基于全卷积网络的声音事件检测方法与流程
本发明属于事件检测技术领域,特别涉及一种多音频事件的检测方法,可用于安全监控。
背景技术:
音频事件检测是指在音频流中定位感兴趣的声音事件并将其正确分类。音频信息在救灾抢险、枪声监控等领域表现出比图像信息更好的实用性,此外音频信息还可以辅助视频信息完成视频监控,搜索任务等,因此实现音频事件检测极具现实意义。
对现实生活中得到的真实音频流进行声音事件检测一直是一项极有挑战性的任务,这是因为首先在现实中不同事件的并发性强,不同的声音事件常常同时发生,这要求音频事件检测系统能够从混叠的音频信号中识别复数的音频事件,也就是所谓的多音频事件检测;其次事件的时间长度难以确定,不同事件的持续时间有很大区别,相同的音频事件在不同场景,甚至在相同场景下的持续时间也有很大区别。早期的音频事件检测算法包括隐马尔可夫模型法和非负矩阵分解法。近年来,随着深度学习的不断发展,基于深度学习的算法,如cnn,rnn等表现出优于传统算法的性能。
2015年,emrecakir等人在polyphonicsoundeventdetectionusingmultilabeldeepneuralnetworks中引入dnn对混叠音频做多标签检测,得到了比传统的隐马尔可夫模型法更高的精度。haominzhang等人在robustsoundeventrecognitionusingconvolutionalneuralnetworks一文中使用cnn对噪声环境下的音频事件进行识别,得到的结果证明网络分类器比传统分类器鲁棒性更强。但是他们的网络结构都没有考虑到音频事件的时域特征联系,
2017年,emrecakir等人在convolutionalrecurrentneuralnetworksforpolyphonicsoundeventdetection一文中结合cnn和rnn提出了crnn算法。该算法使用cnn提取频谱特征,使用rnn提取时间序列信息,凭借优异的性能成为业界主流。但在检测实际音频流中的声音事件时,没有考虑到不同事件持续长度不一的问题,采取了单一尺度网络提取音频的时域特征。
2018年,为了获得多尺度信息,ruilu等人在multi-scalerecurrentneuralnetworkforsoundeventdetection一文中提出了一个多尺度rnn模型,该模型使用两组rnn网络获得捕获不同尺度信息进行多音频事件检测,获得了较好的性能。不过由于rnn网络无法并行处理数据,故算法的时间复杂度过高,网络训练时间过长。
上述的现有方法,虽然可以在一定程度上完成多音频事件检测任务,但是仍旧存在以下问题:1)crnn网络通过lstm等rnn类网络捕获时间序列信息,然而lstm能够有效捕获的最大依赖性长度仅在30到80之间,且是单一尺度信息。这使得rnn类网络难以同时完成定位和分类,且在进行持续时间不同的音频事件检测任务时精度偏低。2)rnn网络难以并行处理,算法时间复杂度高,导致网络训练时间过长。
技术实现要素:
本发明的目的在于克服上述现有技术存在的不足,提出一种基于全卷积网络的声音事件检测方法,以提高多音频事件检测的检测精度和速度。
为实现上述目的,本发明的技术方案包括如下:
(1)对待检测音频流进行数据预处理,即从音频流中提取若干梅尔倒谱特征,每个梅尔倒谱特征表现为一张时频特征图,这些时频特征图组成数据集;
(2)对预处理后得到的数据集做四次交叉验证,得到四组数据子集,每组数据子集包括75%的训练集和25%的验证集;
(3)设计一个自上而下由频率卷积网络、时间卷积网络和解码卷积网络组成的全卷积多音频事件检测网络:
(4)对(2)得到的四组数据子集分别进行标准化处理,并将标准化处理后的数据子集与其对应的标签作为输入样本,一起输入到(3)设计的全卷积多音频事件检测网络中,并利用标准化处理后的训练集和验证集对其进行训练,得到训练好的全卷积多音频事件检测网络;
