一种具有语音识别的食堂刷卡装置及使用方法与流程
本发明涉及刷卡装置技术领域,尤其涉及一种具有语音识别的食堂刷卡装置及使用方法。
背景技术:
在大多的食堂排队刷卡打饭已经是普遍的现象,但现有的刷卡装置需要人工手动按键输入刷卡的数字,然后排队人员进行感应式刷卡,在排队打饭人员很多的情况下,先采用按键方式输入数字,再进行刷卡,动作较慢且人工按键输入容易出错,造成排队等待时间太长,速率低下。
技术实现要素:
本发明要解决的技术问题是针对上述现有技术的不足,提供一种具有语音识别的食堂刷卡装置及使用方法,本装置使用语音识别系统,可以提高操作响应的灵敏度,提高食堂刷卡打饭的速率。
为解决上述技术问题,本发明所采取的技术方案是:
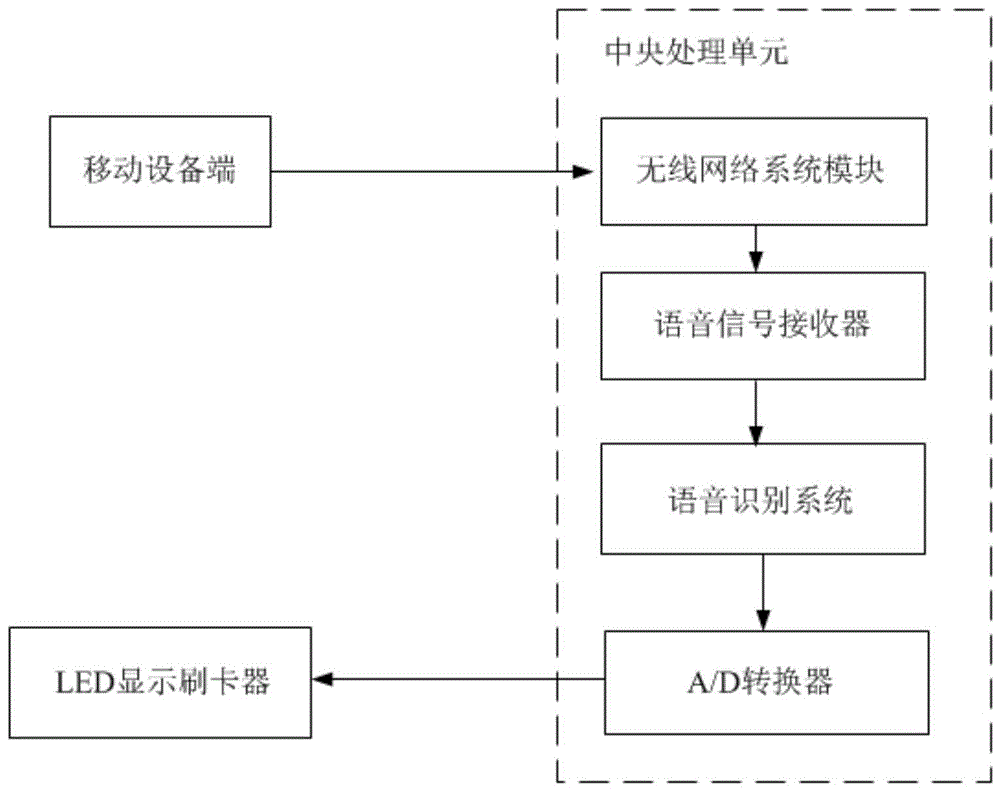
一方面,本发明提供一种具有语音识别的食堂刷卡装置,包括移动设备端、中央处理单元、led显示刷卡器;
所述中央处理单元包括无线网络系统模块、语音信号接收器、语音识别系统、a/d转换器;
所述移动设备端通过无线网络系统模块与语音信号接收器相连接;
所述无线网络系统模块用于将移动设备端与语音信号接收器进行通信连接;所述语音信号接收器用于接收通过无线网络系统模块发送过来的语音信号,其输出端与语音识别系统相连接;
所述语音识别系统用于对移动设备端输入的语音指令进行降噪处理,并对语音信号进行特征提取,采用高斯混合模型gmm建模,隐马尔科夫模型hmm训练高斯混合模型的方法建立gmm-hmm模型,将提取的每一个特征作为gmm-hmm模型的输入,得出每一个特征的最大似然概率,并根据最大似然概率输出该特征相对应的词语,将每个特征相对应的词语合并正确序列的集合文件;语音识别系统的输出端与a/d转换器的输入端相连接;
所述a/d转换器的输出端与led显示刷卡器的输入端相连接。
另一方面,本发明提供一种具有语音识别的食堂刷卡装置的使用方法,通过所述的一种具有语音识别的食堂刷卡装置实现,包括如下步骤:
步骤1:将移动设备端与无线网络系统模块连接,确保语音指令可以通过移动设备端传输;移动设备端接收到用户的语音指令,并通过无线网络系统模块将语音指令传输至语音识别系统;
步骤2:语音识别系统通过训练gmm-hmm模型对语音指令进行语音识别,输出与语音指令相对应的文字信号,根据语音信号切分顺序将得到的文字信号合并为正确序列的集合文件,并将该集合文件输出至a/d转换器;
步骤3:a/d转换器将模拟信号转换为数字信号并传输给led显示刷卡器,由led显示刷卡器将数字信号显示出来。
所述步骤2的具体步骤如下:
步骤2.1:将移动设备端输出的语音信号进行预处理,所述预处理包括降噪和增强处理,对预处理后的语音信号进行相等帧数波的切分,语音信号切分集合h={h1,h2,…,hg,…,hg},其中hg代表第g个语音信号;
步骤2.2:根据傅立叶变换对hg进行声学特征提取;得到特征序列并形成特征矢量序列
步骤2.3:建立连续型语音指令hg服从高斯混合模型gmm的概率密度函数,并将高斯混合模型整合进隐马尔科夫hmm模型,用以拟合基于状态的输出分布,根据隐马尔科夫模型hmm进行训练,得出语音指令hg的最大似然概率;
概率密度函数p(hg)表示为:
其中,μn代表n个语音变量均值,
hmm包含
