在多个帧中的第三帧不由接收接口接收而 是被损毁的情况下,取决于噪声水平信息而重建音频信号的第三音频信号部分。
关于第一及/或第二音频信号部分,例如第一及/或第二音频信号部分可例如被反馈至 一个或多个处理单元(未示出)中以用于产生用于一个或多个扬声器的一个或多个扬声器 信号,使得可重新播放由第一及/或第二音频信号部分包含的所接收的声音信息。
然而,此外,第一及第二音频信号部分亦用于隐藏,例如在后续帧并未到达接收器的状 况下或在彼后续帧不正确的状况下。
尤其,本发明是基于噪声水平追踪应在共同域(本文中被称作“追踪域”)中进行的发 现。追踪域可例如为激发域,例如由LPC(LPC=线性预测系数)或由ISP(ISP=导抗频谱对) 表示信号的域,如AMR-WB及AMR-WB+中所描述(参见[3GP12a]、[3GP12b]、[3GP09a]、 [3GP09b]、[3GP09c])。在单一域中追踪噪声水平尤其具有如下优点:当信号在第一域中的 第一表示与第二域中的第二表示之间切换时(例如,当信号表示自ACELP切换至TCX或自 TCX切换至ACELP时),避免了频迭效应。
关于变换单元120,所变换的是第二音频信号部分自身,或自第二音频信号部分得到的 信号(例如,已被处理第二音频信号部分以获得得到的信号),或自第二音频信号部分得到 的值(例如,已处理第二音频信号部分以获得得到的值)。
关于第一音频信号部分,在一些实施例中,第一音频信号部分可经处理及/或变换至追 踪域。
然而,在其他实施例中,第一音频信号部分可已经被表示于追踪域中。
在一些实施例中,第一信号部分信息等同于第一音频信号部分。在其他实施例中,第一 信号部分信息为例如取决于第一音频信号部分的聚合值。
现在,首先更详细地考虑至舒缓噪声水平的衰落。
所描述的衰落方法可例如实施于xHE-AAC[NMR+12]的低延迟版本(xHE-AAC=扩展高效 率AAC)中,该版本能够在逐帧的基础上在ACELP(语音)与MDCT(音乐/噪声)编码之间 顺畅地切换。
关于在追踪域(例如激发域)中的共同水平追踪,为了在封包丢失的过程中应用至适当 舒缓噪声水平的平滑衰落,需要在正常解码程序的过程中识别此舒缓噪声水平。可例如假 设类似于背景噪声的噪声水平大部分为舒缓的。因此,可在正常解码的过程中得到及连续 更新背景噪声水平。
本发明是基于以下发现:当具有切换式核心编码解码器(例如,ACELP及TCX)时,考 虑独立于所选择核心编码器的共同背景噪声水平为特别合适的。
图6描绘在无错误操作模式的过程中(例如在正常解码的过程中)在解码器中的根据 较佳实施例的背景噪声水平追踪。
追踪自身可例如使用最小值统计方法来执行(参见[Mar01])。
此被追踪的背景噪声水平可例如被认为是上文所提及的噪声水平信息。
举例而言,文献“Rainer Martin的Noise power spectral density estimation based on optimal smoothing and minimum statistics(基于优化光滑和最小值统计的噪声功 率谱密度估计)(IEEE Transactions on Speech and Audio Processing(语音处理及音 频处理)9(2001),第5期,第504至512页)”中呈现的最小值统计噪声估计[Mar01]可 用于背景噪声水平追踪。
相应地,在一些实施例中,噪声水平追踪单元130用于通过应用最小值统计方法(例 如通过使用[Mar01]的最小值统计噪声估计)来判定噪声水平信息。
随后,描述此追踪方法的一些考虑因素及细节。
关于水平追踪,背景应该为类似噪声的。因此较佳地执行在激发域中的水平追踪以避 免追踪由LPC取出的前景音调分量。举例而言,ACELP噪声填充亦可使用激发域中的背景 噪声水平。在激发域中进行追踪的情况下,对背景噪声水平的仅一个单次追踪可起到两个 用途,从而减小计算复杂性。在较佳实施例中,在ACELP激发域中执行追踪。
图7说明根据实施例的LPC合成及去加重的增益推导。
关于水平得到,水平得到可例如在时域中抑或在激发域中抑或在任何其他合适的域中 进行。在用于水平得到及水平追踪的域不同的情况下,可例如需要增益补偿。
在较佳实施例中,在激发域中执行用于ACELP的水平得到。因此,并不需要增益补偿。
对于TCX,可例如需要增益补偿以将得到的水平调整至ACELP激发域。
在较佳实施例中,用于TCX的水平得到在时域中发生。发现了用于此方法的易管理的 增益补偿:如图7中所示得到由LPC合成及去加重引入的增益,且将得到的水平除以此增 益。
或者,可在TCX激发域中执行用于TCX的水平得到。然而,TCX激发域与ACELP激发域 之间的增益补偿被认为太复杂。
因此返回到图1a,在一些实施例中,第一音频信号部分被表示于作为第一域的时域中。 变换单元120用于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的激发 域变换至为追踪域的时域。在这些实施例中,噪声水平追踪单元130用于接收在作为追踪 域的时域中表示的第一信号部分信息。此外,噪声水平追踪单元130用于接收在作为追踪 域的时域中表示的第二信号部分。
在其他实施例中,第一音频信号部分被表示于作为第一域的激发域中。变换单元120用 于将第二音频信号部分或自第二音频信号部分得到的值自为第二域的时域变换至为追踪域 的激发域。在这些实施例中,噪声水平追踪单元130用于接收在作为追踪域的激发域中表 示的第一信号部分信息。此外,噪声水平追踪单元130用于接收在作为追踪域的激发域中 表示的第二信号部分。
在实施例中,第一音频信号部分可例如被表示于作为第一域的激发域中,其中噪声水 平追踪单元130可例如用于接收第一信号部分信息,其中该第一信号部分信息被表示于为 追踪域的FFT域中,且其中该第一信号部分信息取决于在激发域中表示的该第一音频信号 部分,其中变换单元120可例如用于将第二音频信号部分或自第二音频信号部分得到的值 自为第二域的时域变换至为追踪域的FFT域,且其中噪声水平追踪单元130可例如用于接 收在FFT域中表示的第二音频信号部分。
图1b说明根据另一实施例的装置。在图1b中,图1a的变换单元120为第一变换单元 120,及图1a的重建单元140为第一重建单元140。装置进一步包含第二变换单元121及 第二重建单元141。
第二变换单元121用于在多个帧中的第四帧不由接收接口接收的情况下或在该第四帧 由接收接口接收但被损毁的情况下,将噪声水平信息自追踪域变换至第二域。
此外,第二重建单元141用于在多个帧中的该第四帧不由接收接口接收的情况下或在 该第四帧由接收接口接收但被损毁的情况下,取决于在第二域中表示的噪声水平信息而重 建音频信号的第四音频信号部分。
图1c说明根据另一实施例的用于对音频信号进行解码的装置。装置进一步包含用于取 决于第一音频信号部分而判定第一聚合值的第一聚合单元150。此外,图1c的装置进一步 包含用于取决于第二音频信号部分而将第二聚合值判定为自第二音频信号部分得到的值的 第二聚合单元160。在图1c的实施例中,噪声水平追踪单元130用于接收第一聚合值作为 在追踪域中表示的第一信号部分信息,其中噪声水平追踪单元130用于接收第二聚合值作 为在追踪域中表示的第二信号部分信息。噪声水平追踪单元130用于取决于在追踪域中表 示的第一聚合值及取决于在追踪域中表示的第二聚合值而判定噪声水平信息。
在实施例中,第一聚合单元150用于判定第一聚合值以使得第一聚合值指示第一音频 信号部分或自第一音频信号部分得到的信号的均方根。此外,第二聚合单元160用于判定 第二聚合值以使得第二聚合值指示第二音频信号部分或自第二音频信号部分得到的信号的 均方根。
图6说明根据另一实施例的用于对音频信号进行解码的装置。
在图6中,背景水平追踪单元630实施根据图1a的噪声水平追踪单元130。
此外,在图6中,RMS单元650(RMS=均方根)为第一聚合单元,且RMS单元660为第 二聚合单元。