(5)将待检测音频流经过预处理后得到的时频特征图输入到训练好的全卷积多音频事件检测网络中,得到每类音频事件存在的概率值;
(6)设定检测阈值q,将(5)得到的概率值与检测阈值q进行比较:若概率值大于q,则认为该事件存在;若概率值小于等于q,则认为该事件不存在,得到最终音频事件的检测结果。
本发明与现有技术相比,具有如下优点:
1.本发明由于设计了全卷积多音频事件检测网络,不仅可以捕获短时细粒度特征,以对事件边界进行定位,而且可以捕获长时上下文信息,以对事件进行分类,提高了多音频事件检测的精度。
2.由于本发明设计的全卷积多音频事件检测网络中的频率卷积网络、时间卷积网络和解码卷积网络都支持并行运算,所以本发明的时间复杂度比现有技术更低,训练时间大大缩短。
附图说明
图1为本发明的实现流程图;
图2本发明中提取音频流梅尔倒谱特征的示意图;
图3为本发明中的梅尔滤波器结构示意图;
图4为本发明中的全卷积多音频事件检测网络结构示意图。
具体实施方式
下面结合附图对本发明具体实施例和效果作进一步详细描述。
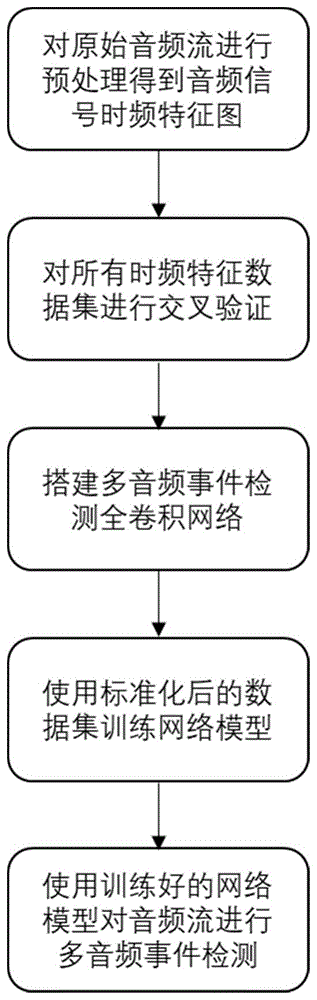
参照图1,本实例的多音频事件检测方法,包括如下步骤:
步骤1,对音频流信号进行预处理得到数据集。
为了实现对原始音频流信号进行有效的时频特征提取,本实例使用的是音频领域中常用的特征提取方式梅尔倒谱。
如图2所示,本步骤的具体实现如下:
1.1)对原始音频流信号做分帧操作,每一帧长度为40ms,帧与帧之间的时间重叠率为50%;
1.2)对得到的每一帧音频段先作傅里叶变换,再把每一帧的傅里叶变换结果沿时间维堆叠起来,得到音频流信号的声谱图,其中每张声谱图时间维长度为256帧;
1.3)为了得到大小合适的声音特征,将每张声谱图通过数量为40的梅尔标度滤波器组,变换为频率维长度为40梅尔频谱特征,得到的每个音频流信号梅尔频谱特征大小为40×256,其中第一维为频率维,第二维为时间维;
所述梅尔标度滤波器组,如图3所示,其中每一个三角窗为一个梅尔滤波器,它们将普通的频率标度转化为梅尔频率标度;该梅尔标度滤波器一共包含40个三角窗,即为包含40个滤波器的梅尔标度滤波器组。梅尔频率标度由stevens,volkmann和newman在1937年命名。人耳能听到的频率范围是20-20000hz,但人耳对hz这种标度单位并不是线性感知关系。例如人耳适应了1000hz的音调,如果把音调频率提高到2000hz,则耳朵只能觉察到频率提高了一点点,根本察觉不到频率提高了一倍。而在梅尔频率标度下,人耳对频率的感知度就成了线性关系。也就是说,如果两段音频的梅尔频率相差两倍,则人耳可以感知到的音调大概也相差两倍。梅尔标度滤波器组所示映射关系,便是普通频率标度和梅尔频率标度之间的映射关系。
1.4)在每张梅尔频谱特征上做倒谱分析,分别得到其对应的梅尔倒谱,即mfcc特征,每个mfcc特征表现为一张大小是40×256的时频特征图,这些时频特征图组成数据集。
步骤2,对预处理后得到的数据集进行交叉验证。
交叉验证,是一种统计学上将数据样本切割成较小子集的实用方法。
本实例采用四次交叉验证,即将数据集均分为四等份,选择其中一份作为验证集,其余三份作为训练集,组成包括25%的验证集和75%的训练集的数据子集;
根据验证集和训练集的不同选择,总共得到四组数据子集。
步骤3,搭建全卷积多音频事件检测网络。
参照图4,本实例搭建的全卷积多音频事件检测网络自上而下由频率卷积网络、时间卷积网络和解码卷积网络组成,其中:
所述频率卷积网络,其结构由自上而下连接的三个频率卷积子网络组成,每个频率卷积子网络自上而下由二维卷积层、批量标准化层和非重叠最大池化层连接组成;