设定隐藏状态si位于t-1时刻的状态qt-1,隐藏状态sj位于t时刻的状态qt,则隐藏状态从si转移到sj的转移概率为:
aij=p(qt=sj|qt-1=si)
其中,1≤i≤n,1≤j≤n,且
根据kg和sg求出概率分布矩阵bg;其中在隐藏状态sj位于t时刻的状态为qt的条件下,输出符号vk处于可观测状态
其中,1≤j≤n,1≤k≤m,且
求出所有状态的初始状态概率分布
其中
采用前向算法计算可观测特征序列的概率分布矩阵
对hmm模型参数解码,设特征序列
hmm的训练通过调节hmm的参数使得
更新公式为:
其中γ1(i)代表更新后的状态概率分布;求解出最大似然概率;
步骤2.4:令g=g+1,重复步骤步骤2.2-步骤2.3,得出语音信号切分集合h={h1,h2,…,hg,…,hg}内所有语音信号的最大似然概率;
步骤2.5:根据每个语音信号的最大似然概率得出与其相对应的文字信号,公式如下:
其中,w指文字信号,χ指特征匹配的概率,
采用上述技术方案所产生的有益效果在于:本发明提供的一种具有语音识别的食堂刷卡装置及使用方法,与现有技术相比较,本发明具有以下突出效果:
1.本发明提供的一种具有语音识别的食堂刷卡装置及使用方法,采用无线传输信号的方式,连接速度快,操作简单,成本较低。
2.本发明提供的一种具有语音识别的食堂刷卡装置及使用方法,通过使用者进行语音对讲,语音识别系统进行特征提取,确定语音信号来自使用者的传输,即可快速实现信号转换与刷卡操作,具有精确、快速、稳定的特点。
3.本发明提供的一种具有语音识别的食堂刷卡装置及使用方法,操作简单、方便快捷,可实现精准的语音识别,应用在食堂极大地解决了人工按键刷卡的耗时,很大程度上提高了食堂打饭的速率,且语音处理信号较为精确,避免了现阶段人工按键刷卡出现错误的频率,具有很大的现实应用意义。
附图说明
图1为本发明实施例提供的具有语音识别的食堂刷卡装置框图;
图2为本发明实施例提供的具有语音识别的食堂刷卡装置的使用方法流程图;
图3为本发明实施例提供的语音识别流程图;
图4为本发明实施例提供的hmm训练示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
本实施例的方法如下所述。
一方面,本发明提供一种具有语音识别的食堂刷卡装置,如图1所示,包括移动设备端、中央处理单元、led显示刷卡器;
所述中央处理单元嵌与arm智能控制芯片内,包括无线网络系统模块、语音信号接收器、语音识别系统、a/d转换器;
所述移动设备端通过无线网络系统模块与语音信号接收器相连接;所述移动设备端为优选耳麦,既可以实现近距离传输准确清晰的语音信号,又方便快捷,避免了远距离传输语音信号造成的噪音与失真等现象,以保证真实场景下的语音识别率。
所述无线网络系统模块用于将移动设备端与语音信号接收器进行通信连接;做为移动设备端与语音识别系统传输的纽带,方便快捷,操作简单,容易实现。所述语音信号接收器用于接收通过无线网络系统模块发送过来的语音信号,其输出端与语音识别系统相连接;