根据一些实施例,图1a、图1b及图1c的(第一)变换单元120用于通过对自第二音 频信号部分得到的值应用增益值(x)(例如,通过将自第二音频信号部分得到的值除以增 益值(x))将自第二音频信号部分得到的值自第二域变换至追踪域。在其他实施例中,可 例如乘以增益值。
在一些实施例中,增益值(x)可例如指示由线性预测编码合成引入的增益,或增益值 (x)可例如指示由线性预测编码合成及去加重引入的增益。
在图6中,单元622提供指示由线性预测编码合成及去加重引入的增益的值(x)。单 元622接着将由第二聚合单元660提供的值(其为自第二音频信号部分得到的值)除以所 提供的增益值(x)(例如,通过除以x,抑或通过乘以值1/x)。因此,图6的包含单元621 及622的单元620实施图1a、图1b或图1c的第一变换单元。
图6的装置接收具有第一音频信号部分的第一帧,该第一音频信号部分为有声激发及/ 或无声激发且被表示于追踪域中(在图6中,(ACELP)LPC域)。将第一音频信号部分反馈 至LPC合成及去加重单元671中以进行处理,从而获得时域第一音频信号部分输出。此外, 将第一音频信号部分反馈至RMS模块650中以获得指示第一音频信号部分的均方根的第一 值。此第一值(第一RMS值)被表示于追踪域中。接着将在追踪域中表示的第一RMS值反 馈至噪声水平追踪单元630中。
此外,图6的装置接收具有第二音频信号部分的第二帧,该第二音频信号部分包含MDCT 频谱且被表示于MDCT域中。噪声填充由噪声填充模块681进行,频域噪声成形由频域噪声 成形模块682进行,至时域的变换由iMDCT/OLA模块683(OLA=重迭相加)进行,且长期预 测由长期预测单元684进行。长期预测单元可例如包含延迟缓冲器(图6中未图示)。
接着将自第二音频信号部分得到的信号反馈至RMS模块660中以获得第二值,该第二 值指示获得自第二音频信号部分得到的那个信号的均方根。此第二值(第二RMS值)仍被 表示于时域中。单元620接着将第二RMS值自时域变换至追踪域,此处追踪域为(ACELP) LPC域。接着将在追踪域中表示的第二RMS值反馈至噪声水平追踪单元630中。
在实施例中,在激发域中进行水平追踪,但在时域中进行TCX衰落。
尽管在正常解码的过程中追踪背景噪声水平,但背景噪声水平可例如在封包丢失的过 程中用作最后接收的信号平滑地逐水平衰落至的适当舒缓噪声水平的指示符。
得到用于追踪的水平及应用水平衰落大体而言为彼此独立的,且可在不同域中执行。 在较佳实施例中,在与水平得到相同的域中执行水平应用,从而导致相同的益处:对于ACELP 而言,不需要增益补偿,且对于TCX而言,需要关于水平得到的反增益补偿(参见图6)且 因此可使用相同增益得到,如由图7所说明。
在下文中,描述根据实施例的高通滤波器对LPC合成增益的影响的补偿。
图8概述此方法。特别地,图8说明在封包丢失的过程中的舒缓噪声水平应用。
在图8中,高通增益滤波器单元643、乘法单元644、衰落单元645、高通滤波器单元 646、衰落单元647及组合单元648一起形成第一重建单元。
此外,在图8中,背景水平供应单元631提供噪声水平信息。举例而言,背景水平供 应单元631可同样实施为图6的背景水平追踪单元630。
此外,在图8中,LPC合成及去加重增益单元649及乘法单元641一起用于第二变换单 元640。
此外,在图8中,衰落单元642表示第二重建单元。
在图8的实施例中,有声及无声激发被单独地衰落:有声激发衰落至零,但无声激发 朝向舒缓噪声水平衰落。图8此外描绘高通滤波器,其在除了当信号被分类为无声时之外 的所有状况下被引入至无声激发的信号链中以抑制低频分量。
为了将高通滤波器的影响模型化,将在LPC合成及去加重之后的水平在有高通滤波器 的情况下计算一次,且在无高通滤波器的情况下计算一次。随后,得到那些两个水平之比 且将其用以更改所应用的背景水平。
此情形由图9说明。特别地,图9描绘根据实施例的在ACELP隐藏的过程中的进阶高 通增益补偿。
代替当前激发信号,仅将简单脉冲用作此计算的输入。这允许复杂性减少,因为脉冲响 应快速衰减,且因此可在较短时间范围内执行RMS得到。实际上,使用仅一个子帧而非整 个帧。
根据实施例,噪声水平追踪单元130用于将舒缓噪声水平判定为噪声水平信息。重建 单元140用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三帧由接收 接口110接收但被损毁的情况下,取决于噪声水平信息而重建第三音频信号部分。
根据实施例,噪声水平追踪单元130用于将舒缓噪声水平判定为噪声水平信息。重建 单元140用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三帧由接收 接口110接收但被损毁的情况下,取决于噪声水平信息而重建第三音频信号部分。
在实施例中,噪声水平追踪单元130用于将舒缓噪声水平判定为自噪声水平频谱得到 的噪声水平信息,其中该噪声水平频谱系通过应用最小值统计方法而获得的。重建单元140 用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三帧由接收接口110 接收但被损毁的情况下,取决于多个线性预测系数而重建第三音频信号部分。
在实施例中,(第一及/或第二)重建单元140、141可例如用于在多个帧中的该第三(第 四)帧不由接收接口110接收的情况下或在该第三(第四)帧由接收接口110接收但被损 毁的情况下,取决于噪声水平信息及取决于第一音频信号部分而重建第三音频信号部分。
根据实施例,(第一及/或第二)重建单元140、141可例如用于通过减小或放大第一音 频信号部分来重建第三(或第四)音频信号部分。
图14说明用于对音频信号进行解码的装置。装置包含接收接口110,其中接收接口110 用于接收包含音频信号的第一音频信号部分的第一帧,且其中接收接口110用于接收包含 音频信号的第二音频信号部分的第二帧。
此外,装置包含噪声水平追踪单元130,其中噪声水平追踪单元130用于取决于第一音 频信号部分及第二音频信号部分中的至少一个(此意味:取决于第一音频信号部分及/或第 二音频信号部分)判定噪声水平信息,其中噪声水平信息被表示于追踪域中。
此外,装置包含第一重建单元140,该第一重建单元用于在多个帧中的第三帧不由接收 接口110接收的情况下或在该第三帧由接收接口110接收但被损毁的情况下,取决于噪声 水平信息而在第一重建域中重建音频信号的第三音频信号部分,其中第一重建域不同于或 等于追踪域。
此外,装置包含变换单元121,该变换单元用于在多个帧中的第四帧不由接收接口110 接收的情况下或在该第四帧由接收接口110接收但被损毁的情况下,将噪声水平信息自追 踪域变换至第二重建域,其中第二重建域不同于追踪域,且其中第二重建域不同于第一重 建域,及
此外,装置包含第二重建单元141,该第二重建单元用于在多个帧中的该第四帧不由接 收接口110接收的情况下或在该第四帧由接收接口110接收但被损毁的情况下,取决于在 第二重建域中表示的噪声水平信息而在第二重建域中重建音频信号的第四音频信号部分。
根据一些实施例,追踪域可例如其中追踪域为时域、频谱域、FFT域、MDCT域或激发 域。第一重建域可例如为时域、频谱域、FFT域、MDCT域或激发域。第二重建域可例如为 时域、频谱域、FFT域、MDCT域或激发域。
在实施例中,追踪域可例如为FFT域,第一重建域可例如为时域,及第二重建域可例 如为激发域。
在另一实施例中,追踪域可例如为时域,第一重建域可例如为时域,及第二重建域可例 如为激发域。
根据实施例,该第一音频信号部分可例如被表示于第一输入域中,及该第二音频信号 部分可例如被表示于第二输入域中。变换单元可例如为第二变换单元。装置可例如进一步 包含用于将第二音频信号部分或自第二音频信号部分得到的值或信号自第二输入域变换至 追踪域以获得第二信号部分信息的第一变换单元。噪声水平追踪单元可例如用于接收在追 踪域中表示的第一信号部分信息,其中第一信号部分信息取决于第一音频信号部分,其中 噪声水平追踪单元用于接收在追踪域中表示的第二信号部分,且其中噪声水平追踪单元用 于取决于在追踪域中表示的第一信号部分信息及取决于在追踪域中表示的第二信号部分信 息判定噪声水平信息。
