一种embedding编解码器的语音增强系统及方法与流程
本发明属于人工智能语音处理技术领域,具体涉及一种embedding编解码器的语音增强系统及方法。
背景技术:
语音增强是语音处理中一项重要的前端技术,其在无线通话、会议录音、听觉辅助、同声传译和语音识别等系统中都有广泛的应用。语音识别系统对语音质量和可懂度要求较高,虽然目前的语音识别系统准确率已经达到了较高的水平,然而对于受噪声或混响污染的语音信号往往难以达到理想的效果。轻微的噪声干扰就可以使语音识别系统的准确率大大降低,现有的非鲁棒性自动语音识别系统还不能在噪声环境下稳定工作。
使用结合注意力机制的语音增强模型来模仿人类的行为方式是一种直觉的做法。文献“modelingattentionandmemoryforauditoryselectioninacocktailpartyenvironment”将语音语谱图的高维映射、注意力机制和长期记忆应用于语音分离。然而,该方法(unifiedauditoryselectionframeworkwithattentionandmemory,asam)在生成掩蔽层的时频元时没有充分利用相关的embedding信息,其在语音增强任务中效果一般,embedding:语谱图中时频点在高维空间上的映射,在自然语言处理中也作为词或句子的表示。
技术实现要素:
针对现有技术中的上述不足,本发明提供的一种embedding编解码器语音增强系统及方法,从高维映射的角度对语音语谱图中的时频元进行建模,提出了一种新颖的语音增强模型结构,能够有效提升带噪语音质量和可懂度,并且对不同信噪比环境有着良好的泛化性。
为了达到以上目的,本发明采用的技术方案为:
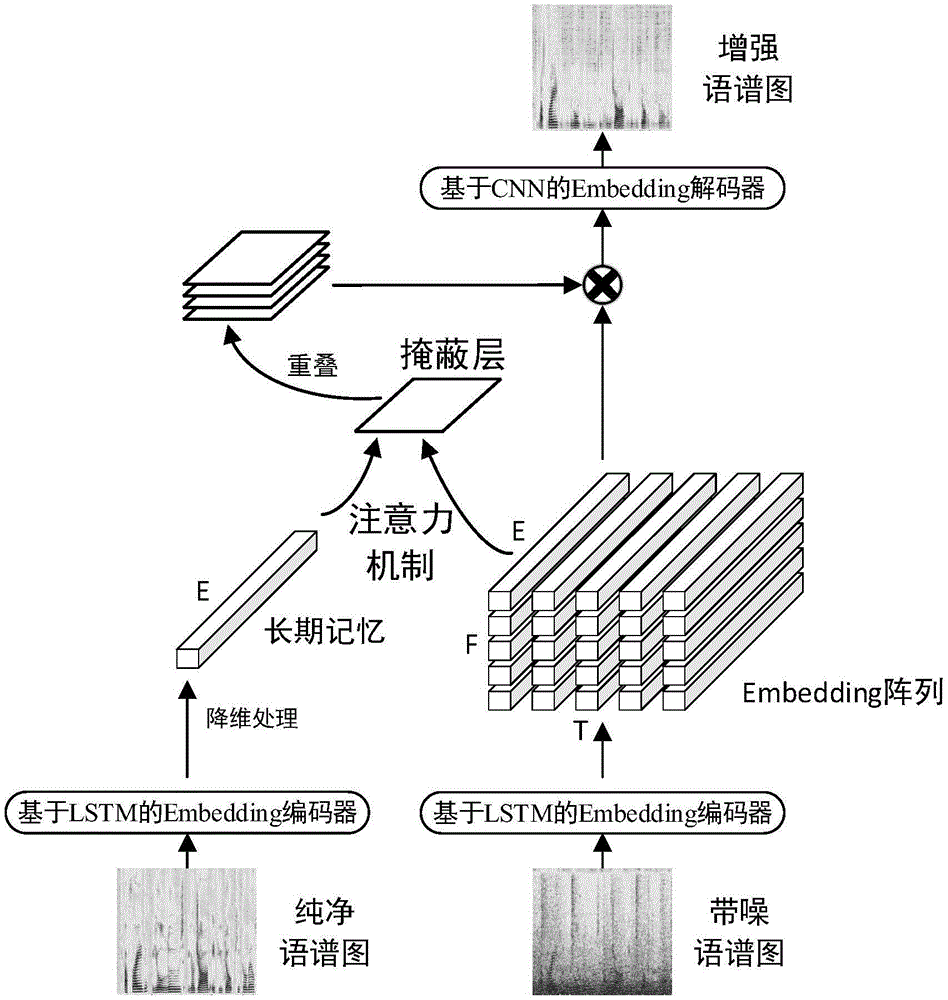
本方案提供一种embedding编解码器的语音增强系统,包括基于长短期记忆神经网络的embedding编码器、与所述embedding编码器连接的长期记忆模块、与所述长期记忆模块连接的注意力模块以及基于卷积神经网络的embedding解码器网络;
所述基于长短期记忆神经网络的embedding编码器用于分别对纯净语音语谱图和带噪语音语谱图进行编码,产生纯净语音的embedding阵列以及带噪语音的embedding阵列;
所述长期记忆模块由纯净语音的embedding阵列产生,用于从带噪语音embedding阵列中提取语音特征;
所述注意力模块用于利用含有纯净语音特征的长期记忆从带噪语音的embedding阵列中提取语音特征,形成新的embedding阵列;
所述基于卷积神经网络的embedding解码器网络用于将新的embedding阵列还原为增强语音语谱图。
进一步地,所述基于长短期记忆神经网络的embedding编码器包括1层全连接网络,以及与所述全连接网络连接且位于所述全连接网络后端的2层长短期记忆网络,且所述embedding编码器产生的embedding阵列尺寸为(f×t×e),其中,f表示频率,t表示时间,e表示embedding向量的尺寸。
再进一步地,所述基于卷积神经网络的embedding解码器网络由1层卷积神经网络组成,其卷积核大小为3×3,其输入输出通道数分别为40和1。
基于上述系统,本发明还提供了一种embedding编解码器的语音增强方法,包括如下步骤:
s1、分别对训练集中的纯净语音和带噪语音进行短时傅里叶变换处理,得到纯净语音以及带噪语音的语谱图;
s2、利用embedding编码器分别对所述纯净语音和带噪语音的语谱图进行编码,产生纯净语音的embedding阵列以及带噪语音的embedding阵列,并通过所述纯净语音的embedding阵列产生长期记忆;
s3、将带噪语音的embedding阵列和所述长期记忆输入至注意力模块,并利用含有纯净语音特征的长期记忆从所述带噪语音的embedding阵列中产生堆叠时频掩蔽层,并利用所述堆叠时频掩蔽层提取语音特征,形成新的embedding阵列;
s4、利用基于卷积神经网络的embedding解码器网络将所述新的embedding阵列还原为增强语音语谱图,实现语音增强。