所述语音识别系统用于对移动设备端输入的语音指令进行降噪处理,并对语音信号进行特征提取,采用高斯混合模型gmm建模,隐马尔科夫模型hmm训练高斯混合模型的方法建立gmm-hmm模型,将提取的每一个特征作为gmm-hmm模型的输入,得出每一个特征的最大似然概率,并根据最大似然概率输出该特征相对应的词语,将每个特征相对应的词语合并正确序列的集合文件;语音识别系统的输出端与a/d转换器的输入端相连接;语音识别系统的输出端与a/d转换器的输入端相连接;首先对移动设备端输入的语音信号进行特征提取,分辨相似度是否匹配;对该语音信号进行声学模型与模式匹配,确保所输入声学模型是控制刷卡系统的模式;
所述a/d转换器(adc0809ccn)用于安装于食堂刷卡装置内部电路系统,可实现将语音识别系统输入的集合文件模拟信号转换为数字信号,其输出端与led显示刷卡器的输入端相连接。
所述led显示刷卡器用于显示a/d转换器输出的数字信号。拥有简单直观,方便快捷的优点,可以快速实现数字显示与刷卡提示;led显示刷卡器采用p3全彩led显示屏。
另一方面,本发明提供一种具有语音识别的食堂刷卡装置的使用方法,通过所述的一种具有语音识别的食堂刷卡装置实现,如图2所示,包括如下步骤:
步骤1:将移动设备端与无线网络系统模块连接,确保语音指令可以通过移动设备端传输;移动设备端接收到用户的语音指令,并通过无线网络系统模块将语音指令传输至语音识别系统;
步骤2:语音识别系统通过训练gmm-hmm模型对语音指令进行语音识别,输出与语音指令相对应的文字信号,如图3所示,根据语音信号切分顺序将得到的文字信号合并为正确序列的集合文件,并将该集合文件输出至a/d转换器;
具体步骤如下:
步骤2.1:将移动设备端输出的语音信号进行预处理,所述预处理包括降噪和增强处理,对预处理后的语音信号进行相等帧数波的切分,语音信号切分集合h={h1,h2,…,hg,…,hg},其中hg代表第g个语音信号;
步骤2.2:根据傅立叶变换对hg进行声学特征提取;得到特征序列并形成特征矢量序列
步骤2.3:建立连续型语音指令hg服从高斯混合模型gmm的概率密度函数,并将高斯混合模型整合进隐马尔科夫hmm模型,用以拟合基于状态的输出分布,根据隐马尔科夫模型hmm进行训练,得出语音指令hg的最大似然概率;
概率密度函数p(hg)表示为:
其中,μn代表n个语音变量均值,
hmm包含
设定隐藏状态si位于t-1时刻的状态qt-1,隐藏状态sj位于t时刻的状态qt,则隐藏状态从si转移到sj的转移概率为:
aij=p(qt=sj|qt-1=si)
其中,1≤i≤n,1≤j≤n,且
根据kg和sg求出概率分布矩阵bg;其中在隐藏状态sj位于t时刻的状态为qt的条件下,输出符号vk处于可观测状态
其中,1≤j≤n,1≤k≤m,且
求出所有状态的初始状态概率分布
其中
采用前向算法计算可观测特征序列的概率分布矩阵
对hmm模型参数解码,设特征序列
hmm的训练通过调节hmm的参数使得
更新公式为:
其中γ1(i)代表更新后的状态概率分布;求解出最大似然概率;
步骤2.4:令g=g+1,重复步骤步骤2.2-步骤2.3,得出语音信号切分集合h={h1,h2,…,hg,…,hg}内所有语音信号的最大似然概率;
步骤2.5:根据每个语音信号的最大似然概率得出与其相对应的文字信号,公式如下:
其中,w指文字信号,χ指特征匹配的概率,
步骤3:a/d转换器将模拟信号转换为数字信号并传输给led显示刷卡器,由led显示刷卡器将数字信号显示出来。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!