根据实施例,第一输入域可例如为激发域,及第二输入域可例如为MDCT域。
在另一实施例中,第一输入域可例如为MDCT域,且其中第二输入域可例如为MDCT域。
在例如在时域中表示信号的情况下,信号可例如由信号的时域样本表示。或例如,在频 谱域中表示信号的情况下,信号可例如由信号的频谱的频谱样本表示。
在实施例中,追踪域可例如为FFT域,第一重建域可例如为时域,及第二重建域可例 如为激发域。
在另一实施例中,追踪域可例如为时域,第一重建域可例如为时域,及第二重建域可例 如为激发域。
在一些实施例中,图14中所说明的单元可例如按针对图1a、图1b、图1c及图1d所 描述的配置。
关于特别的实施例,在例如低速率模式中,根据实施例的装置可例如接收ACELP帧作 为输入,这些ACELP帧被表示于激发域中且接着经由LPC合成变换至时域。此外,在低速 率模式中,根据实施例的装置可例如接收TCX帧作为输入,这些TCX帧被表示于MDCT域 中,且接着经由反MDCT而变换至时域。
接着在FFT域中进行追踪,其中通过进行FFT(快速傅立叶变换)自时域信号得到FFT 信号。可例如通过对于所有频谱线分开进行最小值统计方法来进行追踪以获得舒缓噪声频 谱。
接着通过基于舒缓噪声频谱进行水平得到来进行隐藏。基于舒缓噪声频谱进行水平得 到。对于FD TCX PLC进行至时域中的水平转换。进行在时域中的衰落。针对ACELP PLC及 针对TD TCX PLC(类似ACELP)进行至激发域中的水平得到。接着进行在激发域中的衰落。
以下清单概述此情形:
低速率:
●输入:
○acelp(激发域->时域,经由lpc合成)
○tcx(mdct域->时域,经由反MDCT)
●追踪:
○fft域,经由FFT自时域得到
○最小值统计,对于所有频谱线分开进行->舒缓噪声频谱
●隐藏:
○基于舒缓噪声频谱的水平得到
○对于以下PLC水平转换至时域中
■FD TCX PLC->在时域中衰落
○对于以下PLC水平转换至激发域中
■ACELP PLC
■TD TCX PLC(类似ACELP)->在激发域中衰落
在例如高速率模式中,其可例如接收TCX帧作为输入,这些TCX帧被表示于MDCT域 中,且接着经由反MDCT而变换至时域。
接着可在时域中进行追踪。可例如通过基于能量水平进行最小值统计方法来进行追踪 以获得舒缓噪声水平。
对于隐藏,对于FD TCX PLC而言,水平可被照原样使用,且可仅进行时域中的衰落。 对于TD TCX PLC(类似ACELP),进行至激发域的水平转换及在激发域中的衰落。
以下清单概述此情形:
高速率:
●输入:
○tcx(mdct域->时域,经由反MDCT)
●追踪:
○时域
○基于能量水平的最小值统计->舒缓噪声水平
●隐藏:
○「照原样」使用水平
■FD TCX PLC->在时域中衰落
○对于以下PLC水平转换至激发域中
■TD TCX PLC(类似ACELP)->在激发域中衰落
FFT域及MDCT域皆为频谱域,而激发域为某种时域。
根据实施例,第一重建单元140可例如用于通过进行至类似噪声的频谱的第一衰落而 重建第三音频信号部分。第二重建单元141可例如用于通过进行至类似噪声的频谱的第二 衰落及/或LTP增益的第二衰落来重建第四音频信号部分。此外,第一重建单元140及第二 重建单元141可例如用于按相同衰落速度进行至类似噪声的频谱的第一衰落及至类似噪声 的频谱的第二衰落及/或LTP增益的第二衰落。
现在考虑舒缓噪声的适应性频谱成形。
为了达成在突发封包丢失的过程中至舒缓噪声的适应性成形,作为第一步骤,可进行 对表示背景噪声的适当LPC系数的发现。可在起作用语音的过程中使用用于发现背景噪声 频谱的最小值统计方法及接着通过使用文献中已知的用于LPC得到的任意算法而自背景噪 声频谱计算LPC系数来得到这些LPC系数。例如,一些实施例可直接将背景噪声频谱转换 成可直接用于MDCT域中的FDNS的表示。
至舒缓噪声的衰落可在ISF域中进行(在LSF域中亦可适用;LSF线谱频率):
fcurrent[i]=α·flast[i]+(1-α)·ptmean[i] i=0...16 (26)
通过将ptmean设定为描述舒缓噪声的适当LP系数。
关于舒缓噪声的上文所描述的适应性频谱成形,由图11说明更一般实施例。
图11说明根据实施例的用于对编码音频信号进行解码以获得重建音频信号的装置。
装置包含用于接收一个或多个帧的接收接口1110、系数产生器1120及信号重建器1130。
系数产生器1120用于在一个或多个帧中的当前帧由接收接口1110接收的情况下及在 由接收接口1110接收的当前帧并非被损毁/不正确的情况下,判定由当前帧包含一个或多 个第一音频信号系数,其中该一个或多个第一音频信号系数指示编码音频信号的特性,且 判定指示编码音频信号的背景噪声的一个或多个噪声系数。此外,系数产生器1120用于在 当前帧不由接收接口1110接收的情况下或在由接收接口1110接收的当前帧被损毁/不正 确的情况下,取决于一个或多个第一音频信号系数及取决于一个或多个噪声系数而产生一 个或多个第二音频信号系数。
音频信号重建器1130用于在当前帧由接收接口1110接收的情况下及在由接收接口 1110接收的当前帧未被损毁的情况下,取决于一个或多个第一音频信号系数而重建重建音 频信号的第一部分。此外,音频信号重建器1130用于在当前帧不由接收接口1110接收的 情况下或在由接收接口1110接收的当前帧被损毁的情况下,取决于一个或多个第二音频信 号系数而重建重建音频信号的第二部分。
判定背景噪声在现有技术中是熟知的(参见例如[Mar01]:Rainer Martin的“Noise power spectral density estimation based on optimal smoothing and minimum statistics(基于优化光滑和最小值统计的噪声功率谱密度估计)”,IEEE Transactions on Speech and Audio Processing(语音处理及音频处理)9(2001)第5期,第504至512 页),且在实施例中,装置相应地继续进行。
在一些实施例中,一个或多个第一音频信号系数可例如为编码音频信号的一个或多个 线性预测滤波器系数。在一些实施例中,一个或多个第一音频信号系数可例如为编码音频 信号的一个或多个线性预测滤波器系数。
现有技术中已知如何自线性预测滤波器系数或自导抗频谱对重建音频信号(例如,语 音信号)(参见例如,[3GP09c]:Speech codec speech processing functions(语音编 码解码器的语音处理功能);adaptive multi-rate-wideband(AMRWB)speech codec (自适应多速率宽带语音编码解码器);transcoding functions(编码变换功能),3GPP TS 26.190,第三代合作伙伴计划,2009),且在实施例中,信号重建器相应地继续进行。
根据实施例,一个或多个噪声系数可例如为指示编码音频信号的背景噪声的一个或多 个线性预测滤波器系数。在实施例中,一个或多个线性预测滤波器系数可例如表示背景噪 声的频谱形状。
在实施例中,系数产生器1120可例如用于判定一个或多个第二音频信号部分以使得一 个或多个第二音频信号部分为重建音频信号的一个或多个线性预测滤波器系数,或使得一 个或多个第一音频信号系数为重建音频信号的一个或多个导抗频谱对。
根据实施例,系数产生器1120可例如用于通过应用如下公式而产生一个或多个第二音 频信号系数:
fcurrent[i=α·flast[i]+(1-α)·ptmean[i]
其中fcurrent[i]指示一个或多个第二音频信号系数中的一个,其中flast[i]指示一个或多个 第一音频信号系数中的一个,其中ptmean[i]为一个或多个噪声系数中的一个,其中α为实数, 其中0≤α≤1,且其中i为索引。