进一步地,所述步骤s3包括如下步骤:
s301、将带噪语音的embedding阵列和所述长期记忆输入至注意力模块,并分别对所述带噪语音的embedding阵列和含有纯净语音特征的长期记忆进行注意力计算得到时频掩蔽;
s302、将所述时频掩蔽进行复制和堆叠,产生堆叠时频掩蔽层,并将堆叠时频掩蔽层的尺寸与embedding阵列的尺寸保持一致;
s303、利用所述堆叠时频掩蔽层从embedding阵列中提取语音特征,形成新的embedding阵列。
再进一步地,所述步骤s301中时频掩蔽的表达式如下:
at,f=sigmoid(m·at,f)
其中,m表示长期记忆,at,f表示embedding阵列中的每个embedding向量,at,f表示时频掩蔽层的每个时频单元。
再进一步地,所述步骤s302中堆叠时频掩蔽层的尺寸为(f×t×e),其中,f表示频率,t表示时间、e表示embedding向量的尺寸。
再进一步地,所述步骤s303中提取语音特征a'的表达式如下:
a'=a⊙sm
其中,a表示embedding阵列,sm表示堆叠的时频掩蔽层,⊙表示矩阵点乘。
本发明的有益效果:
(1)本发明提供一种embedding编解码器的语音增强系统,构造了一个堆叠的神经网络模型,包括四个组件:一个基于长短期记忆(lstm,longshort-termmemory)神经网络的embedding编码器、一个基于卷积神经网络(cnn,convolutionalneuralnetwork)的embedding解码器网络、长期记忆模块和注意力结构。神经网络模型对语音语谱图进行编码,对每个时频元高维映射而形成embedding向量表示。纯净语音语谱图和带噪语音语谱图分别产生一个embedding向量的阵列,其中来自纯净语音的embedding阵列产生长期记忆。由长期记忆从带噪embedding阵列提取纯净语音信息,以此形成掩蔽层。该掩蔽层滤除embedding阵列中的干扰信息。最后embedding解码器将embedding矩阵还原语音语谱图。本发明从高维映射的角度对语音语谱图中的时频元进行建模,提出了一种新颖的语音增强模型结构,能够有效提升带噪语音质量和可懂度,并且对不同信噪比环境有着良好的泛化性。此外,本发明中神经网络模型可在低信噪比环境下稳定工作。
(2)本发明提供一种embedding编解码器的语音增强方法,所述方法利用embedding解码器从embedding阵列中提取相关的embedding向量来产生语音语谱图中对应时频元的能量。由于embedding阵列中每个向量可视作对原始输入语谱图对应时频元的高维映射,而embedding阵列与其对应的语谱图一样,应在沿时间和频率方向的局部区域具有稳定性。该方法将局部相关embedding信息加入增强语谱图的形成过程,有效克服了原始方法利用embedding信息不充分的问题,提高了其在语音增强任务中性能,并且可在低信噪比环境中稳定工作。
附图说明
图1为本发明中结合注意力机制和embedding编解码语音增强模型结构示意图。
图2为本发明中embedding解码器功能示意图。
图3为本发明的方法流程图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
实施例
如图1-图2所示,本发明提供了一种embedding编解码器的语音增强系统,包括基于长短期记忆神经网络的embedding编码器、与所述embedding编码器连接的长期记忆模块、与所述长期记忆模块连接的注意力模块以及基于卷积神经网络的embedding解码器网络;所述基于长短期记忆神经网络的embedding编码器用于分别对纯净语音语谱图和带噪语音语谱图进行编码,产生纯净语音的embedding阵列以及带噪语音的embedding阵列;所述长期记忆模块由纯净语音的embedding阵列产生,用于从带噪语音embedding阵列中提取语音特征;所述注意力模块用于利用含有纯净语音特征的长期记忆从带噪语音的embedding阵列中提取语音特征,形成新的embedding阵列;所述基于卷积神经网络的embedding解码器网络用于将新的embedding阵列还原为增强语音语谱图。所述基于长短期记忆神经网络的embedding编码器包括1层全连接网络,以及与所述全连接网络连接且位于所述全连接网络后端的2层长短期记忆网络,且所述embedding编码器产生的embedding阵列尺寸为(f×t×e),其中,f表示频率,t表示时间,e表示embedding向量的尺寸。所述基于卷积神经网络的embedding解码器网络由1层卷积神经网络组成,其卷积核大小为3×3,其输入输出通道数分别为40和1。