所述二维卷积层,使用的卷积核大小为3,步长为1,卷积核个数为64,激活函数为relu;
所述非重叠最大池化层,其只在频域进行,且第一个频率卷积子网络中的池化层窗口大小为5,第二个和第三个频率卷积子网络中的池化层窗口大小为2;
所述时间卷积网络,由自上而下连接的六个时间卷积子网络组成,每个时间卷积子网络自上而下由一维空洞卷积层和批量标准化层连接组成,其中,一维空洞卷积层使用的空洞系数为2n-1,n为空洞卷积层的层数,卷积核大小为3,步长为1,卷积核个数为32,激活函数为relu,dropout为0.2,不使用零填充;
所述解码卷积网络,由自上而下连接的上采样层和一维卷积层组成;
所述上采样层,采用双线性插值法进行上采样,上采样后输出特征的时间维长度为256;
所述一维卷积层,使用的卷积核大小为3,步长为1,卷积核个数与音频事件类别数均为6个,激活函数为sigmiod。
步骤4,对数据子集进行标准化后输入全卷积多音频事件检测网络进行训练。
4.1)对于步骤2得到的四个数据子集,分别使用标准化函数计算其训练集的均值和方差,并基于计算出的均值和方差将训练集和验证集转换为标准正态分布;
4.2)将标准化后的训练集和验证集输入到全卷积多音频事件检测网络,即自上而下依次通过频率卷积网络、时间卷积网络和解码卷积网络;
数据子集中的时频特征图从频率卷积网络输出后大小变为2×256×64,其中,第一维为频率维,第二维为时间维,第三维为通道数,将特征图沿频率维展开,得到大小为256×128的特征图继续输入时间卷积网络,从时间卷积网络输出后大小变为190×32,其中,第一维为时间维,第二维为通道数。由于解码卷积网络中一维卷积层的每个卷积核都连接一个激活函数sigmiod,sigmiod的输出对应于每类音频事件存在的概率值,所以特征图经过解码卷积网络输出后,得到大小为256×6的各类音频事件在当前时间帧发生可能性
4.3)网络选取了二分类交叉熵作为损失函数,它的输入为两个向量,一个是经过sigmiod激活函数后输出的音频事件存在可能性
其中t为当前时间帧数,t为总时间帧数,m为音频事件类别,本实例为6类;
4.4)根据损失函数计算全卷积多音频事件检测网络中卷积核参数的梯度值▽θi,公式如下:
其中θi是全卷积多音频事件检测网络中的第i个卷积核参数;
4.5)利用4.4)得到的卷积核参数的梯度值
其中,η为学习率,本实例中取值为0.001;
4.5)更新完一遍全卷积多音频事件检测网络的所有卷积核参数,即完成一次网络训练;设定训练次数n=1000,如果当前训练次数达到1000次,或者损失函数在训练中连续100次不变小,则训练停止,得到训练好的卷积核参数,否则,返回4.2)。
步骤5,使用全卷积多音频事件检测网络对音频流进行多音频事件检测。
5.1)在网络测试阶段,对待检测音频流进行mfcc特征提取,得到待检测音频流的时频特征图,并对时频特征图进行标准化处理;
5.2)将标准化后的时频特征图输入到训练好的全卷机多音频事件检测网络中,得到6类音频事件在每个时间帧中存在的输出概率值
5.3)设音频事件检测阈值q为0.5,将网络输出的某类音频事件存在的概率值
5.4)根据标签时间维度上1存在的位置,即可判定6类音频事件发生的起止时间,得到最终检测结果。
本发明的效果可通过以下仿真进一步说明:
对本发明搭建的全卷积多音频事件检测网络进行训练,得到网络训练时长;
使用训练好的网络对待检测音频流进行多音频事件检测,根据检测结果计算精度指标er和f1-score,其中er指标用来衡量检测结果的错误率,f1-score用来衡量检测结果的精确度;
将本发明的训练时长和精度指标与现有网络进行比较,结果如表1所示:
表1
从表1可以看出,本发明在相同条件下,比现有精度最高的3d-crnn网络在精度上又提升了2%左右,在运行时间上提升了5倍左右。
- 还没有人留言评论。精彩留言会获得点赞!