根据实施例,flast[i]指示编码音频信号的线性预测滤波器系数,且其中fcurrent[i]指示重建 音频信号的线性预测滤波器系数。
在实施例中,ptmean[i]可例如为线性预测滤波器系数,其指示编码音频信号的背景噪声。
根据实施例,系数产生器1120可例如用于产生至少10个第二音频信号系数作为一个 或多个第二音频信号系数。
在实施例中,系数产生器1120可例如用于在一个或多个帧中的当前帧由接收接口1110 接收的情况下及在由接收接口1110接收的当前帧未被损毁的情况下,通过判定编码音频信 号的噪声频谱来判定一个或多个噪声系数。
在下文中,考虑在FDNS应用之前将MDCT频谱衰落至白噪声。
代替随机修改MDCT频率仓的符号(符号加扰),用使用FDNS成形的白噪声来填充完整 频谱。为了避免频谱特性中的实时改变,应用符号加扰与噪声填充之间的交叉衰落。可如 下实现交叉衰落:
其中:
cum_damping为(绝对)衰减因子,其在帧之间减少,自1开始且朝向0减少
x_old为最后接收的帧的频谱
random_sign返回1或-1
noise含有随机向量(白噪声),其被按比例调整以使得其二次均值(RMS)类似于最后 良好频谱。
术语random_sign()*old_x[i]表征用以使相位随机化且如此避免谐波重复的符号加 扰程序。
随后,可在交叉衰落之后执行能量水平的另一归一化以确保总能量不会归因于两个向 量的相关而发生偏离。
根据实施例,第一重建单元140可例如用于取决于噪声水平信息及取决于第一音频信 号部分重建第三音频信号部分。在特定实施例中,第一重建单元140可例如用于通过减小 或放大第一音频信号部分来重建第三音频信号部分。
在一些实施例中,第二重建单元141可例如用于取决于噪声水平信息及取决于第二音 频信号部分重建第四音频信号部分。在特别的实施例中,第二重建单元141可例如用于通 过减小或放大第二音频信号部分来重建第四音频信号部分。
关于上文所描述的在FDNS应用之前MDCT频谱至白噪声的衰落,由图12说明更一般的 实施例。
图12说明根据实施例的用于对编码音频信号进行解码以获得重建音频信号的装置。
装置包含用于接收包含关于编码音频信号的音频信号频谱的多个音频信号样本的信息 的一个或多个帧的接收接口1210,及用于产生重建音频信号的处理器1220。
处理器1220用于在当前帧不由接收接口1210接收的情况下或在当前帧由接收接口 1210接收但被损毁的情况下,通过将修改的频谱衰落至目标频谱来产生重建音频信号,其 中修改的频谱包含多个修改的信号样本,其中针对修改的频谱的每个修改的信号样本,该 修改的信号样本的绝对值等于音频信号频谱的音频信号样本中的一个的绝对值。
此外,处理器1220用于在一个或多个帧中的当前帧由接收接口1210接收的情况下及 在由接收接口1210接收的当前帧未被损毁的情况下,不将修改的频谱衰落至目标频谱。
根据实施例,目标频谱为类似噪声的频谱。
在实施例中,类似噪声的频谱表示白噪声。
根据实施例,类似噪声的频谱被成形。
在实施例中,类似噪声的频谱的形状取决于先前接收的信号的音频信号频谱。
根据实施例,取决于音频信号频谱的形状而成形类似噪声的频谱。
在实施例中,处理器1220使用倾斜因子来使类似噪声的频谱成形。
根据实施例,处理器1220使用如下公式:
shaped_noise[i]=noise*power(tilt_factor,i/N)
其中N指示样本的数目,
其中i为索引,
其中0<=i<N,其中tilt_factor>0,
其中power为功率函数。
若tilt_factor小于1,则此情形意味在i增加的情况下的衰减。若tilt_factor大于 1,则意味在i增加的情况下的放大。
根据另一实施例,处理器1220可使用如下公式:
shaped_noise[i]=noise*(1+i/(N-1)*(tilt_factor-1))
其中N指示样本的数目,
其中i为索引,其中0<=i<N,
其中tilt_factor>0。
根据实施例,处理器1220用于在当前帧不由接收接口1210接收的情况下或在由接收 接口1210接收的当前帧被损毁的情况下,通过改变音频信号频谱的音频信号样本中的一个 或多个的符号来产生修改的频谱。
在实施例中,音频信号频谱的音频信号样本中的每一个由实数表示,但不由虚数表示。
根据实施例,音频信号频谱的音频信号样本被表示在修改的离散余弦变换域中。
在另一实施例中,音频信号频谱的音频信号样本被表示在经修改的离散正弦变换域中。
根据实施例,处理器1220用于通过使用随机或伪随机输出第一值抑或第二值的随机符 号函数产生修改的频谱。
在实施例中,处理器1220用于通过随后减小衰减因子而将修改的频谱衰落至目标频谱。
根据实施例,处理器1220用于通过随后增加衰减因子而将修改的频谱衰落至目标频谱。
在实施例中,在当前帧不由接收接口1210接收的情况下或在由接收接口1210接收的 当前帧被损毁的情况下,处理器1220用于通过使用如下公式产生重建音频信号:
x[i]=(1-cum_damping)*noise[i]+cum_damping*random_sign()*x_old[i]
其中i为索引,其中x[i]指示重建音频信号的样本,其中cum_damping为衰减因子, 其中x_old[i]指示编码音频信号的音频信号频谱的音频信号样本中的一个,其中 random_sign()返回1或-1,且其中noise为指示目标频谱的随机向量。
一些实施例继续TCX LTP操作。在那些实施例中,在隐藏的过程中用自最后良好帧得 到的LTP参数(LTP滞后及LTP增益)继续TCX LTP操作。
LTP操作可概述如下:
-基于先前得到的输出对LTP延迟缓冲器进行反馈。
-基于LTP滞后:从LTP延迟缓冲器当中选择被用作LTP贡献以使当前信号成形的适 当信号部分。
-使用LTP增益重新按比例调整此LTP贡献。
-将此重新按比例调整的LTP贡献与LTP输入信号相加以产生LTP输出信号。
关于执行LTP延迟缓冲器更新的时间,可考虑不同方法:
作为使用来自最后帧n-1的输出的在帧n中的第一LTP操作。这对在帧n中的LTP处 理的过程中待使用的在帧n中的LTP延迟缓冲器进行更新。
作为使用来自当前帧n的输出的在帧n中的最后LTP操作。这对在帧n+1中的LTP处 理的过程中待使用的在帧n中的LTP延迟缓冲器进行更新。
在下文中,考虑TCX LTP反馈回路的解耦。
解耦TCX LTP反馈回路避免了在处于隐藏模式中时在LTP解码器的每一反馈回路的过 程中额外噪声的引入(由应用于LPT输入信号的噪声替换产生)。
图10说明此解耦。特别地,图10描绘在隐藏的过程中的LTP反馈回路的解耦(bfi=1)。
图10说明延迟缓冲器1020、样本选择器1030及样本处理器1040(样本处理器1040 由虚线指示)。
到执行LTP延迟缓冲器1020更新的时间,一些实施例如下继续进行:
-对于正常操作:按第一LTP操作更新LTP延迟缓冲器1020可能为较佳的,因为通 常持续地储存经求和的输出信号。通过此方法,可省略专用缓冲器。
-对于解耦操作:按最后LTP操作更新LTP延迟缓冲器1020可能为较佳的,因为通 常仅暂时地储存对信号的LTP贡献。通过此方法,保留了暂时性LTP贡献信号。就实施而 言,完全可使此LTP贡献缓冲器为持续性的。
假设在任何状况下使用后一方法(正常操作及隐藏),实施例可例如实施以下情形:
-在正常操作的过程中:在添加至LTP输入信号之后的LTP解码器的时域信号输出被 用以对LTP延迟缓冲器进行反馈。
-在隐藏的过程中:在添加至LTP输入信号之前的LTP解码器的时域信号输出被用以 对LTP延迟缓冲器进行反馈。
一些实施例使TCX LTP增益朝向零衰落。在此实施例中,TCX LTP增益可例如按某一信 号适应性衰落因子朝向零衰落。例如,此情形可例如根据以下伪码迭代地进行:
gain=gain_past*damping;
[...]