如图3所示,基于上述系统,本发明还提供了一种embedding编解码器的语音增强方法,包括如下步骤:
s1、分别对训练集中的纯净语音和带噪语音进行短时傅里叶变换处理,得到纯净语音以及带噪语音的语谱图;
s2、利用embedding编码器分别对所述纯净语音和带噪语音的语谱图进行编码,产生纯净语音的embedding阵列以及带噪语音的embedding阵列,并通过所述纯净语音的embedding阵列产生长期记忆;
s3、将带噪语音的embedding阵列和所述长期记忆输入至注意力模块,并利用含有纯净语音特征的长期记忆从所述带噪语音的embedding阵列中产生堆叠时频掩蔽层,并利用所述堆叠时频掩蔽层提取语音特征,形成新的embedding阵列,其实现方法如下:
所述步骤s3包括如下步骤:
s301、将带噪语音的embedding阵列和所述长期记忆输入至注意力模块,并分别对所述带噪语音的embedding阵列和含有纯净语音特征的长期记忆进行注意力计算得到时频掩蔽;
所述时频掩蔽的表达式如下:
at,f=sigmoid(m·at,f)
其中,m表示长期记忆,at,f表示embedding阵列中的每个embedding向量,at,f表示时频掩蔽层的每个时频单元
s302、将所述时频掩蔽进行复制和堆叠,产生堆叠时频掩蔽层,并将堆叠时频掩蔽层的尺寸与embedding阵列的尺寸保持一致,所述堆叠时频掩蔽的尺寸为(f×t×e),其中,f表示频率,t表示时间、e表示embedding向量的尺寸;
s303、利用所述堆叠时频掩蔽层从embedding阵列中提取语音特征,形成新的embedding阵列;
所述提取语音特征a'的表达式如下:
a'=a⊙sm
其中,a表示embedding阵列,sm表示堆叠的时频掩蔽层,⊙表示矩阵点乘;
s4、利用基于卷积神经网络的embedding解码器网络将所述新的embedding阵列还原为增强语音语谱图,实现语音增强。
本实施例中,本实验将timit语料库和noisex92数据集分别作为语音数据集和噪声数据集。timit语料库中的1984条语音和noisex92中的babble、factory1、destroyerops、f16和white噪声被用于合成带噪语音训练集,混合信噪比范围为-5~0db。所有音频数据采样频率为16khz,使用包含512个采样点的hamming窗以及256的帧移的短时傅里叶变换来计算语谱图。评价指标:短时目标可懂度(stoi,short-timeobjectiveintelligibility),语音质量感知指标(pesq,perceptualevaluationofspeechquality)。
与本发明的模型(aeed)对比的有:单embedding编解码器(eed),卷积循环神经网络(crn),深度循环神经网络(drn)和原始基于声学选择框架的注意力和记忆模型(asam)。如表1-4所示,表1为不同模型在可见噪声上对stoi指标的测试结果,表2为不同模型在可见噪声上对pesq指标的测试结果,表3为不同模型在不可见噪声上对stoi指标的测试结果,表4为不同模型在不可见噪声上对pesq指标的测试结果。
表1
表2
表3
表4
实验对比结果如下,aeed和eed的性能较原始asam有明显提高,结合了注意力机制和长期记忆的aeed指标总体好于eed。aeed在所有测试中取得了最好的pesq;crn在大多数测试条件下取得了最好的stoi,而aeed可以达到与其接近的stoi指标。
- 还没有人留言评论。精彩留言会获得点赞!