gain_past=gain;
其中:
gain为在当前帧中应用的TCX LTP解码器增益;
gain_past为在先前帧中应用的TCX LTP解码器增益;
damping为(相对)衰落因子。
图1d说明根据另一实施例的装置,其中装置进一步包含长期预测单元170,该长期预 测单元170包含延迟缓冲器180。长期预测单元170用于取决于第二音频信号部分、取决 于储存于延迟缓冲器180中的延迟缓冲器输入及取决于长期预测增益而产生处理信号。此 外,长期预测单元用于在多个帧中的该第三帧不由接收接口110接收的情况下或在该第三 帧由接收接口110接收但被损毁的情况下,使长期预测增益朝向零衰落。
在其他实施例中(未示出),长期预测单元可例如用于取决于第一音频信号部分、取决 于储存于延迟缓冲器中的延迟缓冲器输入及取决于长期预测增益而产生处理信号。
在图1d中,此外,第一重建单元140可例如取决于处理信号产生第三音频信号部分。
在实施例中,长期预测单元170可例如用于使长期预测增益朝向零衰落,其中长期预 测增益衰落至零的速度取决于衰落因子。
可选地或另外,长期预测单元170可例如用于在多个帧中的该第三帧不由接收接口110 接收的情况下或在该第三帧由接收接口110接收但被损毁的情况下,通过将所产生的处理 信号储存于延迟缓冲器180中来更新延迟缓冲器180输入。
关于TCX LTP的上文所描述的使用,由图13说明更一般的实施例。
图13说明用于对编码音频信号进行解码以获得重建音频信号的装置。
装置包含用于接收多个帧的接收接口1310、用于储存解码音频信号的音频信号样本的 延迟缓冲器1320、用于自储存于延迟缓冲器1320中的音频信号样本选择多个选定音频信 号样本的样本选择器1330及用于处理选定音频信号样本以获得重建音频信号的重建音频 信号样本的样本处理器1340。
样本选择器1330用于在当前帧由接收接口1310接收的情况下及在由接收接口1310接 收的当前帧未被损毁的情况下,取决于由当前帧包含的音高滞后信息自储存于延迟缓冲器 1320中的音频信号样本选择多个选定音频信号样本。此外,样本选择器1330用于在当前 帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被损毁的情况下, 取决于由先前由接收接口1310所接收的另一帧所包含的音高滞后信息自储存于延迟缓冲 器1320中的音频信号样本选择多个选定音频信号样本。
根据实施例,样本处理器1340可例如用于在当前帧由接收接口1310接收的情况下及 在由接收接口1310接收的当前帧未被损毁的情况下,通过取决于由当前帧所包含的增益信 息重新按比例调整选定音频信号样本而获得重建音频信号样本。此外,样本选择器1330可 例如用于在当前帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被 损毁的情况下,通过取决于由先前由接收接口1310所接收的该另一帧所包含的增益信息重 新按比例调整选定音频信号样本而获得重建音频信号样本。
在实施例中,样本处理器1340可例如用于在当前帧由接收接口1310接收的情况下及 在由接收接口1310接收的当前帧未被损毁的情况下,通过将选定音频信号样本与取决于由 当前帧所包含的增益信息的值相乘而获得重建音频信号样本。此外,样本选择器1330用于 在当前帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被损毁的情 况下,通过将选定音频信号样本与取决于由先前由接收接口1310所接收的该另一帧所包含 的增益信息的值相乘而获得重建音频信号样本。
根据实施例,样本处理器1340可例如用于将重建音频信号样本储存于延迟缓冲器1320 中。
在实施例中,样本处理器1340可例如用于在由接收接口1310接收另一帧之前将重建 音频信号样本储存于延迟缓冲器1320中。
根据实施例,样本处理器1340可例如用于在由接收接口1310接收另一帧之后将重建 音频信号样本储存于延迟缓冲器1320中。
在实施例中,样本处理器1340可例如用于取决于增益信息来重新按比例调整选定音频 信号样本以获得重新按比例调整的音频信号样本,及通过组合重新按比例调整的音频信号 样本与输入音频信号样本以获得处理音频信号样本。
根据实施例,样本处理器1340可例如用于在当前帧由接收接口1310接收的情况下及 在由接收接口1310接收的当前帧未被损毁的情况下,将指示重新按比例调整的音频信号样 本与输入音频信号样本的组合的处理音频信号样本储存于延迟缓冲器1320中,且不将重新 按比例调整的音频信号样本储存于延迟缓冲器1320中。此外,样本处理器1340用于在当 前帧不由接收接口1310接收的情况下或在由接收接口1310接收的当前帧被损毁的情况下, 将重新按比例调整的音频信号样本储存于延迟缓冲器1320中,且不将处理音频信号样本储 存于延迟缓冲器1320中。
根据另一实施例,样本处理器1340可例如用于在当前帧不由接收接口1310接收的情 况下或在由接收接口1310接收的当前帧被损毁的情况下,将处理音频信号样本储存于延迟 缓冲器1320中。
在实施例中,样本选择器1330可例如用于通过取决于修改的增益重新按比例调整选定 音频信号样本而获得重建音频信号样本,其中修改的增益是根据如下公式来定义的:
gain=gain_past*damping;
其中gain为修改的增益,其中样本选择器1330可例如用于在gain已被计算之后将 gain_past设定为gain,且其中damping为实数。
根据实施例,样本选择器1330可例如用于计算修改的增益。
在实施例中,damping可例如根据下式来定义:0<damping<1。
根据实施例,在自上一帧由接收接口1310接收以来至少预定义数目的帧尚未由接收接 口1310接收的情况下,修改的增益gain可例如被设定为零。
在下文中,考虑衰落速度。存在应用某种衰落的若干隐藏模块。虽然此衰落的速度可能 在那些模块中被不同地进行选择,但对于一个核心(ACELP或TCX)的所有隐藏模块使用相 同衰落速度系有益的。举例而言:
对于ACELP,特别地,针对适应性码簿(通过更改增益)及/或针对创新码簿信号(通 过更改增益),应使用相同衰落速度。
又,对于TCX,特别地,针对时域信号及/或针对LTP增益(衰落至零)及/或针对LPC 加权(衰落至一)及/或针对LP系数(衰落至背景频谱形状)及/或针对至白噪声的交叉衰 落,应使用相同衰落速度。
针对ACELP及TCX亦使用相同衰落速度可能进一步为较佳的,但归因于核心的不同性 质,亦可能选择使用不同衰落速度。
此衰落速度可能为静态的,但较佳地适应于信号特性。举例而言,衰落速度可例如取决 于LPC稳定性因子(TCX)及/或分类及/或连续丢失帧的数目。
衰落速度可例如取决于衰减因子来判定,该衰减因子可能被绝对地或相对地给出,且 亦可能在某一衰落的过程中随时间的流逝而改变。
在实施例中,对于LTP增益衰落使用与白噪声衰落相同的衰落速度。
已提供用于产生如上文所描述的舒缓噪声信号的装置、方法及计算机程序。
根据本发明的实施例,提供一种用于解码音频信号的装置,包括:接收接口110,其中 接收接口110用于接收包括音频信号的第一音频信号部分的第一帧,且其中接收接口110 用于接收包括音频信号的第二音频信号部分的第二帧;噪声水平追踪单元130,其中噪声水 平追踪单元130用于根据第一音频信号部分及第二音频信号部分中的至少一个判定噪声水 平信息,其中噪声水平信息被表示于追踪域中;第一重建单元140,用于在多个帧中的第三 帧不由接收接口110接收的情况下或在第三帧由接收接口110接收但被损毁的情况下,根 据噪声水平信息而在第一重建域中重建音频信号的第三音频信号部分,其中第一重建域不 同于或等于追踪域;变换单元121,用于在多个帧中的第四帧不由接收接口110接收的情 况下或在第四帧由接收接口110接收但被损毁的情况下,将噪声水平信息自追踪域变换至 第二重建域,其中第二重建域不同于追踪域,且其中第二重建域不同于第一重建域,以及 第二重建单元141,用于在多个帧中的第四帧不由接收接口110接收的情况下或在第四帧 由接收接口110接收但被损毁的情况下,根据在第二重建域中表示的噪声水平信息而在第 二重建域中重建音频信号的第四音频信号部分。
根据本发明的实施例,其中追踪域为时域、频谱域、FFT域、MDCT域或激发域,其中第 一重建域为时域、频谱域、FFT域、MDCT域或激发域,且其中第二重建域为时域、频谱域、 FFT域、MDCT域或激发域,但不是与第一重建域相同的域。
根据本发明的实施例,其中追踪域为FFT域,其中第一重建域为时域,且其中第二重 建域为激发域。
根据本发明的实施例,其中追踪域为时域,其中第一重建域为时域,且其中第二重建域 为激发域。
根据本发明的实施例,其中第一音频信号部分被表示于第一输入域中,且其中第二音 频信号部分被表示于第二输入域中,其中变换单元121为第二变换单元121,其中装置进 一步包含第一变换单元120,第一变换单元120用于将第二音频信号部分或自第二音频信 号部分得到的值或信号自第二输入域变换至追踪域以获得第二信号部分信息,其中噪声水 平追踪单元用于接收在追踪域中表示的第一信号部分信息,其中第一信号部分信息根据第 一音频信号部分,其中噪声水平追踪单元130用于接收在追踪域中表示的第二信号部分, 且其中噪声水平追踪单元130用于根据在追踪域中表示的第一信号部分信息及根据在追踪 域中表示的第二信号部分信息判定噪声水平信息。
根据本发明的实施例,其中第一输入域为激发域,且其中第二输入域为MDCT域。
根据本发明的实施例,其中第一输入域为MDCT域,且其中第二输入域为MDCT域。
根据本发明的实施例,其中第一重建单元140用于通过进行至类似噪声的频谱的第一 衰落来重建第三音频信号部分,其中第二重建单元141用于通过进行至类似噪声的频谱的 第二衰落及/或LTP增益的第二衰落来重建第四音频信号部分,且其中第一重建单元140及 第二重建单元141用于在相同衰落速度的情况下,进行至类似噪声的频谱的第一衰落及第 二衰落及/或LTP增益的第二衰落。
根据本发明的实施例,其中装置进一步包括用于根据第一音频信号部分而判定第一聚 合值的第一聚合单元150,其中装置进一步包括用于根据第二音频信号部分而将第二聚合 值判定为自第二音频信号部分得到的值的第二聚合单元160,其中噪声水平追踪单元130用 于接收第一聚合值作为在追踪域中表示的第一信号部分信息,其中噪声水平追踪单元130 用于接收第二聚合值作为在追踪域中表示的第二信号部分信息,且其中噪声水平追踪单元 130用于根据在追踪域中表示的第一聚合值及根据在追踪域中表示的第二聚合值而判定噪 声水平信息。
根据本发明的实施例,其中第一聚合单元150用于判定第一聚合值以使得第一聚合值 指示第一音频信号部分或自第一音频信号部分得到的信号的均方根,且其中第二聚合单元 160用于判定第二聚合值以使得第二聚合值指示第二音频信号部分或自第二音频信号部分 得到的信号的均方根。
根据本发明的实施例,其中第一变换单元120用于通过对自第二音频信号部分得到的 值应用增益值而将自第二音频信号部分得到的值自第二输入域变换至追踪域。
根据本发明的实施例,其中增益值指示由线性预测编码合成引入的增益,或其中增益 值指示由线性预测编码合成及去加重引入的增益。
根据本发明的实施例,其中噪声水平追踪单元130用于通过应用最小值统计方法来判 定噪声水平信息。
根据本发明的实施例,其中噪声水平追踪单元130用于将舒缓噪声水平判定为噪声水 平信息,且其中重建单元140用于在多个帧中的第三帧不由接收接口110接收的情况下或 在第三帧由接收接口110接收但被损毁的情况下,根据噪声水平信息而重建第三音频信号 部分。
根据本发明的实施例,其中噪声水平追踪单元130用于将舒缓噪声水平判定为自噪声 水平频谱得到的噪声水平信息,其中噪声水平频谱是通过应用最小值统计方法而获得的, 且其中重建单元140用于在多个帧中的第三帧不由接收接口110接收的情况下或在第三帧 由接收接口110接收但被损毁的情况下,根据多个线性预测系数而重建第三音频信号部分。
根据本发明的实施例,其中第一重建单元140用于在多个帧中的第三帧不由接收接口 110接收的情况下或在第三帧由接收接口110接收但被损毁的情况下,根据噪声水平信息 及根据第一音频信号部分或第二音频信号部分而重建第三音频信号部分。
根据本发明的实施例,其中第一重建单元140用于通过减小或放大自第一音频信号部 分或第二音频信号部分得到的信号来重建第三音频信号部分。
根据本发明的实施例,其中第二重建单元141用于根据噪声水平信息及根据第二音频 信号部分重建第四音频信号部分。
根据本发明的实施例,其中第二重建单元141用于通过减小或放大自第一音频信号部 分或第二音频信号部分得到的信号来重建第四音频信号部分。
根据本发明的实施例,其中装置进一步包括长期预测单元170,长期预测单元170包括 延迟缓冲器180,其中长期预测单元170用于根据第一音频信号部分或第二音频信号部分、 根据储存于延迟缓冲器180中的延迟缓冲器输入及根据长期预测增益而产生处理信号,且 其中长期预测单元170用于在多个帧中的第三帧不由接收接口110接收的情况下或在第三 帧由接收接口110接收但被损毁的情况下,使长期预测增益朝向零衰落。
根据本发明的实施例,其中长期预测单元170用于使长期预测增益朝向零衰落,其中 长期预测增益朝向零衰落的速度取决于衰落因子。
根据本发明的实施例,其中长期预测单元170用于在多个帧中的第三帧不由接收接口 110接收的情况下或在第三帧由接收接口110接收但被损毁的情况下,通过将所产生的处 理信号储存于延迟缓冲器180中来更新延迟缓冲器180输入。
根据本发明的实施例,提供一种用于解码音频信号的方法,包括:接收包括音频信号 的第一音频信号部分的第一帧,及接收包括音频信号的第二音频信号部分的第二帧;根据 第一音频信号部分及第二音频信号部分中的至少一个判定噪声水平信息,其中噪声水平信 息被表示于追踪域中;在多个帧中的第三帧未被接收的情况下或在第三帧被接收但被损毁 的情况下,根据噪声水平信息而在第一重建域中重建音频信号的第三音频信号部分,其中 第一重建域不同于或等于追踪域;在多个帧中的第四帧未被接收的情况下或在第四帧被接 收但被损毁的情况下,将噪声水平信息自追踪域变换至第二重建域,其中第二重建域不同 于追踪域,且其中第二重建域不同于第一重建域,以及在多个帧中的第四帧未被接收的情 况下或在第四帧被接收但被损毁的情况下,根据在第二重建域中表示的噪声水平信息而在 第二重建域中重建音频信号的第四音频信号部分。
根据本发明的实施例,提供一种计算机程序,用于在执行于计算机或信号处理器上时 实施本发明实施例提供的用于解码音频信号的方法。
尽管已在装置的上下文中描述一些方面,但显然,这些方面亦表示对应方法的描述,其 中区块或器件对应于方法步骤或方法步骤的特征。类似地,在方法步骤的上下文中所描述 的方面亦表示对应装置的对应区块或项目或特征的描述。
本发明的分解的信号可储存于数字储存媒体上或可在诸如无线传输媒体的传输媒体或 诸如因特网的有线传输媒体上传输。
取决于某些实施要求,本发明的实施例可以硬件或软件实施。实施可使用数字储存媒 体来执行,该媒体例如软性磁盘、DVD、CD、ROM、PROM、EPROM、EEPROM或闪存,该媒体上 储存有电子可读控制信号,这些电子可读控制信号与可编程计算机系统协作(或能够协作) 以使得执行各个方法。
根据本发明的一些实施例包含具有电子可读控制信号的非暂时性数据载体,这些电子 可读控制信号能够与可编程计算机系统协作,使得执行本文中所描述的方法中的一个。
大体而言,本发明的实施例可实施为具有程序代码的计算机程序产品,当计算机程序 产品执行于计算机上时,程序代码操作性地用于执行这些方法中的一个。程序代码可(例 如)储存于机器可读载体上。
其他实施例包含储存于机器可读载体上的用于执行本文中所描述的方法中的一个的计 算机程序。
换言之,因此,本发明方法的实施例为具有程序代码的计算机程序,当计算机程序执行 于计算机上时,该程序代码用于执行本文中所描述的方法中的一个。
因此,本发明方法的另一实施例为包含记录于其上的,用于执行本文中所描述的方法 中的一个的计算机程序的数据载体(或数字储存媒体,或计算机可读媒体)。
因此,本发明方法的另一实施例为表示用于执行本文中所描述的方法中的一个的计算 机程序的数据串流或信号序列。数据串流或信号序列可例如用于经由数据通信连接(例如, 经由因特网)而传送。
另一实施例包含用于或经调适以执行本文中所描述的方法中的一个的处理构件,例如, 计算机或可编程逻辑器件。
另一实施例包含安装有用于执行本文中所描述的方法中的一个的计算机程序的计算机。
在一些实施例中,可编程逻辑器件(例如,场可编程门阵列)可用于执行本文中所描述 的方法的功能性中的一些或所有。在一些实施例中,场可编程门阵列可与微处理器协作, 以便执行本文中所描述的方法中的一个。大体而言,较佳地由任何硬件装置执行这些方法。
上文所描述的实施例仅仅说明本发明的原理。应理解,对本文中所描述的配置及细节 的修改及变型对本领域技术人员而言将是显而易见。因此,仅意欲由待决专利的权利要求 的范围限制,而不由通过本文的实施例的描述及解释而提出的特定细节限制。
参考文献
[3GP09a]3GPP;Technical Specification Group Services and System Aspects, Extended adaptive multi-rate-wideband(AMR-WB+)codec,3GPP TS 26.290,3rd Generation PartnershipProject,2009.
[3GP09b]Extended adaptive multi-rate-wideband(AMR-WB+)codec;floating- point ANSI-C code,3GPP TS 26.304,3rd Generation Partnership Project,2009.
[3GP09c]Speech codec speech processing functions;adaptive multi-rate- wideband(AMRWB)speech codec;transcoding functions,3GPP TS 26.190, 3rd Generation PartnershipProject,2009.
[3GP12a]Adaptive multi-rate(AMR)speech codec;error concealment of lost frames(release 11),3GPP TS 26.091,3rd Generation Partnership Project,Sep 2012.
[3GP12b]Adaptive multi-rate(AMR)speech codec;transcoding functions (release 11),3GPP TS 26.090,3rd Generation Partnership Project, Sep 2012.[3GP12c],ANSI-C code for the adaptive multi-rate- wideband(AMR-WB)speech codec,3GPP TS 26.173,3rd Generation Partnership Project,Sep 2012.
[3GP12d]ANSI-C code for the floating-point adaptive multi-rate(AMR)speech codec(release11),3GPP TS 26.104,3rd Generation Partnership Project,Sep 2012.
[3GP12e]General audio codec audio processing functions;Enhanced aacPlus general audio codec;additional decoder tools(release 11),3GPP TS 26.402,3rd Generation PartnershipProject,Sep 2012.
[3GP12f]Speech codec speech processing functions;adaptive multi-rate- wideband(amr-wb)speech codec;ansi-c code,3GPP TS 26.204,3rd Generation Partnership Project,2012.
[3GP12g]Speech codec speech processing functions;adaptive multi-rate- wideband(AMR-WB)speech codec;error concealment of erroneous or lost frames,3GPP TS 26.191,3rdGeneration Partnership Project,Sep 2012.
[BJH06]I.Batina,J.Jensen,and R.Heusdens,Noise power spectrum estimation for speech enhancement using an autoregressive model for speech power spectrum dynamics,in Proc.IEEE Int.Conf.Acoust., Speech,Signal Process.3(2006),1064–1067.
[BP06]A.Borowicz and A.Petrovsky,Minima controlled noise estimation for klt-based speech enhancement,CD-ROM,2006,Italy,Florence.
[Coh03]I.Cohen,Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging,IEEE Trans.Speech Audio Process.11(2003),no.5,466–475.
[CPK08]Choong Sang Cho,Nam In Park,and Hong Kook Kim,A packet loss concealment algorithm robust to burst packet loss for celp-type speech coders,Tech.report,KoreaEnectronics Technology Institute, Gwang Institute of Science and Technology,2008,The23rd International Technical Conference on Circuits/Systems,Computers and Communications(ITC-CSCC 2008).
[Dob95]G.Doblinger,Computationally efficient speech enhancement by spectral minima tracking in subbands,in Proc.Eurospeech(1995), 1513–1516.
[EBU10]EBU/ETSI JTC Broadcast,Digital audio broadcasting(DAB);transport of advanced audio coding(AAC)audio,ETSI TS 102 563,European Broadcasting Union,May 2010.
[EBU12]Digital radio mondiale(DRM);system specification,ETSI ES 201 980, ETSI,Jun 2012.
[EH08]Jan S.Erkelens and Richards Heusdens,Tracking of Nonstationary Noise Based onData-Driven Recursive Noise Power Estimation,Audio, Speech,and Language Processing,IEEE Transactions on 16(2008),no. 6,1112–1123.
[EM84]Y.Ephraim and D.Malah,Speech enhancement using a minimum mean- square error short-time spectral amplitude estimator,IEEE Trans. Acoustics,Speech and Signal Processing32(1984),no.6,1109–1121. [EM85]Speech enhancement using a minimum mean-square error log-spectral amplitude estimator,IEEE Trans.Acoustics,Speech and Signal Processing 33(1985),443–445.
[Gan05]S.Gannot,Speech enhancement:Application of the kalman filter in the estimate-maximize(em framework),Springer,2005.
[HE95]H.G.Hirsch and C.Ehrlicher,Noise estimation techniques for robust speech recognition,Proc.IEEE Int.Conf.Acoustics,Speech,Signal Processing,no.pp.153-156,IEEE,1995.
[HHJ10]Richard C.Hendriks,Richard Heusdens,and Jesper Jensen,MMSE based noise PSD tracking with low complexity,Acoustics Speech and Signal Processing(ICASSP),2010IEEE International Conference on,Mar 2010, pp.4266–4269.
[HJH08]Richard C.Hendriks,Jesper Jensen,and Richard Heusdens,Noise tracking using dft domain subspace decompositions,IEEE Trans.Audio, Speech,Lang.Process.16(2008),no.3,541–553.
[IET12]IETF,Definition of the Opus Audio Codec,Tech.Report RFC 6716, Internet Engineering Task Force,Sep 2012.
[ISO09]ISO/IEC JTC1/SC29/WG11,Information technology–coding of audio- visual objects–part 3:Audio,ISO/IEC IS 14496-3,International Organization for Standardization,2009.
[ITU03]ITU-T,Wideband coding of speech at around 16 kbit/s using adaptive multi-rate wideband(amr-wb),Recommendation ITU-T G.722.2, Telecommunication Standardization Sectorof ITU,Jul 2003.
[ITU05]Low-complexity coding at 24 and 32 kbit/s for hands-free operation in systems with low frame loss,Recommendation ITU-T G.722.1, Telecommunication Standardization Sector of ITU,May 2005.
[ITU06a]G.722 Appendix III:A high-complexity algorithm for packet loss concealment for G.722,ITU-T Recommendation,ITU-T,Nov 2006.
[ITU06b]G.729.1:G.729-based embedded variable bit-rate coder:An 8-32 kbit/s scalable wideband coder bitstream interoperable with g.729, Recommendation ITU-T G.729.1,Telecommunication Standardization Sector of ITU,May 2006.
[ITU07]G.722 Appendix IV:A low-complexity algorithm for packet loss concealment with G.722,ITU-T Recommendation,ITU-T,Aug 2007.
[ITU08a]G.718:Frame error robust narrow-band and wideband embedded variable bit-rate coding of speech and audio from 8-32 kbit/s,Recommendation ITU-T G.718,TelecommunicationStandardization Sector of ITU,Jun 2008.
[ITU08b]G.719:Low-complexity,full-band audio coding for high-quality, conversational applications,Recommendation ITU-T G.719, Telecommunication Standardization Sectorof ITU,Jun 2008.
[ITU12]G.729:Coding of speech at 8 kbit/s using conjugate-structure algebraic-code-excited linear prediction(cs-acelp),Recommendation ITU-T G.729,TelecommunicationStandardization Sector of ITU,June 2012.
[LS01]Pierre Lauber and Ralph Sperschneider,Error concealment for compressed digital audio,Audio Engineering Society Convention 111, no.5460,Sep 2001.
[Mar01]Rainer Martin,Noise power spectral density estimation based on optimal smoothing and minimum statistics,IEEE Transactions on Speech and Audio Processing 9(2001),no.5,504–512.
[Mar03]Statistical methods for the enhancement of noisy speech, International Workshop on Acoustic Echo and Noise Control (IWAENC2003),Technical University of Braunschweig,Sep 2003.
[MC99]R.Martin and R.Cox,New speech enhancement techniques for low bit rate speech coding,in Proc.IEEE Workshop on Speech Coding(1999), 165–167.
[MCA99]D.Malah,R.V.Cox,and A.J.Accardi,Tracking speech-presence uncertainty to improve speech enhancement in nonstationary noise environments,Proc.IEEE Int.Conf.on Acoustics Speech and Signal Processing(1999),789–792.
[MEP01]Nikolaus Meine,Bernd Edler,and Heiko Purnhagen,Error protection and concealment for HILN MPEG-4 parametric audio coding,Audio Engineering Society Convention 110,no.5300,May 2001.
[MPC89]Y.Mahieux,J.-P.Petit,and A.Charbonnier,Transform coding ofaudio signals using correlation between successive transform blocks, Acoustics,Speech,and Signal Processing,1989.ICASSP-89.,1989 International Conference on,1989,pp.2021–2024 vol.3.
[NMR+12]Max Neuendorf,Markus Multrus,Nikolaus Rettelbach,Guillaume Fuchs, Julien Robilliard,Jérémie Lecomte,Stephan Wilde,Stefan Bayer, Sascha Disch,Christian Helmrich,Roch Lefebvre,Philippe Gournay, Bruno Bessette,Jimmy Lapierre,Kristopfer Heiko Purnhagen, Lars Villemoes,Werner Oomen,Erik Schuijers,Kei Kikuiri,Toru Chinen,Takeshi Norimatsu,Chong Kok Seng,Eunmi Oh,Miyoung Kim, Schuyler Quackenbush,and Berndhard Grill,MPEG Unified Speech and Audio Coding-The ISO/MPEG Standard for High-Efficiency Audio Coding of all Content Types,Convention Paper 8654,AES,April 2012, Presented at the 132nd Convention Budapest,Hungary.
[PKJ+11]Nam In Park,Hong Kook Kim,Min A Jung,Seong Ro Lee,and Seung Ho Choi,Burst packet loss concealment using multiple codebooks and comfort noise for celp-type speech coders in wireless sensor networks,Sensors 11(2011),5323–5336.
[QD03]Schuyler Quackenbush and Peter F.Driessen,Error mitigation in MPEG-4 audio packet communication systems,Audio Engineering Society Convention 115,no.5981,Oct 2003.
[RL06]S.Rangachari and P.C.Loizou,A noise-estimation algorithm for highly non-stationary environments,Speech Commun.48(2006),220– 231.
[SFB00]V.Stahl,A.Fischer,and R.Bippus,Quantile based noise estimation for spectral subtraction and wiener filtering,in Proc.IEEE Int. Conf.Acoust.,Speech and Signal Process.(2000),1875–1878.
[SS98]J.Sohn and W.Sung,A voice activity detector employing soft decision based noise spectrum adaptation,Proc.IEEE Int.Conf. Acoustics,Speech,Signal Processing,no.pp.365-368,IEEE,1998.
[Yu09]Rongshan Yu,A low-complexity noise estimation algorithm based on smoothing of noise power estimation and estimation bias correction, Acoustics,Speech and Signal Processing,2009.ICASSP 2009.IEEE International Conference on,Apr 2009,pp.4421–4424.
- 还没有人留言评论。精彩留言会获得点赞!